

So optimieren Sie die MySQL-Datenbank

Methoden zur Optimierung der MySQL-Datenbank: Erstellen Sie einen Indexindex, verwenden Sie weniger Select-Anweisungen, aktivieren Sie das Abfrage-Caching, wählen Sie eine geeignete Speicher-Engine aus, vermeiden Sie die Verwendung von oder in der Where-Klausel zum Herstellen einer Verbindung und vermeiden Sie die Rückgabe großer Datenmengen usw.
Bei einer datenzentrierten Anwendung wirkt sich die Qualität der Datenbank direkt auf die Leistung des Programms aus, daher ist die Datenbankleistung entscheidend. Daher muss jeder die Optimierungsoperationen der MySQL-Datenbank verstehen. In diesem Artikel werden hauptsächlich die allgemeinen Optimierungsoperationen in der MySQL-Datenbank zusammengefasst. Ich werde im Folgenden nicht näher darauf eingehen.
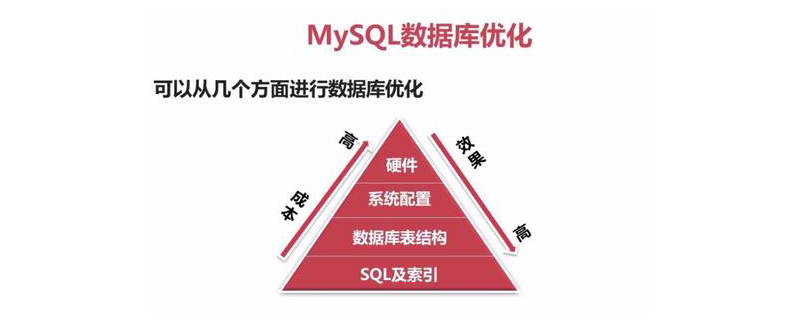
1. Index
Natürlich haben wir diese Art und Weise stillschweigend optimiert Primärschlüsselindex. Manchmal ist es uns egal, ob ein geeigneter Index definiert ist, die Leistung (Geschwindigkeit) der Datenbankabfrage wird um ein Vielfaches oder sogar Dutzende Male verbessert.
2. Verwenden Sie SELECT* sparsam
Manche Leute wählen beim Abfragen der Datenbank möglicherweise aus, was sie abfragen möchten. Wir sollten die Daten erhalten, die wir verwenden möchten, nicht alle, denn wenn wir sie auswählen, erhöht sich die Belastung des Webservers, die Belastung der Netzwerkübertragung steigt und die Abfragegeschwindigkeit nimmt natürlich ab.
3. EXPLAIN SELECT
Es wird geschätzt, dass viele Menschen diese Funktion noch nie gesehen haben, es wird jedoch dringend empfohlen, sie zu verwenden. EXPLAIN zeigt, wie MySQL Indizes verwendet, um Select-Anweisungen zu verarbeiten und Tabellen zu verknüpfen. Kann dabei helfen, bessere Indizes auszuwählen und optimiertere Abfrageanweisungen zu schreiben. Die Hauptverwendung besteht darin, „explain“ vor „select“ hinzuzufügen.
EXPLAIN SELECT [查找字段名] FROM tab_name ...
4. Abfrage-Cache aktivieren
Auf den meisten MySQL-Servern ist der Abfrage-Cache aktiviert. Dies ist eine der effektivsten Möglichkeiten zur Leistungsverbesserung und wird von der MySQL-Datenbank-Engine verwaltet. Wenn viele der gleichen Abfragen mehrmals ausgeführt werden, werden die Abfrageergebnisse in einem Cache abgelegt, sodass nachfolgende identische Abfragen die Tabelle nicht bedienen müssen, sondern direkt auf die zwischengespeicherten Ergebnisse zugreifen.
Der erste Schritt besteht darin, query_cache_type auf ON zu setzen und dann zu prüfen, ob die Systemvariable have_query_cache verfügbar ist:
show variables like 'have_query_cache'
Danach weisen Sie dem Abfragecache und der Steuerung die Speichergröße zu der Maximalwert der zwischengespeicherten Abfrageergebnisse. Relevante Vorgänge werden in der Konfigurationsdatei geändert.
5. Verwenden Sie NOT NULL
Viele Tabellen enthalten Spalten, die NULL (Nullwert) sein können, auch wenn die Anwendung keinen NULL-Wert speichern muss NULL ist die Standardeigenschaft der Spalte. Normalerweise ist es am besten, Spalten als NOT NULL anzugeben, es sei denn, Sie müssen wirklich NULL-Werte speichern.
Abfragen, die NULL-fähige Spalten enthalten, sind schwieriger für MySQL zu optimieren, da NULL-fähige Spalten Indizes, Indexstatistiken und Wertvergleiche komplexer machen. Spalten, die NULL sein können, benötigen mehr Speicherplatz und erfordern eine spezielle Behandlung in MySQL. Wenn NULL-fähige Spalten indiziert werden, erfordert jeder Indexdatensatz ein zusätzliches Byte, was in MyISAM sogar dazu führen kann, dass ein Index fester Größe (z. B. ein Index mit nur einer Ganzzahlspalte) zu einem Index variabler Größe wird.
Normalerweise bringt das Ändern der NULL-Spalte in NOT NULL nur eine geringe Leistungsverbesserung, sodass (bei der Optimierung) keine Notwendigkeit besteht, diese Situation zuerst im vorhandenen Schema zu suchen und zu ändern, es sei denn, Sie sind sicher, dass dies dazu führt ein Problem. Wenn Sie jedoch vorhaben, einen Index für eine Spalte zu erstellen, sollten Sie vermeiden, die Spalte als NULL zu gestalten. Natürlich gibt es Ausnahmen. Erwähnenswert ist beispielsweise, dass InnoDB ein separates Bit zum Speichern von NULL-Werten verwendet, sodass es eine gute Speicherplatzeffizienz für spärliche Daten bietet. Dies gilt jedoch nicht für MyISAM.
6. Auswahl der Speicher-Engine
Was die Auswahl von MyISAM und InnoDB betrifft: Wenn Sie Transaktionsverarbeitung oder Fremdschlüssel benötigen, ist InnoDB möglicherweise die bessere Möglichkeit. Wenn Sie eine Volltextindizierung benötigen, ist MyISAM normalerweise eine gute Wahl, da es in das System integriert ist. Wir testen jedoch nicht sehr oft 2 Millionen Datensatzzeilen. Auch wenn es etwas langsamer ist, können wir mit Sphinx einen Volltextindex von InnoDB erhalten.
Die Größe der Daten ist ein wichtiger Faktor, der sich darauf auswirkt, welche Speicher-Engine Sie wählen. Große Datensätze entscheiden sich in der Regel für InnoDB, da es die Transaktionsverarbeitung und Fehlerwiederherstellung unterstützt. Die Größe der Datenbank bestimmt die Länge der Fehlerwiederherstellungszeit. InnoDB kann Transaktionsprotokolle für die schnellere Datenwiederherstellung verwenden. Während MyISAM für diese Aufgaben
Stunden oder sogar Tage benötigen kann, benötigt InnoDB nur wenige Minuten.
Ihre Gewohnheit, Datenbanktabellen zu bedienen, kann ebenfalls ein Faktor sein, der die Leistung stark beeinflusst. Beispiel: COUNT() ist in der MyISAM-Tabelle sehr schnell, kann aber in der InnoDB-Tabelle schmerzhaft sein. Die Primärschlüsselabfrage wird unter InnoDB recht schnell sein, wir müssen jedoch aufpassen, dass es auch zu Leistungsproblemen kommt, wenn unser Primärschlüssel zu lang ist. Eine große Anzahl von Einfügungsanweisungen wird unter MyISAM schneller sein, aber Aktualisierungen werden unter InnoDB schneller sein – insbesondere, wenn die Parallelität groß ist.
所以,到底你检使用哪一个呢?根据经验来看,如果是一些小型的应用或项目,那么MyISAM也许会更适合。当然,在大型的环境下使用MyISAM也会有很大成功的时候,但却不总是这样的。如果你正在计划使用一个超大数据量的项目,而且需要事务处理或外键支持,那么你真的应该直接使用InnoDB方式。但需要记住InnoDB的表需要更多的内存和存储,转换100GB的MyISAM 表到InnoDB 表可能会让你有非常坏的体验。
七、避免在 where 子句中使用 or 来连接
如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = 'admin'
可以这样查询:
select id from t where num = 10 union all select id from t where Name = 'admin'
八、多使用varchar/nvarchar
使用varchar/nvarchar代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
九、避免大数据量返回
这里要考虑使用limit,来限制返回的数据量,如果每次返回大量自己不需要的数据,也会降低查询速度。
十、where子句优化
where 子句中使用参数,会导致全表扫描,因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
应尽量避免在 where 子句中对字段进行表达式操作,避免在where子句中对字段进行函数操作这将导致引擎放弃使用索引而进行全表扫描。不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
相关学习推荐:mysql教程(视频)
Das obige ist der detaillierte Inhalt vonSo optimieren Sie die MySQL-Datenbank. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Ausführliche Interpretation: Warum ist Laravel so langsam wie eine Schnecke?
Mar 07, 2024 am 09:54 AM
Ausführliche Interpretation: Warum ist Laravel so langsam wie eine Schnecke?
Mar 07, 2024 am 09:54 AM
Laravel ist ein beliebtes PHP-Entwicklungsframework, wird jedoch manchmal dafür kritisiert, dass es so langsam wie eine Schnecke ist. Was genau verursacht die unbefriedigende Geschwindigkeit von Laravel? In diesem Artikel werden die Gründe, warum Laravel in vielerlei Hinsicht so langsam wie eine Schnecke ist, ausführlich erläutert und mit spezifischen Codebeispielen kombiniert, um den Lesern zu einem tieferen Verständnis dieses Problems zu verhelfen. 1. Probleme mit der ORM-Abfrageleistung In Laravel ist ORM (Object Relational Mapping) eine sehr leistungsstarke Funktion, die dies ermöglicht
 Wie kann ich die Einstellungen optimieren und die Leistung verbessern, nachdem ich einen neuen Win11-Computer erhalten habe?
Mar 03, 2024 pm 09:01 PM
Wie kann ich die Einstellungen optimieren und die Leistung verbessern, nachdem ich einen neuen Win11-Computer erhalten habe?
Mar 03, 2024 pm 09:01 PM
Wie können wir die Leistung nach Erhalt eines neuen Computers einrichten und optimieren? Benutzer können direkt auf „Datenschutz und Sicherheit“ klicken und dann auf „Allgemein“ (Werbe-ID, lokaler Inhalt, Anwendungsstart, Einstellungsempfehlungen, Produktivitätstools) klicken oder die lokale Gruppenrichtlinie direkt öffnen Lassen Sie mich den Benutzern im Detail vorstellen, wie sie die Einstellungen optimieren und die Leistung des neuen Win11-Computers nach Erhalt verbessern können: 1. Drücken Sie die Tastenkombination [Win+i], um Einstellungen zu öffnen, und klicken Sie dann Klicken Sie links auf [Datenschutz und Sicherheit] und rechts unter „Windows-Berechtigungen“ auf „Allgemein (Werbe-ID, lokaler Inhalt, App-Start, Einstellungsvorschläge, Tools)“.
 Diskussion über Golangs GC-Optimierungsstrategie
Mar 06, 2024 pm 02:39 PM
Diskussion über Golangs GC-Optimierungsstrategie
Mar 06, 2024 pm 02:39 PM
Die Garbage Collection (GC) von Golang war schon immer ein heißes Thema unter Entwicklern. Als schnelle Programmiersprache kann der integrierte Garbage Collector von Golang den Speicher sehr gut verwalten, mit zunehmender Programmgröße treten jedoch manchmal Leistungsprobleme auf. In diesem Artikel werden die GC-Optimierungsstrategien von Golang untersucht und einige spezifische Codebeispiele bereitgestellt. Die Garbage Collection im Garbage Collector von Golang Golang basiert auf gleichzeitigem Mark-Sweep (concurrentmark-s
 C++-Programmoptimierung: Techniken zur Reduzierung der Zeitkomplexität
Jun 01, 2024 am 11:19 AM
C++-Programmoptimierung: Techniken zur Reduzierung der Zeitkomplexität
Jun 01, 2024 am 11:19 AM
Die Zeitkomplexität misst die Ausführungszeit eines Algorithmus im Verhältnis zur Größe der Eingabe. Zu den Tipps zur Reduzierung der Zeitkomplexität von C++-Programmen gehören: Auswahl geeigneter Container (z. B. Vektor, Liste) zur Optimierung der Datenspeicherung und -verwaltung. Nutzen Sie effiziente Algorithmen wie die schnelle Sortierung, um die Rechenzeit zu verkürzen. Eliminieren Sie mehrere Vorgänge, um Doppelzählungen zu reduzieren. Verwenden Sie bedingte Verzweigungen, um unnötige Berechnungen zu vermeiden. Optimieren Sie die lineare Suche, indem Sie schnellere Algorithmen wie die binäre Suche verwenden.
 Entschlüsselung von Laravel-Leistungsengpässen: Optimierungstechniken vollständig enthüllt!
Mar 06, 2024 pm 02:33 PM
Entschlüsselung von Laravel-Leistungsengpässen: Optimierungstechniken vollständig enthüllt!
Mar 06, 2024 pm 02:33 PM
Entschlüsselung von Laravel-Leistungsengpässen: Optimierungstechniken vollständig enthüllt! Als beliebtes PHP-Framework bietet Laravel Entwicklern umfangreiche Funktionen und ein komfortables Entwicklungserlebnis. Mit zunehmender Größe des Projekts und steigender Anzahl an Besuchen kann es jedoch zu Leistungsengpässen kommen. Dieser Artikel befasst sich mit den Techniken zur Leistungsoptimierung von Laravel, um Entwicklern dabei zu helfen, potenzielle Leistungsprobleme zu erkennen und zu lösen. 1. Optimierung der Datenbankabfrage mithilfe von Eloquent. Vermeiden Sie verzögertes Laden, wenn Sie Eloquent zum Abfragen der Datenbank verwenden
 Laravel-Leistungsengpass aufgedeckt: Optimierungslösung aufgedeckt!
Mar 07, 2024 pm 01:30 PM
Laravel-Leistungsengpass aufgedeckt: Optimierungslösung aufgedeckt!
Mar 07, 2024 pm 01:30 PM
Laravel-Leistungsengpass aufgedeckt: Optimierungslösung aufgedeckt! Mit der Entwicklung der Internettechnologie ist die Leistungsoptimierung von Websites und Anwendungen immer wichtiger geworden. Als beliebtes PHP-Framework kann es bei Laravel während des Entwicklungsprozesses zu Leistungsengpässen kommen. In diesem Artikel werden die Leistungsprobleme untersucht, auf die Laravel-Anwendungen stoßen können, und einige Optimierungslösungen und spezifische Codebeispiele bereitgestellt, damit Entwickler diese Probleme besser lösen können. 1. Optimierung von Datenbankabfragen Datenbankabfragen sind einer der häufigsten Leistungsengpässe in Webanwendungen. existieren
 So optimieren Sie die Startelemente des WIN7-Systems
Mar 26, 2024 pm 06:20 PM
So optimieren Sie die Startelemente des WIN7-Systems
Mar 26, 2024 pm 06:20 PM
1. Drücken Sie die Tastenkombination (Win-Taste + R) auf dem Desktop, um das Ausführungsfenster zu öffnen, geben Sie dann [regedit] ein und drücken Sie zur Bestätigung die Eingabetaste. 2. Nachdem wir den Registrierungseditor geöffnet haben, klicken wir zum Erweitern auf [HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionExplorer] und prüfen dann, ob sich im Verzeichnis ein Serialize-Element befindet. Wenn nicht, können wir mit der rechten Maustaste auf Explorer klicken, ein neues Element erstellen und es Serialize nennen. 3. Klicken Sie dann auf „Serialisieren“, klicken Sie dann mit der rechten Maustaste auf die leere Stelle im rechten Bereich, erstellen Sie einen neuen DWORD-Wert (32) und nennen Sie ihn „Star“.
 Die Parameterkonfiguration des Vivox100 wurde enthüllt: Wie kann die Prozessorleistung optimiert werden?
Mar 24, 2024 am 10:27 AM
Die Parameterkonfiguration des Vivox100 wurde enthüllt: Wie kann die Prozessorleistung optimiert werden?
Mar 24, 2024 am 10:27 AM
Die Parameterkonfiguration des Vivox100 wurde enthüllt: Wie kann die Prozessorleistung optimiert werden? In der heutigen Zeit der rasanten technologischen Entwicklung sind Smartphones zu einem unverzichtbaren Bestandteil unseres täglichen Lebens geworden. Als wichtiger Bestandteil eines Smartphones steht die Leistungsoptimierung des Prozessors in direktem Zusammenhang mit der Benutzererfahrung des Mobiltelefons. Als hochkarätiges Smartphone hat die Parameterkonfiguration des Vivox100 große Aufmerksamkeit erregt, insbesondere die Optimierung der Prozessorleistung hat bei den Benutzern große Aufmerksamkeit erregt. Als „Gehirn“ des Mobiltelefons beeinflusst der Prozessor direkt die Laufgeschwindigkeit des Mobiltelefons.
