

Kann der Python-Crawler Videos crawlen?

Webcrawler, auch Webspider genannt, bezeichnen Skriptprogramme, die nach bestimmten Regeln die benötigten Inhalte im Web crawlen. Wie wir alle wissen, enthält jede Webseite normalerweise Eingänge zu anderen Webseiten, und Webcrawler verwenden eine URL, um nacheinander andere URLs einzugeben, um den erforderlichen Inhalt zu erhalten.

Crawler-Struktur
Crawler-Planer ( Eingang des Programms, der zum Starten des gesamten Programms verwendet wird)
URL-Manager (wird zur Verwaltung nicht gecrawlter URLs und gecrawlter URLs verwendet)
Webseiten-Downloader (wird zum Herunterladen von Webseiteninhalten zur Analyse verwendet)
Webseiten-Parser (wird zum Parsen heruntergeladener Webseiten und zum Abrufen neuer URLs und erforderlicher Inhalte verwendet)
Webseiten-Ausgabeprogramm (wird verwendet, um den erhaltenen Inhalt in Form einer Datei auszugeben)
Erster Schritt
Analysieren Sie den Quellcode der Webseite. Beispiel: http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97, klicken Sie mit der rechten Maustaste, um den Quellcode anzuzeigen. Wenn Sie suchen, werden Sie ihn nicht finden, aber einige können direkt angesehen werden, z. B. Meipai-Videos.
Verwandte Empfehlungen: „Python-Video-Tutorial“
Schritt 2
Erfassen Sie das Paket, analysieren Sie die Anfrage und senden Sie es zurück. Dies kann auch über das leistungsstarke Chrome erreicht werden, wie im obigen Beispiel: Rechtsklick->Element prüfen->Netzwerk, dann aktualisieren Sie die Webseite mit F5
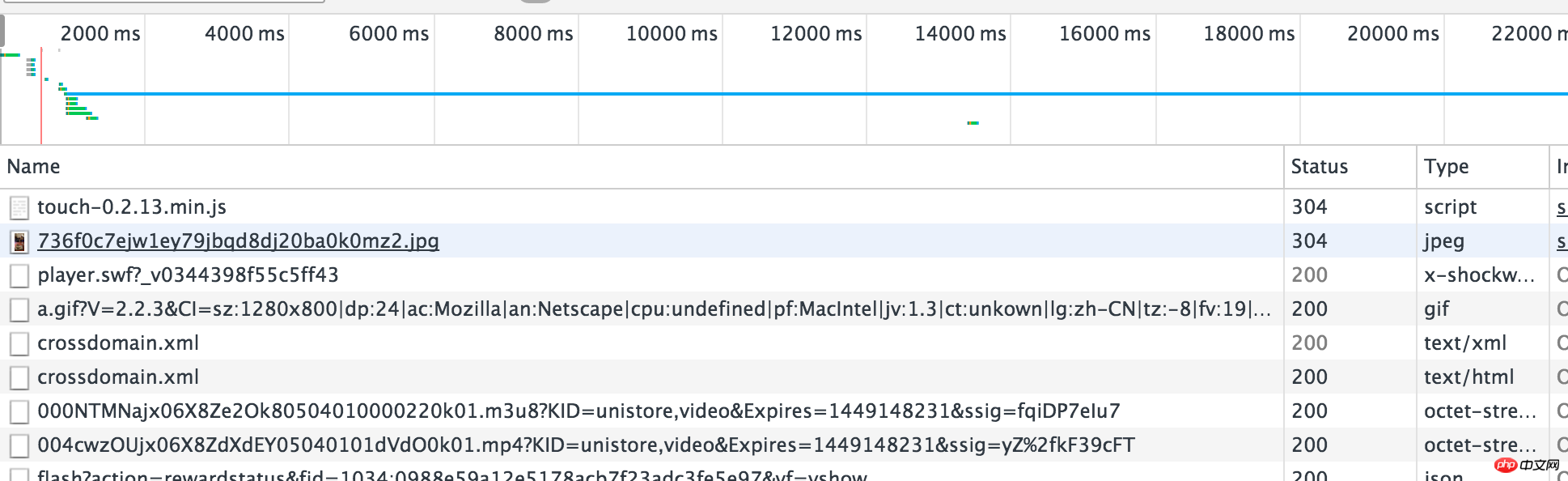
Ich habe festgestellt, dass es viele Videoformate gibt, die nur einzeln analysiert werden können. Sie können sie auf einmal in den Browser kopieren und öffnen Genug, es ist der Download-Link, den wir wollen.
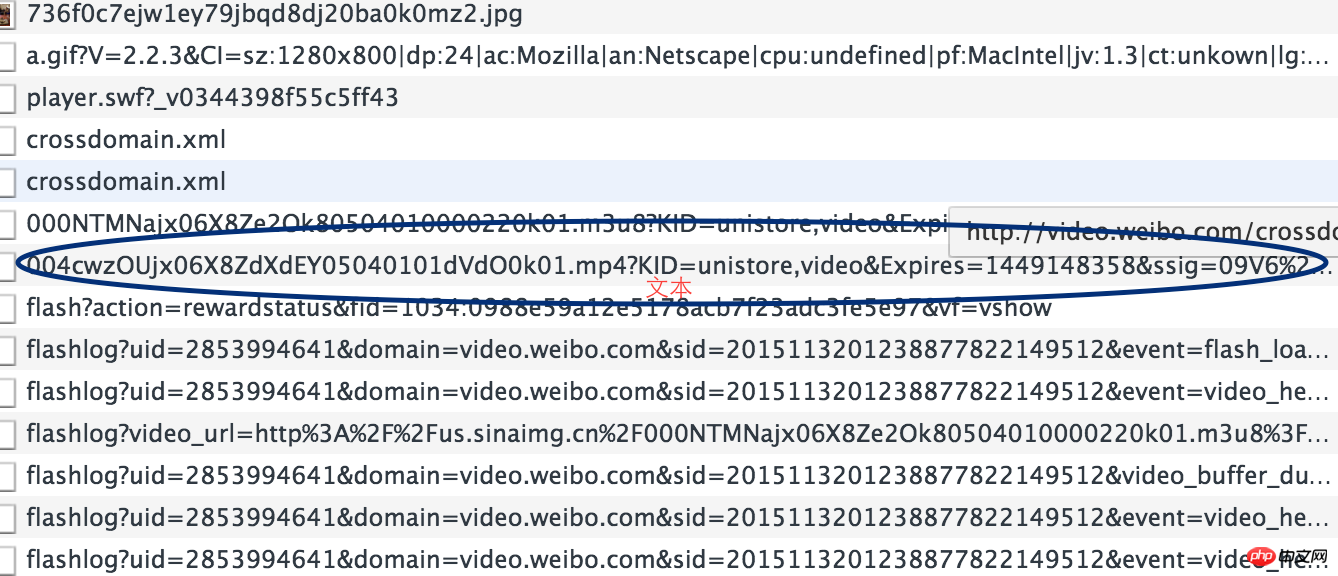
Der dritte Schritt
Analysieren Sie die Muster von Download-Links und Video-Links. Das heißt, die Beziehung zwischen http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97 und xxx.mp4. Dies erfordert wiederum eine Analyse des Quellcodes der Webseite. Sie können auf den Link mit dem Suffix .m3u8 achten. Wenn Sie ihn öffnen, wird er von der Wiedergabesoftware nicht abgespielt Verwenden Sie die Netzwerkadresse der Datei, um sie online abzuspielen, und prüfen Sie, ob der gewünschte Download-Link tatsächlich darin aufgezeichnet ist. Darüber hinaus befindet sich der Link mit der Endung .m3u8 im Quellcode der Webseite.

Zusammenfassung
Nach der Analyse der ersten drei Schritte entstand die Idee von Beziehen des Video-Download-Links Holen Sie sich einfach den Link mit dem Suffix .m3u8 aus dem Quellcode der Webseite, laden Sie die Datei herunter, holen Sie sich den Video-Download-Link daraus und laden Sie schließlich das Video herunter
Quellcode
#coding=utf-8
import os
import re
import urllib2
import urllib
from common import Common
class SinaVideo():
URL_PIRFIX = "http://us.sinaimg.cn/"
def getM3u8(self,html):
reg = re.compile(r'list=([\s\S]*?)&fid')
result = reg.findall(html)
return result[0]
def getName(self,url):
return url.split('=')[1]
def getSinavideoUrl(self,filepath):
f = open(filepath,'r')
lines = f.readlines()
f.close()
for line in lines:
if line[0] !='#':
return line
def download(self,url,filepath):
#获取名称
name = self.getName(url)
html = Common.getHtml(url)
m3u8 = self.getM3u8(html)
Common.download(urllib.unquote(m3u8),filepath,name + '.m3u8')
url = self.URL_PIRFIX + self.getSinavideoUrl(filepath+name+'.m3u8')
Common.download(url,filepath,name+'.mp4')Aufrufmethode:
#common.py
#coding=utf-8
import urllib2
import os
import re
class Common():
# 获取网页源码
@staticmethod
def getHtml(url):
html = urllib2.urlopen(url).read()
print "[+]获取网页源码:"+url
return html
# 下载文件
@staticmethod
def download(url,filepath,filename):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'UTF-8,*;q=0.5',
'Accept-Encoding': 'gzip,deflate,sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.114 Mobile Safari/537.36'
}
request = urllib2.Request(url,headers = headers);
response = urllib2.urlopen(request)
path = filepath + filename
with open(path,'wb') as output:
while True:
buffer = response.read(1024*256);
if not buffer:
break
# received += len(buffer)
output.write(buffer)
print "[+]下载文件成功:"+path
@staticmethod
def isExist(filepath):
return os.path.exists(filepath)
@staticmethod
def createDir(filepath):
os.makedirs(filepath,0777)Ergebnis:

Das obige ist der detaillierte Inhalt vonKann der Python-Crawler Videos crawlen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python haben jeweils ihre eigenen Vorteile und wählen nach den Projektanforderungen. 1.PHP ist für die Webentwicklung geeignet, insbesondere für die schnelle Entwicklung und Wartung von Websites. 2. Python eignet sich für Datenwissenschaft, maschinelles Lernen und künstliche Intelligenz mit prägnanter Syntax und für Anfänger.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Nginx SSL -Zertifikat -Aktualisierung Debian Tutorial
Apr 13, 2025 am 07:21 AM
Nginx SSL -Zertifikat -Aktualisierung Debian Tutorial
Apr 13, 2025 am 07:21 AM
In diesem Artikel werden Sie begleitet, wie Sie Ihr NginXSSL -Zertifikat auf Ihrem Debian -System aktualisieren. Schritt 1: Installieren Sie zuerst CertBot und stellen Sie sicher, dass Ihr System Certbot- und Python3-CertBot-Nginx-Pakete installiert hat. If not installed, please execute the following command: sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx Step 2: Obtain and configure the certificate Use the certbot command to obtain the Let'sEncrypt certificate and configure Nginx: sudocertbot--nginx Follow the prompts to select
 So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Das Konfigurieren eines HTTPS -Servers auf einem Debian -System umfasst mehrere Schritte, einschließlich der Installation der erforderlichen Software, der Generierung eines SSL -Zertifikats und der Konfiguration eines Webservers (z. B. Apache oder NGINX) für die Verwendung eines SSL -Zertifikats. Hier ist eine grundlegende Anleitung unter der Annahme, dass Sie einen Apacheweb -Server verwenden. 1. Installieren Sie zuerst die erforderliche Software, stellen Sie sicher, dass Ihr System auf dem neuesten Stand ist, und installieren Sie Apache und OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
 Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Die Entwicklung eines Gitlab -Plugins für Debian erfordert einige spezifische Schritte und Kenntnisse. Hier ist ein grundlegender Leitfaden, mit dem Sie mit diesem Prozess beginnen können. Wenn Sie zuerst GitLab installieren, müssen Sie GitLab in Ihrem Debian -System installieren. Sie können sich auf das offizielle Installationshandbuch von GitLab beziehen. Holen Sie sich API Access Token, bevor Sie die API -Integration durchführen. Öffnen Sie das GitLab -Dashboard, finden Sie die Option "AccessTokens" in den Benutzereinstellungen und generieren Sie ein neues Zugriffs -Token. Wird generiert
 Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Apache ist der Held hinter dem Internet. Es ist nicht nur ein Webserver, sondern auch eine leistungsstarke Plattform, die enormen Datenverkehr unterstützt und dynamische Inhalte bietet. Es bietet eine extrem hohe Flexibilität durch ein modulares Design und ermöglicht die Ausdehnung verschiedener Funktionen nach Bedarf. Modularität stellt jedoch auch Konfigurations- und Leistungsherausforderungen vor, die ein sorgfältiges Management erfordern. Apache eignet sich für Serverszenarien, die hoch anpassbare und entsprechende komplexe Anforderungen erfordern.
