

MySQL-Lösungen mit hoher Parallelität umfassen: 1. Optimierung von SQL-Anweisungen; Schneiden usw.
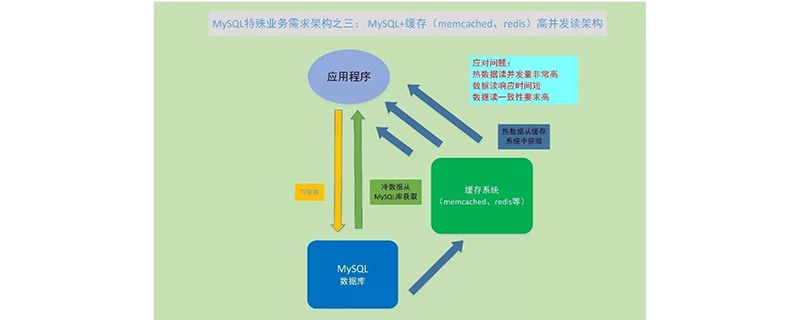
Die meisten Engpässe bei hoher Parallelität liegen im Hintergrund. Der normale Optimierungsplan für die Speicherung von MySQL lautet wie folgt:
(1) Optimierung von SQL-Anweisungen im Code
(2) Datenbankfeldoptimierung, Indexoptimierung
(3) Cache, Redis/Memcache usw. hinzufügen
(4) Master -Slave, Lese-Schreib-Trennung
(5) Partitionstabelle
(6) Vertikale Aufteilung, entkoppeltes Modul
(7) Horizontale Aufteilung
Video-Kursempfehlung →: „ Daten-Parallelitätslösung auf Zehn-Millionen-Ebene (Theorie + Praxis) “
Programmanalyse:
1 , Methode 1 und Methode 2 sind der einfachste und schnellste Weg zur Effizienzsteigerung. Da jede Anweisung auf den Index trifft, ist sie am effizientesten. Wenn der Index jedoch zur Optimierung von SQL erstellt wird, kommt es zu einem Überlauf des Index. Bei Tabellen mit mehreren zehn Millionen oder mehr werden die Kosten für die Verwaltung des Index erheblich erhöht, was wiederum den Speicheraufwand der Datenbank erhöht.
2. Optimierung von Datenbankfeldern. Ein leitender Programmierer entdeckte einmal, dass beim Entwurf von Tabellenfeldern ein Datumstyp als Varchar-Typ entworfen wurde. Obwohl er nicht standardisiert war, konnten die geschriebenen Daten nicht überprüft werden und auch die Effizienz der Indizierung war unterschiedlich
3. Caching eignet sich für Geschäftsszenarien mit relativ geringer Lese- und Schreibhäufigkeit und relativ geringer Aktualisierungshäufigkeit. Andernfalls gibt es kaum Cache-Einwände und die Trefferquote ist nicht hoch. Im Allgemeinen dient das Caching hauptsächlich dazu, die Verarbeitungsgeschwindigkeit der Schnittstelle zu verbessern, den durch Parallelität verursachten DB-Druck und andere dadurch verursachte Probleme zu verringern.
4. Die Partitionierung ist keine Tabelle. Das Ergebnis ist immer noch eine Tabelle, aber die gespeicherte Datendatei ist in mehrere kleine Blöcke unterteilt. Wenn die Tabellendaten sehr groß sind, können die Probleme gelöst werden, die dadurch entstehen, dass sie nicht sofort in den Speicher geladen werden können und große Tabellendaten verwaltet werden.
5. Durch die vertikale Aufteilung wird die Tabelle spaltenweise in mehrere Tabellen aufgeteilt. Es ist üblich, die erweiterten Daten der Haupttabelle und die Textdaten zu trennen, um den Druck auf die Festplatten-E/A zu verringern.
6. Horizontale Aufteilung Der Hauptzweck der horizontalen Aufteilung besteht darin, die gleichzeitigen Lese- und Schreibfunktionen einer einzelnen Tabelle (der Druck wird auf verschiedene Untertabellen verteilt) und die Festplatten-E/A-Leistung (eine sehr große . MYD-Datei wird auf verschiedene kleine Tabellen verteilt). Wenn keine Daten mit mehr als 10 Millionen Ebenen vorhanden sind, warum sollte sie dann zerlegt werden? Es ist auch möglich, nur eine einzelne Tabelle zu optimieren, und wenn keine zu große Parallelität besteht, kann eine partitionierte Tabelle im Allgemeinen die Anforderung erfüllen. Daher ist unter normalen Umständen die horizontale Aufteilung die letzte Wahl, und Sie müssen beim Entwurf dennoch Schritt für Schritt vorgehen.
Das obige ist der detaillierte Inhalt vonWie MySQL mit hoher Parallelität umgeht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



