


Hier finden Sie ein etwas tiefergehendes Verständnis des String-Objekts in Java.
Entwicklung der Java-Objektimplementierung
String-Objekte sind eines der am häufigsten verwendeten Objekte in Java, daher implementieren Java-Entwickler ständig String-Objekte, um die Leistung zu verbessern von String-Objekten.
(Empfohlenes Lernen: Java-Video-Tutorial)
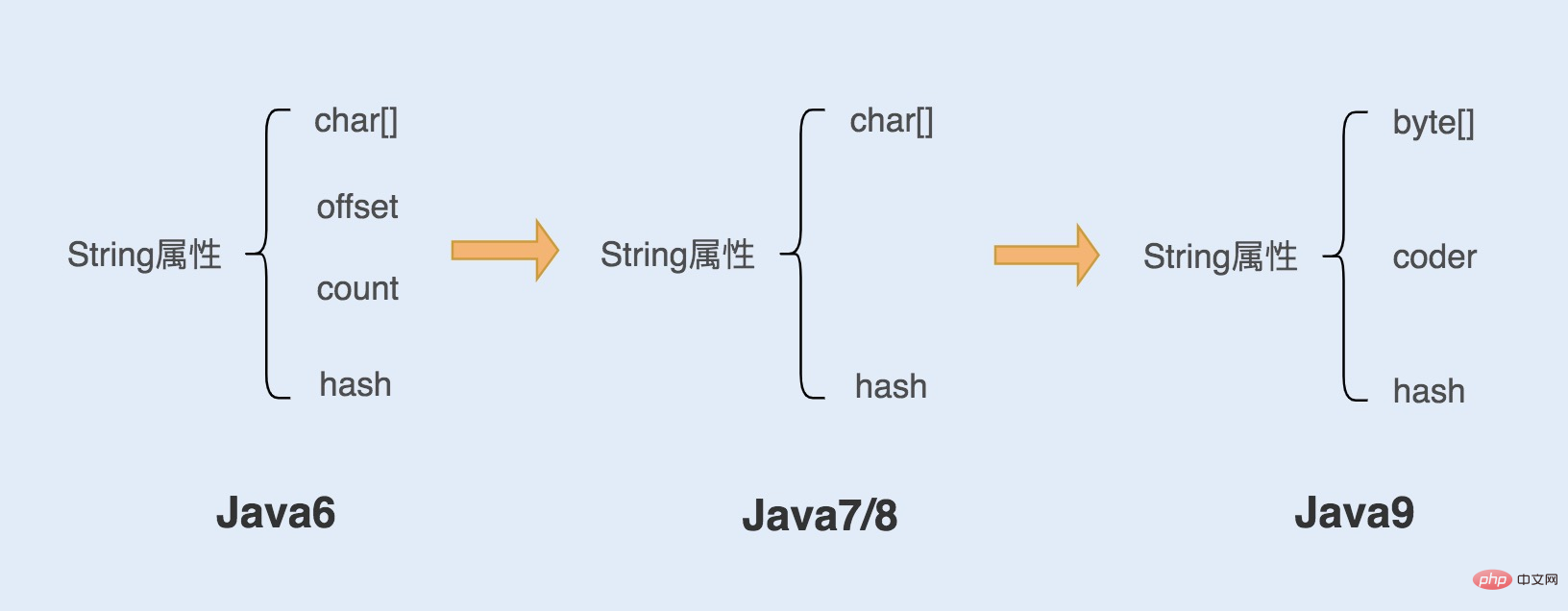
Attribute von String-Objekten in Java6 und früheren Versionen
In Java6 und früheren Versionen ist das String-Objekt ein Objekt, das ein char-Array kapselt. Es verfügt hauptsächlich über vier Mitgliedsvariablen, nämlich char-Array, Offset-Offset, Zeichenanzahl und ha Hope-Wert-Hash. Das String-Objekt sucht das Array char[] und erhält die Zeichenfolge über die beiden Attribute offset und count. Dadurch können Array-Objekte effizient und schnell gemeinsam genutzt und gleichzeitig Speicherplatz gespart werden. Diese Methode kann jedoch zu Speicherverlusten führen.
Attribute von String-Objekten in Java7- und 8-Versionen
Ab der Java7-Version hat Java einige Änderungen an der String-Klasse vorgenommen, insbesondere nicht mehr an der String-Klasse Offset und Zählung zweier Variablen. Dies hat den Vorteil, dass das String-Objekt etwas weniger Speicher beansprucht und die String.substring()-Methode char[] nicht mehr gemeinsam nutzt, wodurch das Speicherverlustproblem gelöst wird, das durch die Verwendung dieser Methode verursacht werden kann.
Attribute von String-Objekten in Java9 und späteren Versionen
Ab der Java9-Version hat Java das Array char[] in ein Array byte[] geändert. Wir alle wissen, dass char aus zwei Bytes besteht, wenn es zum Speichern eines Bytes verwendet wird, was zu einer Verschwendung von Speicherplatz führt. Um dieses eine Byte Platz zu sparen, sind Java-Entwickler dazu übergegangen, ein Byte zum Speichern von Zeichenfolgen zu verwenden.
Darüber hinaus verwaltet das String-Objekt einen neuen Attributcoder. Dieses Attribut ist die Kennung des Codierungsformats. Wenn Sie die Stringlänge berechnen oder die Methode indexOf() aufrufen Feld zum Bestimmen, wie die Zeichenfolgenlänge berechnet werden soll. Das Coder-Attribut hat standardmäßig zwei Werte: 0 und 1, wobei 0 für Latin-1 (Einzelbyte-Kodierung) und 1 für UTF-16-Kodierung steht.
Wie String-Objekte erstellt und im Speicher gespeichert werden
In Java werden Variablen grundlegender Datentypen und Verweise auf Objekte im Stapelspeicher in der lokalen Variablentabelle gespeichert; Objekte, die mit dem neuen Schlüsselwort und dem Konstruktor erstellt wurden, werden im Heap-Speicher gespeichert. Es gibt im Allgemeinen zwei Möglichkeiten, ein String-Objekt zu erstellen: eine ist ein Literal (String-Konstante) und die andere ist ein Konstruktor (String()). Die beiden Methoden werden unterschiedlich im Speicher gespeichert.
So erstellen Sie Literale (String-Konstanten)
Beim Erstellen einer Zeichenfolge mithilfe von Literalen prüft die JVM zunächst, ob sie im String-Konstantenpool vorhanden ist. Wenn das Literal vorhanden ist , wird die Referenzadresse des Literals im Speicher zurückgegeben; wenn sie nicht vorhanden ist, wird das Literal im String-Konstantenpool erstellt und die Referenz zurückgegeben. Der Vorteil dieser Erstellungsmethode besteht darin, dass vermieden wird, dass Zeichenfolgen mit demselben Wert wiederholt im Speicher erstellt werden, wodurch Speicherplatz gespart wird. Gleichzeitig ist diese Schreibmethode einfacher und leichter zu lesen.
String str = "i like yanggb.";
String-Konstanten-Pool
Eine besondere Erklärung des Konstanten-Pools sollte hier erfolgen. Der Konstantenpool ist ein spezieller Speicher, der von der JVM verwaltet wird, um die wiederholte Erstellung von String-Objekten zu reduzieren. Dieser Speicher wird als String-Konstantenpool oder String-Literal-Pool bezeichnet. In JDK1.6 und früheren Versionen befindet sich der Laufzeitkonstantenpool im Methodenbereich. In JDK1.7 und späteren Versionen der JVM wurde der Laufzeitkonstantenpool aus dem Methodenbereich verschoben und im Java-Heap (Heap) ein Bereich zum Speichern des Laufzeitkonstantenpools geöffnet. Ab JDK1.8 hat die JVM den Java-Methodenbereich gestrichen und durch den Metaspace (MetaSpace) ersetzt, der sich im direkten Speicher befindet. Die Zusammenfassung ist, dass sich der aktuelle String-Konstantenpool im Heap befindet.
Die Eigenschaften mehrerer String-Objekte, die wir kennen, stammen alle aus dem String-Konstantenpool.
1. Alle String-Objekte werden im Konstantenpool gemeinsam genutzt, sodass das String-Objekt nicht geändert werden kann, da sich alle Variablen, die auf dieses String-Objekt verweisen, entsprechend ändern (Referenzänderungen). Das String-Objekt ist so konzipiert, dass es unveränderlich ist. Wir werden später ein detailliertes Verständnis dieser unveränderlichen Funktion erhalten.
2. Das Sprichwort, dass das String-Objekt eine schlechte Leistung beim Spleißen von Strings hat, kommt daher. Aufgrund der unveränderlichen Natur des String-Objekts wird bei jeder Änderung (hier beim Spleißen) ein neues String-Objekt zurückgegeben Wenn Sie das ursprüngliche String-Objekt verwenden, verbraucht das Erstellen eines neuen String-Objekts mehr Leistung (was zusätzlichen Speicherplatz freigibt).
3.因为常量池中创建的String对象是共享的,因此使用双引号声明的String对象(字面量)会直接存储在常量池中,如果该字面量在之前已存在,则是会直接引用已存在的String对象,这一点在上面已经描述过了,这里再次提及,是为了特别说明这一做法保证了在常量池中的每个String对象都是唯一的,也就达到了节约内存的目的。
构造函数(String())的创建方式
使用构造函数的方式创建字符串时,JVM同样会在字符串常量池中先检查是否存在该字面量,只是检查后的情况会和使用字面量创建的方式有所不同。如果存在,则会在堆中另外创建一个String对象,然后在这个String对象的内部引用该字面量,最后返回该String对象在内存地址中的引用;如果不存在,则会先在字符串常量池中创建该字面量,然后再在堆中创建一个String对象,然后再在这个String对象的内部引用该字面量,最后返回该String对象的引用。
String str = new String("i like yanggb.");这就意味着,只要使用这种方式,构造函数都会另行在堆内存中开辟空间,创建一个新的String对象。具体的理解是,在字符串常量池中不存在对应的字面量的情况下,new String()会创建两个对象,一个放入常量池中(字面量),一个放入堆内存中(字符串对象)。
String对象的比较
比较两个String对象是否相等,通常是有【==】和【equals()】两个方法。
在基本数据类型中,只可以使用【==】,也就是比较他们的值是否相同;而对于对象(包括String)来说,【==】比较的是地址是否相同,【equals()】才是比较他们内容是否相同;而equals()是Object都拥有的一个函数,本身就要求对内部值进行比较。
String str = "i like yanggb.";
String str1 = new String("i like yanggb.");
System.out.println(str == str1); // falseSystem.out.println(str.equals(str1)); // true因为使用字面量方式创建的String对象和使用构造函数方式创建的String对象的内存地址是不同的,但是其中的内容却是相同的,也就导致了上面的结果。
String对象中的intern()方法
我们都知道,String对象中有很多实用的方法。为什么其他的方法都不说,这里要特别说明这个intern()方法呢,因为其中的这个intern()方法最为特殊。它的特殊性在于,这个方法在业务场景中几乎用不上,它的存在就是在为难程序员的,也可以说是为了帮助程序员了解JVM的内存结构而存在的(?我信你个鬼,你个糟老头子坏得很)。
/*** When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
**/public native String intern();上面是源码中的intern()方法的官方注释说明,大概意思就是intern()方法用来返回常量池中的某字符串,如果常量池中已经存在该字符串,则直接返回常量池中该对象的引用。否则,在常量池中加入该对象,然后返回引用。然后我们可以从方法签名上看出intern()方法是一个native方法。
下面通过几个例子来详细了解下intern()方法的用法。
第一个例子
String str1 = new String("1");
System.out.println(str1 == str1.intern()); // falseSystem.out.println(str1 == "1"); // false在上面的例子中,intern()方法返回的是常量池中的引用,而str1保存的是堆中对象的引用,因此两个打印语句的结果都是false。
第二个例子
String str2 = new String("2") + new String("3");
System.out.println(str2 == str2.intern()); // trueSystem.out.println(str2 == "23"); // true在上面的例子中,str2保存的是堆中一个String对象的引用,这和JVM对【+】的优化有关。实际上,在给str2赋值的第一条语句中,创建了3个对象,分别是在字符串常量池中创建的2和3、还有在堆中创建的字符串对象23。因为字符串常量池中不存在字符串对象23,所以这里要特别注意:intern()方法在将堆中存在的字符串对象加入常量池的时候采取了一种截然不同的处理方案——不是在常量池中建立字面量,而是直接将该String对象自身的引用复制到常量池中,即常量池中保存的是堆中已存在的字符串对象的引用。根据前面的说法,这时候调用intern()方法,就会在字符串常量池中复制出一个对堆中已存在的字符串常量的引用,然后返回对字符串常量池中这个对堆中已存在的字符串常量池的引用的引用(就是那么绕,你来咬我呀)。这样,在调用intern()方法结束之后,返回结果的就是对堆中该String对象的引用,这时候使用【==】去比较,返回的结果就是true了。同样的,常量池中的字面量23也不是真正意义的字面量23了,它真正的身份是堆中的那个String对象23。这样的话,使用【==】去比较字面量23和str2,结果也就是true了。
第三个例子
String str4 = "45";
String str3 = new String("4") + new String("5");
System.out.println(str3 == str3.intern()); // falseSystem.out.println(str3 == "45"); // false这个例子乍然看起来好像比前面的例子还要复杂,实际上却和上面的第一个例子是一样的,最难理解的反而是第二个例子。
所以这里就不多说了,而至于为什么还要举这个例子,我相信聪明的你一下子就明白了。
String对象的不可变性
先来看String对象的一段源码。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
}从类签名上来看,String类用了final修饰符,这就意味着这个类是不能被继承的,这是决定String对象不可变特性的第一点。从类中的数组char[] value来看,这个类成员变量被private和final修饰符修饰,这就意味着其数值一旦被初始化之后就不能再被更改了,这是决定String对象不可变特性的第二点。
Java开发者为什么要将String对象设置为不可变的,主要可以从以下三个方面去考虑:
1.安全性。假设String对象是可变的,那么String对象将可能被恶意修改。
2.唯一性。这个做法可以保证hash属性值不会频繁变更,也就确保了唯一性,使得类似HashMap的容器才能实现相应的key-value缓存功能。
3.功能性。可以实现字符串常量池(究竟是先有设计,还是先有实现呢)。
String对象的优化
字符串是常用的Java类型之一,所以对字符串的操作是避免不了的。而在对字符串的操作过程中,如果使用不当的话,性能可能会有天差地别,所以有一些地方是要注意一下的。
拼接字符串的性能优化
字符串的拼接是对字符串的操作中最频繁的一个使用。由于我们都知道了String对象的不可变性,所以我们在开发过程中要尽量减少使用【+】进行字符串拼接操作。这是因为使用【+】进行字符串拼接,会在得到最终想要的结果前产生很多无用的对象。
String str = 'i'; str = str + ' '; str = str + 'like'; str = str + ' '; str = str + 'yanggb'; str = str + '.'; System.out.println(str); // i like yanggb.
事实上,如果我们使用的是比较智能的IDE编写代码的话,编译器是会提示将代码优化成使用StringBuilder或者StringBuffer对象来优化字符串的拼接性能的,因为StringBuilder和StringBuffer都是可变对象,也就避免了过程中产生无用的对象了。而这两种替代方案的区别是,在需要线程安全的情况下,选用StringBuffer对象,这个对象是支持线程安全的;而在不需要线程安全的情况下,选用StringBuilder对象,因为StringBuilder对象的性能在这种场景下,要比StringBuffer对象或String对象要好得多。
使用intern()方法优化内存占用
前面吐槽了intern()方法在实际开发中没什么用,这里又来说使用intern()方法来优化内存占用了,这人真的是,嘿嘿,真香。关于方法的使用就不说了,上面有详尽的用法说明,这里来说说具体的应用场景好了。有一位Twitter的工程师在Qcon全球软件开发大会上分享了一个他们对String对象优化的案例,他们利用了这个String.intern()方法将以前需要20G内存存储优化到只需要几百兆内存。具体就是,使用intern()方法将原本需要创建到堆内存中的String对象都放到常量池中,因为常量池的不重复特性(存在则返回引用),也就避免了大量的重复String对象造成的内存浪费问题。
什么,要我给intern()方法道歉?不可能。String.intern()方法虽好,但是也是需要结合场景来使用的,并不能够乱用。因为实际上,常量池的实现是类似于一个HashTable的实现方式,而HashTable存储的数据越大,遍历的时间复杂度就会增加。这就意味着,如果数据过大的话,整个字符串常量池的负担就会大大增加,有可能性能不会得到提升却反而有所下降。
字符串分割的性能优化
字符串的分割是字符串操作的常用操作之一,对于字符串的分割,大部分人使用的都是split()方法,split()方法在大部分场景下接收的参数都是正则表达式,这种分割方式本身没有什么问题,但是由于正则表达式的性能是非常不稳定的,使用不恰当的话可能会引起回溯问题并导致CPU的占用居高不下。在以下两种情况下split()方法不会使用正则表达式:
1.传入的参数长度为1,且不包含“.$|()[{^?*+\”regex元字符的情况下,不会使用正则表达式。
2.传入的参数长度为2,第一个字符是反斜杠,并且第二个字符不是ASCII数字或ASCII字母的情况下,不会使用正则表达式。
所以我们在字符串分割时,应该慎重使用split()方法,而首先考虑使用String.indexOf()方法来进行字符串分割,在String.indexOf()无法满足分割要求的时候再使用Split()方法。而在使用split()方法分割字符串时,需要格外注意回溯问题。
总结
Obwohl Sie String-Objekte für die Entwicklung verwenden können, ohne String-Objekte zu verstehen, kann uns das Verständnis von String-Objekten dabei helfen, besseren Code zu schreiben.
„Ich hoffe nur, dass ich am Ende der Geschichte immer noch ich selbst bin und du immer noch du.“
Empfohlenes Tutorial: Java-Tutorial
Das obige ist der detaillierte Inhalt vonTiefes Verständnis von String-Objekten in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



