

Dieser Artikel bietet Ihnen eine grundlegende Einführung in MapReduce (mit Code). Ich hoffe, dass er für Sie hilfreich ist.
1. WordCount-Programm
1.1 WordCount-Quellprogramm
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}1.2 Führen Sie das Programm aus, Ausführen als->Java-Anwendung
1.3 Kompilieren und Paket Programm, Jar-Datei generieren
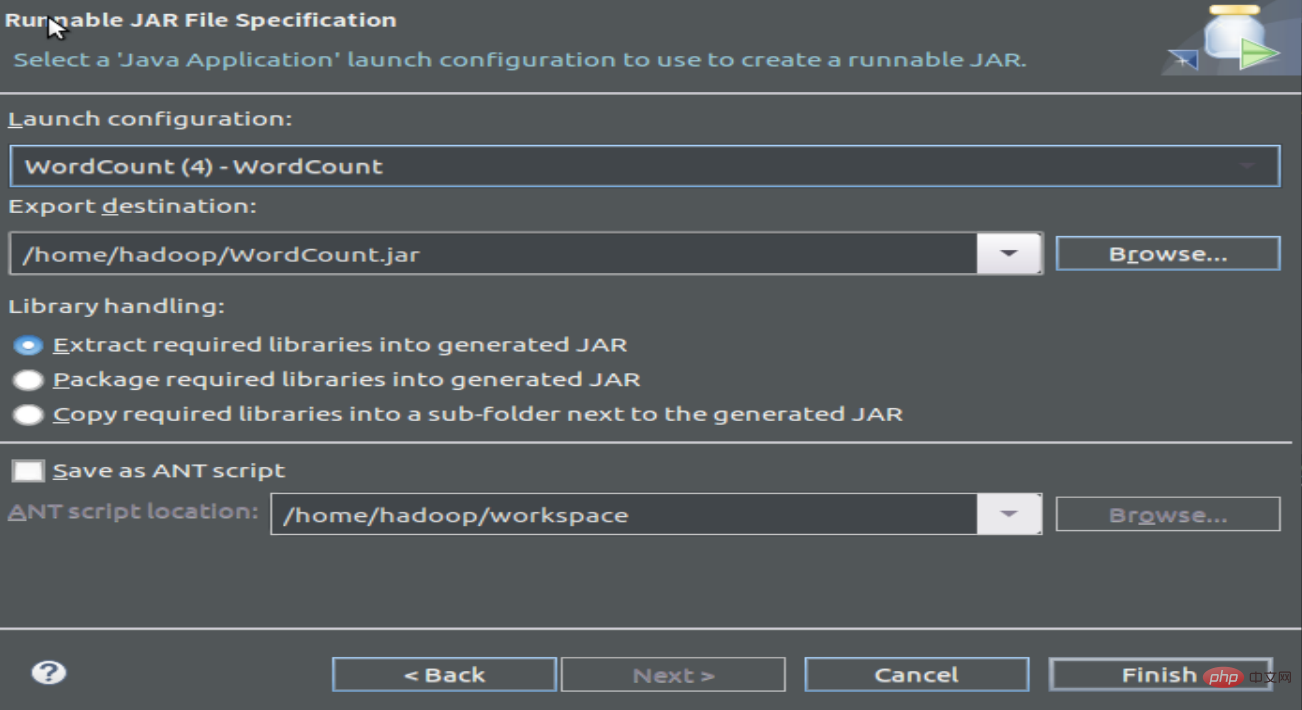
2 Führen Sie das Programm aus
2.1 Erstellen Sie eine Textdatei zum Zählen der Worthäufigkeit
wordfile1.txt
Spark Hadoop
Big Data
wordfile2.txt
Spark Hadoop
Big Cloud
2.2 Starten Sie hdfs und erstellen Sie einen neuen Eingabedateiordner, laden Sie die Worthäufigkeitsdatei hoch
cd /usr/local/hadoop/
./sbin/start-dfs.sh
./ bin/hadoop fs -mkdir input
./bin/hadoop fs -put /home/hadoop/wordfile1.txt input
./bin/hadoop fs -put /home/hadoop/wordfile2 .txt-Eingabe
2.3 Sehen Sie sich die hochgeladene Worthäufigkeitsdatei an:
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls .
Gefunden 2 items
drwxr-xr- x - hadoop supergroup 0 2019-02-11 15:40 input
-rw-r--r-- 1 hadoop supergroup 5 2019-02-10 20:22 test.txt
hadoop@dblab-VirtualBox: /usr/local/hadoop$ ./bin/hadoop fs -ls ./input
2 Elemente gefunden
-rw-r--r-- 1 Hadoop-Supergruppe 27 2019- 02-11 15:40 input/wordfile1.txt
-rw-r--r-- 1 hadoop supergroup 29 2019-02-11 15:40 input/wordfile2.txt
2.4 Run WordCount
./bin /hadoop jar /home/hadoop/WordCount.jar Eingabe-Ausgabe
Eine große Menge an Informationen wird auf dem Bildschirm eingegeben
Dann können Sie den Lauf anzeigen Ergebnisse:
hadoop@dblab-VirtualBox: /usr/local/hadoop$ ./bin/hadoop fs -cat output/*
Hadoop 2
Spark 2
Das obige ist der detaillierte Inhalt vonEinführung in den Grundinhalt von MapReduce (mit Code). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Lernen Sie C# von Grund auf
Lernen Sie C# von Grund auf
 So lösen Sie verstümmelte Filezilla-Zeichen
So lösen Sie verstümmelte Filezilla-Zeichen
 So aktivieren Sie die gleiche Stadtfunktion auf Douyin
So aktivieren Sie die gleiche Stadtfunktion auf Douyin
 Verlauf der Oracle-Ansichtstabellenoperationen
Verlauf der Oracle-Ansichtstabellenoperationen
 Douyin-Level-Preisliste 1-75
Douyin-Level-Preisliste 1-75
 So summieren Sie dreidimensionale Arrays in PHP
So summieren Sie dreidimensionale Arrays in PHP
 Methode zur Registrierung eines Google-Kontos
Methode zur Registrierung eines Google-Kontos
 So lesen Sie Dateien und konvertieren sie in Java in Strings
So lesen Sie Dateien und konvertieren sie in Java in Strings
 Die Rolle des Linux-Betriebssystems
Die Rolle des Linux-Betriebssystems








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



