
 Backend-Entwicklung
C#.Net-Tutorial
Grafisches Durchlaufen der Ebenenreihenfolge in C++ und schichtweises Drucken von Binärbäumen, die durch intelligente Zeiger erstellt wurden
Backend-Entwicklung
C#.Net-Tutorial
Grafisches Durchlaufen der Ebenenreihenfolge in C++ und schichtweises Drucken von Binärbäumen, die durch intelligente Zeiger erstellt wurden
Grafisches Durchlaufen der Ebenenreihenfolge in C++ und schichtweises Drucken von Binärbäumen, die durch intelligente Zeiger erstellt wurden

Binärbäume sind eine äußerst verbreitete Datenstruktur und es gibt unzählige Artikel darüber, wie man ihre Elemente durchquert. In den meisten Artikeln wird jedoch das Durchqueren von Vorbestellungen, Zwischenbestellungen und Nachbestellungen erläutert. Es gibt nicht viele Artikel zum schichtweisen Drucken von Elementen. Die Erklärungen in vorhandenen Artikeln sind ebenfalls relativ unklar und schwer zu lesen. In diesem Artikel werden anschauliche Bilder und klarer Code verwendet, um Ihnen das Verständnis der Implementierung des Level-Order-Traversals zu erleichtern. Gleichzeitig verwenden wir intelligente Zeiger, die von modernem C++ bereitgestellt werden, um die Ressourcenverwaltung von Baumdatenstrukturen zu vereinfachen.
Verwandte Tutorials: Tutorial zum Datenstrukturbaum
Kommen wir nun zum Punkt.
Konstruieren Sie einen Binärbaum mit intelligenten Zeigern
Was wir hier implementieren möchten, ist ein Binärbaum, der einfach einen binären Suchbaum simuliert und eine Einfügefunktion bereitstellt, die die Anforderungen eines binären Suchbaums erfüllt , einschließlich In-Order-Traversal. Gleichzeitig verwenden wir shared_ptr, um Ressourcen zu verwalten.
Jetzt implementieren wir nur zwei Methoden: insert und ldr Die Implementierung der anderen Methoden ist nicht das, worum es in diesem Artikel geht, aber wir werden sie in den folgenden Artikeln einzeln vorstellen:
struct BinaryTreeNode: public std::enable_shared_from_this<BinaryTreeNode> {
explicit BinaryTreeNode(const int value = 0)
: value_{value}, left{std::shared_ptr<BinaryTreeNode>{}}, right{std::shared_ptr<BinaryTreeNode>{}}
{}
void insert(const int value)
{
if (value < value_) {
if (left) {
left->insert(value);
} else {
left = std::make_shared<BinaryTreeNode>(value);
}
}
if (value > value_) {
if (right) {
right->insert(value);
} else {
right = std::make_shared<BinaryTreeNode>(value);
}
}
}
// 中序遍历
void ldr()
{
if (left) {
left->ldr();
}
std::cout << value_ << "\n";
if (right) {
right->ldr();
}
}
// 分层打印
void layer_print();
int value_;
// 左右子节点
std::shared_ptr<BinaryTreeNode> left;
std::shared_ptr<BinaryTreeNode> right;
private:
// 层序遍历
std::vector<std::shared_ptr<BinaryTreeNode>> layer_contents();
};Unser Knotenobjekt erbt von enable_shared_from_this, normalerweise ist dies nicht notwendig, aber um den Betrieb während der Durchquerung der Ebenenreihenfolge zu erleichtern, müssen wir einen intelligenten Zeiger von this erstellen, daher ist dieser Schritt notwendig. insert fügt Elemente, die kleiner als die Wurzel sind, in den linken Teilbaum ein, und Elemente, die größer als die Wurzel sind, werden in den rechten Teilbaum eingefügt. ldr ist die konventionellste Durchquerung in der Reihenfolge. Sie wird hier implementiert, um alle Elemente im Baum anzuzeigen auf herkömmliche Weise.
Es ist zu beachten, dass es am besten ist, make_shared zu verwenden, um sie zu erstellen, anstatt sie als globale/lokale Objekte zu initialisieren. Andernfalls wird es beim Durchlaufen der Ebenenreihenfolge zerstört Die Zerstörung von shared_ptr führt zur Zerstörung des Objekts, was zu undefiniertem Verhalten führt.
Angenommen, wir haben einen Datensatz: [3, 1, 0, 2, 5, 4, 6, 7], nehmen das erste Element als Wurzel und fügen alle Daten in unseren Baum ein Das Ergebnis ist der folgende Binärbaum:
auto root = std::make_shared<BinaryTreeNode>(3); root->insert(1); root->insert(0); root->insert(2); root->insert(5); root->insert(4); root->insert(6); root->insert(7);

Sie können sehen, dass die Knoten in vier Schichten unterteilt sind. Jetzt müssen wir Schicht für Schicht drucken.
Durchquerung der Ebenenreihenfolge
Tatsächlich ist die Idee sehr einfach. Wir übernehmen die Breite-zuerst-Idee: Drucken Sie zuerst alle Kinder des Knotens und dann die Kinder des Kindes Knoten.
Nehmen Sie das obige Bild als Beispiel. Wir drucken zuerst den Wert des Wurzelknotens 3 und dann die Werte aller seiner untergeordneten Knoten, nämlich 1 und 5 und dann die untergeordneten Knoten des linken und rechten untergeordneten Knotens und so weiter. . . . . .
Es ist leicht zu sagen, aber es wird mühsam sein, den Code zu schreiben. Wir können das Problem nicht einfach mit der Rekursion lösen, wie beim Durchlaufen in der Reihenfolge (tatsächlich können wir einen verbesserten rekursiven Algorithmus verwenden), da diese direkt zu den Blattknoten führt, was nicht das gewünschte Ergebnis ist. Aber es spielt keine Rolle, wir können die Warteschlange verwenden, um die untergeordnete Knotenwarteschlange am Ende der Warteschlange hinzuzufügen, dann vom Anfang der Warteschlange, dem Wurzelknoten, durchlaufen, ihre untergeordneten Knoten zur Warteschlange hinzufügen und dann Führen Sie den gleichen Vorgang am zweiten Knoten aus. Wenn Sie auf das Ende einer Zeile stoßen, markieren wir es mit nullptr.
Schauen Sie sich zuerst den spezifischen Code an:
std::vector<std::shared_ptr<BinaryTreeNode>>
BinaryTreeNode::layer_contents()
{
std::vector<std::shared_ptr<BinaryTreeNode>> nodes;
// 先添加根节点,根节点自己就会占用一行输出,所以添加了作为行分隔符的nullptr
// 因为需要保存this,所以这是我们需要继承enable_shared_from_this是理由
// 同样是因为这里,当返回的结果容器析构时this的智能指针也会析构
// 如果我们使用了局部变量则this的引用计数从1减至0,导致对象被销毁,而使用了make_shared创建的对象引用计数是从2到1,没有问题
nodes.push_back(shared_from_this());
nodes.push_back(nullptr);
// 我们使用index而不是迭代器,是因为添加元素时很可能发生迭代器失效,处理这一问题将会耗费大量精力,而index则无此烦恼
for (int index = 0; index < nodes.size(); ++index) {
if (!nodes[index]) {
// 子节点打印完成或已经遍历到队列末尾
if (index == nodes.size()-1) {
break;
}
nodes.push_back(nullptr); // 添加分隔符
continue;
}
if (nodes[index]->left) { // 将当前节点的子节点都添加进队列
nodes.push_back(nodes[index]->left);
}
if (nodes[index]->right) {
nodes.push_back(nodes[index]->right);
}
}
return nodes;
}Der Code selbst ist nicht kompliziert, wichtig ist die Idee dahinter.
Illustration des Algorithmus
Es spielt keine Rolle, ob Sie diesen Code beim ersten Mal nicht verstehen. Wir stellen Ihnen unten ein Diagramm zur Verfügung:
Das erste ist das Zustand am Anfang der Schleife wurde bestimmt (^ stellt einen Nullzeiger dar):
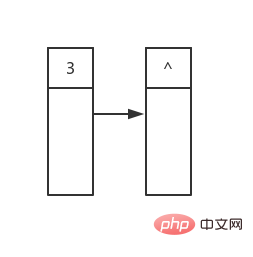
Dann beginnen wir mit dem Durchlauf vom ersten Element Das erste, das durchquert wird, ist root, das zwei untergeordnete Elemente hat. Die Werte sind 1 bzw. 5:
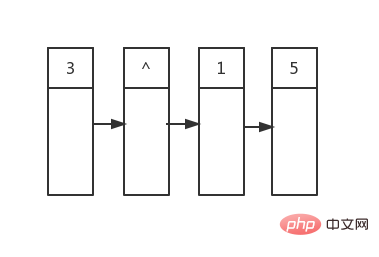
Dann ist der Indexwert +1, dieses Mal geht es nach nullptr, Da es sich nicht am Ende der Warteschlange befindet, fügen wir einfach einen nullptr am Ende der Warteschlange hinzu, sodass sich die Knoten in der zweiten Reihe alle in der Warteschlange befinden:

Dann beginnen wir mit dem Durchlaufen der Knoten in der zweiten Zeile und verwenden deren untergeordnete Knoten als Der Inhalt der drei Zeilen wird in die Warteschlange gestellt, am Ende wird ein Zeilentrenner hinzugefügt und so weiter:

Um es einfach auszudrücken: Alle Knoten der vorherigen Zeile werden über die Warteschlange zwischengespeichert. Anschließend werden alle Knoten der nächsten Zeile basierend auf dem Cache der vorherigen Zeile abgerufen Der Zyklus wird bis zur letzten Ebene des Binärbaums fortgesetzt. Natürlich können mit ähnlichen Ideen nicht nur Binärbäume, sondern auch das Durchlaufen anderer Multibäume in Ebenenordnung implementiert werden.
Okay, da wir nun wissen, wie wir den Inhalt jeder Zeile erhalten, können wir die Knoten Zeile für Zeile verarbeiten:
void BinaryTreeNode::layer_print()
{
auto nodes = layer_contents();
for (auto iter = nodes.begin(); iter != nodes.end(); ++iter) {
// 空指针代表一行结束,这里我们遇到空指针就输出换行符
if (*iter) {
std::cout << (*iter)->value_ << " ";
} else {
std::cout << "\n";
}
}
}如你所见,这个方法足够简单,我们把节点信息保存在额外的容器中是为了方便做进一步的处理,如果只是打印的话大可不必这么麻烦,不过简单通常是有代价的。对于我们的实现来说,分隔符的存在简化了我们对层级之间的区分,然而这样会导致浪费至少log2(n)+1个vector的存储空间,某些情况下可能引起性能问题,而且通过合理得使用计数变量可以避免这些额外的空间浪费。当然具体的实现读者可以自己挑战一下,原理和我们上面介绍的是类似的因此就不在赘述了,也可以参考园内其他的博客文章。
测试
最后让我们看看完整的测试程序,记住要用make_shared创建root实例:
int main()
{
auto root = std::make_shared<BinaryTreeNode>(3);
root->insert(1);
root->insert(0);
root->insert(2);
root->insert(5);
root->insert(4);
root->insert(6);
root->insert(7);
root->ldr();
std::cout << "\n";
root->layer_print();
}输出:
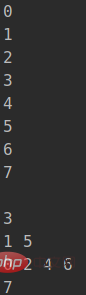
可以看到上半部分是中序遍历的结果,下半部分是层序遍历的输出,而且是逐行打印的,不过我们没有做缩进。所以不太美观。
另外你可能已经发现了,我们没有写任何有关资源释放的代码,没错,这就是智能指针的威力,只要注意资源的创建,剩下的事都可以放心得交给智能指针处理,我们可以把更多的精力集中在算法和功能的实现上。
如有错误和疑问欢迎指出!
Das obige ist der detaillierte Inhalt vonGrafisches Durchlaufen der Ebenenreihenfolge in C++ und schichtweises Drucken von Binärbäumen, die durch intelligente Zeiger erstellt wurden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Was ist die Rolle von CHAR in C -Saiten?
Apr 03, 2025 pm 03:15 PM
Was ist die Rolle von CHAR in C -Saiten?
Apr 03, 2025 pm 03:15 PM
In C wird der Zeichenentyp in Saiten verwendet: 1. Speichern Sie ein einzelnes Zeichen; 2. Verwenden Sie ein Array, um eine Zeichenfolge darzustellen und mit einem Null -Terminator zu enden. 3. Durch eine Saitenbetriebsfunktion arbeiten; 4. Lesen oder geben Sie eine Zeichenfolge von der Tastatur aus.
 Vier Möglichkeiten zur Implementierung von Multithreading in C -Sprache
Apr 03, 2025 pm 03:00 PM
Vier Möglichkeiten zur Implementierung von Multithreading in C -Sprache
Apr 03, 2025 pm 03:00 PM
Multithreading in der Sprache kann die Programmeffizienz erheblich verbessern. Es gibt vier Hauptmethoden, um Multithreading in C -Sprache zu implementieren: Erstellen Sie unabhängige Prozesse: Erstellen Sie mehrere unabhängig laufende Prozesse. Jeder Prozess hat seinen eigenen Speicherplatz. Pseudo-MultitHhreading: Erstellen Sie mehrere Ausführungsströme in einem Prozess, der denselben Speicherplatz freigibt und abwechselnd ausführt. Multi-Thread-Bibliothek: Verwenden Sie Multi-Thread-Bibliotheken wie PThreads, um Threads zu erstellen und zu verwalten, wodurch reichhaltige Funktionen der Thread-Betriebsfunktionen bereitgestellt werden. Coroutine: Eine leichte Multi-Thread-Implementierung, die Aufgaben in kleine Unteraufgaben unterteilt und sie wiederum ausführt.
 Berechnung des C-Subscript 3-Index 5 C-Subscript 3-Index 5-Algorithmus-Tutorial
Apr 03, 2025 pm 10:33 PM
Berechnung des C-Subscript 3-Index 5 C-Subscript 3-Index 5-Algorithmus-Tutorial
Apr 03, 2025 pm 10:33 PM
Die Berechnung von C35 ist im Wesentlichen kombinatorische Mathematik, die die Anzahl der aus 3 von 5 Elementen ausgewählten Kombinationen darstellt. Die Berechnungsformel lautet C53 = 5! / (3! * 2!), Was direkt durch Schleifen berechnet werden kann, um die Effizienz zu verbessern und Überlauf zu vermeiden. Darüber hinaus ist das Verständnis der Art von Kombinationen und Beherrschen effizienter Berechnungsmethoden von entscheidender Bedeutung, um viele Probleme in den Bereichen Wahrscheinlichkeitsstatistik, Kryptographie, Algorithmus -Design usw. zu lösen.
 Unterschiedliche Funktionsnutzungsabstand Funktion C -Verwendung Tutorial
Apr 03, 2025 pm 10:27 PM
Unterschiedliche Funktionsnutzungsabstand Funktion C -Verwendung Tutorial
Apr 03, 2025 pm 10:27 PM
STD :: Einzigartige Entfernung benachbarte doppelte Elemente im Container und bewegt sie bis zum Ende, wodurch ein Iterator auf das erste doppelte Element zeigt. STD :: Distanz berechnet den Abstand zwischen zwei Iteratoren, dh die Anzahl der Elemente, auf die sie hinweisen. Diese beiden Funktionen sind nützlich, um den Code zu optimieren und die Effizienz zu verbessern, aber es gibt auch einige Fallstricke, auf die geachtet werden muss, wie z. STD :: Distanz ist im Umgang mit nicht randomischen Zugriffs-Iteratoren weniger effizient. Indem Sie diese Funktionen und Best Practices beherrschen, können Sie die Leistung dieser beiden Funktionen voll ausnutzen.
 Wie kann ich die Schlangennomenklatur in der C -Sprache anwenden?
Apr 03, 2025 pm 01:03 PM
Wie kann ich die Schlangennomenklatur in der C -Sprache anwenden?
Apr 03, 2025 pm 01:03 PM
In der C -Sprache ist die Snake -Nomenklatur eine Konvention zum Codierungsstil, bei der Unterstriche zum Verbinden mehrerer Wörter mit Variablennamen oder Funktionsnamen angeschlossen werden, um die Lesbarkeit zu verbessern. Obwohl es die Zusammenstellung und den Betrieb nicht beeinträchtigen wird, müssen langwierige Benennung, IDE -Unterstützung und historisches Gepäck berücksichtigt werden.
 Verwendung von Veröffentlichungen in C.
Apr 04, 2025 am 07:54 AM
Verwendung von Veröffentlichungen in C.
Apr 04, 2025 am 07:54 AM
Die Funktion Release_Semaphor in C wird verwendet, um das erhaltene Semaphor zu freigeben, damit andere Threads oder Prozesse auf gemeinsame Ressourcen zugreifen können. Es erhöht die Semaphorzahl um 1 und ermöglicht es dem Blockierfaden, die Ausführung fortzusetzen.
 C Sprachdatenstruktur: Die Schlüsselrolle von Datenstrukturen in der künstlichen Intelligenz
Apr 04, 2025 am 10:45 AM
C Sprachdatenstruktur: Die Schlüsselrolle von Datenstrukturen in der künstlichen Intelligenz
Apr 04, 2025 am 10:45 AM
C Sprachdatenstruktur: Überblick über die Schlüsselrolle der Datenstruktur in der künstlichen Intelligenz im Bereich der künstlichen Intelligenz sind Datenstrukturen für die Verarbeitung großer Datenmengen von entscheidender Bedeutung. Datenstrukturen bieten eine effektive Möglichkeit, Daten zu organisieren und zu verwalten, Algorithmen zu optimieren und die Programmeffizienz zu verbessern. Gemeinsame Datenstrukturen, die häufig verwendete Datenstrukturen in der C -Sprache sind: Arrays: Eine Reihe von nacheinander gespeicherten Datenelementen mit demselben Typ. Struktur: Ein Datentyp, der verschiedene Arten von Daten zusammen organisiert und ihnen einen Namen gibt. Linked List: Eine lineare Datenstruktur, in der Datenelemente durch Zeiger miteinander verbunden werden. Stack: Datenstruktur, die dem LEST-In-First-Out-Prinzip (LIFO) folgt. Warteschlange: Datenstruktur, die dem First-In-First-Out-Prinzip (FIFO) folgt. Praktischer Fall: Die benachbarte Tabelle in der Graphentheorie ist künstliche Intelligenz
 Probleme mit der Dev-C-Version
Apr 03, 2025 pm 07:33 PM
Probleme mit der Dev-C-Version
Apr 03, 2025 pm 07:33 PM
DEV-C 4.9.9.2 Kompilierungsfehler und -lösungen Wenn das Kompilieren von Programmen in Windows 11-System mit Dev-C 4.9.9.2 kompiliert wird, kann der Compiler-Datensatz die folgende Fehlermeldung anzeigen: GCC.EXE: INTERNEHERERROR: ABTREIDED (programmcollect2) pleasSubMitAfulbugrort.SeeforinSructions. Obwohl die endgültige "Kompilierung erfolgreich ist", kann das tatsächliche Programm nicht ausgeführt werden und eine Fehlermeldung "Original -Code -Archiv kann nicht kompiliert werden" auftauchen. Dies liegt normalerweise daran, dass der Linker sammelt
