

Eine ausführliche Einführung in die zugrunde liegende Datenstruktur von Redis

1. Überblick
Ich glaube, dass alle Schüler, die Redis verwendet haben, sehr gut wissen, dass Redis auf Schlüssel-Wert-Paaren basiert verteiltes Speichersystem, das Memcached ähnelt, aber eine leistungsstarke Schlüsselwertdatenbank ist, die besser als Memcached ist.
wird in „Redis-Design und -Implementierung“ beschrieben:
Jedes Schlüssel-Wert-Paar (Schlüsselwert) in der Redis-Datenbank ist zusammengesetzt von Objekten:
Der Datenbankschlüssel ist immer ein String-Objekt;
Der Datenbankwert kann ein String-Objekt, ein Listenobjekt (Liste) oder einer der fünf Objekttypen sein: Hash , setzen und sortieren Sie festgelegte Objekte.
Warum sagen wir, dass Redis besser ist als Memcached? Weil das Aufkommen von Redis den Schlüsselwertspeicher in Memcached bereichert hat. In einigen Fällen kann es eine sehr gute ergänzende Rolle zur relationalen Datenbank spielen Alle Typen dieser Daten unterstützen Push/Pop-, Add/Remove-, Schnitt-, Vereinigungs-, Differenz- und umfangreichere Operationen, und diese Operationen sind alle atomar.
Was wir heute besprechen, ist nicht der Datentyp der Werte in Redis, sondern ihre spezifische Implementierung – der zugrunde liegende Datentyp.
Die zugrunde liegende Datenstruktur von Redis hat die folgenden Datentypen:
1. Einfache dynamische Zeichenfolge
3
4. Sprungtabelle
5. Komprimierte Liste
2. Einfache dynamische Zeichenfolge (einfache dynamische Zeichenfolge) SDS
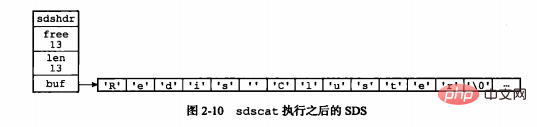
2.1 ÜbersichtRedis ist eine Open-Source-Schlüsselwertdatenbank, die in ANSI C-Sprache geschrieben ist. Subjektiv denken wir vielleicht, dass Redis die Zeichenfolge ist C verwendet die traditionelle String-Darstellung in der C-Sprache, aber Redis verwendet nicht direkt die traditionelle String-Darstellung der C-Sprache, sondern erstellt einen eigenen sogenannten einfachen dynamischen String (SDS). und verwenden Sie SDS als Standard-String-Darstellung von Redis:redis>SET msg "hello world" OK
2.2 Definition von SDS
Die Struktur der in Redis definierten dynamischen Zeichenfolge:/*
* 保存字符串对象的结构
*/
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};1 Variable, die zum Aufzeichnen der Länge des in buf verwendeten Speicherplatzes verwendet wird (hier wird darauf hingewiesen, dass die Länge von Redis 5 beträgt)
2. freie Variable, die zum Aufzeichnen des freien Speicherplatzes in buf (space) verwendet wird Wird zum ersten Mal zugewiesen, ist im Allgemeinen kein freier Speicherplatz vorhanden. Beim Ändern der Zeichenfolge bleibt Speicherplatz übrig)
3 🎜>2.3 SDS und C Der Unterschied zwischen Strings
Im Gegensatz zu C-Strings verfügt die Datenstruktur von SDS über Variablen, die speziell zum Speichern der Länge des Strings verwendet werden. Wir können die Länge des Strings direkt ermitteln, indem wir den Wert des len-Attributs abrufen.
2.3.2 Pufferüberlauf verhindern
C-String zeichnet die Länge des Strings nicht auf. Zusätzlich zur hohen Komplexität der Erfassung kann dies auch der Fall sein kann leicht zu einer Flächenüberschreitung führen.
Angenommen, das Programm hat zwei Zeichenfolgen s1 und s2, die im Speicher nebeneinander liegen. s1 speichert die Zeichenfolge „redis“ und s2 speichert die Zeichenfolge „MongoDb“:
Wenn wir nun den Inhalt von s1 in den Redis-Cluster ändern, aber vergessen, erneut genügend Speicherplatz für s1 zuzuweisen, treten folgende Probleme auf:
Wir können sehen, dass der ursprüngliche Inhalt in s2 durch den Inhalt von S1 belegt wurde und s2 jetzt ein Cluster anstelle von „Mongodb“ ist.Redis 中SDS 的空间分配策略完全杜绝了发生缓冲区溢出的可能性:
当我们需要对一个SDS 进行修改的时候,redis 会在执行拼接操作之前,预先检查给定SDS 空间是否足够,如果不够,会先拓展SDS 的空间,然后再执行拼接操作
2.3.3 减少修改字符串时带来的内存重分配次数
C语言字符串在进行字符串的扩充和收缩的时候,都会面临着内存空间的重新分配问题。
1. 字符串拼接会产生字符串的内存空间的扩充,在拼接的过程中,原来的字符串的大小很可能小于拼接后的字符串的大小,那么这样的话,就会导致一旦忘记申请分配空间,就会导致内存的溢出。
2. 字符串在进行收缩的时候,内存空间会相应的收缩,而如果在进行字符串的切割的时候,没有对内存的空间进行一个重新分配,那么这部分多出来的空间就成为了内存泄露。
举个例子:我们需要对下面的SDS进行拓展,则需要进行空间的拓展,这时候redis 会将SDS的长度修改为13字节,并且将未使用空间同样修改为1字节

因为在上一次修改字符串的时候已经拓展了空间,再次进行修改字符串的时候会发现空间足够使用,因此无须进行空间拓展

通过这种预分配策略,SDS将连续增长N次字符串所需的内存重分配次数从必定N次降低为最多N次
2.3.4 惰性空间释放
我们在观察SDS 的结构的时候可以看到里面的free 属性,是用于记录空余空间的。我们除了在拓展字符串的时候会使用到free 来进行记录空余空间以外,在对字符串进行收缩的时候,我们也可以使用free 属性来进行记录剩余空间,这样做的好处就是避免下次对字符串进行再次修改的时候,需要对字符串的空间进行拓展。
然而,我们并不是说不能释放SDS 中空余的空间,SDS 提供了相应的API,让我们可以在有需要的时候,自行释放SDS 的空余空间。
通过惰性空间释放,SDS 避免了缩短字符串时所需的内存重分配操作,并未将来可能有的增长操作提供了优化
2.3.5 二进制安全
C 字符串中的字符必须符合某种编码,并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串结尾,这些限制使得C字符串只能保存文本数据,而不能保存想图片,音频,视频,压缩文件这样的二进制数据。
但是在Redis中,不是靠空字符来判断字符串的结束的,而是通过len这个属性。那么,即便是中间出现了空字符对于SDS来说,读取该字符仍然是可以的。
例如:
2.3.6 兼容部分C字符串函数
虽然SDS 的API 都是二进制安全的,但他们一样遵循C字符串以空字符串结尾的惯例。
2.3.7 总结
3、链表
3.1 概述
链表提供了高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度。
链表在Redis 中的应用非常广泛,比如列表键的底层实现之一就是链表。当一个列表键包含了数量较多的元素,又或者列表中包含的元素都是比较长的字符串时,Redis 就会使用链表作为列表键的底层实现。
3.2 链表的数据结构
每个链表节点使用一个 listNode结构表示(adlist.h/listNode):
typedef struct listNode{
struct listNode *prev;
struct listNode * next;
void * value;
}多个链表节点组成的双端链表:

我们可以通过直接操作list 来操作链表会更加方便:
typedef struct list{
//表头节点
listNode * head;
//表尾节点
listNode * tail;
//链表长度
unsigned long len;
//节点值复制函数
void *(*dup) (void *ptr);
//节点值释放函数
void (*free) (void *ptr);
//节点值对比函数
int (*match)(void *ptr, void *key);
}list 组成的结构图:
3.3 链表的特性
双端:链表节点带有prev 和next 指针,获取某个节点的前置节点和后置节点的时间复杂度都是O(N)
无环:表头节点的 prev 指针和表尾节点的next 都指向NULL,对立案表的访问时以NULL为截止
表头和表尾:因为链表带有head指针和tail 指针,程序获取链表头结点和尾节点的时间复杂度为O(1)
长度计数器:链表中存有记录链表长度的属性 len
多态:链表节点使用 void* 指针来保存节点值,并且可以通过list 结构的dup 、 free、 match三个属性为节点值设置类型特定函数。
4、字典
4.1 概述
字典,又称为符号表(symbol table)、关联数组(associative array)或映射(map),是一种用于保存键值对的抽象数据结构。
在字典中,一个键(key)可以和一个值(value)进行关联,字典中的每个键都是独一无二的。在C语言中,并没有这种数据结构,但是Redis 中构建了自己的字典实现。
举个简单的例子:
redis > SET msg "hello world" OK
创建这样的键值对(“msg”,“hello world”)在数据库中就是以字典的形式存储
4.2 字典的定义
4.2.1 哈希表
Redis 字典所使用的哈希表由 dict.h/dictht 结构定义:
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}一个空的字典的结构图如下:
我们可以看到,在结构中存有指向dictEntry 数组的指针,而我们用来存储数据的空间既是dictEntry
4.2.2 哈希表节点( dictEntry )
dictEntry 结构定义:
typeof struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}
struct dictEntry *next;
}在数据结构中,我们清楚key 是唯一的,但是我们存入里面的key 并不是直接的字符串,而是一个hash 值,通过hash 算法,将字符串转换成对应的hash 值,然后在dictEntry 中找到对应的位置。
这时候我们会发现一个问题,如果出现hash 值相同的情况怎么办?Redis 采用了链地址法:
当k1 和k0 的hash 值相同时,将k1中的next 指向k0 想成一个链表。
4.2.3 字典
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privedata;
// 哈希表
dictht ht[2];
// rehash 索引
in trehashidx;
}type 属性 和privdata 属性是针对不同类型的键值对,为创建多态字典而设置的。
ht 属性是一个包含两个项(两个哈希表)的数组
普通状态下的字典:
4.3 解决哈希冲突
在上述分析哈希节点的时候我们有讲到:在插入一条新的数据时,会进行哈希值的计算,如果出现了hash值相同的情况,Redis 中采用了连地址法(separate chaining)来解决键冲突。
每个哈希表节点都有一个next 指针,多个哈希表节点可以使用next 构成一个单向链表,被分配到同一个索引上的多个节点可以使用这个单向链表连接起来解决hash值冲突的问题。
举个例子:
现在哈希表中有以下的数据:k0 和k1
我们现在要插入k2,通过hash 算法计算到k2 的hash 值为2,即我们需要将k2 插入到dictEntry[2]中:

在插入后我们可以看到,dictEntry指向了k2,k2的next 指向了k1,从而完成了一次插入操作(这里选择表头插入是因为哈希表节点中没有记录链表尾节点位置)
4.4 Rehash
随着对哈希表的不断操作,哈希表保存的键值对会逐渐的发生改变,为了让哈希表的负载因子维持在一个合理的范围之内,我们需要对哈希表的大小进行相应的扩展或者压缩,这时候,我们可以通过 rehash(重新散列)操作来完成。
4.4.1 目前的哈希表状态:
我们可以看到,哈希表中的每个节点都已经使用到了,这时候我们需要对哈希表进行拓展。
4.4.2 为哈希表分配空间
哈希表空间分配规则:
如果执行的是拓展操作,那么ht[1] 的大小为第一个大于等于ht[0] 的2的n次幂
如果执行的是收缩操作,那么ht[1] 的大小为第一个大于等于ht[0] 的2的n次幂
因此这里我们为ht[1] 分配 空间为8,
4.4.3 数据转移
Übertragen Sie die Daten in ht[0] nach ht[1]. Während des Übertragungsvorgangs muss der Hashwert der Daten im Hash-Tabellenknoten neu berechnet werden
Das Ergebnis nach der Datenübertragung:
4.4.4 Lassen Sie ht[0] los
Lassen Sie ht[0] los und setzen Sie dann ht[1] auf ht[0]. Zum Schluss zuweisen eine leere Hash-Tabelle zu ht[1]:
4.4.5 Progressiver Rehash
Wie wir oben erwähnt haben, können Sie vor der Erweiterung oder Komprimierung direkt Bereiten Sie alle Schlüssel-Wert-Paare in ht[1] erneut auf, da die Datenmenge relativ gering ist. Im eigentlichen Entwicklungsprozess wird dieser Rehash-Vorgang nicht einmalig und zentral durchgeführt, sondern mehrfach und schrittweise.
Detaillierte Schritte der progressiven Wiederaufbereitung:
1. Ordnen Sie Platz für ht[1] zu und lassen Sie das Wörterbuch zwei Hash-Tabellen ht[0] und ht[1] gleichzeitig enthalten
2. Pflegen Sie eine Indexzählervariable rehasidx zu welchem Zeitpunkt und setzen Sie ihren Wert auf 0, um anzuzeigen, dass die Wiederaufbereitung beginnt.
3 Während der Wiederaufbereitung wird zusätzlich eine CRUD-Operation am Wörterbuch ausgeführt Um die angegebenen Vorgänge auszuführen, wird das Programm auch die Daten in ht[0] in der Tabelle ht[1] erneut aufbereiten und rehashidx um eins erhöhen
4. Wenn alle Daten in ht[0] übertragen werden. Wann Wenn Sie ht[1] erreichen, setzen Sie rehasidx auf -1, was das Ende des Rehash anzeigt.
Der Vorteil der Verwendung von progressivem Rehash besteht darin, dass es einen Divide-and-Conquer-Ansatz anwendet und den riesigen Rechenaufwand vermeidet, der durch die Zentralisierung verursacht wird aufwärmen.
Das obige ist der detaillierte Inhalt vonEine ausführliche Einführung in die zugrunde liegende Datenstruktur von Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
