

Dieser Artikel bietet Ihnen eine Einführung in die SQL-Optimierung für Tabellenabfragen. Ich hoffe, dass er für Freunde hilfreich ist.
Hintergrund
Diese SQL-Optimierung gilt für Tabellenabfragen in Javaweb.
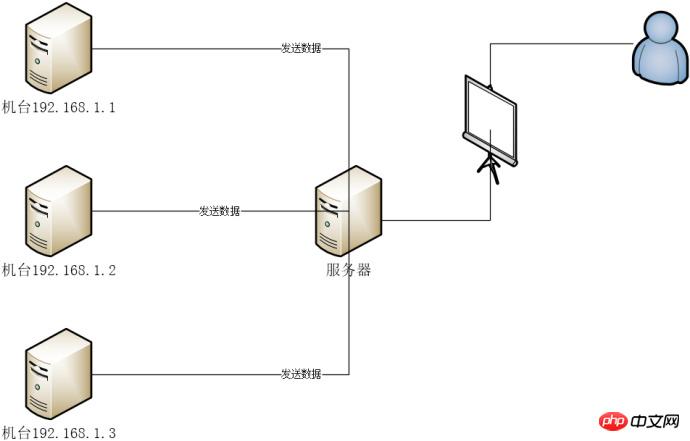
N Maschinen senden Geschäftsdaten an Auf dem Server speichert das Serverprogramm die Daten in der MySQL-Datenbank. Das Javaweb-Programm auf dem Server zeigt die Daten auf der Webseite an, damit Benutzer sie anzeigen können.
Windows eigenständige Master-Slave-Trennung
Wurde in Tabellen und Datenbanken unterteilt Jahr für Jahr Talenttabelle
Jede Tabelle enthält etwa 200.000 Daten
3 Tage Datenabfrage 70-80er Jahre
3-5s
Kann SQL-Paging nicht verwenden, kann nur Java für Paging verwenden.
Wenn Sie Druid konfigurieren, können Sie die SQL-Ausführungszeit und die URI-Anfrage direkt auf der Druid-Seite anzeigen Time
verwendet System.currentTimeMillis im Hintergrundcode, um den Zeitunterschied zu berechnen.
Fazit: Der Hintergrund ist langsam und das Abfragen von SQL ist langsam
Das SQL Das Spleißen ist zu lang und erreicht 3000 Zeilen, einige sogar 8000 Zeilen. Die meisten davon sind Union-All-Operationen und es werden unnötige verschachtelte Abfragen und unnötige Felder abgefragt.
Verwenden Sie EXPLAIN, um die Ausführung anzuzeigen Plan, außer der Zeit, verwendet nur ein Feld in der Where-Bedingung den Index
Hinweis: Da die Optimierung abgeschlossen ist, kann die vorherige SQL nicht gefunden werden, daher kann ich hier nur YY verwenden .
Der Effekt ist nicht so offensichtlich
Der Effekt ist nicht so offensichtlich offensichtlich
Zum Beispiel die Union-All-Operation zerlegen (eine Union-all-SQL ist auch sehr lang)
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_02 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_03 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_04 left join ... on .. left join .. on .. where ..
Zerlegen Sie die obige SQL zur Ausführung in mehrere SQL und fassen Sie schließlich die Daten zusammen, was etwa 20 Sekunden schneller ist.
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where ..
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where ..
Verwenden Sie asynchrone Java-Programmieroperationen, führen Sie es aus Zerlegen Sie das SQL asynchron und fassen Sie die Daten schließlich zusammen. Hier werden CountDownLatch und ExecutorService verwendet:
// 获取时间段所有天数
List<String> days = MyDateUtils.getDays(requestParams.getStartTime(), requestParams.getEndTime());
// 天数长度
int length = days.size();
// 初始化合并集合,并指定大小,防止数组越界
List<你想要的数据类型> list = Lists.newArrayListWithCapacity(length);
// 初始化线程池
ExecutorService pool = Executors.newFixedThreadPool(length);
// 初始化计数器
CountDownLatch latch = new CountDownLatch(length);
// 查询每天的时间并合并
for (String day : days) {
Map<String, Object> param = Maps.newHashMap();
// param 组装查询条件
pool.submit(new Runnable() {
@Override
public void run() {
try {
// mybatis查询sql
// 将结果汇总
list.addAll(查询结果);
} catch (Exception e) {
logger.error("getTime异常", e);
} finally {
latch.countDown();
}
}
});
}
try {
// 等待所有查询结束
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// list为汇总集合
// 如果有必要,可以组装下你想要的业务数据,计算什么的,如果没有就没了Das Ergebnis ist 20-30s schneller
Nachfolgend finden Sie ein Beispiel meiner Konfiguration. Skip-Name-Resolve hinzugefügt, 4-5 Sekunden schneller. Andere Konfigurationen werden von selbst bestimmt
[client] port=3306 [mysql] no-beep default-character-set=utf8 [mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin slave-skip-errors=all #跳过所有错误 skip-name-resolve port=3306 datadir="D:/mysql-slave/data" character-set-server=utf8 default-storage-engine=INNODB sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" log-output=FILE general-log=0 general_log_file="WINDOWS-8E8V2OD.log" slow-query-log=1 slow_query_log_file="WINDOWS-8E8V2OD-slow.log" long_query_time=10 # Binary Logging. # log-bin # Error Logging. log-error="WINDOWS-8E8V2OD.err" # 整个数据库最大连接(用户)数 max_connections=1000 # 每个客户端连接最大的错误允许数量 max_connect_errors=100 # 表描述符缓存大小,可减少文件打开/关闭次数 table_open_cache=2000 # 服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的BLOB字段一起工作时相当必要) # 每个连接独立的大小.大小动态增加 max_allowed_packet=64M # 在排序发生时由每个线程分配 sort_buffer_size=8M # 当全联合发生时,在每个线程中分配 join_buffer_size=8M # cache中保留多少线程用于重用 thread_cache_size=128 # 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量. thread_concurrency=64 # 查询缓存 query_cache_size=128M # 只有小于此设定值的结果才会被缓冲 # 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖 query_cache_limit=2M # InnoDB使用一个缓冲池来保存索引和原始数据 # 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少. # 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80% # 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸. innodb_buffer_pool_size=1G # 用来同步IO操作的IO线程的数量 # 此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在一个大数值下表现的更好. innodb_read_io_threads=16 innodb_write_io_threads=16 # 在InnoDb核心内的允许线程数量. # 最优值依赖于应用程序,硬件以及操作系统的调度方式. # 过高的值可能导致线程的互斥颠簸. innodb_thread_concurrency=9 # 0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘. # 1 ,InnoDB会在每次提交后刷新(fsync)事务日志到磁盘上 # 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上 innodb_flush_log_at_trx_commit=2 # 用来缓冲日志数据的缓冲区的大小. innodb_log_buffer_size=16M # 在日志组中每个日志文件的大小. innodb_log_file_size=48M # 在日志组中的文件总数. innodb_log_files_in_group=3 # 在被回滚前,一个InnoDB的事务应该等待一个锁被批准多久. # InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务. # 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎 # 那么一个死锁可能发生而InnoDB无法注意到. # 这种情况下这个timeout值对于解决这种问题就非常有帮助. innodb_lock_wait_timeout=30 # 开启定时 event_scheduler=ON
Schnell 4-5s
Die Auswirkung ist nicht so offensichtlich
Darüber bin ich selbst sehr überrascht. Das ursprüngliche SQL, b ist der Index
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where b = 'xxx'
Es sollte vorher Union All geben, Union All wird einzeln ausgeführt und das endgültige Zusammenfassungsergebnis wird erhalten . Geändert in
select aa from bb_2018_10_02 left join ... on .. left join .. on .. inner join
(
select 'xxx1' as b2
union all
select 'xxx2' as b2
union all
select 'xxx3' as b2
union all
select 'xxx3' as b2
) t on b = t.b2Das Ergebnis ist 3-4 Sekunden schneller
Entsprechend der obigen Operation ist die Abfrage Die Effizienz wurde in 3 Tagen verbessert. Sie erreichte etwa 8 Sekunden und könnte nicht schneller sein. Die CPU-Auslastung und die Speicherauslastung von MySQL sind nicht sehr hoch. Die maximale Datenmenge beträgt 600.000 in 3 Tagen. Dies ist also nicht der Fall. Verlässt man sich weiterhin auf die im Internet bereitgestellten Informationen, sind eine Reihe sexy Operationen grundsätzlich nutzlos und es gibt keine Möglichkeit.
Nach der Analyse der SQL-Optimierung ist es bereits in Ordnung. Stellen Sie sich vor, es handele sich um ein Problem beim Lesen und Schreiben der Festplatte. Stellen Sie die optimierten Programme in verschiedenen Umgebungen vor Ort bereit. Einer hat SSD und einer hat keine SSD. Es wurde festgestellt, dass die Abfrageeffizienz sehr unterschiedlich war. Nach Tests mit Software wurde festgestellt, dass die Lese- und Schreibgeschwindigkeit einer SSD 700–800 M/s beträgt und die Lese- und Schreibgeschwindigkeit einer gewöhnlichen mechanischen Festplatte 70–80 M/s beträgt.
Optimierungsergebnisse: Erwartungen erfüllen.
Schlussfolgerung zur Optimierung: SQL-Optimierung ist nicht nur die Optimierung von SQL selbst, sondern hängt auch von den eigenen Hardwarebedingungen, den Auswirkungen anderer Anwendungen und der Optimierung des eigenen Codes ab.
Das Obige ist der gesamte Inhalt dieses Artikels. Weitere spannende Informationen zu Java finden Sie im Java-Video-Tutorial und in der Java-Entwicklung Tutorial auf der chinesischen PHP-Website Spalte! ! !
Das obige ist der detaillierte Inhalt vonEinführung in die SQL-Optimierung für Tabellenabfragen in Javaweb. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was sind die Parameter des Festzeltes?
Was sind die Parameter des Festzeltes?
 Neueste Nachrichten zu Shib-Münzen
Neueste Nachrichten zu Shib-Münzen
 Alle Verwendungen von Cloud-Servern
Alle Verwendungen von Cloud-Servern
 Vom Viewer aufgerufene Methode
Vom Viewer aufgerufene Methode
 So registrieren Sie sich bei Binance
So registrieren Sie sich bei Binance
 Wissen Sie, ob Sie die andere Person sofort kündigen, nachdem Sie ihr auf Douyin gefolgt sind?
Wissen Sie, ob Sie die andere Person sofort kündigen, nachdem Sie ihr auf Douyin gefolgt sind?
 Allgemeine iscsiadm-Befehle
Allgemeine iscsiadm-Befehle
 Was können TikTok-Freunde tun?
Was können TikTok-Freunde tun?









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



