

Dieser Artikel bietet Ihnen eine Einführung in die Verwendung von Jsoup zur Implementierung der Crawler-Technologie. Ich hoffe, dass er für Freunde in Not hilfreich ist.
1. Kurze Beschreibung von Jsoup
In Java werden viele Crawler-Frameworks unterstützt, z. B. WebMagic, Spider, Jsoup, usw. Heute verwenden wir Jsoup, um ein einfaches Crawler-Programm zu implementieren.
Jsoup verfügt über eine sehr praktische API zum Verarbeiten von HTML-Dokumenten, z. B. zum Verweisen auf die Dokumentdurchlaufmethode von DOM-Objekten, zum Verweisen auf die Verwendung von CSS-Selektoren usw., sodass wir Jsoup verwenden können, um das Crawlen von Seitendaten schnell zu beherrschen .
2. Schnellstart
1) HTML-Seite schreiben

Die Produktinformationen der Tabelle in der Die Seite gehört uns. Die zu crawlenden Daten. Zu den Attributen gehören der Produktname der pname-Klasse und die Produktbilder der pimg-Klasse.
2) Verwenden Sie HttpClient zum Lesen von HTML-Seiten
HttpClient ist ein Tool zur Verarbeitung von HTTP-Protokolldaten. Es kann zum Einlesen von HTML-Seiten in Java-Programme als Eingabestreams verwendet werden. Sie können das HttpClient-JAR-Paket von http://hc.apache.org/ herunterladen.

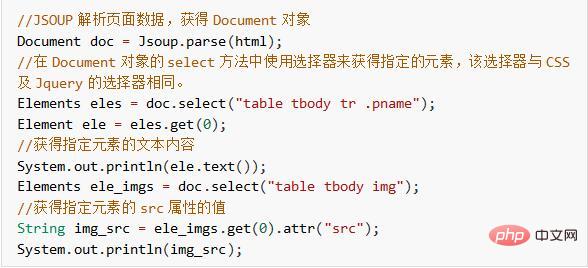
3) Verwenden Sie Jsoup, um eine HTML-Zeichenfolge zu analysieren.
Wird durch Einführung des Jsoup-Tools und direkten Aufruf der Parse-Methode erhalten, um eine Zeichenfolge zu analysieren, die den Inhalt der Datei beschreibt HTML-Seite Ein Document-Objekt. Das Document-Objekt ruft den angegebenen Inhalt auf der HTML-Seite ab, indem es den DOM-Baum bedient. Informationen zu verwandten APIs finden Sie in der offiziellen Dokumentation von Jsoup: https://jsoup.org/cookbook/
Nachfolgend verwenden wir Jsoup, um den im obigen HTML angegebenen Produktnamen und die Preisinformationen zu erhalten.
Bisher haben wir die Funktion implementiert, HttpClient+Jsoup zum Crawlen von HTML-Seitendaten zu verwenden. Als Nächstes machen wir den Effekt intuitiver, indem wir beispielsweise die gecrawlten Daten in der Datenbank und die Bilder auf dem Server speichern.
3. Speichern Sie die gecrawlten Seitendaten
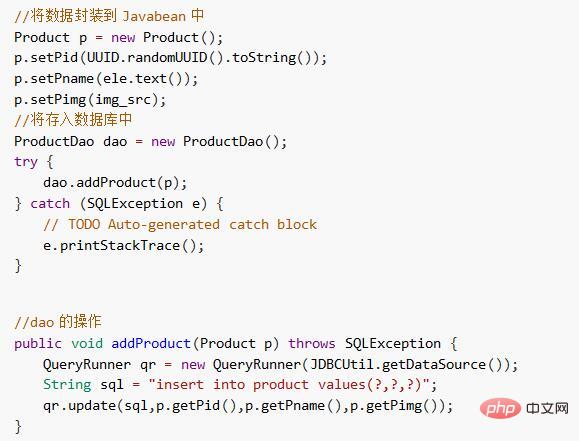
1) Speichern Sie gewöhnliche Daten in der Datenbank
Kapseln Sie die gecrawlten Daten in Entity-Beans und speichern Sie sie in die Datenbank.
2) Speichern Sie das Bild auf dem Server
Speichern Sie das Bild lokal auf dem Server, indem Sie das Bild direkt herunterladen.

4. Zusammenfassung
In diesem Fall wird lediglich die Verwendung von HttpClient+Jsoup zum Crawlen von Netzwerkdaten für die Crawler-Technologie selbst implementiert , Es gibt viele Orte, an denen es sich zu vertiefen lohnt, die ich Ihnen später erklären werde.
Das obige ist der detaillierte Inhalt vonEinführung in die Methode zur Verwendung von Jsoup zur Implementierung der Crawler-Technologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So fügen Sie Audio in ppt ein
So fügen Sie Audio in ppt ein
 Detaillierte Erläuterung der Verwendung der Sprintf-Funktion
Detaillierte Erläuterung der Verwendung der Sprintf-Funktion
 PDF- ins XML-Format
PDF- ins XML-Format
 Was führt dazu, dass der Computerbildschirm gelb wird?
Was führt dazu, dass der Computerbildschirm gelb wird?
 Funktionen des Raysource-Download-Tools
Funktionen des Raysource-Download-Tools
 ETH-Währungspreis heutiger Marktpreis USD
ETH-Währungspreis heutiger Marktpreis USD
 WeChat-Schritte
WeChat-Schritte
 Anrufwarnung des Nationalen Zentrums für Betrugsbekämpfung
Anrufwarnung des Nationalen Zentrums für Betrugsbekämpfung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



