

Kann PHP den Empfehlungsalgorithmus nicht verwenden?

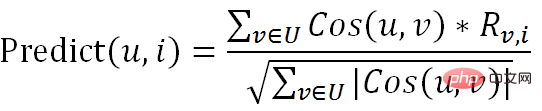
Kann PHP den Empfehlungsalgorithmus nicht verwenden?
Empfehlungsalgorithmen sind sehr alt und wurden benötigt und angewendet, bevor maschinelles Lernen aufkam.
Kollaborative Filterung (Collaborative Filtering) ist die klassischste Art von Empfehlungsalgorithmus, einschließlich Online-Zusammenarbeit und Offline-Filterung. Bei der sogenannten Online-Zusammenarbeit geht es darum, mithilfe von Online-Daten Artikel zu finden, die Benutzern gefallen könnten, während bei der Offline-Filterung einige Daten herausgefiltert werden, die keine Empfehlung wert sind, z. B. Daten mit niedrigem Empfehlungswert oder Daten, die Benutzer trotz hohem Empfehlungswert gekauft haben Empfehlungswert.
Im Folgenden wird erläutert, wie Sie mit PHP + MySQL einen einfachen kollaborativen Filteralgorithmus implementieren.
Um den kollaborativen Filterempfehlungsalgorithmus zu implementieren, müssen Sie zunächst die Kernidee und den Prozess des Algorithmus verstehen. Die Kernidee dieses Algorithmus lässt sich wie folgt zusammenfassen: Wenn a und b die gleiche Reihe von Elementen mögen (nennen wir b vorerst einen Nachbarn), dann mag a wahrscheinlich andere Elemente, die b mögen. Der Implementierungsprozess des Algorithmus lässt sich einfach wie folgt zusammenfassen: 1. Bestimmen Sie, welche Nachbarn a hat. 2. Verwenden Sie die Nachbarn, um vorherzusagen, welche Art von Artikeln a gefallen könnten.
Die Kernformel des Algorithmus lautet wie folgt:
1. Kosinusähnlichkeit (Nachbarn finden):
2. Vorhersageformel (sagen Sie voraus, welche Art von Artikeln Ihnen gefallen könnten):
Allein aus diesen beiden Formeln können wir ersehen, dass allein die Berechnung nach diesen beiden Formeln erfordert Es sind viele Schleifen und Beurteilungen erforderlich, außerdem sind Sortierprobleme mit der Auswahl und Verwendung von Sortieralgorithmen verbunden. Hier wählen wir die schnelle Sortierung.
Erstellen Sie zunächst eine Tabelle:
DROP TABLE IF EXISTS `tb_xttj`; CREATE TABLE `tb_xttj` ( `name` varchar(255) NOT NULL, `a` int(255) default NULL, `b` int(255) default NULL, `c` int(255) default NULL, `d` int(255) default NULL, `e` int(255) default NULL, `f` int(255) default NULL, `g` int(255) default NULL, `h` int(255) default NULL, PRIMARY KEY (`name`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1; INSERT INTO `tb_xttj` VALUES ('John', '4', '4', '5', '4', '3', '2', '1', null); INSERT INTO `tb_xttj` VALUES ('Mary', '3', '4', '4', '2', '5', '4', '3', null); INSERT INTO `tb_xttj` VALUES ('Lucy', '2', '3', null, '3', null, '3', '4', '5'); INSERT INTO `tb_xttj` VALUES ('Tom', '3', '4', '5', null, '1', '3', '5', '4'); INSERT INTO `tb_xttj` VALUES ('Bill', '3', '2', '1', '5', '3', '2', '1', '1'); INSERT INTO `tb_xttj` VALUES ('Leo', '3', '4', '5', '2', '4', null, null, null);

Hier empfehlen wir nur Leo in der letzten Zeile, um zu sehen, welches von f, g und h empfohlen werden kann ihm.
Verwenden Sie PHP + MySQL. Das Flussdiagramm lautet wie folgt:

Der Code zum Herstellen einer Verbindung zur Datenbank und zum Speichern als zweidimensionales Array lautet wie folgt:
header("Content-Type:text/html;charset=utf-8");
mysql_connect("localhost","root","admin");
mysql_select_db("geodatabase");
mysql_query("set names 'utf8'");
$sql = "SELECT * FROM tb_xttj";
$result = mysql_query($sql);
$array = array();
while($row=mysql_fetch_array($result))
{
$array[]=$row;//$array[][]是一个二维数组
}Frage 1: Diese Art der Abfrage ist für ein so kleines Demonstrationssystem in Ordnung, für ein großes Datensystem jedoch ineffizient .
Der Code zum Ermitteln des Cos-Werts von Leo und anderen lautet wie folgt:
/*
* 以下示例只求Leo的推荐,如此给变量命名我也是醉了;初次理解算法,先不考虑效率和逻辑的问题,主要把过程做出来
*/
$cos = array();
$cos[0] = 0;
$fm1 = 0;
//开始计算cos
//计算分母1,分母1是第一个公式里面 “*”号左边的内容,分母二是右边的内容
for($i=1;$i<9;$i++){
if($array[5][$i] != null){//$array[5]代表Leo
$fm1 += $array[5][$i] * $array[5][$i];
}
}
$fm1 = sqrt($fm1);
for($i=0;$i<5;$i++){
$fz = 0;
$fm2 = 0;
echo "Cos(".$array[5][0].",".$array[$i][0].")=";
for($j=1;$j<9;$j++){
//计算分子
if($array[5][$j] != null && $array[$i][$j] != null){
$fz += $array[5][$j] * $array[$i][$j];
}
//计算分母2
if($array[$i][$j] != null){
$fm2 += $array[$i][$j] * $array[$i][$j];
}
}
$fm2 = sqrt($fm2);
$cos[$i] = $fz/$fm1/$fm2;
echo $cos[$i]."<br/>";
}Das in diesem Schritt erhaltene Ergebnis:
wird sein Für eine gute Cos-Wertsortierung verwenden Sie den Schnellsortierungscode wie folgt:
//对计算结果进行排序,凑合用快排吧先
function quicksort($str){
if(count($str)<=1) return $str;//如果个数不大于一,直接返回
$key=$str[0];//取一个值,稍后用来比较;
$left_arr=array();
$right_arr=array();
for($i=1;$i<count($str);$i++){//比$key大的放在右边,小的放在左边;
if($str[$i]>=$key)
$left_arr[]=$str[$i];
else
$right_arr[]=$str[$i];
}
$left_arr=quicksort($left_arr);//进行递归;
$right_arr=quicksort($right_arr);
return array_merge($left_arr,array($key),$right_arr);//将左中右的值合并成一个数组;
}
$neighbour = array();//$neighbour只是对cos值进行排序并存储
$neighbour = quicksort($cos);Das $neighbour-Array speichert hier nur die Cos-Werte sortiert von groß nach klein und ist nicht mit Personen verbunden . Dieses Problem muss noch gelöst werden.
Wählen Sie die 3 Personen mit den höchsten CoS-Werten als Leos Nachbarn aus:
//$neighbour_set 存储最近邻的人和cos值
$neighbour_set = array();
for($i=0;$i<3;$i++){
for($j=0;$j<5;$j++){
if($neighbour[$i] == $cos[$j]){
$neighbour_set[$i][0] = $j;
$neighbour_set[$i][1] = $cos[$j];
$neighbour_set[$i][2] = $array[$j][6];//邻居对f的评分
$neighbour_set[$i][3] = $array[$j][7];//邻居对g的评分
$neighbour_set[$i][4] = $array[$j][8];//邻居对h的评分
}
}
}
print_r($neighbour_set);
echo "<p><br/>";Das Ergebnis dieses Schrittes:
Das ist eine Zwei -dimensionales Array, die Indizes der ersten Ebene des Arrays sind 0, 1, 2, was 3 Personen darstellt. Der Index 0 der zweiten Ebene stellt die Reihenfolge der Nachbarn in der Datentabelle dar, zum Beispiel ist Jhon die 0. Person in der Tabelle; der Index 1 repräsentiert den Cos-Wert von Leo und der Index 2, 3 und 4 repräsentieren das Nachbarpaar f bzw. g, h-Bewertung.
Starten Sie die Vorhersage, und der Berechnungscode für Predict lautet wie folgt:
Berechnen Sie Leos vorhergesagte Werte für f, g bzw. h. Hier gibt es ein Problem, nämlich wie man damit umgehen soll, wenn einige Nachbarn leere Werte für f, g, h haben. Beispielsweise sind die Bewertungen von Jhon und Mary für h leer. Instinktiv denke ich darüber nach, if zur Beurteilung zu verwenden, und wenn es leer ist, überspringe ich diese Berechnungsreihe, aber ob dies sinnvoll ist, muss noch geprüft werden. Der folgende Code schreibt dieses Urteil nicht.
//计算Leo对f的评分
$p_arr = array();
$pfz_f = 0;
$pfm_f = 0;
for($i=0;$i<3;$i++){
$pfz_f += $neighbour_set[$i][1] * $neighbour_set[$i][2];
$pfm_f += $neighbour_set[$i][1];
}
$p_arr[0][0] = 6;
$p_arr[0][1] = $pfz_f/sqrt($pfm_f);
if($p_arr[0][1]>3){
echo "推荐f";
}
//计算Leo对g的评分
$pfz_g = 0;
$pfm_g = 0;
for($i=0;$i<3;$i++){
$pfz_g += $neighbour_set[$i][1] * $neighbour_set[$i][3];
$pfm_g += $neighbour_set[$i][1];
$p_arr[1][0] = 7;
$p_arr[1][1] = $pfz_g/sqrt($pfm_g);
}
if($p_arr[0][1]>3){
echo "推荐g";
}
//计算Leo对h的评分
$pfz_h = 0;
$pfm_h = 0;
for($i=0;$i<3;$i++){
$pfz_h += $neighbour_set[$i][1] * $neighbour_set[$i][4];
$pfm_h += $neighbour_set[$i][1];
$p_arr[2][0] = 8;
$p_arr[2][1] = $pfz_h/sqrt($pfm_h);
}
print_r($p_arr);
if($p_arr[0][1]>3){
echo "推荐h";
}
$p_arr是对Leo的推荐数组,其内容类似如下;f ist die 6. Spalte, der Vorhersagewert ist 4,23, g ist die siebte Spalte, der Vorhersagewert ist 2,65...
Fertig f, g, h Es gibt zwei Verarbeitungsmethoden nach dem Vorhersagewert: Eine besteht darin, Leo Elemente mit einem Vorhersagewert von mehr als 3 zu empfehlen, und die andere besteht darin, die Vorhersagewerte von groß nach klein zu sortieren und Leo die beiden besten Elemente mit großen Vorhersagewerten zu empfehlen. Dieser Code wurde nicht geschrieben.
Wie aus dem obigen Beispiel ersichtlich ist, ist die Implementierung des Empfehlungsalgorithmus sehr mühsam und erfordert Schleifen, Beurteilung, Zusammenführen von Arrays usw. Bei unsachgemäßer Handhabung wird es zu einer Belastung für das System. Bei der tatsächlichen Verarbeitung treten weiterhin folgende Probleme auf:
1. Im obigen Beispiel empfehlen wir nur Leo, und wir wissen bereits, dass Leo die Elemente f, g, h nicht ausgewertet hat. In einem tatsächlichen System muss für jeden Benutzer, der eine Empfehlung abgeben muss, herausgefunden werden, welche Artikel er nicht bewertet hat, was einen weiteren Teil des Overheads darstellt.
2. Die gesamte Tabellenabfrage sollte nicht durchgeführt werden. Im tatsächlichen System können einige Standardwerte festgelegt werden. Beispiel: Wir finden den Cos-Wert zwischen Löwe und anderen Personen in der Tabelle. Wenn der Wert größer als 0,80 ist, bedeutet dies, dass sie Nachbarn sein können. Auf diese Weise höre ich auf, den Cos-Wert zu berechnen, wenn ich 10 Nachbarn finde, um zu vermeiden, dass die gesamte Tabelle abgefragt wird. Diese Methode kann auch sinnvoll für empfohlene Artikel verwendet werden. Ich empfehle beispielsweise nur 10 Artikel und höre auf, den Vorhersagewert zu berechnen, nachdem ich sie empfohlen habe.
3. Wenn das System verwendet wird, ändern sich auch die Elemente. Heute ist es fgh, und morgen kann es sein, dass sich die Elemente ändern.
4. Inhaltsbasierte Empfehlungen können entsprechend eingeführt werden, um den Empfehlungsalgorithmus zu verbessern.
5. Empfohlene Genauigkeitsprobleme wirken sich auf die Genauigkeit aus.
Weitere PHP-bezogene Kenntnisse finden Sie auf der PHP-Chinese-Website!
Das obige ist der detaillierte Inhalt vonKann PHP den Empfehlungsalgorithmus nicht verwenden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 PHP 8.4 Installations- und Upgrade-Anleitung für Ubuntu und Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 Installations- und Upgrade-Anleitung für Ubuntu und Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 bringt mehrere neue Funktionen, Sicherheitsverbesserungen und Leistungsverbesserungen mit einer beträchtlichen Menge an veralteten und entfernten Funktionen. In dieser Anleitung wird erklärt, wie Sie PHP 8.4 installieren oder auf PHP 8.4 auf Ubuntu, Debian oder deren Derivaten aktualisieren. Obwohl es möglich ist, PHP aus dem Quellcode zu kompilieren, ist die Installation aus einem APT-Repository wie unten erläutert oft schneller und sicherer, da diese Repositorys in Zukunft die neuesten Fehlerbehebungen und Sicherheitsupdates bereitstellen.
 So richten Sie Visual Studio-Code (VS-Code) für die PHP-Entwicklung ein
Dec 20, 2024 am 11:31 AM
So richten Sie Visual Studio-Code (VS-Code) für die PHP-Entwicklung ein
Dec 20, 2024 am 11:31 AM
Visual Studio Code, auch bekannt als VS Code, ist ein kostenloser Quellcode-Editor – oder eine integrierte Entwicklungsumgebung (IDE) –, die für alle gängigen Betriebssysteme verfügbar ist. Mit einer großen Sammlung von Erweiterungen für viele Programmiersprachen kann VS Code c
 Wie analysiert und verarbeitet man HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
Wie analysiert und verarbeitet man HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
Dieses Tutorial zeigt, wie XML -Dokumente mit PHP effizient verarbeitet werden. XML (Extensible Markup-Sprache) ist eine vielseitige textbasierte Markup-Sprache, die sowohl für die Lesbarkeit des Menschen als auch für die Analyse von Maschinen entwickelt wurde. Es wird üblicherweise für die Datenspeicherung ein verwendet und wird häufig verwendet
 7 PHP-Funktionen, die ich leider vorher nicht kannte
Nov 13, 2024 am 09:42 AM
7 PHP-Funktionen, die ich leider vorher nicht kannte
Nov 13, 2024 am 09:42 AM
Wenn Sie ein erfahrener PHP-Entwickler sind, haben Sie möglicherweise das Gefühl, dass Sie dort waren und dies bereits getan haben. Sie haben eine beträchtliche Anzahl von Anwendungen entwickelt, Millionen von Codezeilen debuggt und eine Reihe von Skripten optimiert, um op zu erreichen
 Erklären Sie JSON Web Tokens (JWT) und ihren Anwendungsfall in PHP -APIs.
Apr 05, 2025 am 12:04 AM
Erklären Sie JSON Web Tokens (JWT) und ihren Anwendungsfall in PHP -APIs.
Apr 05, 2025 am 12:04 AM
JWT ist ein offener Standard, der auf JSON basiert und zur sicheren Übertragung von Informationen zwischen Parteien verwendet wird, hauptsächlich für die Identitätsauthentifizierung und den Informationsaustausch. 1. JWT besteht aus drei Teilen: Header, Nutzlast und Signatur. 2. Das Arbeitsprinzip von JWT enthält drei Schritte: Generierung von JWT, Überprüfung von JWT und Parsingnayload. 3. Bei Verwendung von JWT zur Authentifizierung in PHP kann JWT generiert und überprüft werden, und die Funktionen und Berechtigungsinformationen der Benutzer können in die erweiterte Verwendung aufgenommen werden. 4. Häufige Fehler sind Signaturüberprüfungsfehler, Token -Ablauf und übergroße Nutzlast. Zu Debugging -Fähigkeiten gehört die Verwendung von Debugging -Tools und Protokollierung. 5. Leistungsoptimierung und Best Practices umfassen die Verwendung geeigneter Signaturalgorithmen, das Einstellen von Gültigkeitsperioden angemessen.
 PHP -Programm zum Zählen von Vokalen in einer Zeichenfolge
Feb 07, 2025 pm 12:12 PM
PHP -Programm zum Zählen von Vokalen in einer Zeichenfolge
Feb 07, 2025 pm 12:12 PM
Eine Zeichenfolge ist eine Folge von Zeichen, einschließlich Buchstaben, Zahlen und Symbolen. In diesem Tutorial wird lernen, wie Sie die Anzahl der Vokale in einer bestimmten Zeichenfolge in PHP unter Verwendung verschiedener Methoden berechnen. Die Vokale auf Englisch sind a, e, i, o, u und sie können Großbuchstaben oder Kleinbuchstaben sein. Was ist ein Vokal? Vokale sind alphabetische Zeichen, die eine spezifische Aussprache darstellen. Es gibt fünf Vokale in Englisch, einschließlich Großbuchstaben und Kleinbuchstaben: a, e, ich, o, u Beispiel 1 Eingabe: String = "TutorialPoint" Ausgabe: 6 erklären Die Vokale in der String "TutorialPoint" sind u, o, i, a, o, ich. Insgesamt gibt es 6 Yuan
 Erklären Sie die späte statische Bindung in PHP (statisch: :).
Apr 03, 2025 am 12:04 AM
Erklären Sie die späte statische Bindung in PHP (statisch: :).
Apr 03, 2025 am 12:04 AM
Statische Bindung (statisch: :) implementiert die späte statische Bindung (LSB) in PHP, sodass das Aufrufen von Klassen in statischen Kontexten anstatt Klassen zu definieren. 1) Der Analyseprozess wird zur Laufzeit durchgeführt.
 Was sind PHP Magic -Methoden (__construct, __Destruct, __call, __get, __set usw.) und geben Sie Anwendungsfälle an?
Apr 03, 2025 am 12:03 AM
Was sind PHP Magic -Methoden (__construct, __Destruct, __call, __get, __set usw.) und geben Sie Anwendungsfälle an?
Apr 03, 2025 am 12:03 AM
Was sind die magischen Methoden von PHP? Zu den magischen Methoden von PHP gehören: 1. \ _ \ _ Konstrukt, verwendet, um Objekte zu initialisieren; 2. \ _ \ _ Destruct, verwendet zur Reinigung von Ressourcen; 3. \ _ \ _ Call, behandeln Sie nicht existierende Methodenaufrufe; 4. \ _ \ _ GET, Implementieren Sie den dynamischen Attributzugriff; 5. \ _ \ _ Setzen Sie dynamische Attributeinstellungen. Diese Methoden werden in bestimmten Situationen automatisch aufgerufen, wodurch die Code -Flexibilität und -Effizienz verbessert werden.
