

Welche Technologie wird für Data Warehouse benötigt?

Data Warehousing ist eine Reihe neuer Anwendungstechnologien, die auf der Grundlage der Datenbanksystemtechnologie basierend auf den Anforderungen der Geschäftsentwicklung von Informationssystemen entwickelt wurden und nach und nach unabhängig wurden. Es gibt zwei Haupttechnologien für Data Warehouse: OLTP und OLAP. Lassen Sie es uns unten analysieren:

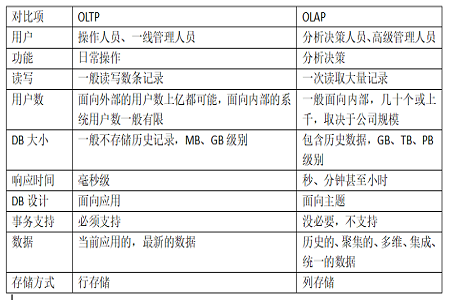
1. OLTP und OLAP
Der vollständige Name von OLTP lautet Online Transaction Processing. OLTP verwendet hauptsächlich traditionelle relationale Datenbanken für die Transaktionsverarbeitung. Die Kernanforderung von OLTP ist die effiziente und schnelle Verarbeitung einzelner Datensätze. Die grundlegendsten Anforderungen wie Indexierungstechnologie und Unterdatenbank und Untertabelle sollen dieses Problem lösen.
Der vollständige Name von OLAP lautet „Online Analytical Processing“. Im Gegensatz zur OLTP-Datenbank, die das Hinzufügen, Löschen, Ändern und die Parallelitätskontrolle von Daten berücksichtigen muss, sind OLAP-Daten im Allgemeinen erforderlich Es müssen lediglich Datenabfrageanforderungen verarbeitet werden. Importe werden stapelweise importiert, sodass die Reaktion auf Anforderungen durch Technologien wie Spaltenspeicherung, Spaltenkomprimierung und Bitmap-Indizierung erheblich beschleunigt werden kann.
2. Einfacher Vergleich von OLTP- und OLAP-Daten
3. Logisches Architekturdesign des Data Warehouse
Offline-Data-Warehouses werden normalerweise auf der Grundlage der dimensionalen Modellierungstheorie erstellt. Die logische Schichtung basiert hauptsächlich auf den folgenden Überlegungen:
1. Benutzer sollten es verwenden Daten, die vom Datenteam sorgfältig verarbeitet werden, und nicht Rohdaten aus dem Geschäftssystem. Der erste Vorteil davon besteht darin, dass Benutzer sorgfältig aufbereitete, standardisierte und saubere Daten aus geschäftlicher Sicht verwenden. Sehr einfach zu verstehen und zu verwenden. Zweitens: Wenn das vorgelagerte Geschäftssystem geändert oder sogar neu aufgebaut wird (z. B. Tabellenstruktur, Felder, Geschäftsbedeutung usw.), ist das Datenteam dafür verantwortlich, alle diese Änderungen zu bewältigen und die Auswirkungen auf nachgelagerte Benutzer zu minimieren.
2. Leistung und Wartbarkeit: Durch die Datenschichtung erfolgt die Datenverarbeitung grundsätzlich im Datenteam, sodass nicht immer wieder dieselbe Geschäftslogik ausgeführt werden muss, wodurch entsprechender Speicher- und Rechenaufwand gespart wird . Darüber hinaus macht die Datenschichtung die Wartung des Data Warehouse übersichtlich und komfortabel. Jede Schicht ist nur für ihre eigenen Aufgaben verantwortlich. Wenn bei der Datenverarbeitung auf einer bestimmten Schicht ein Problem auftritt, müssen Sie nur diese Schicht ändern.
3. Für ein Unternehmen und eine Organisation ist die Qualität der Daten sehr wichtig. Wenn jeder über einen Indikator spricht, muss dieser auf einem klaren und anerkannten Kaliber basieren standardisieren.
4. ODS-Schicht: Die Datentabellen des Data Warehouse-Quellsystems werden normalerweise intakt gespeichert. Dies wird als ODS-Schicht (Operation Data Store) bezeichnet ) sind sie die Datenquelle, die von der nachfolgenden Data-Warehouse-Schicht verarbeitet wird (d. h. die Faktentabellen- und Dimensionstabellenschicht, die auf der Grundlage der Kimball-Dimensionsmodellierung generiert wird, und die Zusammenfassungsschichtdaten, die auf der Grundlage dieser Faktentabellen und Detailtabellen verarbeitet werden). Gleichzeitig speichert die ODS-Schicht auch historische inkrementelle Daten oder vollständige Daten.
5. DWD- und DWS-Schichten: Data Warehouse Detail (DWD) und Data Warehouse Summary (DWS) sind Gegenstand des Data Warehouse. Die Daten der DWD- und DWS-Schichten werden von der ODS-Schicht nach ETL-Bereinigung, Konvertierung und Laden generiert und basieren normalerweise auf Kimballs dimensionaler Modellierungstheorie, und die Dimensionen jedes Unterthemas werden durch konsistente Dimensionen und Datenbusse garantiert. Konsistenz.
6. Anwendungsschicht (ADS): Die Anwendungsschicht ist hauptsächlich der Data Mart (Data Mart, DM), der von jeder Geschäftsabteilung oder Abteilung basierend auf DWD und DWS eingerichtet wird. Der Data Mart DM ist relativ zu DWD und DWS. Für Data Warehouse (DW). Im Allgemeinen stammen die Daten der Anwendungsschicht von der DW-Schicht, ein direkter Zugriff auf die ODS-Schicht ist jedoch grundsätzlich nicht zulässig. Darüber hinaus enthält die Anwendungsschicht im Vergleich zur DW-Schicht nur detaillierte und zusammenfassende Schichtdaten, die für die Abteilungen oder Parteien selbst wichtig sind.
Das obige ist der detaillierte Inhalt vonWelche Technologie wird für Data Warehouse benötigt?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Austausch von Projekterfahrungen in der Datenverarbeitung und im Data Warehouse durch MySQL-Entwicklung
Nov 03, 2023 am 09:39 AM
Austausch von Projekterfahrungen in der Datenverarbeitung und im Data Warehouse durch MySQL-Entwicklung
Nov 03, 2023 am 09:39 AM
Im heutigen digitalen Zeitalter gelten Daten allgemein als Grundlage und Kapital für unternehmerische Entscheidungen. Allerdings ist es nicht einfach, große Datenmengen zu verarbeiten und sie in verlässliche Entscheidungsunterstützungsinformationen umzuwandeln. Zu diesem Zeitpunkt beginnen Datenverarbeitung und Data Warehousing eine wichtige Rolle zu spielen. In diesem Artikel werden Projekterfahrungen bei der Implementierung von Datenverarbeitung und Data Warehouse durch MySQL-Entwicklung vorgestellt. 1. Projekthintergrund Dieses Projekt basiert auf den Anforderungen der Datenkonstruktion eines Handelsunternehmens und zielt darauf ab, Datenaggregation, Konsistenz, Bereinigung und Zuverlässigkeit durch Datenverarbeitung und Data Warehouse zu erreichen. Daten für diese Implementierung
 Verwenden Sie die Sprache Hive in Go, um ein effizientes Data Warehouse zu implementieren
Jun 15, 2023 pm 08:52 PM
Verwenden Sie die Sprache Hive in Go, um ein effizientes Data Warehouse zu implementieren
Jun 15, 2023 pm 08:52 PM
In den letzten Jahren sind Data Warehouses zu einem integralen Bestandteil des Unternehmensdatenmanagements geworden. Die direkte Verwendung der Datenbank für die Datenanalyse kann einfache Abfrageanforderungen erfüllen. Wenn wir jedoch umfangreiche Datenanalysen durchführen müssen, kann eine einzelne Datenbank diese Anforderungen nicht mehr erfüllen. Derzeit müssen wir ein Data Warehouse verwenden, um große Datenmengen zu verarbeiten . Hive ist eine der beliebtesten Open-Source-Komponenten im Data-Warehouse-Bereich. Es kann die verteilte Hadoop-Computing-Engine und SQL-Abfragen integrieren und die parallele Verarbeitung großer Datenmengen unterstützen. Verwenden Sie gleichzeitig in der Go-Sprache
 Aufbrechen von Datensilos mit einem einheitlichen Data Warehouse: CDP auf Basis von Apache Doris
Mar 20, 2024 pm 01:47 PM
Aufbrechen von Datensilos mit einem einheitlichen Data Warehouse: CDP auf Basis von Apache Doris
Mar 20, 2024 pm 01:47 PM
Da Unternehmensdatenquellen immer vielfältiger werden, ist das Problem von Datensilos allgegenwärtig. Wenn Versicherungsunternehmen Kundendatenplattformen (CDPs) aufbauen, stehen sie vor dem Problem komponentenintensiver Rechenschichten und verstreuter Datenspeicherung aufgrund von Datensilos. Um diese Probleme zu lösen, führten sie CDP 2.0 auf Basis von Apache Doris ein und nutzten die einheitlichen Data-Warehouse-Funktionen von Doris, um Datensilos aufzubrechen, Datenverarbeitungspipelines zu vereinfachen und die Datenverarbeitungseffizienz zu verbessern.
 Wie unterstützt die Go-Sprache Data Warehouse- und Datenanalyseanwendungen in der Cloud?
May 17, 2023 pm 04:51 PM
Wie unterstützt die Go-Sprache Data Warehouse- und Datenanalyseanwendungen in der Cloud?
May 17, 2023 pm 04:51 PM
In den letzten Jahren sind Data Warehouse und Datenanalyse in der Cloud mit der kontinuierlichen Weiterentwicklung der Cloud-Computing-Technologie für immer mehr Unternehmen zu einem Problembereich geworden. Wie unterstützt Go als effiziente und leicht zu erlernende Programmiersprache Data Warehouse- und Datenanalyseanwendungen in der Cloud? Go-Sprache Cloud-Data-Warehouse-Entwicklungsanwendung Um Data-Warehouse-Anwendungen in der Cloud zu entwickeln, kann Go-Sprache eine Vielzahl von Entwicklungsframeworks und -tools verwenden, und der Entwicklungsprozess ist normalerweise sehr einfach. Darunter sind mehrere wichtige Tools: 1.1GoCloudGoCloud ist ein
 Was sind die herausragenden Merkmale eines Data Warehouse im Vergleich zu einer operativen Datenbank?
Jul 19, 2022 pm 04:15 PM
Was sind die herausragenden Merkmale eines Data Warehouse im Vergleich zu einer operativen Datenbank?
Jul 19, 2022 pm 04:15 PM
Die herausragenden Merkmale sind „massive Datenunterstützung“ und „Fast-Retrieval-Technologie“. Data Warehouse ist eine strukturierte Datenumgebung für Entscheidungsunterstützungssysteme und Online-Analyseanwendungsdatenquellen. Die Datenbank ist der Kern der gesamten Data Warehouse-Umgebung, in der Daten gespeichert werden und der Datenabruf unterstützt wird. Sie ist im Vergleich zu manipulativen Datenbanken hervorragend Es zeichnet sich durch die Unterstützung großer Datenmengen und eine schnelle Abruftechnologie aus.
 Integration von PHP und Data Warehouse
May 16, 2023 pm 11:10 PM
Integration von PHP und Data Warehouse
May 16, 2023 pm 11:10 PM
Mit der rasanten Entwicklung des Internets und von Big Data beginnen immer mehr Unternehmen, Data Warehouses als wichtige Infrastruktur zur Unterstützung der Geschäftsentwicklung zu nutzen. Als beliebte Programmiersprache ist PHP nach und nach für viele Unternehmen und Organisationen zur ersten Wahl geworden. Wie lässt sich PHP also in das Data Warehouse integrieren? 1. Überblick über Data Warehouse Data Warehouse bezieht sich auf ein großes Datenspeichersystem, das mit einem Thema als Kern und gemäß einem bestimmten Datenmodell und einer bestimmten Datenarchitektur aufgebaut ist. Sein Zweck besteht darin, die Geschwindigkeit des Datenzugriffs und die Effizienz der Abfragen zu verbessern
 Wie kann sichergestellt werden, dass KI- und Analyseprojekte nicht scheitern?
May 08, 2023 pm 06:40 PM
Wie kann sichergestellt werden, dass KI- und Analyseprojekte nicht scheitern?
May 08, 2023 pm 06:40 PM
2023 ist ein Jahr der eskalierenden Wirtschaftskrise und der Klimarisiken. Daher wird der Bedarf an datengesteuerten Erkenntnissen zur Förderung von Effizienz, Widerstandsfähigkeit und anderen wichtigen Initiativen für Unternehmen im Jahr 2023 oberste Priorität haben. Viele Unternehmen haben versucht, fortschrittliche Analysen und künstliche Intelligenz einzusetzen, um diesem Bedarf gerecht zu werden. Jetzt müssen sie den Proof of Concept in einen Return on Investment umwandeln. Viele Unternehmen machen große Fortschritte und investieren viel Talent und die richtige Software. Allerdings scheitern die KI- und Analyseprojekte vieler Unternehmen, weil sie nicht über die richtigen zugrunde liegenden Technologien zur Unterstützung von KI- und erweiterten Analyse-Workloads verfügen. Einige Unternehmen verlassen sich auf veraltete Legacy-Hardwaresysteme, während andere durch die Kosten- und Kontrollprobleme behindert werden, die mit der Nutzung der öffentlichen Cloud einhergehen. Die meisten Unternehmen
 So verwenden Sie Java zum Entwickeln einer Hive-basierten Data Warehouse-Anwendung
Sep 21, 2023 pm 04:48 PM
So verwenden Sie Java zum Entwickeln einer Hive-basierten Data Warehouse-Anwendung
Sep 21, 2023 pm 04:48 PM
So entwickeln Sie mit Java eine Hive-basierte Data-Warehouse-Anwendung. Einführung: Im heutigen Big-Data-Zeitalter ist Data-Warehouse ein wichtiges Werkzeug für Unternehmen zum Speichern und Verarbeiten großer Datenmengen. Als Mitglied des Hadoop-Ökosystems bietet Hive Data-Warehouse-Lösungen. Ziel dieses Artikels ist es, die Verwendung von Java zum Entwickeln einer Hive-basierten Data Warehouse-Anwendung vorzustellen und detaillierte Codebeispiele bereitzustellen. 1. Vorbereitung Bevor wir beginnen, müssen wir die folgenden Punkte sicherstellen: Installieren Sie Hadoop und Hive und stellen Sie sicher, dass sie ordnungsgemäß ausgeführt werden