
 Datenbank
MySQL-Tutorial
Was ist MySql-Master-Slave-Replikation? Wie konfiguriere ich die Implementierung?
Datenbank
MySQL-Tutorial
Was ist MySql-Master-Slave-Replikation? Wie konfiguriere ich die Implementierung?
Was ist MySql-Master-Slave-Replikation? Wie konfiguriere ich die Implementierung?

Der Inhalt dieses Artikels soll Ihnen vorstellen, was MySql-Master-Slave-Replikation ist. Wie konfiguriere ich die Implementierung? Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird Ihnen hilfreich sein.
1. Was ist MySQL-Master-Slave-Replikation
MySQL-Master-Slave-Replikation ist eine ihrer wichtigsten Funktionen. Master-Slave-Replikation bedeutet, dass ein Server als Master-Datenbankserver fungiert und ein oder mehrere Server als Slave-Datenbankserver fungieren. Die Daten im Master-Server werden automatisch auf die Slave-Server kopiert. Bei der mehrstufigen Replikation kann der Datenbankserver entweder als Master oder als Slave fungieren. Die Grundlage der MySQL-Master-Slave-Replikation besteht darin, dass der Master-Server Binärprotokolle von Datenbankänderungen aufzeichnet und der Slave-Server automatisch Aktualisierungen über die Binärprotokolle des Master-Servers durchführt.
2. Arten der Mysq-Master-Slave-Replikation
1. Anweisungsbasierte Replikation:
Die auf dem Master-Server ausgeführte Anweisung wird erneut auf dem Slave-Server ausgeführt in MySQL – Unterstützt nach Version 3.23.
Bestehende Probleme: Es kann sein, dass die Uhrzeit nicht vollständig synchronisiert ist, was zu Abweichungen führt und der Benutzer, der die Anweisung ausführt, möglicherweise auch ein anderer Benutzer ist.
2. Zeilenbasierte Replikation:
Kopieren Sie den angepassten Inhalt direkt auf den Hauptserver, ohne sich darum zu kümmern, welche Anweisung die Inhaltsänderung verursacht hat. Wird in einer späteren Version eingeführt .
Bestehende Probleme: Beispielsweise gibt es 10.000 Benutzer in einer Gehaltstabelle und wir addieren das Gehalt jedes Benutzers um 1.000, dann kopiert die zeilenbasierte Replikation den Inhalt von 10.000 Zeilen, was zu einem relativ großen Overhead führt Für die anweisungsbasierte Replikation ist nur eine Anweisung erforderlich.
3. Replikation gemischter Typen:
MySQL verwendet standardmäßig die anweisungsbasierte Replikation. Wenn die anweisungsbasierte Replikation Probleme verursacht, wird die zeilenbasierte Replikation verwendet und MySQL wählt automatisch.
In der MySQL-Master-Slave-Replikationsarchitektur können Lesevorgänge auf allen Servern ausgeführt werden, während Schreibvorgänge nur auf dem Master-Server ausgeführt werden können. Obwohl die Master-Slave-Replikationsarchitektur eine Erweiterung für Lesevorgänge bietet, wird der Master-Server bei mehr Schreibvorgängen (mehrere Slave-Server müssen Daten vom Master-Server synchronisieren) zwangsläufig zu einem Leistungsengpass bei der Replikation des Single-Masters Modell.
3. Das Funktionsprinzip der MySQL-Master-Slave-Replikation
1: Die auf dem Master-Server ausgeführten Anweisungen sind auf dem Slave-Server ausgeführt. Führen Sie es erneut aus. Es wird in MySQL-3.23 und späteren Versionen unterstützt.
Bestehende Probleme: Es kann sein, dass die Uhrzeit nicht vollständig synchronisiert ist, was zu Abweichungen führt und der Benutzer, der die Anweisung ausführt, möglicherweise auch ein anderer Benutzer ist.2, zeilenbasierte Replikation: Kopieren Sie den angepassten Inhalt direkt auf den Hauptserver, ohne sich darum zu kümmern, welche Anweisung die Änderung verursacht hat, eingeführt nach MySQL-5.0 Version.
Bestehende Probleme: Beispielsweise gibt es 10.000 Benutzer in einer Gehaltstabelle und wir addieren das Gehalt jedes Benutzers um 1.000, dann kopiert die zeilenbasierte Replikation den Inhalt von 10.000 Zeilen, was zu einem relativ großen Overhead führt Für die anweisungsbasierte Replikation ist nur eine Anweisung erforderlich.3, Replikation gemischter Typen: MySQL verwendet standardmäßig die anweisungsbasierte Replikation, und die zeilenbasierte Replikation wird verwendet, wenn die anweisungsbasierte Replikation Probleme verursacht. MySQL wählt es automatisch aus.
In der MySQL-Master-Slave-Replikationsarchitektur können Lesevorgänge auf allen Servern ausgeführt werden, während Schreibvorgänge nur auf dem Master-Server ausgeführt werden können. Obwohl die Master-Slave-Replikationsarchitektur eine Erweiterung für Lesevorgänge bietet, wird der Master-Server bei mehr Schreibvorgängen (mehrere Slave-Server müssen Daten vom Master-Server synchronisieren) zwangsläufig zu einem Leistungsengpass bei der Replikation des Single-Masters Modell. Drei Funktionsprinzipien der MySQL-Master-Slave-Replikation Wie unten gezeigt: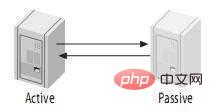
Zuallererst macht ein Prozess das Kopieren von Bin-Log-Protokollen und das Parsen von Protokollen zu einem seriellen Prozess. Die Leistung unterliegt bestimmten Einschränkungen, und die Verzögerung der asynchronen Replikation ist ebenfalls relativ lang .
Außerdem muss die Slave-Seite, nachdem sie das Bin-Protokoll von der Master-Seite erhalten hat, den Protokollinhalt analysieren und ihn dann selbst ausführen. Während dieses Vorgangs sind möglicherweise viele Änderungen auf der Master-Seite aufgetreten und es wurden möglicherweise viele neue Protokolle hinzugefügt. Wenn zu diesem Zeitpunkt ein irreparabler Fehler im Speicher auf der Master-Seite auftritt, werden alle zu diesem Zeitpunkt vorgenommenen Änderungen niemals abgerufen. Wenn der Druck auf den Slave relativ hoch ist, kann dieser Vorgang länger dauern.
Um die Leistung der Replikation zu verbessern und bestehende Risiken zu lösen, werden spätere Versionen von MySQL die Replikationsaktion auf der Slave-Seite auf zwei Prozesse übertragen. Die Person, die diesen Verbesserungsplan vorgeschlagen hat, ist „Jeremy Zawodny“, ein Ingenieur bei Yahoo! Dadurch wird nicht nur das Leistungsproblem gelöst, sondern auch die asynchrone Verzögerungszeit verkürzt und das Ausmaß möglicher Datenverluste verringert.
Natürlich besteht auch nach dem Wechsel zur aktuellen Zwei-Thread-Verarbeitung immer noch die Möglichkeit einer Slave-Datenverzögerung und eines Datenverlusts. Schließlich ist diese Replikation asynchron. Diese Probleme bleiben bestehen, solange die Datenänderungen nicht in einer Transaktion erfolgen. Wenn Sie diese Probleme vollständig vermeiden möchten, können Sie sie nur mit MySQL-Clustern lösen. Der MySQL-Cluster ist jedoch eine Lösung für In-Memory-Datenbanken. Alle Daten müssen in den Speicher geladen werden, was sehr viel Speicher erfordert und für allgemeine Anwendungen nicht sehr praktisch ist.
Eine weitere Sache, die zu erwähnen ist, ist, dass Sie mit den Replikationsfiltern von MySQL nur einen Teil der Daten auf dem Server kopieren können. Es gibt zwei Arten der Replikationsfilterung: Filtern von Ereignissen im Binärprotokoll auf dem Master und Filtern von Ereignissen im Relay-Protokoll auf dem Slave. Wie folgt:
Konfigurieren Sie die my.cnf-Datei des Masters (Schlüsselkonfiguration)/etc/my.cnf
log-bin=mysql-bin server-id = 1 binlog-do-db=icinga binlog-do-db=DB2 //如果备份多个数据库,重复设置这个选项即可 binlog-do-db=DB3 //需要同步的数据库,如果没有本行,即表示同步所有的数据库 binlog-ignore-db=mysql //被忽略的数据库 配置Slave的my.cnf文件(关键性的配置)/etc/my.cnf log-bin=mysql-bin server-id=2 master-host=10.1.68.110 master-user=backup master-password=1234qwer master-port=3306 replicate-do-db=icinga replicate-do-db=DB2 replicate-do-db=DB3 //需要同步的数据库,如果没有本行,即表示同步所有的数据库 replicate-ignore-db=mysql //被忽略的数据库
Netizens sagten, dass es Replikate-do-db gibt Da es bei der Nutzung zu Problemen kommen kann (http://blog.knowsky.com/19696...), habe ich es selbst nicht getestet. Ich vermute, dass der Parameter binlog-do-db im Hauptserver verwendet wird, um die Datenbanken herauszufiltern, die nicht in die Konfigurationsdatei kopiert werden dürfen, indem das Binärprotokoll gefiltert wird, d. h. keine Betriebsprotokolle geschrieben werden, die das Kopieren von Daten nicht zulassen in das Binärprotokoll kopiert werden; und „replicate-do -db“ wird vom Server verwendet, um Datenbanken oder Tabellen herauszufiltern, die nicht kopiert werden dürfen, indem das Relay-Protokoll gefiltert wird, d. h., wenn die Aktionen im Relay-Protokoll ausgeführt werden Unzulässige Änderungsaktionen werden nicht durchgeführt. In diesem Fall gilt bei mehreren Slave-Datenbankservern: Einige Slave-Server kopieren nicht nur Daten vom Master-Server, sondern fungieren auch als Master-Server, um Daten auf andere Slave-Server zu kopieren. Dann sollte binlog-do- vorhanden sein in seiner Konfigurationsdatei gleichzeitig. Die beiden Parameter db und Replicate-do-db sind korrekt. Alles ist meine eigene Vorhersage. Die spezifische Verwendung von binlog-do-db und Replicate-do-db muss in der tatsächlichen Entwicklung noch ein wenig untersucht werden.
Im Internet heißt es, dass das Ignorieren bestimmter Datenbanken oder Tabellen während der Replikation am besten nicht auf dem Masterserver durchgeführt werden sollte, da der Masterserver nach dem Ignorieren nicht mehr in die Binärdatei schreibt Datei, aber auf dem Slave-Server. Obwohl einige Datenbanken ignoriert werden, werden die Betriebsinformationen auf dem Master-Server weiterhin in das Relay-Protokoll auf dem Slave-Server kopiert, aber nicht auf dem Slave-Server ausgeführt. Ich denke, das bedeutet, dass es empfehlenswert ist, „replite-do-db“ auf dem Slave-Server statt „binlog-do-db“ auf dem Master-Server einzurichten.
Außerdem müssen Sie nur eine schreiben, unabhängig davon, ob es sich um eine Blacklist (binlog-ignore-db, Replicate-ignore-db) oder eine Whitelist (binlog-do-db, Replicate-do-db) handelt . Bei gleichzeitiger Nutzung greift nur die Whitelist.
4. Der Prozess der MySQL-Master-Slave-Replikation
Es gibt zwei Situationen der MySQL-Master-Slave-Replikation: synchrone Replikation und asynchrone Replikation. Der größte Teil der tatsächlichen Replikationsarchitektur ist asynchron Replikation.
Der grundlegende Prozess der Replikation ist wie folgt:
Der IO-Prozess auf dem Slave stellt eine Verbindung zum Master her und fordert die angegebene Protokolldatei vom angegebenen Speicherort an (oder von Anfang an) protokollieren).
Nachdem der Master die Anforderung vom E/A-Prozess des Slaves erhalten hat, liest der für die Replikation verantwortliche E/A-Prozess die Protokollinformationen nach der angegebenen Position im Protokoll gemäß den Anforderungsinformationen und gibt sie zurück zum IO-Prozess des Slaves. Zusätzlich zu den im Protokoll enthaltenen Informationen umfassen die zurückgegebenen Informationen auch den Namen der Bin-Log-Datei und den Speicherort des Bin-Logs, in dem die zurückgegebenen Informationen an den Master gesendet wurden.
Nachdem der E/A-Prozess des Slaves die Informationen empfangen hat, fügt er den empfangenen Protokollinhalt der Reihe nach am Ende der Relay-Log-Datei auf der Slave-Seite hinzu und liest die Bin- Protokoll auf der Master-Seite. Der Dateiname und der Speicherort des Protokolls werden in der Master-Info-Datei aufgezeichnet, sodass dem Master beim nächsten Lesen klar mitgeteilt werden kann, „von welchem Speicherort in einem bestimmten Bin-Protokoll aus ich“ möchte Ich muss mit dem nächsten Protokollinhalt beginnen, bitte senden Sie ihn mir.“
Nachdem der SQL-Prozess des Slaves den neu hinzugefügten Inhalt im Relay-Log erkennt, analysiert er sofort den Inhalt des Relay-Logs und wird zum ausführbaren Inhalt, wenn er tatsächlich ausgeführt wird die Master-Seite und führt sie auf sich selbst aus.
五、Mysql主从复制的具体配置
复制通常用来创建主节点的副本,通过添加冗余节点来保证高可用性,当然复制也可以用于其他用途,例如在从节点上进行数据读、分析等等。在横向扩展的业务中,复制很容易实施,主要表现在在利用主节点进行写操作,多个从节点进行读操作,MySQL复制的异步性是指:事物首先在主节点上提交,然后复制给从节点并在从节点上应用,这样意味着在同一个时间点主从上的数据可能不一致。异步复制的好处在于它比同步复制要快,如果对数据的一致性要求很高,还是采用同步复制较好。
最简单的复制模式就是一主一从的复制模式了,这样一个简单的架构只需要三个步骤即可完成:
(1)建立一个主节点,开启binlog,设置服务器id;
(2)建立一个从节点,设置服务器id;
(3)将从节点连接到主节点上。
下面我们开始操作,以MySQL 5.5为例,操作系统Ubuntu12.10,Master 10.1.6.159 Slave 10.1.6.191。
apt-get install mysql-server
Master机器
Master上面开启binlog日志,并且设置一个唯一的服务器id,在局域网内这个id必须唯一。二进制的binlog日志记录master上的所有数据库改变,这个日志会被复制到从节点上,并且在从节点上回放。修改my.cnf文件,在mysqld模块下修改如下内容:
[mysqld] server-id = 1 log_bin = /var/log/mysql/mysql-bin.log
log_bin设置二进制日志所产生文件的基本名称,二进制日志由一系列文件组成,log_bin的值是可选项,如果没有为log_bin设置值,则默认值是:主机名-bin。如果随便修改主机名,则binlog日志的名称也会被改变的。server-id是用来唯一标识一个服务器的,每个服务器的server-id都不一样。这样slave连接到master后,会请求master将所有的binlog传递给它,然后将这些binlog在slave上回放。为了防止权限混乱,一般都是建立一个单独用于复制的账户。
binlog是复制过程的关键,它记录了数据库的所有改变,通常即将执行完毕的语句会在binlog日志的末尾写入一条记录,binlog只记录改变数据库的语句,对于不改变数据库的语句则不进行记录。这种情况叫做基于语句的复制,前面提到过还有一种情况是基于行的复制,两种模式各有各的优缺点。
Slave机器
slave机器和master一样,需要一个唯一的server-id。
[mysqld] server-id = 2
连接Slave到Master
在Master和Slave都配置好后,只需要把slave只想master即可
change master to master_host='10.1.6.159',master_port=3306,master_user='rep', master_password='123456'; start slave;
接下来在master上做一些针对改变数据库的操作,来观察slave的变化情况。在修改完my.cnf配置重启数据库后,就开始记录binlog了。可以在/var/log/mysql目录下看到一个mysql-bin.000001文件,而且还有一个mysql-bin.index文件,这个mysql-bin.index文件是什么?这个文件保存了所有的binlog文件列表,但是我们在配置文件中并没有设置改值,这个可以通过log_bin_index进行设置,如果没有设置改值,则默认值和log_bin一样。在master上执行show binlog events命令,可以看到第一个binlog文件的内容。
注意:上面的sql语句是从头开始复制第一个binlog,如果想从某个位置开始复制binlog,就需要在change master to时指定要开始的binlog文件名和语句在文件中的起点位置,参数如下:master_log_file和master_log_pos。
mysql> show binlog events\G *************************** 1. row *************************** Log_name: mysql-bin.000001 Pos: 4 Event_type: Format_desc Server_id: 1 End_log_pos: 107 Info: Server ver: 5.5.28-0ubuntu0.12.10.2-log, Binlog ver: 4 *************************** 2. row *************************** Log_name: mysql-bin.000001 Pos: 107 Event_type: Query Server_id: 1 End_log_pos: 181 Info: create user rep *************************** 3. row *************************** Log_name: mysql-bin.000001 Pos: 181 Event_type: Query Server_id: 1 End_log_pos: 316 Info: grant replication slave on *.* to rep identified by '123456' 3 rows in set (0.00 sec)
Log_name 是二进制日志文件的名称,一个事件不能横跨两个文件
Pos 这是该事件在文件中的开始位置
Event_type 事件的类型,事件类型是给slave传递信息的基本方法,每个新的binlog都已Format_desc类型开始,以Rotate类型结束
Server_id 创建该事件的服务器id
End_log_pos 该事件的结束位置,也是下一个事件的开始位置,因此事件范围为Pos~End_log_pos-1
Info 事件信息的可读文本,不同的事件有不同的信息
示例
在master的test库中创建一个rep表,并插入一条记录。
create table rep(name var);
insert into rep values ("guol");
flush logs;flush logs命令强制轮转日志,生成一个新的二进制日志,可以通过show binlog events in 'xxx'来查看该二进制日志。可以通过show master status查看当前正在写入的binlog文件。这样就会在slave上执行相应的改变操作。
上面就是最简单的主从复制模式,不过有时候随着时间的推进,binlog会变得非常庞大,如果新增加一台slave,从头开始复制master的binlog文件是非常耗时的,所以我们可以从一个指定的位置开始复制binlog日志,可以通过其他方法把以前的binlog文件进行快速复制,例如copy物理文件。在change master to中有两个参数可以实现该功能,master_log_file和master_log_pos,通过这两个参数指定binlog文件及其位置。我们可以从master上复制也可以从slave上复制,假如我们是从master上复制,具体操作过程如下:
(1)为了防止在操作过程中数据更新,导致数据不一致,所以需要先刷新数据并锁定数据库:flush tables with read lock。
(2)检查当前的binlog文件及其位置:show master status。
mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000003 Position: 107 Binlog_Do_DB: Binlog_Ignore_DB: 1 row in set (0.00 sec)
(3)通过mysqldump命令创建数据库的逻辑备分:mysqldump --all-databases -hlocalhost -p >back.sql。
(4)有了master的逻辑备份后,对数据库进行解锁:unlock tables。
(5)把back.sql复制到新的slave上,执行:mysql -hlocalhost -p 把master的逻辑备份插入slave的数据库中。
(6)现在可以把新的slave连接到master上了,只需要在change master to中多设置两个参数master_log_file='mysql-bin.000003'和master_log_pos='107'即可,然后启动slave:start slave,这样slave就可以接着107的位置进行复制了。
change master to master_host='10.1.6.159',master_port=3306,master_user='rep', master_password='123456',master_log_file='mysql-bin.000003',master_log_pos='107'; start slave;
有时候master并不能让你锁住表进行复制,因为可能跑一些不间断的服务,如果这时master已经有了一个slave,我们则可以通过这个slave进行再次扩展一个新的slave。原理同在master上进行复制差不多,关键在于找到binlog的位置,你在复制的同时可能该slave也在和master进行同步,操作如下:
(1)为了防止数据变动,还是需要停止slave的同步:stop slave。
(2)然后刷新表,并用mysqldump逻辑备份数据库。
(3)使用show slave status查看slave的相关信息,记录下两个字段的值Relay_Master_Log_File和Exec_Master_Log_Pos,这个用来确定从后面哪里开始复制。
(4)对slave解锁,把备份的逻辑数据库导入新的slave的数据库中,然后设置change master to,这一步和复制master一样。
六、深入了解Mysql主从配置
1、一主多从
由一个master和一个slave组成复制系统是最简单的情况。Slave之间并不相互通信,只能与master进行通信。在实际应用场景中,MySQL复制90%以上都是一个Master复制到一个或者多个Slave的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。
在上图中,是我们开始时提到的一主多从的情况,这时主库既要负责写又要负责为几个从库提供二进制日志。这种情况将二进制日志只给某一从,这一从再开启二进制日志并将自己的二进制日志再发给其它从,或者是干脆这个从不记录只负责将二进制日志转发给其它从,这样架构起来性能可能要好得多,而且数据之间的延时应该也稍微要好一些。PS:这些前面都写过了,又复制了一遍。
2、主主复制
上图中,Master-Master复制的两台服务器,既是master,又是另一台服务器的slave。这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。在这种复制架构中,各自上运行的不是同一db,比如左边的是db1,右边的是db2,db1的从在右边反之db2的从在左边,两者互为主从,再辅助一些监控的服务还可以实现一定程度上的高可以用。
3、主动—被动模式的Master-Master(Master-Master in Active-Passive Mode)
上图中,这是由master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中只有一个节点在提供读写服务,另外一个节点时刻准备着,当主节点一旦故障马上接替服务。比如通过corosync+pacemaker+drbd+MySQL就可以提供这样一组高可用服务,主备模式下再跟着slave服务器,也可以实现读写分离。
4、带从服务器的Master-Master结构(Master-Master with Slaves)

Der Vorteil dieser Struktur besteht darin, dass sie Redundanz bietet. Bei einer geografisch verteilten Replikationsstruktur gibt es kein Problem mit dem Ausfall einzelner Knoten und es können auch leseintensive Anforderungen an den Slave gestellt werden.
5. MySQL-5.5 unterstützt die halbsynchrone Replikation
Frühere MySQL-Replikation konnte nur auf Basis der asynchronen Implementierung implementiert werden. Ab MySQL-5.5 wird die halbautomatische Replikation unterstützt. Bei der vorherigen asynchronen Replikation kontrollierte die Hauptdatenbank den Fortschritt der Standby-Datenbank nach der Ausführung einiger Transaktionen nicht. Wenn die Standby-Datenbank im Rückstand ist und die Hauptdatenbank leider abstürzt (z. B. aufgrund einer Ausfallzeit), sind die Daten in der Standby-Datenbank unvollständig. Kurz gesagt: Wenn die Hauptdatenbank ausfällt, können wir die Standby-Datenbank nicht verwenden, um weiterhin datenkonsistente Dienste bereitzustellen. Die halbsynchrone Replikation (halbsynchrone Replikation) garantiert bis zu einem gewissen Grad, dass die übermittelte Transaktion an mindestens eine Standby-Datenbank übertragen wurde. Im halbsynchronen Modus wird nur sichergestellt, dass die Transaktion an die Standby-Datenbank übermittelt wurde, nicht jedoch, dass sie in der Standby-Datenbank abgeschlossen wurde.
Darüber hinaus gibt es eine weitere Situation, die dazu führen kann, dass die Primär- und Sekundärdaten inkonsistent sind. In einer Sitzung wird nach der Übermittlung einer Transaktion an die Hauptdatenbank darauf gewartet, dass die Transaktion an mindestens eine Standby-Datenbank übertragen wird. Wenn die Hauptdatenbank während dieses Wartevorgangs abstürzt, sind die Standby-Datenbank und die Hauptdatenbank möglicherweise inkonsistent , was sehr tödlich ist. Wenn das aktive und das Standby-Netzwerk ausfallen oder die Standby-Datenbank ausgefallen ist, wartet die Primärdatenbank 10 Sekunden (der Standardwert von rpl_semi_sync_master_timeout), nachdem die Transaktion übermittelt wurde, bevor sie fortfährt. Zu diesem Zeitpunkt wechselt die Hauptbibliothek wieder in ihren ursprünglichen asynchronen Zustand.
Nachdem MySQL das Semi-Sync-Plug-in geladen und aktiviert hat, muss jede Transaktion warten, bis die Standby-Datenbank das Protokoll empfängt, bevor sie es an den Client zurückgibt. Wenn Sie eine kleine Transaktion durchführen und die Verzögerung zwischen den beiden Hosts gering ist, kann Semi-Sync bei geringem Leistungsverlust einen Datenverlust von null erreichen.
Das Obige ist der gesamte Inhalt dieses Artikels. Ich hoffe, er wird für das Studium aller hilfreich sein. Weitere spannende Inhalte finden Sie in den entsprechenden Tutorial-Kolumnen auf der chinesischen PHP-Website! ! !
Das obige ist der detaillierte Inhalt vonWas ist MySql-Master-Slave-Replikation? Wie konfiguriere ich die Implementierung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
Schritte zur Durchführung von SQL in Navicat: Verbindung zur Datenbank herstellen. Erstellen Sie ein SQL -Editorfenster. Schreiben Sie SQL -Abfragen oder Skripte. Klicken Sie auf die Schaltfläche Ausführen, um eine Abfrage oder ein Skript auszuführen. Zeigen Sie die Ergebnisse an (wenn die Abfrage ausgeführt wird).
