

DOM
DOM ist die Abkürzung für Document Object Model. Das Dokumentobjektmodell ist ein Dokument, das XML oder HTML in Form von Baumknoten ausdrückt. Mithilfe von DOM-Methoden und -Eigenschaften können Sie auf jedes Element auf der Seite zugreifen, es ändern, löschen und auch ein Element hinzufügen. DOM ist eine sprachunabhängige API, die in jeder Sprache implementiert werden kann, einschließlich Javascript
Schauen Sie sich einen der folgenden Texte an.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html> <head> <title>My page</title> </head> <body> <p class="opener">first paragraph</p> <p><em>second</em> paragraph</p> <p id="closer">final</p> </body> </html>
Werfen wir einen Blick auf den zweiten Absatz
<p><em>second</em> paragraph</p>
Sie können sehen, dass dies ein p-Tag ist. Es ist im Body-Tag enthalten. Body ist also der übergeordnete Knoten von p und p ist der untergeordnete Knoten. Der erste und dritte Absatz sind ebenfalls untergeordnete Knoten des Körpers. Sie sind alle Geschwisterknoten des zweiten Absatzes. Dieses em-Tag ist ein untergeordneter Knoten des zweiten Segments p. Daher ist p sein übergeordneter Knoten. Die Eltern-Kind-Knotenbeziehung kann eine baumartige Beziehung darstellen. Es heißt also DOM-Baum.
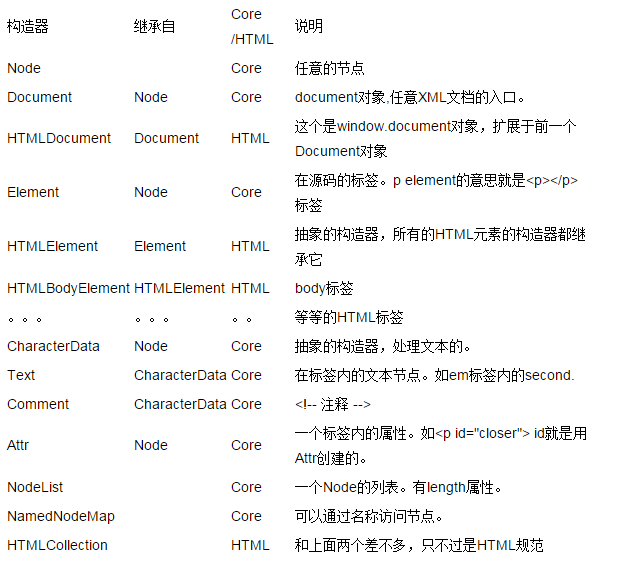
Kern-DOM und HTML-DOM
Wir wissen bereits, dass DOM HTML- und XML-Dokumente darstellen kann. Tatsächlich ist ein HTML-Dokument ein XML-Dokument, jedoch stärker standardisiert. Daher gilt die Core-DOM-Spezifikation als Teil von DOM Level 1 für alle XML-Dokumente und die HTML-DOM-Spezifikation erweitert das Core-DOM. Natürlich gilt HTML-DOM nicht für alle XML-Dokumente, sondern nur für HTML-Dokumente. Werfen wir einen Blick auf die Konstruktoren von Core DOM und HTML DOM.
Konstruktorbeziehung
Auf DOM-Knoten zugreifen
Bevor wir das Formular validieren oder das Bild ändern, müssen wir wissen, wie wir auf das Element (Element) zugreifen. Es gibt viele Möglichkeiten, Elemente zu erhalten.
Dokumentknoten
Wir können über Dokument auf das aktuelle Dokument zugreifen. Wir können Firebugs (Firefox-Plug-in) verwenden, um die Eigenschaften und Methoden des Dokuments anzuzeigen.
Alle Knoten verfügen über die Attribute „nodeType“, „nodeName“ und „nodeValue“. Werfen wir einen Blick auf den Knotentyp des Dokuments
document.nodeType;//9
Insgesamt gibt es 12 Knotentypen. Dokument ist 9. Häufig verwendete sind Element (Element: 1), Attribut (Attribut: 2) und Text (Text: 3).
Knoten haben auch Namen. für HTML-Tags. Der Knotenname ist der Labelname. Der Name des Textknotens (Text) ist #text. Der Name des Dokumentknotens (Dokument) ist #document.
Knoten haben auch Werte. Bei Textknoten ist der Wert der Text. Der Wert des Dokuments ist null
documentElement
XML verfügt über einen ROOT-Knoten zum Umschließen des Dokuments. für HTML-Dokumente. Der ROOT-Knoten ist das HTML-Tag. Greifen Sie auf den Wurzelknoten zu. Sie können die Eigenschaften von documentElement verwenden.
document.documentElement;//<html> document.documentElement.nodeType;//1 document.documentElement.nodeName;//HTML document.documentElement.tagName;//对于element,nodeName和tagName相同
Untergeordnete Knoten
Um festzustellen, ob es untergeordnete Knoten enthält, können wir die folgende Methode verwenden
document.documentElement.hasChildNodes();//true
HTML hat zwei untergeordnete Knoten.
document.documentElement.childNodes.length;//2 document.documentElement.childNodes[0];//<head> document.documentElement.childNodes[1];//<body>
Sie können auch über den untergeordneten Knoten
auf den übergeordneten Knoten zugreifendocument.documentElement.childNodes[1].parentNode;//<html>
Wir weisen der Variablen
die Referenz von body zuvar bd = document.documentElement.childNodes[1]; bd.childNodes.length;//9
Schauen wir uns die Struktur des Körpers an
<body> <p class="opener">first paragraph</p> <p><em>second</em> paragraph</p> <p id="closer">final</p> <!-- and that's about it --> </body>
Warum beträgt die Anzahl der untergeordneten Knoten 9?
Zuerst gibt es 4 P’s und einen Kommentar, insgesamt 4.
4 Knoten umfassen 3 leere Knoten. Das sind 7.
Der 8. leere Knoten zwischen Körper und erstem p.
Der neunte ist der leere Knoten zwischen dem Kommentar und
bd.childNodes[1];// <p class="opener">
Sie können überprüfen, ob es Attribute hat
bd.childNodes[1].hasAttributes();//true
Sie können auch die Anzahl der Attribute überprüfen
bd.childNodes[1].attributes.length;//1
//可以用index和名字来访问属性,也可以用getAttribute方法。
bd.childNodes[1].attributes[0].nodeName;//class
bd.childNodes[1].attributes[0].nodeValue;//opener
bd.childNodes[1].attributes['class'].nodeValue;//opener
bd.childNodes[1].getAttribute('class');//opener
Greifen Sie auf den Inhalt im Tag zu
Schauen wir uns das erste Tag p an
Sie können über die Eigenschaft textContent darauf zugreifen. Es ist zu beachten, dass textContent im IE-Browser nicht vorhanden ist. Bitte ersetzen Sie es durch innerText. Das Ergebnis ist dasselbe.
bg.childNodes[1].textContent;// "first paragraph"
Es gibt auch ein Attribut namens innerHTML. Dies ist keine DOM-Spezifikation. Aber alle gängigen Browser unterstützen dieses Attribut. Was zurückgegeben wird, ist HTML-Code.
bg.childNodes[1].innerHTML;// "first paragraph"
Der erste Absatz enthält keinen HTML-Code, daher ist das Ergebnis dasselbe wie textContent (innerText im IE). Werfen wir einen Blick auf das zweite Tag, das den HTML-Code
enthältbd.childNodes[3].innerHTML;//"<em>second</em> paragraph" bd.childNodes[3].textContent;//second paragraph
Eine andere Möglichkeit, den Textknoten und dann das Attribut nodeValue abzurufen, lautet wie folgt:
bd.childNodes[1].childNodes.length;//1 子节点个数 bd.childNodes[1].childNodes[0].nodeName;// 节点名称 #text bd.childNodes[1].childNodes[0].nodeValue;//节点值 first paragraph
快速访问DOM
通过childNodes,parentNode,nodeName,nodeValue以及attributes,可以访问文档任意的节点了。但是在实际运用过程中,文本节点是比较讨厌的。如果文本改变了,有可能就影响脚本了。还有如果DOM树足够的深入,那么访问起来的确有些不方便。幸好我们可以用更为方便的方法来访问节点。这些方法是
getElementsByTagName() getElementsByName() getElementById()
首先说下getElementsByTagName()
通过一个标签名称(tag name)来获取一个html元素的集合。例子如下
document.getElementsByTagName('p').length;//3
因为返回的是个集合,我们可以用过数组下标的形式来访问或者通过item方法。比较一下还是推荐用数组的访问方法。更简单一些。
document.getElementsByTagName('p')[0];// <p class="opener">
document.getElementsByTagName('p').item(0);//和上面的结果一样
document.getElementsByTagName('p')[0].innerHTML;//first paragraph
访问元素的属性,可以用attributes集合。但是更简单的方法是直接作为一个属性来访问就行。看个例子
document.getElementsByTagName('p')[2].id;//closer
要注意的是,class属性不能正常的使用。。要用className。因为class在javascript规范中是保留字。
document.getElementsByTagName('p')[0].className;//opener
我们可以用如下方法访问页面所有元素
<span style="color: #ff0000;">document.getElementsByTagName('*').length;//9</span>
注意:在IE早期的版本不支持上述方法。可以用document.all来取代。IE7已经支持了,但是返回的是所有节点(node),而不仅仅是元素节点(element nodes)。
Siblings, Body, First, Last Child
nextSibling和previousSibling是两个比较方便访问DOM的方法。用来访问相邻的节点的。例子如下
var para = document.getElementById('closer')
para.nextSibling;//"\n"
para.previousSibling;//"\n"
para.previousSibling.previousSibling;//<p>
para.previousSibling.previousSibling.previousSibling;//"\n"
para.previousSibling.previousSibling.nextSibling.nextSibling;// <p id="closer">
body 用来访问body元素的。
document.body;//<body>
firstChild 和lastChild 。firstChild是和childNodes[0]一样.lastChild和 childNodes[childNodes.length - 1]一样。
遍历DOM
通过以上的学习,我们可以写个函数,用来遍历DOM
function walkDOM(n) {
do {
alert(n);
if (n.hasChildNodes()) {
walkDOM(n.firstChild)
}
} while (n = n.nextSibling)
}
walkDOM(document.body);//测试
修改节点
下面来看看DOM节点的修改。
先获取要改变的节点。
var my = document.getElementById('closer');
非常容易更改这个元素的属性。我们可以更改innerHTML.
my.innerHTML = 'final';//final
因为innerHTML可以写入html,所以我们来修改html。
my.innerHTML = '<em>my</em> final';//<em>my</em> fnal
em标签已经成为dom树的一部分了。我们可以测试一下
my.firstChild;//<em> my.firstChild.firstChild;//my
我们也可以通过nodeValue来改变值。
my.firstChild.firstChild.nodeValue = 'your';//your
修改样式
大部分修改节点可能都是修改样式。元素节点有style属性用来修改样式。style的属性和css属性是一一对应的。如下代码
my.style.border = "1px solid red";
CSS属性很多都有破折号("-"),如padding-top,这在javascript中是不合法的。这样的话一定要省略波折号并把第二个词的开头字母大写,规范如下。 margin-left变为marginLeft。依此类推
my.style.fontWeight = 'bold';
我们还可以修改其他的属性,无论这些属性是否被初始化。
my.align = "right"; my.name = 'myname'; my.id = 'further'; my;//<p id="further" align="right" style="border: 1px solid red; font-weight: bold;">
创建节点
为了创建一个新的节点,可以使用createElement和createTextNode.如果新建完成,可以用appendChild()把节点添加到DOM树中。
创建一个元素P,并把设置innerHTML属性
var myp = document.createElement('p');
myp.innerHTML = 'yet another';
元素P建完成了,就可以随意修改添加属性了
myp.style.border = '2px dotted blue'
接下来可以用appendChild把新的节点添加到DOM树中的。
document.body.appendChild(myp)
使用DOM的方法
用innerHTML方法的确很简单,我们可以用纯的dom方法来实现上面的功能。
// 创建p
var myp = document.createElement('p');
// 创建一个文本节点
var myt = document.createTextNode('one more paragraph')
myp.appendChild(myt);
// 创建一个STRONG元素
var str = document.createElement('strong');
str.appendChild(document.createTextNode('bold'));
// 把STRONG元素添加到P中
myp.appendChild(str);
// 把P元素添加到BODY中
document.body.appendChild(myp);
//结果<p>one more paragraph<strong>bold</strong></p>
cloneNode()
另一种新建节点的方法是,我们可以用cloneNode来复制一个节点。cloneNode()可以传入一个boolean参数。如果为true就是深度复制,包括他的子节点,false,仅仅复制自己。
首先获取要复制的元素。
var el = document.getElementsByTagName('p')[1];//<p><em>second</em> paragraph</p>
先不用深度复制。
document.body.appendChild(el.cloneNode(false))
我们发现页面并没有变化,因为仅仅复制的是元素p。和下面的效果一样。
document.body.appendChild(document.createElement('p'));
如果用深度复制,包括p下面所有的子节点都会被复制。当然包括文本节点和EM元素。
document.body.appendChild(el.cloneNode(true))
insertBefore()
用appendChild,就是把元素添加到最后。而insertBefore方法可以更精确控制插入元素的位置。
elementNode.insertBefore(new_node,existing_node)
实例
document.body.insertBefore(
document.createTextNode('boo!'),
document.body.firstChild
);
意思就是新建一个文本节点,把它作为body元素的第一个节点。
删除节点
要从DOM树删除一个节点,我们可以使用removeChild().我们来看看要操作的HTML
<body> <p class="opener">first paragraph</p> <p><em>second</em> paragraph</p> <p id="closer">final</p> <!-- and that's about it --> </body>
来看看下面代码,删除第二段
var myp = document.getElementsByTagName('p')[1];
var removed = document.body.removeChild(myp);
removed节点就是删除的节点。以后还可以用这删除的节点。
我们也可以用replaceChild()方法。这个方法是删除一个节点,并用另一个节点替代。当执行上个删除节点操作之后,结果如下
<body> <p class="opener">first paragraph</p> <p id="closer">final</p> <!-- and that's about it --> </body>
我们来看看replaceChild的使用。我们把上一个删除节点来替代第二个p
var replaced = document.body.replaceChild(removed, p);
和removeChild返回一样。replaced就是移除的节点。现在结果为
<body> <p class="opener">first paragraph</p> <p><em>second</em> paragraph</p> <!-- and that's about it --> </body>
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



