

Crawler-Parsing-Methode fünf: XPath

Viele Sprachen können zum Crawlen verwendet werden, aber Crawler, die auf Python basieren, sind prägnanter und bequemer. Crawler sind auch zu einem wesentlichen Bestandteil der Python-Sprache geworden. Es gibt auch verschiedene Möglichkeiten, Crawler zu analysieren. Im vorherigen Artikel wurde Ihnen die vierte Crawler-Parsing-Methode vorgestellt: PyQuery Heute stelle ich Ihnen eine weitere Methode vor, XPath.

Grundlegende Verwendung von xpath im Python-Crawler
1. Einführung
XPath ist eine Sprache zum Auffinden von Informationen in XML-Dokumenten. XPath kann zum Durchlaufen von Elementen und Attributen in XML-Dokumenten verwendet werden. XPath ist ein Hauptelement des W3C XSLT-Standards und sowohl XQuery als auch XPointer basieren auf XPath-Ausdrücken.2. Installation
pip3 install lxml
3. Verwendung
1 , importierenfrom lxml import etree
from lxml import etree
wb_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(wb_data)
print(html)
result = etree.tostring(html)
print(result.decode("utf-8"))<Element html at 0x39e58f0>
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>Schreibmethode eins
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a')
print(html)
for i in html_data:
print(i.text)<Element html at 0x12fe4b8> first item second item third item fourth item fifth item
Schreibmethode zwei
(direkt im Tag wo Sie müssen den Inhalt finden. Fügen Sie einfach ein /text() dahinter ein
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()')
print(html)
for i in html_data:
print(i)<Element html at 0x138e4b8> first item second item third item fourth item fifth item
#使用parse打开html的文件
html = etree.parse('test.html')
html_data = html.xpath('//*')<br>#打印是一个列表,需要遍历
print(html_data)
for i in html_data:
print(i.text)html = etree.parse('test.html') html_data = etree.tostring(html,pretty_print=True) res = html_data.decode('utf-8') print(res)
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/@href')
for i in html_data:
print(i)7. Oben finden wir alle absoluten Pfade (jeder wird von der Wurzel aus durchsucht), unten finden wir relative Pfade, zum Beispiel finden wir den a-Tag-Inhalt unter allen li-Tags.
link1.html link2.html link3.html link4.html link5.html
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a[@href="link2.html"]/text()')
print(html_data)
for i in html_data:
print(i)html = etree.HTML(wb_data)
html_data = html.xpath('//li/a/text()')
print(html_data)
for i in html_data:
print(i)['first item', 'second item', 'third item', 'fourth item', 'fifth item'] first item second item third item fourth item fifth item
9. Die Methode zur Überprüfung spezifischer Attribute unter relativen Pfaden ähnelt der unter absoluten Pfaden. Man kann auch sagen, dass sie dieselbe ist.
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a//@href')
print(html_data)
for i in html_data:
print(i)Drucken:
[<Element a at 0x216e468>] second item
10、查找最后一个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()]/a/text()')
print(html_data)
for i in html_data:
print(i)
打印:
['fifth item'] fifth item
11、查找倒数第二个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()-1]/a/text()')
print(html_data)
for i in html_data:
print(i)
打印:
['fourth item'] fourth item
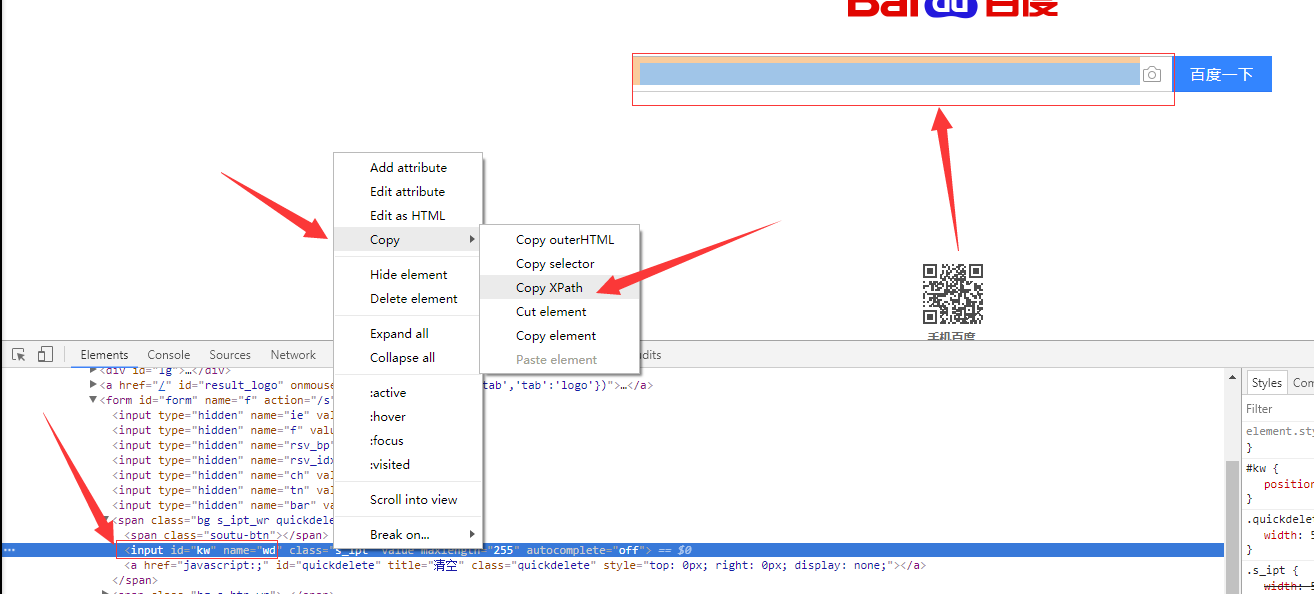
12、如果在提取某个页面的某个标签的xpath路径的话,可以如下图:
//*[@id="kw"]
解释:使用相对路径查找所有的标签,属性id等于kw的标签。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.selector import Selector, HtmlXPathSelector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
<li><a id='i1' href="link.html">first item</a></li>
<li><a id='i2' href="llink.html">first item</a></li>
<li><a href="llink2.html">second item<span>vv</span></a></li>
</ul>
<div><a href="llink2.html">second item</a></div>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
# hxs = HtmlXPathSelector(response)
# print(hxs)
# hxs = Selector(response=response).xpath('//a')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[2]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[contains(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first()
# print(hxs)
# ul_list = Selector(response=response).xpath('//body/ul/li')
# for item in ul_list:
# v = item.xpath('./a/span')
# # 或
# # v = item.xpath('a/span')
# # 或
# # v = item.xpath('*/a/span')
# print(v)Das obige ist der detaillierte Inhalt vonCrawler-Parsing-Methode fünf: XPath. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Bei der Verwendung von Pythons Pandas -Bibliothek ist das Kopieren von ganzen Spalten zwischen zwei Datenrahmen mit unterschiedlichen Strukturen ein häufiges Problem. Angenommen, wir haben zwei Daten ...
 Können Python -Parameteranmerkungen Zeichenfolgen verwenden?
Apr 01, 2025 pm 08:39 PM
Können Python -Parameteranmerkungen Zeichenfolgen verwenden?
Apr 01, 2025 pm 08:39 PM
Alternative Verwendung von Python -Parameteranmerkungen in der Python -Programmierung, Parameteranmerkungen sind eine sehr nützliche Funktion, die den Entwicklern helfen kann, Funktionen besser zu verstehen und zu verwenden ...
 Python Cross-Platform Desktop-Anwendungsentwicklung: Welche GUI-Bibliothek ist die beste für Sie?
Apr 01, 2025 pm 05:24 PM
Python Cross-Platform Desktop-Anwendungsentwicklung: Welche GUI-Bibliothek ist die beste für Sie?
Apr 01, 2025 pm 05:24 PM
Auswahl der Python-plattformübergreifenden Desktop-Anwendungsentwicklungsbibliothek Viele Python-Entwickler möchten Desktop-Anwendungen entwickeln, die sowohl auf Windows- als auch auf Linux-Systemen ausgeführt werden können ...
 Warum kann mein Code nicht die von der API zurückgegebenen Daten erhalten? Wie löst ich dieses Problem?
Apr 01, 2025 pm 08:09 PM
Warum kann mein Code nicht die von der API zurückgegebenen Daten erhalten? Wie löst ich dieses Problem?
Apr 01, 2025 pm 08:09 PM
Warum kann mein Code nicht die von der API zurückgegebenen Daten erhalten? Bei der Programmierung stoßen wir häufig auf das Problem der Rückgabe von Nullwerten, wenn API aufruft, was nicht nur verwirrend ist ...
 Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen an? Uvicorn ist ein leichter Webserver, der auf ASGI basiert. Eine seiner Kernfunktionen ist es, auf HTTP -Anfragen zu hören und weiterzumachen ...
 Wie lösten Python -Skripte an einem bestimmten Ort die Ausgabe in Cursorposition?
Apr 01, 2025 pm 11:30 PM
Wie lösten Python -Skripte an einem bestimmten Ort die Ausgabe in Cursorposition?
Apr 01, 2025 pm 11:30 PM
Wie lösten Python -Skripte an einem bestimmten Ort die Ausgabe in Cursorposition? Beim Schreiben von Python -Skripten ist es üblich, die vorherige Ausgabe an die Cursorposition zu löschen ...
 Bieten Google und AWS öffentliche PYPI -Bildquellen an?
Apr 01, 2025 pm 05:15 PM
Bieten Google und AWS öffentliche PYPI -Bildquellen an?
Apr 01, 2025 pm 05:15 PM
Viele Entwickler verlassen sich auf PYPI (PythonpackageIndex) ...
