

Dieser Artikel bietet Ihnen eine detaillierte Einführung (Codebeispiel) über Multi-Table-Operationen in der Django-Modellebene. Ich hoffe, dass er für Sie hilfreich ist.
Erstellen Sie ein Modell
Die Beziehung zwischen Tabellen
Eins-zu-eins, viele-zu-eins, viele-zu-viele, Verwendung Denken Sie bei der Veröffentlichungstabelle über die Beziehung, die darin enthaltenen Operationen und den Unterschied zwischen dem Hinzufügen von Fremdschlüsseleinschränkungen und dem Nichthinzufügen von Fremdschlüsseleinschränkungen nach. Eine Eins-zu-Eins-Fremdschlüsseleinschränkung fügt einer Eins-zu-Eindeutigkeitseinschränkung hinzu -viele Einschränkungen.
Beispiel: Nehmen wir folgende Konzepte, Felder und Beziehungen an
Autorenmodell: Ein Autor hat einen Namen und ein Alter.
Detailliertes Modell des Autors: Geben Sie die Details des Autors in die Detailtabelle ein, einschließlich Geburtstag, Mobiltelefonnummer, Privatadresse und andere Informationen. Es besteht eine Eins-zu-Eins-Beziehung zwischen dem Modell für Autorendetails und dem Modell für Autoren
Verlegermodell: Der Herausgeber hat einen Namen, eine Stadt und eine E-Mail-Adresse.
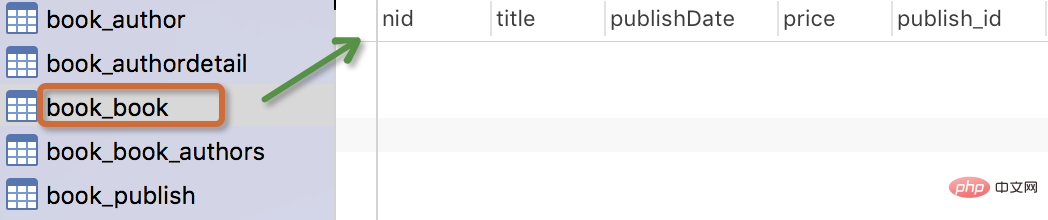
Buchmodell: Bücher haben Titel und Veröffentlichungsdaten, und ein Autor kann auch mehrere Bücher schreiben, sodass die Beziehung zwischen Autoren und Büchern eine Viele-zu-Viele-Beziehung ist (viele-). zu viele); ein Buch sollte nur von einem Verlag veröffentlicht werden, sodass Verlage und Bücher eine Eins-zu-viele-Beziehung (eins-zu-viele) haben.
Das Modell ist wie folgt aufgebaut:
from django.db import models
# Create your models here.
class Author(models.Model): #比较常用的信息放到这个表里面
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
age=models.IntegerField()
# 与AuthorDetail建立一对一的关系,一对一的这个关系字段写在两个表的任意一个表里面都可以
authorDetail=models.OneToOneField(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE) #就是foreignkey+unique,只不过不需要我们自己来写参数了,<br>并且orm会自动帮你给这个字段名字拼上一个_id,数据库中字段名称为authorDetail_id
class AuthorDetail(models.Model):#不常用的放到这个表里面
nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=64)
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField()
#多对多的表关系,我们学mysql的时候是怎么建立的,是不是手动创建一个第三张表,然后写上两个字段,每个字段外键关联到另外两张多对多关系的表,orm的manytomany自动帮我们创建第三张表,<br>两种方式建立关系都可以,以后的学习我们暂时用orm自动创建的第三张表,因为手动创建的第三张表我们进行orm操作的时候,很多关于多对多关系的表之间的orm语句方法无法使用
#如果你想删除某张表,你只需要将这个表注销掉,然后执行那两个数据库同步指令就可以了,自动就删除了。
class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
# 与Publish建立一对多的关系,外键字段建立在多的一方,字段publish如果是外键字段,那么它自动是int类型
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) #foreignkey里面可以加很多的参数,都是需要咱们学习的,慢慢来,to指向表,<br>to_field指向你关联的字段,不写这个,默认会自动关联主键字段,on_delete级联删除
字段名称不需要写成publish_id,orm在翻译foreignkey的时候会自动给你这个字段拼上一个_id,这个字段名称在数据库里面就自动变成了publish_id
# 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表,并且注意一点,你查看book表的时候,你看不到这个字段,因为这个字段就是创建第三<br>张表的意思,不是创建字段的意思,所以只能说这个book类里面有authors这个字段属性
authors=models.ManyToManyField(to='Author',) #注意不管是一对多还是多对多,写to这个参数的时候,最后后面的值是个字符串,不然你就需要将你要关联的那个表放到这个表的上面Über die drei Möglichkeiten, eine Viele-zu-Viele-Tabelle zu erstellen (im Moment erfahren Sie es zuerst)
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
# 自己创建第三张表,分别通过外键关联书和作者
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")Methode 2: Erstellen Sie automatisch die dritte Tabelle über ManyToManyField
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 通过ORM自带的ManyToManyField自动创建第三张表
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", related_name="authors")Methode 3 : Legen Sie ManyTomanyField fest und geben Sie die selbst erstellte dritte Tabelle an. Drei Tabellen
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 自己创建第三张表,并通过ManyToManyField指定关联
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", through="Author2Book", through_fields=("author", "book"))
# through_fields接受一个2元组('field1','field2'):
# 其中field1是定义ManyToManyField的模型外键的名(author),field2是关联目标模型(book)的外键名。
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")Hinweis:
Wenn wir zusätzliche Felder in der dritten relationalen Tabelle speichern müssen, müssen wir die dritte Methode verwenden .
Aber wenn wir die dritte Methode verwenden, um eine Viele-zu-Viele-Beziehung zu erstellen, können wir die von ORM bereitgestellten Methoden zum Festlegen, Hinzufügen, Entfernen und Löschen nicht verwenden, um die Viele-zu-Viele-Beziehung zu verwalten Sie müssen die dritte Methode verwenden, um die Viele-zu-Viele-Beziehung zu verwalten. Tabellenmodell, um Viele-zu-Viele-Beziehungen zu verwalten.
#创建一对一关系字段时的一些参数
to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
同ForeignKey字段。Einige Parameter beim Erstellen von Eins-zu-vielen-Beziehungsfeldern
to
设置要关联的表
to_field
设置要关联的表的字段
related_name
反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。
related_query_name
反向查询操作时,使用的连接前缀,用于替换表名。
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。Einige Parameter beim Erstellen von Viele-zu-vielen-Feldern
to
设置要关联的表
related_name
同ForeignKey字段。
related_query_name
同ForeignKey字段。
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。
through_fields 设置关联的字段。 db_table 默认创建第三张表时,数据库中表的名称。Einige Metainformationseinstellungen beim Erstellen von Tabellen
元信息
ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下:
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
db_table
ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。
index_together
联合索引。
unique_together
联合唯一索引。
ordering
指定默认按什么字段排序。
只有设置了该属性,我们查询到的结果才可以被reverse()。Nachdem wir diese Tabelle erstellt haben, können wir das Navicat-Tool verwenden, um die Tabellen in der Datenbank anzuzeigen. Für diese Art von Einzeltabellendaten können wir zunächst eine hinzufügen einige Daten und führen Sie die folgenden Vorgänge zum Hinzufügen, Löschen, Ändern und Überprüfen durch.
Die generierte Tabelle sieht wie folgt aus:
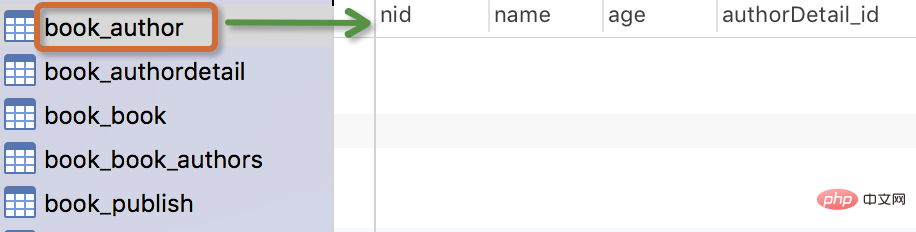

🎜>
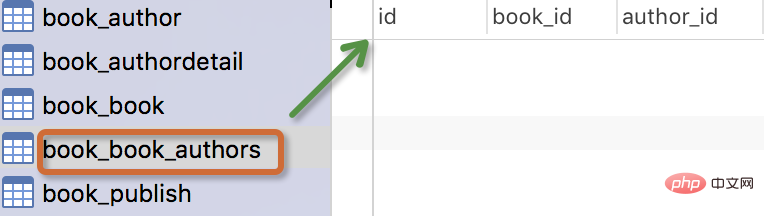 Hinweis:
Hinweis:
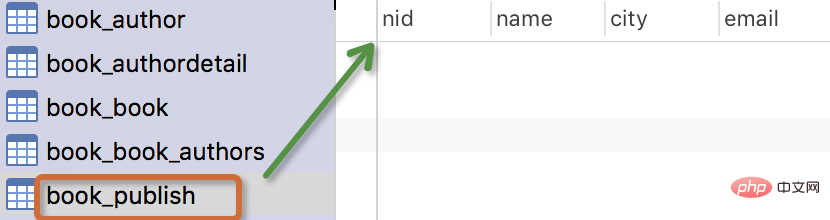
wird automatisch basierend auf den Metadaten im Modell generiert und kann auch als anderer Name überschrieben werden
myapp_modelNameFür Fremdschlüsselfelder fügt Django idCREATE TABLEDas Fremdschlüsselfeld ForeignKey hat die Einstellung null=True (wodurch der Fremdschlüssel den Nullwert NULL akzeptieren kann), und Sie können ihm den Nullwert None zuweisen. models.pyUnsere Tabelle enthält Eins-zu-Eins-, Eins-zu-Viele- und Viele-zu-Viele-Beziehungen. Egal wie viele Tabellen es in Zukunft gibt. Wir werden diesen drei Beziehungen nicht entkommen können. Die Funktionsweise dieser Beziehung ist dieselbe. on_delete 当删除关联表中的数据时,当前表与其关联的行的行为。 models.CASCADE 删除关联数据,与之关联也删除 models.DO_NOTHING 删除关联数据,引发错误IntegrityError models.PROTECT 删除关联数据,引发错误ProtectedError models.SET_NULL 删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空) models.SET_DEFAULT 删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值) models.SET 删除关联数据, a. 与之关联的值设置为指定值,设置:models.SET(值) b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
Geben Sie vor dem Vorgang einfach einige Daten ein: Es gibt noch zwei Methoden: Erstellen und Speichern , und single Der Unterschied zwischen den Tabellen besteht darin, zu sehen, wie die Daten der zugehörigen Felder hinzugefügt werden
Tabelle veröffentlichen: 
author表:
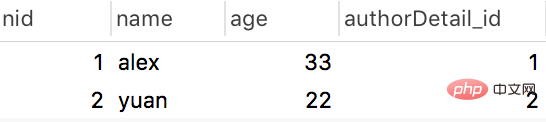
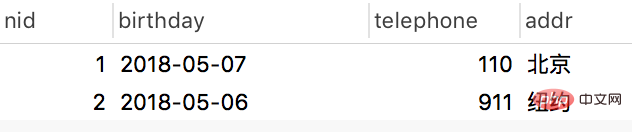
authordetail表:
一对多
方式1: publish_obj=Publish.objects.get(nid=1) #拿到nid为1的出版社对象 book_obj=Book.objects.create(title="金瓶煤",publishDate="2012-12-12",price=100,publish=publish_obj) #出版社对象作为值给publish,其实就是自动将publish字段<br>变成publish_id,然后将publish_obj的id给取出来赋值给publish_id字段,注意你如果不是publish类的对象肯定会报错的,别乱昂 方式2: book_obj=Book.objects.create(title="金瓶煤",publishDate="2012-12-12",price=100,publish_id=1) #直接可以写id值,注意字段属性的写法和上面不同,这个是<br>publish_id=xxx,上面是publish=xxx。

核心:book_obj.publish与book_obj.publish_id是什么?
一对多的删改和单表的删改是一样的,别忘了删除表的时候,咱们是做了级联删除的。
多对多
方式一: 多对多一般在前端页面上使用的时候是多选下拉框的样子来给用户选择多个数据,这里可以让用户选择多个书籍,多个作者
# 当前生成的书籍对象
book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1)
# 为书籍绑定的作者对象
yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录,注意取的是author的model对象
egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录
#有人可能会说,我们可以直接给第三张表添加数据啊,这个自动生成的第三张表你能通过models获取到吗,是获取不到的,用不了的,当然如果你知道了这个表的名字,那么你通过原生sql语句<br>可以进行书的添加,所以要通过orm间接的给第三张表添加数据,如果是你手动添加的第三张表你是可以直接给第三张表添加数据
# 绑定多对多关系,即向关系表book_authors中添加纪录,给书添加两个作者,下面的语法就是告诉orm给第三张表添加两条数据
book_obj.authors.add(yuan,egon) # 将某些特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[])
#book_obj是书籍对象,authors是book表里面那个多对多的关系字段名称。
#其实orm就是先通过book_obj的authors属性找到第三张表,然后将book_obj的id值和两个作者对象的id值组合成两条记录添加到第三张表里面去
方式二
book_obj.authors.add(1,2)
book_obj.authors.add(*[1,2]) #这种方式用的最多,因为一般是给用户来选择,用户选择是多选的,选完给你发送过来的就是一堆的id值数据库表纪录生成如下:
book表

book_authors表
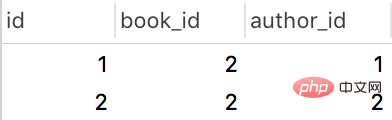
核心:book_obj.authors.all()是什么?
多对多关系其它常用API:
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[1,2]),将多对多的关系数据删除 book_obj.authors.clear() #清空被关联对象集合 book_obj.authors.set() #先清空再设置 =====
删除示例:
book_obj = models.Book.objects.filter(nid=4)[0] # book_obj.authors.remove(2) #将第三张表中的这个book_obj对象对应的那个作者id为2的那条记录删除 # book_obj.authors.clear() # book_obj.authors.set('2') #先清除掉所有的关系数据,然后只给这个书对象绑定这个id为2的作者,所以只剩下一条记录 3---2,比如用户编辑数据的时候,选择作者发生了变化,<br>那么需要重新选择,所以我们就可以先清空,然后再重新绑定关系数据,注意这里写的是字符串,数字类型不可以 book_obj.authors.set(*['1',]) #这么写也可以,但是注意列表中的元素是字符串
三 基于对象的跨表查询
跨表查询是分组查询的基础,F和Q查询是最简单的,所以认真学习跨表查询
一对多查询(Publish 与 Book)

正向查询(按字段:publish):关联属性字段所在的表查询被关联表的记录就是正向查询,反之就是反向查询
# 查询主键为1的书籍的出版社所在的城市 book_obj=Book.objects.filter(pk=1).first() # book_obj.publish 是主键为1的书籍对象关联的出版社对象,book对象.外键字段名称 print(book_obj.publish.city)
反向查询(按表名:book_set,因为加上_set是因为反向查询的时候,你查询出来的可能是多条记录的集合):
publish=Publish.objects.get(name="苹果出版社")
#publish.book_set.all() : 与苹果出版社关联的所有书籍对象集合,写法:小写的表名_set.all(),得到queryset类型数据
book_list=publish.book_set.all()
for book_obj in book_list:
print(book_obj.title)一对一查询(Author与AuthorDetail)

正向查询(按字段:authorDetail):
egon=Author.objects.filter(name="egon").first() print(egon.authorDetail.telephone) egon.authorDeail就拿到了这个对象,因为一对一找到的就是一条记录,注意写法:作者对象.字段名,就拿到了那个关联对象
反向查询(按表名:author):不需要_set,因为一对一正向反向都是找到一条记录
# 查询所有住址在北京的作者的姓名 authorDet=AuthorDetail.objects.filter(addr="beijing")[0] authorDet.author.name
多对多查询(Author与Book)

正向查询(按字段:authors):
# 金瓶煤所有作者的名字以及手机号
book_obj=Book.objects.filter(title="金瓶煤").first()
authors=book_obj.authors.all()
for author_obj in authors:
print(author_obj.name,author_obj.authorDetail.telephone)反向查询(按表名:book_set):
# 查询egon出过的所有书籍的名字
author_obj=Author.objects.get(name="egon")
book_list=author_obj.book_set.all() #与egon作者相关的所有书籍
for book_obj in book_list:
print(book_obj.title)注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改:
publish = ForeignKey(Book, related_name='bookList')
那么接下来就会如我们看到这般:
# 查询 人民出版社出版过的所有书籍 publish=Publish.objects.get(name="人民出版社") book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合
在这里我们补充一点,因为你很快就要接触到了,那就是form表单里面的button按钮和form表单外面的button按钮的区别,form表单里面的button按钮其实和input type='submit'的标签是有同样的效果的,都能够提交form表单的数据,但是如果放在form表单外面的button按钮,那就只是个普通的按钮了。,还有一点,input type='submit'按钮放到form表单外面那就成了一个普通的按钮。
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
''' 基于双下划线的查询就一句话:正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表,一对一、一对多、多对多都是一个写法,注意,我们写orm查询的时候,哪个表在前哪个表在后<br>都没问题,因为走的是join连表操作。 '''
一对多查询
# 例: 查询苹果出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects
.filter(publish__name="苹果出版社") #通过__告诉orm将book表和publish表进行join,然后找到所有记录中publish.name='苹果出版社'的记录<br>(注意publish是属性名称),然后select book.title,book.price的字段值
.values_list("title","price") #values或者values_list
# 反向查询 按表名:book
queryResult=Publish.objects
.filter(name="苹果出版社")
.values_list("book__title","book__price")多对多查询
# 例: 查询yuan出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects
.filter(authors__name="yuan")
.values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects
.filter(name="yuan")
.values_list("book__title","book__price")一对一查询
# 查询yuan的手机号
# 正向查询
ret=Author.objects.filter(name="yuan").values("authordetail__telephone")
# 反向查询
ret=AuthorDetail.objects.filter(author__name="yuan").values("telephone")五 聚合查询、分组查询、F查询和Q查询
聚合
aggregate(*args, **kwargs)
# 计算所有图书的平均价格
>>> from django.db.models import Avg
>>> Book.objects.all().aggregate(Avg('price')) #或者给它起名字:aggretate(a=Avg('price'))
{'price__avg': 34.35}aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
>>> Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 34.35}如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> from django.db.models import Avg, Max, Min
>>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) #count('id'),count(1)也可以统计个数,Book.objects.all().aggregete和Book.objects.<br> aggregate(),都可以
{'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}分组
###################################--单表分组查询--#######################################################
查询每一个部门名称以及对应的员工数
emp:
id name age salary dep
1 alex 12 2000 销售部
2 egon 22 3000 人事部
3 wen 22 5000 人事部
sql语句:
select dep,Count(*) from emp group by dep;
ORM:
emp.objects.values("dep").annotate(c=Count("id") #注意:annotate里面必须写个聚合函数,不然没有意义,并且必须有个别名=,别名随便写,但是必须有,用哪个字段分组,<br>values里面就写哪个字段,annotate其实就是对分组结果的统计,统计你需要什么。
'''
select dep,count('id') as c from emp grouby dep; #原生sql语句中的as c,不是必须有的
'''
###################################--多表分组查询--###########################
多表分组查询:
查询每一个部门名称以及对应的员工数
emp:
id name age salary dep_id
1 alex 12 2000 1
2 egon 22 3000 2
3 wen 22 5000 2
dep
id name
1 销售部
2 人事部
emp-dep:
id name age salary dep_id id name
1 alex 12 2000 1 1 销售部
2 egon 22 3000 2 2 人事部
3 wen 22 5000 2 2 人事部
sql语句:
select dep.name,Count(*) from emp left join dep on emp.dep_id=dep.id group by dep.id
ORM:
dep.objetcs.values("id").annotate(c=Count("emp")).values("name","c")
ret = models.Emp.objects.values('dep_id','name').annotate(a=Count(1))
'''
SELECT `app01_emp`.`dep_id`, `app01_emp`.`name`, COUNT(1) AS `a` FROM `app01_emp` GROUP BY `app01_emp`.`dep_id`, `app01_emp`.`name`
'''
#<QuerySet [{'dep_id': 1, 'name': 'alex', 'a': 1}, {'dep_id': 2, 'name': 'egon', 'a': 1}, {'dep_id': 2, 'name': 'wen', 'a': 1}]>,注意,这里如果你写了其他<br>字段,那么只有这两个字段重复,才算一组,合并到一起来统计个数class Emp(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
salary=models.DecimalField(max_digits=8,decimal_places=2)
dep=models.CharField(max_length=32)
province=models.CharField(max_length=32)annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询,,既然是join连表,就可以使用咱们的双下划线进行连表了。
#单表:
#查询每一个部门的id以及对应员工的平均薪水
ret = models.Emp.objects.values('dep_id').annotate(s=Avg('salary'))
#查询每个部门的id以及对对应的员工的最大年龄
ret = models.Emp.objects.values('dep_id').annotate(a=Max('age'))
#Emp表示表,values中的字段表示按照哪个字段group by,annotate里面是显示分组统计的是什么
#连表:
# 查询每个部门的名称以及对应的员工个数和员工最大年龄
ret = models.Emp.objects.values('dep__name').annotate(a=Count('id'),b=Max('age')) #注意,正向与反向的结果可能不同,如果反向查的时候,有的部门还没有员工,<br>那么他的数据也会被统计出来,只不过值为0,但是正向查的话只能统计出来有员工的部门的相关数据,因为通过你是员工找部门,而不是通过部门找员工,结果集里面的数据个数不同,但是你想要的统计<br>结果是一样的
#<QuerySet [{'a': 1, 'dep__name': '销售部', 'b': 12}, {'a': 3, 'dep__name': '人事部', 'b': 22}]>
#使用双下划线进行连表,然后按照部门名称进行分组,然后统计员工个数和最大年龄,最后结果里面显示的是部门名称、个数、最大年龄。
#注意:如果values里面有多个字段的情况:
ret = models.Emp.objects.values('dep__name','age').annotate(a=Count('id'),b=Max('age')) #是按照values里面的两个字段进行分组,两个字段同时相同才算是一组,<br>看下面的sql语句
'''
SELECT `app01_dep`.`name`, `app01_emp`.`age`, COUNT(`app01_emp`.`id`) AS `a`, MAX(`app01_emp`.`age`) AS `b` FROM `app01_emp` INNER JOIN `app01_dep`<br> ON (`app01_emp`.`dep_id` = `app01_dep`.`id`) GROUP BY `app01_dep`.`name`, `app01_emp`.`age`;
'''下面是书籍表和出版社表的一个连表分组的sql语句写法:
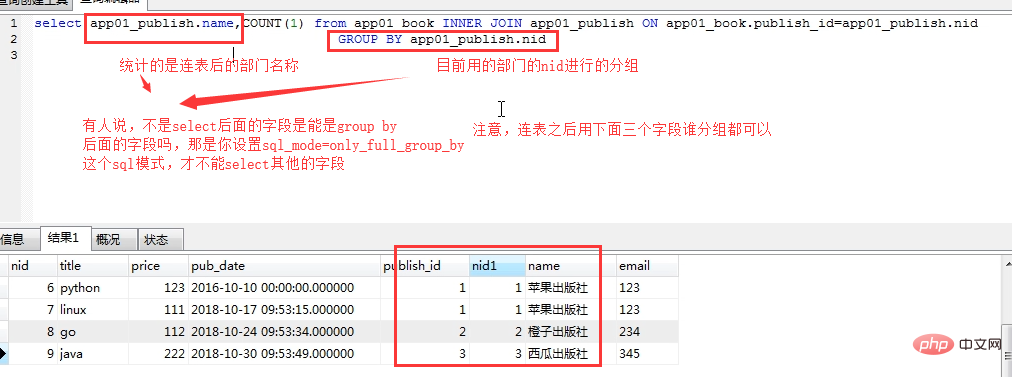
F查询与Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?我们在book表里面加上两个字段:评论数:commentNum,收藏数:KeepNum
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
# 查询评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commentNum__gt=F('keepNum'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
# 查询评论数大于收藏数2倍的书籍
Book.objects.filter(commentNum__gt=F('keepNum')*2)修改操作也可以使用F函数,比如将每一本书的价格提高30元:
Book.objects.all().update(price=F("price")+30)Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
from django.db.models import Q Q(title__startswith='Py')
Q 对象可以使用&(与) 、|(或)、~(非) 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon"))
等同于下面的SQL WHERE 子句:
WHERE name ="yuan" OR name ="egon"
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title")
bookList=Book.objects.filter(Q(Q(authors__name="yuan") & ~Q(publishDate__year=2017))&Q(id__gt=6)).values_list("title") #可以进行Q嵌套,多层Q嵌套等,<br>其实工作中比较常用查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017),
title__icontains="python" #也是and的关系,但是Q必须写在前面
)六 Python脚本中调用Django环境(django外部脚本使用models)
如果你想通过自己创建的python文件在django项目中使用django的models,那么就需要调用django的环境:
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup()
from app01 import models #引入也要写在上面三句之后
books = models.Book.objects.all()
print(booksDas obige ist der detaillierte Inhalt vonDetaillierte Einführung in Multi-Table-Operationen in der Django-Modellebene (Codebeispiel). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So lösen Sie das Problem der fehlenden ssleay32.dll
So lösen Sie das Problem der fehlenden ssleay32.dll
 So öffnen Sie das Terminalfenster in vscode
So öffnen Sie das Terminalfenster in vscode
 Ist A5-Papier größer oder B5-Papier größer?
Ist A5-Papier größer oder B5-Papier größer?
 Die Rolle der Parseint-Funktion
Die Rolle der Parseint-Funktion
 Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen
Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen
 So definieren Sie ein Array
So definieren Sie ein Array
 Wie viel entspricht Snapdragon 8gen2 Apple?
Wie viel entspricht Snapdragon 8gen2 Apple?
 Fil-Währungspreis Echtzeitpreis
Fil-Währungspreis Echtzeitpreis
 Schritte zur SpringBoot-Projekterstellung
Schritte zur SpringBoot-Projekterstellung









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



