

Redis-Speichermodell (ausführliche Erklärung)

Redis ist derzeit eine der beliebtesten In-Memory-Datenbanken und verbessert die Lese- und Schreibgeschwindigkeit erheblich. Man kann sagen, dass Redis ein unverzichtbarer Bestandteil für die Erzielung einer hohen Parallelität auf der Website ist . [Empfohlenes Lernen: Redis-Video-Tutorial]

Wenn wir Redis verwenden, kommen wir mit den 5 Objekttypen von Redis (String, Hash) in Kontakt , list , Sammlungen, geordnete Sammlungen) sind Rich Types ein großer Vorteil von Redis gegenüber Memcached usw. Auf der Grundlage des Verständnisses der Verwendung und der Eigenschaften der fünf Objekttypen von Redis wird ein weiteres Verständnis des Speichermodells von Redis für die Verwendung von Redis von großem Nutzen sein, zum Beispiel:
1. Schätzen Sie die Speichernutzung von Redis. Bisher sind die Kosten für die Speichernutzung noch relativ hoch, und eine vernünftige Bewertung der Speichernutzung von Redis anhand der Anforderungen und die Auswahl der geeigneten Maschinenkonfiguration können Kosten sparen und gleichzeitig die Anforderungen erfüllen.
2. Speichernutzung optimieren. Wenn Sie das Redis-Speichermodell verstehen, können Sie geeignetere Datentypen und Codierungen auswählen und den Redis-Speicher besser nutzen.
3. Probleme analysieren und lösen. Wenn in Redis Probleme wie Blockierung und Speichernutzung auftreten, sollte die Ursache des Problems so schnell wie möglich ermittelt werden, um die Analyse und Lösung zu erleichtern.
In diesem Artikel wird hauptsächlich das Speichermodell von Redis vorgestellt (am Beispiel von 3.0), einschließlich des von Redis belegten Speichers und seiner Abfrage, der Codierung verschiedener Objekttypen im Speicher und der Speicherzuweisung (jemalloc). , Einfache dynamische Zeichenfolge (SDS), RedisObject usw.; auf dieser Grundlage werden dann mehrere Anwendungen des Redis-Speichermodells vorgestellt.
1. Redis-Speicherstatistik
Wenn Sie Ihre Arbeit gut machen möchten, müssen Sie zunächst Ihre Tools schärfen. Bevor Sie den Redis-Speicher erklären, erklären Sie zunächst, wie Sie die Speichernutzung von Redis zählen.
Nachdem sich der Client über redis-cli mit dem Server verbunden hat (wenn später keine besonderen Anweisungen vorliegen, verwendet der Client immer redis-cli), können Sie die Speichernutzung mit dem Info-Befehl überprüfen:
info memory
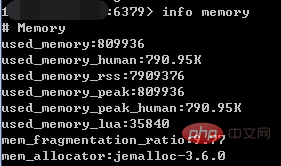
Unter anderem kann der Info-Befehl viele Informationen über den Redis-Server anzeigen, einschließlich grundlegender Serverinformationen, CPU, Speicher, Persistenz, Client-Verbindungsinformationen usw.; Ein Parameter, der angibt, dass nur speicherbezogene Informationen angezeigt werden.
Einige der wichtigeren Anweisungen in den zurückgegebenen Ergebnissen lauten wie folgt:
(1) used_memory: Die Gesamtmenge des von zugewiesenen Speichers der Redis-Allokator (Einheit ist Bytes), einschließlich des verwendeten virtuellen Speichers (d. h. Swap); der Redis-Allokator wird später eingeführt. used_memory_human wird einfach freundlicher angezeigt.
(2)used_memory_rss: Der Redis-Prozess belegt den Speicher des Betriebssystems (Einheit ist Bytes), was mit dem von oben und angezeigten Wert übereinstimmt ps-Befehle; Zusätzlich zum vom Allokator zugewiesenen Speicher enthält used_memory_rss auch den für die Ausführung des Prozesses erforderlichen Speicher, Speicherfragmente usw., jedoch keinen virtuellen Speicher.
Daher ist used_memory und used_memory_rss ersterer der Betrag, der aus Redis-Perspektive erhalten wird, und letzterer ist der Betrag, der aus Sicht des Betriebssystems erhalten wird. Der Grund, warum die beiden unterschiedlich sind, besteht darin, dass einerseits die Speicherfragmentierung und der zum Ausführen des Redis-Prozesses erforderliche Speicher kleiner sein können als der letztere, andererseits kann es sein, dass ersterer aufgrund der Existenz von virtuellem Speicher vorhanden ist größer als letzteres.
Da in tatsächlichen Anwendungen die Datenmenge in Redis relativ groß ist, ist der vom Prozess zu diesem Zeitpunkt belegte Speicher viel kleiner als die Menge der Redis-Daten und der Speicherfragmente von used_memory_rss zu used_memory ist Es ist zu einem Parameter zur Messung der Redis-Speicherfragmentierungsrate geworden; dieser Parameter ist mem_fragmentation_ratio.
(3)mem_fragmentation_ratio: Speicherfragmentierungsverhältnis, dieser Wert ist das Verhältnis von used_memory_rss/used_memory.
mem_fragmentation_ratio ist im Allgemeinen größer als 1. Je größer der Wert, desto größer ist das Speicherfragmentierungsverhältnis. mem_fragmentation_ratio <1, was darauf hinweist, dass Redis den virtuellen Speicher verwendet, ist er viel langsamer als der Speicher. Wenn diese Situation auftritt, sollte sie rechtzeitig überprüft werden B. das Hinzufügen von Redis-Knoten, das Hinzufügen von Redis-Serverspeicher, optimierte Anwendungen usw.
Im Allgemeinen befindet sich mem_fragmentation_ratio in einem relativ gesunden Zustand um 1,03 (für Jemalloc); der Wert von mem_fragmentation_ratio im obigen Screenshot ist sehr groß, da die Daten nicht in Redis gespeichert wurden und der Redis-Prozess selbst ausgeführt wird Der Speicher macht used_memory_rss viel größer als used_memory.
(4)mem_allocator: Der von Redis verwendete Speicherzuweiser, der zur Kompilierzeit angegeben werden kann; es kann libc, jemalloc oder tcmalloc sein, der Standardwert ist jemalloc; im Screenshot Der Standardwert ist jemalloc.
2. Redis-Speicheraufteilung
Redis ist eine In-Memory-Datenbank, und der im Speicher gespeicherte Inhalt besteht hauptsächlich aus Daten (Schlüssel-Wert-Paare). dass neben Daten auch andere Teile von Redis Speicher beanspruchen.
Die Speichernutzung von Redis kann hauptsächlich in die folgenden Teile unterteilt werden:
1. Daten
Daten sind der wichtigste Teil; Die Statistik dieses Teils befindet sich im used_memory.
Redis verwendet Schlüssel-Wert-Paare zum Speichern von Daten. Die Werte (Objekte) umfassen 5 Typen, nämlich Zeichenfolgen, Hashes, Listen, Mengen und geordnete Mengen. Diese 5 Typen werden von Redis für die Außenwelt bereitgestellt. Tatsächlich kann jeder Typ innerhalb von Redis über zwei oder mehr interne Codierungsimplementierungen verfügen. Wenn Redis Objekte speichert, werden die Daten nicht direkt in den Speicher geworfen wird auf verschiedene Arten verpackt: z. B. redisObject, SDS usw.; dieser Artikel wird sich später auf die Details der Datenspeicherung in Redis konzentrieren.
2. Der zum Ausführen des Prozesses selbst erforderliche Speicher
Der Redis-Hauptprozess selbst benötigt zum Ausführen definitiv Speicher, z. B. Code, Konstantenpool usw.; Einige Megabyte und in den meisten Produktionsumgebungen Im Vergleich zum von Redis-Daten belegten Speicher kann dies ignoriert werden. Dieser Teil des Speichers wird von jemalloc nicht zugewiesen und wird daher nicht in used_memory gezählt.
Zusätzlicher Hinweis: Zusätzlich zum Hauptprozess belegt die Ausführung von von Redis erstellten Unterprozessen auch Speicher, z. B. die Unterprozesse, die erstellt werden, wenn Redis AOF- und RDB-Umschreibungen durchführt. Dieser Teil des Speichers gehört natürlich nicht zum Redis-Prozess und wird nicht in used_memory und used_memory_rss gezählt.
3. Pufferspeicher
Der Pufferspeicher umfasst den Client-Puffer, den Kopier-Backlog-Puffer usw.; der Client-Puffer speichert den Eingabe- und Ausgabepuffer der Client-Verbindung Kopierrückstand Der Puffer wird für einen Teil der Kopierfunktion verwendet; der AOF-Puffer wird zum Speichern des letzten Schreibbefehls während des AOF-Neuschreibens verwendet. Bevor Sie die entsprechenden Funktionen verstehen, müssen Sie die Details dieser Puffer nicht kennen. Dieser Teil des Speichers wird von jemalloc zugewiesen und wird daher in used_memory gezählt.
4. Speicherfragmentierung
Speicherfragmentierung wird von Redis während des Prozesses der Zuweisung und Wiederverwendung von physischem Speicher erzeugt. Wenn sich die Daten beispielsweise häufig ändern und die Datengröße sehr unterschiedlich ist, wird der von Redis freigegebene Speicherplatz möglicherweise nicht im physischen Speicher freigegeben, Redis kann ihn jedoch nicht effektiv nutzen, was zu einer Speicherfragmentierung führt. Die Speicherfragmentierung wird in used_memory nicht gezählt.
Die Erzeugung von Speicherfragmentierung hängt mit der Datenverarbeitung, den Eigenschaften der Daten usw. zusammen. Darüber hinaus hängt sie auch mit dem verwendeten Speicherzuteiler zusammen: Wenn der Speicherzuteiler angemessen ausgelegt ist Das Auftreten von Speicherfragmentierung kann so weit wie möglich reduziert werden. Jemalloc, das später besprochen wird, leistet gute Arbeit bei der Kontrolle der Speicherfragmentierung.
Wenn die Speicherfragmentierung im Redis-Server bereits groß ist, können Sie die Speicherfragmentierung durch einen sicheren Neustart reduzieren: Denn nach dem Neustart liest Redis die Daten erneut aus der Backup-Datei und ordnet sie im Speicher neu an. Wählen Sie für alle Daten die entsprechende Speichereinheit erneut aus, um die Speicherfragmentierung zu reduzieren.
3. Details zur Redis-Datenspeicherung
1. Übersicht
Details zur Redis-Datenspeicherung umfassen Speicherzuweiser (z. B. Jemalloc), einfache dynamische Zeichenfolgen (SDS), 5 Objekttypen und interne Codierung, redisObject. Bevor ich den spezifischen Inhalt beschreibe, möchte ich zunächst die Beziehung zwischen diesen Konzepten erläutern.
Die folgende Abbildung zeigt das Datenmodell, das bei der Ausführung von set hello world beteiligt ist.
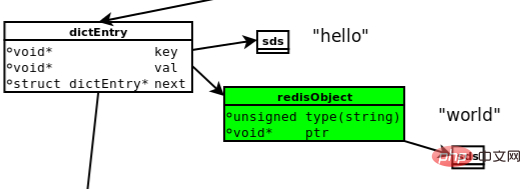
Bildquelle: https://searchdatabase.techtarget.com.cn/7-20218/
(1) dictEntry: Redis ist Schlüsselwert Datenbank, daher gibt es für jedes Schlüssel-Wert-Paar einen dictEntry, der Zeiger auf Schlüssel und Wert speichert und auf den nächsten dictEntry verweist, der nichts mit diesem Schlüsselwert zu tun hat.
(2) Schlüssel: Wie in der oberen rechten Ecke des Bildes zu sehen ist, wird Schlüssel („Hallo“) nicht direkt als Zeichenfolge gespeichert, sondern in der SDS-Struktur.
(3) redisObject: Value("world") wird weder direkt als String noch direkt im SDS wie Key gespeichert, sondern in redisObject. Unabhängig davon, um welchen der fünf Werttypen es sich handelt, wird er über redisObject gespeichert. Das Typfeld in redisObject gibt den Typ des Wertobjekts an, und das PTR-Feld zeigt auf die Adresse des Objekts. Es ist jedoch ersichtlich, dass das Zeichenfolgenobjekt zwar von redisObject gepackt wird, aber dennoch über SDS gespeichert werden muss.
Tatsächlich verfügt redisObject zusätzlich zu den Feldern „type“ und „ptr“ über weitere Felder, die im Diagramm nicht angezeigt werden, z. B. Felder, die zur Angabe der internen Codierung des Objekts verwendet werden. Diese werden später ausführlich vorgestellt.
(4) jemalloc: Unabhängig davon, ob es sich um ein DictEntry-Objekt, ein redisObject oder ein SDS-Objekt handelt, ist ein Speicherzuweiser (z. B. jemalloc) erforderlich, um Speicher für die Speicherung zuzuweisen. Am Beispiel des DictEntry-Objekts besteht es aus 3 Zeigern und belegt 24 Bytes auf einem 64-Bit-Computer. Jemalloc weist ihm eine 32-Byte-Speichereinheit zu.
Im Folgenden werden jemalloc, redisObject, SDS, Objekttypen und interne Codierung vorgestellt.
2. jemalloc
Redis gibt beim Kompilieren einen Speicherzuweiser an; der Speicherzuweiser kann libc, jemalloc oder tcmalloc sein, und der Standardwert ist jemalloc.
jemalloc, als Standard-Speicherzuweiser von Redis, leistet relativ gute Arbeit bei der Reduzierung der Speicherfragmentierung. In 64-Bit-Systemen unterteilt jemalloc den Speicherplatz in drei Bereiche: klein, groß und riesig. Wenn Redis Daten speichert, wählt es den Speicherblock mit der am besten geeigneten Größe aus. Lagerung.
Die durch jemalloc geteilten Speichereinheiten sind wie folgt:
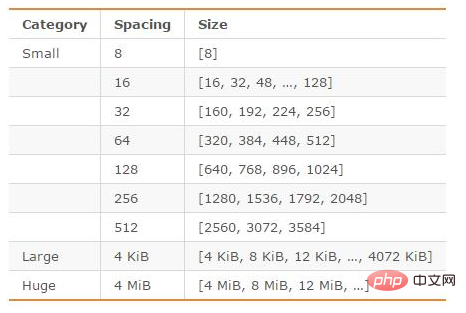
图片来源:http://blog.csdn.net/zhengpeitao/article/details/76573053
例如,如果需要存储大小为130字节的对象,jemalloc会将其放入160字节的内存单元中。
3、redisObject
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过redisObject对象进行存储。
redisObject对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持,下面将通过redisObject的结构来说明它是如何起作用的。
redisObject的定义如下(不同版本的Redis可能稍稍有所不同):
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;redisObject的每个字段的含义和作用如下:
(1)type
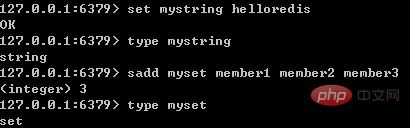
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
当我们执行type命令时,便是通过读取RedisObject的type字段获得对象的类型;如下图所示:
(2)encoding
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
通过object encoding命令,可以查看对象采用的编码方式,如下图所示:
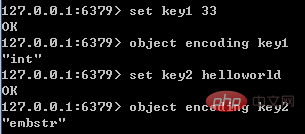
5种对象类型对应的编码方式以及使用条件,将在后面介绍。
(3)lru
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。
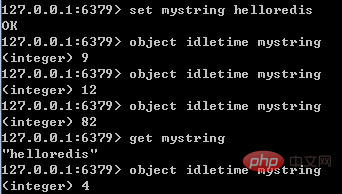
lru值除了通过object idletime命令打印之外,还与Redis的内存回收有关系:如果Redis打开了maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys—lru,那么当Redis内存占用超过maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
(4)refcount
refcount与共享对象
refcount记录的是该对象被引用的次数,类型为整型。refcount的作用,主要在于对象的引用计数和内存回收。当创建新对象时,refcount初始化为1;当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
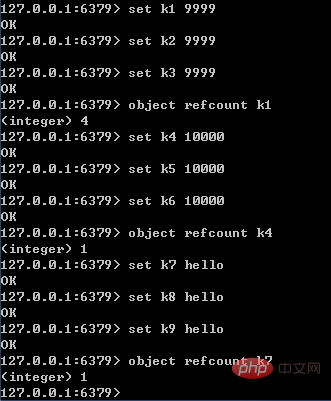
Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
共享对象的具体实现
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为O(1);对于普通字符串,判断复杂度为O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
就目前的实现来说,Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;当Redis需要使用值为0~9999的字符串对象时,可以直接使用这些共享对象。10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值进行改变。
共享对象的引用次数可以通过object refcount命令查看,如下图所示。命令执行的结果页佐证了只有0~9999之间的整数会作为共享对象。
(5)ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
(6)总结
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节:
4bit+4bit+24bit+4Byte+8Byte=16Byte。
4、SDS
Redis没有直接使用C字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。
(1)SDS结构
sds的结构如下:
struct sdshdr {
int len;
int free;
char buf[];
};其中,buf表示字节数组,用来存储字符串;len表示buf已使用的长度,free表示buf未使用的长度。下面是两个例子。
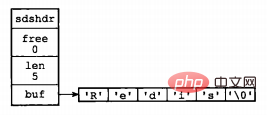
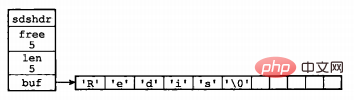
图片来源:《Redis设计与实现》
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
(2)SDS与C字符串的比较
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
- 获取字符串长度:SDS是O(1),C字符串是O(n)
- 缓冲区溢出:使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
- 修改字符串时内存的重分配:对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
- 存取二进制数据:SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
此外,由于SDS中的buf仍然使用了C字符串(即以’\0’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。
(3)SDS与C字符串的应用
Redis在存储对象时,一律使用SDS代替C字符串。例如set hello world命令,hello和world都是以SDS的形式存储的。而sadd myset member1 member2 member3命令,不论是键(”myset”),还是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式存储。除了存储对象,SDS还用于存储各种缓冲区。
只有在字符串不会改变的情况下,如打印日志时,才会使用C字符串。
四、Redis的对象类型与内部编码
前面已经说过,Redis支持5种对象类型,而每种结构都有至少两种编码;这样做的好处在于:一方面接口与实现分离,当需要增加或改变内部编码时,用户使用不受影响,另一方面可以根据不同的应用场景切换内部编码,提高效率。
Redis各种对象类型支持的内部编码如下图所示(图中版本是Redis3.0,Redis后面版本中又增加了内部编码,略过不提;本章所介绍的内部编码都是基于3.0的):
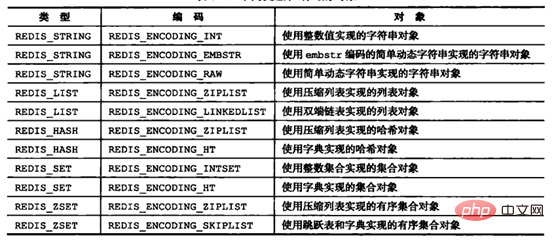
Bildquelle: „Redis-Design und -Implementierung“
Die Konvertierung der internen Redis-Kodierung entspricht den folgenden Regeln: Die Kodierungskonvertierung erfolgt in Redis ist beim Schreiben von Daten abgeschlossen und der Konvertierungsprozess ist irreversibel. Er kann nur von der Codierung mit kleinem Speicher in die Codierung mit großem Speicher konvertiert werden.
1. String
(1) Übersicht
String ist der grundlegendste Typ, da alle Schlüssel vom Typ String sind und string Mehrere andere komplexe Elementtypen sind auch Strings.
Die Zeichenfolgenlänge darf 512 MB nicht überschreiten.
(2) Interne Codierung
Es gibt drei interne Codierungen für String-Typen. Ihre Anwendungsszenarien sind wie folgt:
- int: 8 Bytes langer Integer-Typ. Wenn der Zeichenfolgenwert eine Ganzzahl ist, wird der Wert durch eine lange Ganzzahl dargestellt.
- embstr: <=39-Byte-Zeichenfolge. Sowohl Embstr als auch Raw verwenden RedisObject und SDS zum Speichern von Daten. Der Unterschied besteht darin, dass Embstr nur einmal Speicherplatz zuweist (daher sind RedisObject und SDS kontinuierlich), während Raw zweimal Speicherplatz zuordnen muss (Platz für RedisObject bzw. SDS zuweisen). Daher besteht der Vorteil von Embstr im Vergleich zu Raw darin, dass es beim Erstellen einmal weniger Platz zuweist, beim Löschen einmal weniger Platz freigibt und alle Daten des Objekts miteinander verbunden sind, was das Auffinden erleichtert. Die Nachteile von Embstr liegen ebenfalls auf der Hand. Wenn die Länge der Zeichenfolge zunimmt und Speicher neu zugewiesen werden muss, müssen das gesamte RedisObject und SDS neu zugewiesen werden. Daher ist Embstr in Redis schreibgeschützt.
- raw: Zeichenfolge größer als 39 Bytes
Das Beispiel sieht wie folgt aus:
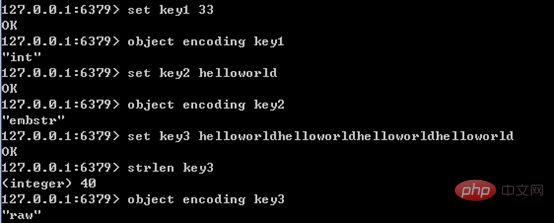
embstr und raw Die Länge von Der Unterschied liegt bei 39. Dies liegt daran, dass die Länge von redisObject 16 Bytes und die Länge von sds 9 + Stringlänge beträgt. Wenn die Stringlänge also 39 beträgt, beträgt die Länge von embstr genau 16+9+39=64, jemalloc Es können 64 Byte Speichereinheiten zugewiesen werden.
(3) Kodierungskonvertierung
Wenn die int-Daten keine Ganzzahl mehr sind oder die Größe den Bereich von long überschreitet, werden sie automatisch in Raw konvertiert.
Da die Implementierung von Embstr schreibgeschützt ist, wird das Embstr-Objekt vor der Änderung in Raw konvertiert. Daher muss das geänderte Objekt so lange wie das Embstr-Objekt geändert werden raw, unabhängig davon, ob es 39 Bytes erreicht. Ein Beispiel ist in der folgenden Abbildung dargestellt:
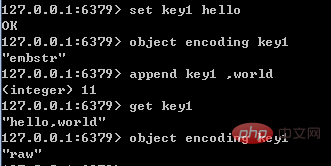
2. Liste
(1) Übersicht
Liste (Liste) wird verwendet Speichern Sie mehrere Objekte. Jede Zeichenfolge wird als Element bezeichnet. Eine Liste kann 2 ^ 32-1 Elemente speichern. Listen in Redis unterstützen das Einfügen und Einfügen an beiden Enden und können Elemente an einer bestimmten Position (oder einem bestimmten Bereich) abrufen und als Arrays, Warteschlangen, Stapel usw. fungieren.
(2) Interne Codierung
Die interne Codierung der Liste kann eine komprimierte Liste (Ziplist) oder eine doppelendige verknüpfte Liste (Linkedlist) sein.
Doppelend verknüpfte Liste: Sie besteht aus einer Listenstruktur und mehreren listNode-Strukturen. Die typische Struktur ist wie folgt:
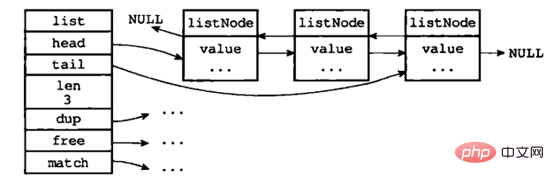
Bildquelle: „ Redis-Design und -Implementierung》
Wie aus der Abbildung ersichtlich ist, speichert die doppelendige verknüpfte Liste sowohl den Kopfzeiger als auch den Endzeiger, und jeder Knoten verfügt über Zeiger, die vorwärts und rückwärts auf die Länge der Liste zeigen wird in der verknüpften Liste gespeichert; dup-, free- und match-set-typspezifische Funktionen für Knotenwerte, sodass verknüpfte Listen zum Speichern verschiedener Wertetypen verwendet werden können. Jeder Knoten in der verknüpften Liste zeigt auf ein redisObject, dessen Typ eine Zeichenfolge ist.
Komprimierte Liste: Die komprimierte Liste wurde von Redis entwickelt, um Speicherplatz zu sparen. Sie besteht aus einer Reihe speziell codierter kontinuierlicher Speicherblöcke (und nicht wie eine Doppel-). Ende der verknüpften Liste: Jeder Knoten ist eine sequentielle Datenstruktur, die aus Zeigern besteht. Die spezifische Struktur ist relativ kompliziert und wird weggelassen. Im Vergleich zu doppelendigen verknüpften Listen können komprimierte Listen Speicherplatz sparen, aber die Komplexität ist höher, wenn die Anzahl der Knoten gering ist ist groß, es werden immer noch doppelt verkettete Listen verwendet. Gutes Geschäft.
Komprimierte Listen werden nicht nur zum Implementieren von Listen verwendet, sondern auch zum Implementieren von Hashes und geordneten Listen.
(3) Kodierungskonvertierung
Eine komprimierte Liste wird nur verwendet, wenn die folgenden zwei Bedingungen erfüllt sind: Die Anzahl der Elemente in der Liste beträgt weniger als 512; alle Zeichenfolgenobjekte in der Liste sind weniger als 64 Zeichen Festival. Wenn eine Bedingung nicht erfüllt ist, wird eine doppelendige Liste verwendet und die Codierung kann nur von einer komprimierten Liste in eine doppelendige verknüpfte Liste konvertiert werden, und die umgekehrte Richtung ist nicht möglich.
Die folgende Abbildung zeigt die Merkmale der Listenkodierungskonvertierung:
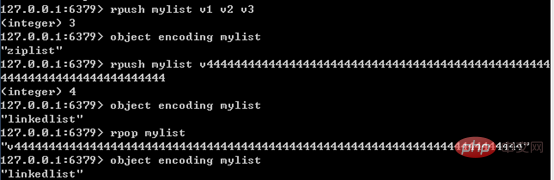
其中,单个字符串不能超过64字节,是为了便于统一分配每个节点的长度;这里的64字节是指字符串的长度,不包括SDS结构,因为压缩列表使用连续、定长内存块存储字符串,不需要SDS结构指明长度。后面提到压缩列表,也会强调长度不超过64字节,原理与这里类似。
3、哈希
(1)概况
哈希(作为一种数据结构),不仅是redis对外提供的5种对象类型的一种(与字符串、列表、集合、有序结合并列),也是Redis作为Key-Value数据库所使用的数据结构。为了说明的方便,在本文后面当使用“内层的哈希”时,代表的是redis对外提供的5种对象类型的一种;使用“外层的哈希”代指Redis作为Key-Value数据库所使用的数据结构。
(2)内部编码
内层的哈希使用的内部编码可以是压缩列表(ziplist)和哈希表(hashtable)两种;Redis的外层的哈希则只使用了hashtable。
压缩列表前面已介绍。与哈希表相比,压缩列表用于元素个数少、元素长度小的场景;其优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于哈希中元素数量较少,因此操作的时间并没有明显劣势。
hashtable:一个hashtable由1个dict结构、2个dictht结构、1个dictEntry指针数组(称为bucket)和多个dictEntry结构组成。
正常情况下(即hashtable没有进行rehash时)各部分关系如下图所示:
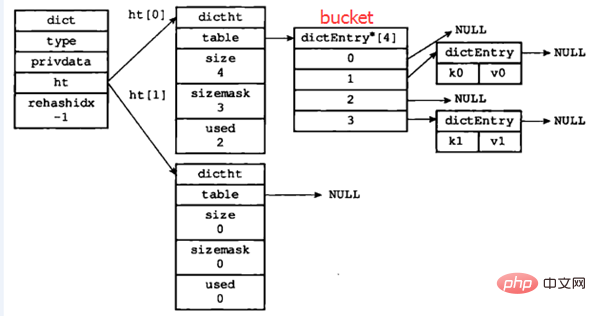
图片改编自:《Redis设计与实现》
下面从底层向上依次介绍各个部分:
dictEntry
dictEntry结构用于保存键值对,结构定义如下:
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;
}dictEntry;其中,各个属性的功能如下:
- key:键值对中的键;
- val:键值对中的值,使用union(即共用体)实现,存储的内容既可能是一个指向值的指针,也可能是64位整型,或无符号64位整型;
- next:指向下一个dictEntry,用于解决哈希冲突问题
在64位系统中,一个dictEntry对象占24字节(key/val/next各占8字节)。
bucket
bucket是一个数组,数组的每个元素都是指向dictEntry结构的指针。redis中bucket数组的大小计算规则如下:大于dictEntry的、最小的2^n;例如,如果有1000个dictEntry,那么bucket大小为1024;如果有1500个dictEntry,则bucket大小为2048。
dictht
dictht结构如下:
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictht;其中,各个属性的功能说明如下:
- table属性是一个指针,指向bucket;
- size属性记录了哈希表的大小,即bucket的大小;
- used记录了已使用的dictEntry的数量;
- sizemask属性的值总是为size-1,这个属性和哈希值一起决定一个键在table中存储的位置。
dict
一般来说,通过使用dictht和dictEntry结构,便可以实现普通哈希表的功能;但是Redis的实现中,在dictht结构的上层,还有一个dict结构。下面说明dict结构的定义及作用。
dict结构如下:
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
int trehashidx;
} dict;其中,type属性和privdata属性是为了适应不同类型的键值对,用于创建多态字典。
ht属性和trehashidx属性则用于rehash,即当哈希表需要扩展或收缩时使用。ht是一个包含两个项的数组,每项都指向一个dictht结构,这也是Redis的哈希会有1个dict、2个dictht结构的原因。通常情况下,所有的数据都是存在放dict的ht[0]中,ht[1]只在rehash的时候使用。dict进行rehash操作的时候,将ht[0]中的所有数据rehash到ht[1]中。然后将ht[1]赋值给ht[0],并清空ht[1]。
因此,Redis中的哈希之所以在dictht和dictEntry结构之外还有一个dict结构,一方面是为了适应不同类型的键值对,另一方面是为了rehash。
(3)编码转换
如前所述,Redis中内层的哈希既可能使用哈希表,也可能使用压缩列表。
只有同时满足下面两个条件时,才会使用压缩列表:哈希中元素数量小于512个;哈希中所有键值对的键和值字符串长度都小于64字节。如果有一个条件不满足,则使用哈希表;且编码只可能由压缩列表转化为哈希表,反方向则不可能。
下图展示了Redis内层的哈希编码转换的特点:
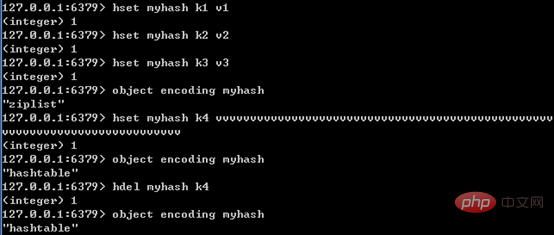
4、集合
(1)概况
集合(set)与列表类似,都是用来保存多个字符串,但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
一个集合中最多可以存储2^32-1个元素;除了支持常规的增删改查,Redis还支持多个集合取交集、并集、差集。
(2)内部编码
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
哈希表前面已经讲过,这里略过不提;需要注意的是,集合在使用哈希表时,值全部被置为null。
整数集合的结构定义如下:
typedef struct intset{
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;其中,encoding代表contents中存储内容的类型,虽然contents(存储集合中的元素)是int8_t类型,但实际上其存储的值是int16_t、int32_t或int64_t,具体的类型便是由encoding决定的;length表示元素个数。
整数集合适用于集合所有元素都是整数且集合元素数量较小的时候,与哈希表相比,整数集合的优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于集合数量较少,因此操作的时间并没有明显劣势。
(3)编码转换
只有同时满足下面两个条件时,集合才会使用整数集合:集合中元素数量小于512个;集合中所有元素都是整数值。如果有一个条件不满足,则使用哈希表;且编码只可能由整数集合转化为哈希表,反方向则不可能。
下图展示了集合编码转换的特点:
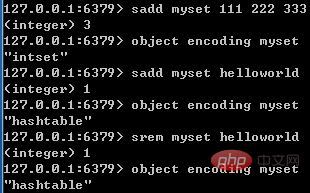
5、有序集合
(1)概况
有序集合与集合一样,元素都不能重复;但与集合不同的是,有序集合中的元素是有顺序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
(2)内部编码
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。ziplist在列表和哈希中都有使用,前面已经讲过,这里略过不提。
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。具体结构相对比较复杂,略。
(3)编码转换
只有同时满足下面两个条件时,才会使用压缩列表:有序集合中元素数量小于128个;有序集合中所有成员长度都不足64字节。如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表,反方向则不可能。
下图展示了有序集合编码转换的特点:
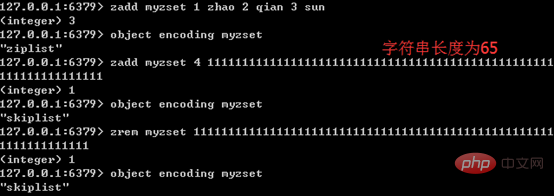
五、应用举例
了解Redis的内存模型之后,下面通过几个例子说明其应用。
1、估算Redis内存使用量
要估算redis中的数据占据的内存大小,需要对redis的内存模型有比较全面的了解,包括前面介绍的hashtable、sds、redisobject、各种对象类型的编码方式等。
下面以最简单的字符串类型来进行说明。
假设有90000个键值对,每个key的长度是7个字节,每个value的长度也是7个字节(且key和value都不是整数);下面来估算这90000个键值对所占用的空间。在估算占据空间之前,首先可以判定字符串类型使用的编码方式:embstr。
90000个键值对占据的内存空间主要可以分为两部分:一部分是90000个dictEntry占据的空间;一部分是键值对所需要的bucket空间。
每个dictEntry占据的空间包括:
1)一个dictEntry,24字节,jemalloc会分配32字节的内存块
2)一个key,7字节,所以SDS(key)需要7+9=16个字节,jemalloc会分配16字节的内存块
3)一个redisObject,16字节,jemalloc会分配16字节的内存块
4)一个value,7字节,所以SDS(value)需要7+9=16个字节,jemalloc会分配16字节的内存块
5)综上,一个dictEntry需要32+16+16+16=80个字节。
bucket空间:bucket数组的大小为大于90000的最小的2^n,是131072;每个bucket元素为8字节(因为64位系统中指针大小为8字节)。
因此,可以估算出这90000个键值对占据的内存大小为:90000*80 + 131072*8 = 8248576。
下面写个程序在redis中验证一下:
public class RedisTest {
public static Jedis jedis = new Jedis("localhost", 6379);
public static void main(String[] args) throws Exception{
Long m1 = Long.valueOf(getMemory());
insertData();
Long m2 = Long.valueOf(getMemory());
System.out.println(m2 - m1);
}
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set("aa" + i, "aa" + i); //key和value长度都是7字节,且不是整数
}
}
public static String getMemory(){
String memoryAllLine = jedis.info("memory");
String usedMemoryLine = memoryAllLine.split("\r\n")[1];
String memory = usedMemoryLine.substring(usedMemoryLine.indexOf(':') + 1);
return memory;
}
}运行结果:8247552
理论值与结果值误差在万分之1.2,对于计算需要多少内存来说,这个精度已经足够了。之所以会存在误差,是因为在我们插入90000条数据之前redis已分配了一定的bucket空间,而这些bucket空间尚未使用。
作为对比将key和value的长度由7字节增加到8字节,则对应的SDS变为17个字节,jemalloc会分配32个字节,因此每个dictEntry占用的字节数也由80字节变为112字节。此时估算这90000个键值对占据内存大小为:90000*112 + 131072*8 = 11128576。
在redis中验证代码如下(只修改插入数据的代码):
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set("aaa" + i, "aaa" + i); //key和value长度都是8字节,且不是整数
}
}运行结果:11128576;估算准确。
对于字符串类型之外的其他类型,对内存占用的估算方法是类似的,需要结合具体类型的编码方式来确定。
2、优化内存占用
了解redis的内存模型,对优化redis内存占用有很大帮助。下面介绍几种优化场景。
(1)利用jemalloc特性进行优化
上一小节所讲述的90000个键值便是一个例子。由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。
(2)使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
(3)共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
(4)避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
3、关注内存碎片率
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。
Das obige ist der detaillierte Inhalt vonRedis-Speichermodell (ausführliche Erklärung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
