

So implementieren Sie mit Java eine P2P-Seed-Suchfunktion

Der Inhalt dieses Artikels befasst sich mit der Verwendung von Java zur Implementierung einer P2P-Seed-Suchfunktion. Ich hoffe, dass er für Freunde in Not hilfreich ist.
Ich hatte vor vielen Jahren großes Interesse an P2P, aber es blieb in der Theorie und hatte nie die Gelegenheit, es in die Praxis umzusetzen. Ich habe dieses Ding kürzlich implementiert. Ich denke, es gibt einige Dinge, die ich teilen kann. Kommen wir zum Punkt
Grundkonzepte
Bevor ich über P2P spreche, möchte ich darüber sprechen, wie wir Dateien herunterladen. Lassen Sie mich mehrere Möglichkeiten zum Herunterladen von Dateien auflisten
1. Verwenden Sie zum Herunterladen das http-Protokoll. Die am häufigsten verwendete Methode ist wahrscheinlich das Herunterladen von Dateien über einen Browser.
2. Zum Herunterladen gibt es zwei Modi: Port (aktiv) In diesem Modus öffnet der Client lokal eine FTP-Verbindung und dann senden Geben Sie dem FTP-Server N+1-Abhörport für die Datenübertragung. Wenn eine Firewall vorhanden ist oder der Client NAT ist, kann er nicht heruntergeladen werden. Eine andere Möglichkeit ist der passive Modus. In diesem Modus öffnet der FTP-Server zusätzlich zu Port 21 einen weiteren Port größer als 1023. Das heißt, der Client initiiert aktiv FTP-Verbindungen und Datenübertragungsverbindungen, solange der FTP-Server vorhanden ist ist offen. Es wird kein Problem mit diesem Port geben.
Die beiden oben genannten Methoden können zusammen als CS-Architektur bezeichnet werden. Bei dieser Architektur werden Ressourcen auf den Server konzentriert, wenn die Datenmenge ein bestimmtes Niveau erreicht. Um dieses Problem zu lösen, können wir an eine verteilte Dezentralisierung denken. P2P steht für Peer-to-Peer. Dabei handelt es sich um eine Peer-to-Peer-Architektur.
P2P-Architektur
Wenn Ressourcen auf jedem Knoten gespeichert sind, fragen wir uns möglicherweise: Wenn ich eine Ressource herunterlade, woher weiß ich, auf welchen Computern sich diese Datei befindet? Kann sie heruntergeladen werden?
In der frühen P2P-Architektur gab es eine Tracker-Rolle, die für die Speicherung von Metadateninformationen von Dateien verantwortlich war. Jetzt wird die Datei auf jedem Peer gespeichert und die Dateiinformationen werden über den Tracker abgerufen.
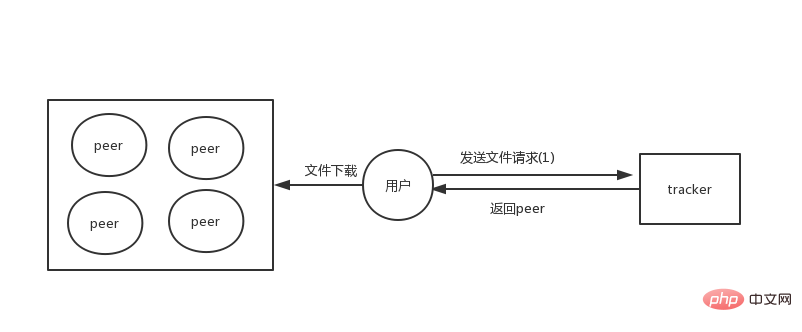
Unter dieser Architektur werden alle unsere Dateien verteilt, aber der Tracker ist für die Speicherung der Metadateninformationen aller Dateien verantwortlich, sodass der Tracker nur eine kleine Menge speichern muss von Daten im Vergleich zu vorhandenen Dateien wird relativ einfach sein.
Aber sobald der Tracker-Server hängt oder der Dienst nicht verfügbar ist, werden nicht alle Dateien heruntergeladen, da er nicht vollständig verteilt ist. Um vollständig dezentralisiert zu sein, wird später eine Tracker-lose Architektur entwickelt
Zu diesem Zeitpunkt existiert der Tracker nicht mehr und alle Dateien, einschließlich der Metadateninformationen der Dateien, werden verteilt gespeichert. DHTDHT (Distributed Hash Table) verteilte Hash-Tabelle, die als Ersatz für den Tracker verwendet wird. Es gibt viele Algorithmen zur Implementierung von DHT, wie zum Beispiel denKademlia-Algorithmus und so weiter.
Einige Konzepte:
3.Routing-Tabelle Routing-Tabelle
Der Schwerpunkt liegt hier auf der Implementierung, daher gibt es im Internet viele Informationen zum Hauptteil. Sie können sich auf
Wie man es implementiert
Es gibt zwei Schritte zur Implementierung der Seed-Suche. Der erste Schritt ist ein Crawler, der zum Crawlen von Seed-Informationen im Internet verwendet wird. Der zweite Schritt besteht darin, sich an der Suche zu beteiligen. Sie müssen über folgende Kenntnisse verfügen: Seeds, BitTorrent-DHT-Protokoll, BencodedWenn es um P2P geht, müssen wir Seeds erwähnen, also die Art von Dateien, die das Ergebnis sind .torrent. Jeder hat möglicherweise BT-Torrents verwendet, die Dateien heruntergeladen haben, und die heruntergeladenen Dateien verwenden das Bittorrent-Protokoll. Wie sammelt man Samen im Internet? Die in BT-Seeds enthaltenen Hauptfelder: https://segmentfault.com/a/1190000000681331Die in DHT erhaltenen Seeds werden als „Trackerless Torrent“ bezeichnet. Es gibt kein Ankündigungsattribut, aber es gibt stattdessen das nodes-Attribut. Es wird offiziell empfohlen, router.bittorrent.com nicht zum Seed oder zur Routing-Tabelle hinzuzufügen. 1.So erhalten Sie Samen von DHT
Wenn Sie die Sameninformationen erhalten möchten, müssen Sie über ein umfassendes Verständnis des DHT-Protokolls verfügen das DHT-Protokoll
Weitere Informationen finden Sie hier: http://www.bittorrent.org/beps/bep_0005.html
So implementieren Sie eine Routing-Tabelle:
Die Routing-Tabelle deckt alle Node-IDs ab, von 0 bis 2 hoch 160. Die Routing-Tabelle kann aus Buckets bestehen, und jeder Bucket deckt einen Teil aller Knoten ab. Zu Beginn gibt es nur einen Bucket in der Routing-Tabelle, der alle Nodeids abdeckt. Jeder Bucket kann nur bis zu K Knoten enthalten. Der aktuelle K-Wert beträgt 8. Wenn der Bucket voll ist und alle darin enthaltenen Knoten in Ordnung sind und sich die eigene Knoten-ID nicht in diesem Bucket befindet, wird der ursprüngliche Bucket in zwei neue Buckets aufgeteilt, die 0..2159
und 2 abdecken159..2160.
Wenn ein Bucket voll ist, werden neue Knoten leicht verworfen. Wenn ein Knoten darin offline geht, wird er ersetzt. Wenn ein Knoten in den letzten 15 Minuten nicht angepingt wurde, pingen Sie den Knoten an. Wenn keine Antwort zurückgegeben wird, wird der Knoten ebenfalls ersetzt.
Jeder Bucket sollte ein zuletzt geändertes Attribut haben, um die Aktivität dieses Buckets anzuzeigen. Dieses Feld wird in den folgenden Situationen aktualisiert:
1. Der Knoten im Bucket wird angepingt und hat eine Antwort
2. Ein Knoten wird zu diesem Bucket hinzugefügt
3 . Der Knoten im Bucket wurde ersetzt
Wenn der Bucket dieses Feld nicht innerhalb von 15 Minuten aktualisiert, wird eine ID innerhalb des Bucket-Bereichs zufällig ausgewählt, um die Operation „find_node“ auszuführen.
KRPC-Protokoll
Das KRPC-Protokoll wird zur Übertragung von Nachrichten im dht-Netzwerk verwendet.
1.ping
Ping-Abfrage wird hauptsächlich zur Heartbeat-Überprüfung verwendet
2.find_node
Suche Nach einem Knoten fragt die andere Partei die nächsten N Knoten ab und gibt sie aus ihrer eigenen Routing-Tabelle zurück, normalerweise 8
3.get_peers
finde den Besitzer von Der Infohash basiert auf dem Infohash-Peer. Wenn die zurückgegebenen Peers und keine Knoten gefunden werden, teilt return nodes
anderen Peers dies mit Sie haben auch Infohash.
Beachten Sie, dass die oben genannten vier die Routing-Tabelle aktualisieren
Zu Beginn gibt es keine Knoten in der Routing-Tabelle Sie müssen vom Superknoten aus beginnen (z. B. usw.), um Knoten über find_node-Anfragen zu finden und hinzuzufügen, und die zurückgegebenen Knoten werden für find_node verwendet.
Die Routing-Tabelle, die ich selbst implementiert habe, unterscheidet sich geringfügig von der oben beschriebenen. dht.transmissionbt.com
Wenn wir dem DHT-Netzwerk beitreten, können wir den Infohash der Seed-Datei nur über die vier oben vorgestellten Methoden abrufen, daher müssen wir den Seed auch über den Infohash herunterladen , siehe bep_009http://www.bittorrent.org/beps/bep_0009.html
Wir verwenden hauptsächlich bep_009, um das Namensfeld des Torrents abzurufen. Nachdem wir das Dateinamenfeld erhalten haben, können wir einen Index erstellen basierend auf dem Namen und dem Infohash, um eine Suche bereitzustellen. (Hier erstellen wir hauptsächlich Magnet-Links. Mit Magnet-Links können Sie zu Thunder, Baidu Netdisk usw. gehen, um Ressourcen herunterzuladen
)Die meisten Magnet-Link-Formate: magnet:?xt=urn : btih:infohash
Die oben vorgestellte Methode besteht darin, einen Magnet-Link zu erstellen, indem man Infohash erhält und ihn dann mithilfe von Software von Drittanbietern herunterlädt. Natürlich können Sie ihn auch selbst über das BitTorrent-Protokoll herunterladen. Wenn Sie interessiert sind, können Sie selbst recherchieren. Okay, das Obige stellt nur kurz einige Implementierungsschritte vor. In meinen eigenen Worten habe ich auf einige Github-DHT-Projekte verwiesen und sie dann selbst implementiert :https://github.com/mistletoe9527/dht-spiderDas obige ist der detaillierte Inhalt vonSo implementieren Sie mit Java eine P2P-Seed-Suchfunktion. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1383
1383
 52
52

 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Kapseln sind dreidimensionale geometrische Figuren, die aus einem Zylinder und einer Hemisphäre an beiden Enden bestehen. Das Volumen der Kapsel kann berechnet werden, indem das Volumen des Zylinders und das Volumen der Hemisphäre an beiden Enden hinzugefügt werden. In diesem Tutorial wird erörtert, wie das Volumen einer bestimmten Kapsel in Java mit verschiedenen Methoden berechnet wird. Kapselvolumenformel Die Formel für das Kapselvolumen lautet wie folgt: Kapselvolumen = zylindrisches Volumenvolumen Zwei Hemisphäre Volumen In, R: Der Radius der Hemisphäre. H: Die Höhe des Zylinders (ohne die Hemisphäre). Beispiel 1 eingeben Radius = 5 Einheiten Höhe = 10 Einheiten Ausgabe Volumen = 1570,8 Kubikeinheiten erklären Berechnen Sie das Volumen mithilfe der Formel: Volumen = π × R2 × H (4
 Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Spring Boot vereinfacht die Schaffung robuster, skalierbarer und produktionsbereiteter Java-Anwendungen, wodurch die Java-Entwicklung revolutioniert wird. Der Ansatz "Übereinkommen über Konfiguration", der dem Feder -Ökosystem inhärent ist, minimiert das manuelle Setup, Allo
