

BP-Algorithmus für neuronale Netzwerke

Das BP-Netzwerk (Back Propagation) wurde 1986 von einer Gruppe von Wissenschaftlern unter der Leitung von Rumelhart und McCelland vorgeschlagen. Es ist ein mehrschichtiges Feedforward-Netzwerk, das nach dem Fehler-Back-Propagation-Algorithmus trainiert wurde Verwendetes neuronales Netzwerkmodell eins.
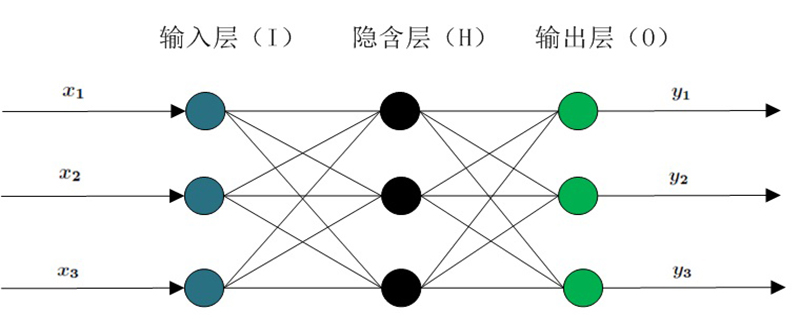
Das BP-Netzwerk kann eine große Anzahl von Eingabe-Ausgabe-Musterzuordnungsbeziehungen lernen und speichern, ohne die mathematischen Gleichungen, die diese Zuordnungsbeziehung beschreiben, im Voraus offenzulegen.
Seine Lernregel besteht darin, die Methode des steilsten Abstiegs zu verwenden und die Gewichte und Schwellenwerte des Netzwerks durch Backpropagation kontinuierlich anzupassen, um die Summe der quadratischen Fehler des Netzwerks zu minimieren. Die Topologiestruktur des neuronalen BP-Netzwerkmodells umfasst die Eingabeschicht, die verborgene Schicht und die Ausgabeschicht. (Empfohlenes Lernen: Web-Front-End-Video-Tutorial)
BP-Neuronales Netzwerk-Algorithmus wird auf der Grundlage des vorhandenen BP-Neuronalen Netzwerk-Algorithmus durch willkürliche Auswahl vorgeschlagen Mit einer Reihe von Gewichten wird die gegebene Zielausgabe direkt als algebraische Summe linearer Gleichungen verwendet, um ein System linearer Gleichungen zu erstellen. Die Lösung erfordert kein lokales Minimum und keine langsamen Konvergenzprobleme herkömmlicher Methoden zu verstehen.
BP-Algorithmus
Künstliche neuronale Netze (ANN) erschienen nach den 1940er Jahren. Es ist durch zahlreiche Neuronen regulierbar. Es ist durch Verbindungsgewichte verbunden und hat die Eigenschaften von großen -Skalierte Parallelverarbeitung, verteilte Informationsspeicherung und gute Selbstorganisations- und Selbstlernfähigkeiten werden zunehmend in den Bereichen Informationsverarbeitung, Mustererkennung, intelligente Steuerung und Systemmodellierung eingesetzt.
Insbesondere das Fehler-Backpropagation-Training (BP-Netzwerk) kann jede kontinuierliche Funktion annähern und verfügt über starke nichtlineare Abbildungsfähigkeiten sowie die Anzahl der Zwischenschichten des Netzwerks und die Verarbeitungseinheiten jeder Schicht. Parameter wie Die Anzahl und der Lernkoeffizient des Netzwerks können je nach Situation eingestellt werden. Die Flexibilität ist groß und spielt daher in vielen Anwendungsbereichen eine wichtige Rolle.
Um die Mängel des neuronalen BP-Netzwerks zu beheben, wie z. B. langsame Konvergenzgeschwindigkeit, Unfähigkeit, Konvergenz zum globalen Maximalpunkt zu garantieren, fehlende theoretische Anleitung bei der Auswahl der mittleren Schicht des Netzwerks und der Anzahl seiner Einheiten Aufgrund der Instabilität des Netzwerklernens und des Gedächtnisses wurden für diese Methode viele verbesserte Algorithmen vorgeschlagen.
Das obige ist der detaillierte Inhalt vonBP-Algorithmus für neuronale Netzwerke. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
Heutige Deep-Learning-Methoden konzentrieren sich darauf, die am besten geeignete Zielfunktion zu entwerfen, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird ein neues, leichtgewichtiges Netzwerk-Framework entworfen
 Die Grundlage, Grenze und Anwendung von GNN
Apr 11, 2023 pm 11:40 PM
Die Grundlage, Grenze und Anwendung von GNN
Apr 11, 2023 pm 11:40 PM
Graphische neuronale Netze (GNN) haben in den letzten Jahren rasante und unglaubliche Fortschritte gemacht. Das graphische neuronale Netzwerk, auch bekannt als Graph Deep Learning, Graph Representation Learning (Graph Representation Learning) oder geometrisches Deep Learning, ist das am schnellsten wachsende Forschungsthema im Bereich des maschinellen Lernens, insbesondere des Deep Learning. Der Titel dieser Veröffentlichung lautet „Basics, Frontiers and Applications of GNN“ und stellt hauptsächlich den allgemeinen Inhalt des umfassenden Buches „Basics, Frontiers and Applications of Graph Neural Networks“ vor, das von den Wissenschaftlern Wu Lingfei, Cui Peng, Pei Jian und Zhao zusammengestellt wurde Liang. 1. Einführung in graphische neuronale Netze 1. Warum Graphen studieren? Graphen sind eine universelle Sprache zur Beschreibung und Modellierung komplexer Systeme. Der Graph selbst ist nicht kompliziert, er besteht hauptsächlich aus Kanten und Knoten. Wir können Knoten verwenden, um jedes Objekt darzustellen, das wir modellieren möchten, und Kanten, um zwei darzustellen
 Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Die aktuellen Mainstream-KI-Chips sind hauptsächlich in drei Kategorien unterteilt: GPU, FPGA und ASIC. Sowohl GPU als auch FPGA sind im Frühstadium relativ ausgereifte Chiparchitekturen und Allzweckchips. ASIC ist ein Chip, der für bestimmte KI-Szenarien angepasst ist. Die Industrie hat bestätigt, dass CPUs nicht für KI-Computing geeignet sind, sie aber auch für KI-Anwendungen unerlässlich sind. Vergleich der GPU-Lösungsarchitektur zwischen GPU und CPU Die CPU folgt der von Neumann-Architektur, deren Kern die Speicherung von Programmen/Daten und die serielle sequentielle Ausführung ist. Daher benötigt die CPU-Architektur viel Platz zum Platzieren der Speichereinheit (Cache) und der Steuereinheit (Steuerung). Im Gegensatz dazu nimmt die Recheneinheit (ALU) nur einen kleinen Teil ein, sodass die CPU eine große Leistung erbringt Paralleles Rechnen.
 „Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
„Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
In Minecraft ist Redstone ein sehr wichtiger Gegenstand. Es ist ein einzigartiges Material im Spiel. Schalter, Redstone-Fackeln und Redstone-Blöcke können Drähten oder Objekten stromähnliche Energie verleihen. Mithilfe von Redstone-Schaltkreisen können Sie Strukturen aufbauen, mit denen Sie andere Maschinen steuern oder aktivieren können. Sie können selbst so gestaltet sein, dass sie auf die manuelle Aktivierung durch Spieler reagieren, oder sie können wiederholt Signale ausgeben oder auf Änderungen reagieren, die von Nicht-Spielern verursacht werden, beispielsweise auf Bewegungen von Kreaturen und Gegenstände. Fallen, Pflanzenwachstum, Tag und Nacht und mehr. Daher kann Redstone in meiner Welt extrem viele Arten von Maschinen steuern, von einfachen Maschinen wie automatischen Türen, Lichtschaltern und Blitzstromversorgungen bis hin zu riesigen Aufzügen, automatischen Farmen, kleinen Spielplattformen und sogar in Spielcomputern gebauten Maschinen . Kürzlich, B-Station UP main @
 Eine Drohne, die starken Winden standhält? Caltech nutzt 12 Minuten Flugdaten, um Drohnen das Fliegen im Wind beizubringen
Apr 09, 2023 pm 11:51 PM
Eine Drohne, die starken Winden standhält? Caltech nutzt 12 Minuten Flugdaten, um Drohnen das Fliegen im Wind beizubringen
Apr 09, 2023 pm 11:51 PM
Wenn der Wind stark genug ist, um den Schirm zu blasen, ist die Drohne stabil, genau wie folgt: Das Fliegen im Wind ist ein Teil des Fliegens in der Luft. Wenn der Pilot das Flugzeug aus großer Höhe landet, kann die Windgeschwindigkeit variieren Auf einer kleineren Ebene können böige Winde auch den Drohnenflug beeinträchtigen. Derzeit werden Drohnen entweder unter kontrollierten Bedingungen, ohne Wind, geflogen oder von Menschen per Fernbedienung gesteuert. Drohnen werden von Forschern gesteuert, um in Formationen am freien Himmel zu fliegen. Diese Flüge werden jedoch normalerweise unter idealen Bedingungen und Umgebungen durchgeführt. Damit Drohnen jedoch autonom notwendige, aber routinemäßige Aufgaben wie die Zustellung von Paketen ausführen können, müssen sie sich in Echtzeit an die Windverhältnisse anpassen können. Um Drohnen beim Fliegen im Wind wendiger zu machen, hat ein Team von Ingenieuren des Caltech
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
 Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Einleitung Im Bereich Computer Vision ist die genaue Messung der Bildähnlichkeit eine wichtige Aufgabe mit einem breiten Spektrum praktischer Anwendungen. Von Bildsuchmaschinen über Gesichtserkennungssysteme bis hin zu inhaltsbasierten Empfehlungssystemen ist die Fähigkeit, ähnliche Bilder effektiv zu vergleichen und zu finden, wichtig. Das siamesische Netzwerk bietet in Kombination mit Kontrastverlust einen leistungsstarken Rahmen für das datengesteuerte Erlernen der Bildähnlichkeit. In diesem Blogbeitrag werden wir uns mit den Details siamesischer Netzwerke befassen, das Konzept des Kontrastverlusts untersuchen und untersuchen, wie diese beiden Komponenten zusammenarbeiten, um ein effektives Bildähnlichkeitsmodell zu erstellen. Erstens besteht das siamesische Netzwerk aus zwei identischen Teilnetzwerken mit denselben Gewichten und Parametern. Jedes Subnetzwerk codiert das Eingabebild in einen Merkmalsvektor, der