

Detaillierte Erläuterung der RDB-Persistenz in Redis

Im Vergleich zu anderen Caching-Produkten wie Memcache hat Redis den offensichtlichen Vorteil, dass Redis nicht nur einfache Daten vom Typ Schlüsselwert unterstützt, sondern auch Listen-, Set- und Zset-Speicher bereitstellt von Datenstrukturen wie Hash. Wir haben zwei Artikel damit verbracht, diese umfangreichen Datentypen im Detail vorzustellen. Als Nächstes stellen wir einen weiteren großen Vorteil von Redis vor – die Persistenz. (Empfehlung: Redis-Video-Tutorial)
Da Redis eine In-Memory-Datenbank ist, dient die sogenannte In-Memory-Datenbank dazu, den Inhalt der Datenbank im Speicher zu speichern, was damit zusammenhängt zu herkömmlichem MySQL, Oracle usw. Im Vergleich zu herkömmlichen Datenbanken, die Inhalte direkt auf der Festplatte speichern, ist die Lese- und Schreibeffizienz einer In-Memory-Datenbank viel schneller als die einer herkömmlichen Datenbank (die Lese- und Schreibeffizienz des Speichers). ist viel größer als die Lese- und Schreibeffizienz der Festplatte). Das Speichern im Speicher bringt jedoch auch einen Nachteil mit sich. Sobald der Strom abgeschaltet wird oder der Computer ausfällt, gehen alle Daten in der Speicherdatenbank verloren.
Um dieses Manko zu beheben, bietet Redis die Funktion, Speicherdaten auf der Festplatte zu speichern und persistente Dateien zum Wiederherstellen von Datenbankdaten zu verwenden. Redis unterstützt zwei Formen der Persistenz: eine ist RDB-Snapshotting (Snapshotting) und die andere ist AOF (Append-Only-File). In diesem Blog werden zunächst RDB-Snapshots vorgestellt.
1. Einführung in RDB
RDB ist eine von Redis verwendete Methode zur Persistenz. Es handelt sich um eine Momentaufnahme des aktuell im Speicher befindlichen Datensatzes . Auf die Festplatte schreiben, also Snapshot-Snapshot (alle Schlüssel-Wert-Paardaten in der Datenbank). Bei der Wiederherstellung wird die Snapshot-Datei direkt in den Speicher eingelesen.
Zurück nach oben
2. Auslösemethode
RDB verfügt über zwei Auslösemethoden, nämlich automatische Auslösung und manuelle Auslösung.
①, Automatisch auslösen
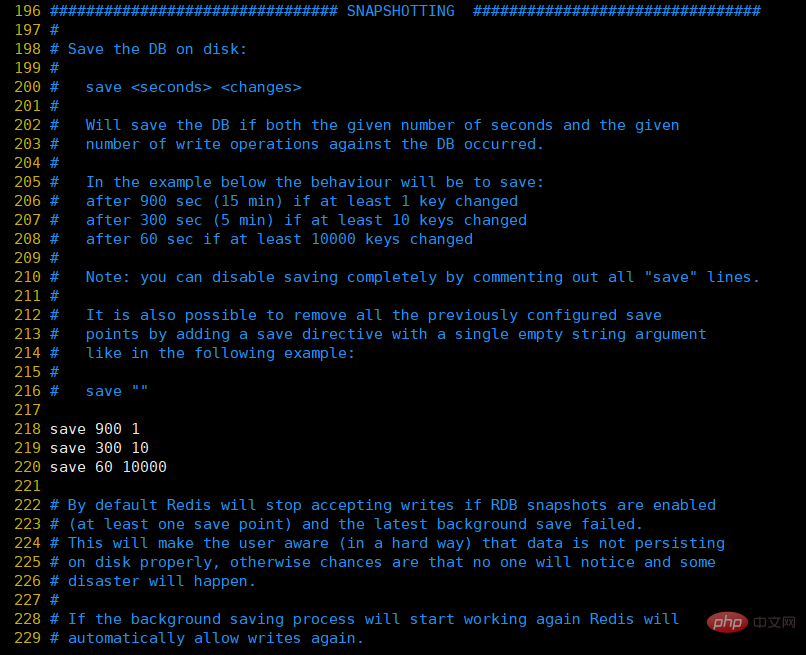
Unter SNAPSHOTTING in der redis.conf-Konfigurationsdatei
① speichern: Dies wird zum Konfigurieren des Triggers verwendet die RDB-Persistenzbedingung von Redis, d. h. wann die Daten im Speicher auf der Festplatte gespeichert werden sollen. Zum Beispiel „save m n“. Gibt an, dass bgsave automatisch ausgelöst wird, wenn der Datensatz innerhalb von m Sekunden n-mal geändert wurde (dieser Befehl wird unten vorgestellt und der Befehl zum manuellen Auslösen der RDB-Persistenz).
Die Standardkonfiguration lautet wie folgt:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
Wenn Sie nur die Caching-Funktion von Redis verwenden und keine Persistenz benötigen, können Sie natürlich alle Speicherzeilen auskommentieren, um die Speicherfunktion zu deaktivieren. Sie können eine leere Zeichenfolge direkt verwenden, um eine Deaktivierung zu erreichen: save „“
②, stop-writes-on-bgsave-error: Der Standardwert ist „yes“. Wenn RDB aktiviert ist und die letzte Datenspeicherung im Hintergrund fehlschlägt, wird angezeigt, ob Redis keine Daten mehr empfängt. Dadurch würde der Benutzer darauf aufmerksam gemacht, dass die Daten nicht korrekt auf der Festplatte gespeichert wurden, andernfalls würde niemand bemerken, dass eine Katastrophe aufgetreten ist. Wenn Redis neu startet, kann es erneut Daten empfangen
③, rdbcompression ist der Standardwert „yes“. Für auf der Festplatte gespeicherte Snapshots können Sie festlegen, ob diese zur Speicherung komprimiert werden sollen. Wenn ja, verwendet Redis den LZF-Algorithmus zur Komprimierung. Wenn Sie keine CPU für die Komprimierung beanspruchen möchten, können Sie diese Funktion deaktivieren. Die auf der Festplatte gespeicherten Snapshots sind dann jedoch größer.
④, rdbchecksum: Der Standardwert ist ja. Nach dem Speichern des Snapshots können wir Redis auch den CRC64-Algorithmus zur Datenüberprüfung verwenden lassen, dies erhöht jedoch den Leistungsverbrauch um etwa 10 %. Wenn Sie die maximale Leistungsverbesserung erzielen möchten, können Sie diese Funktion deaktivieren.
⑤, dbfilename: Legen Sie den Dateinamen des Snapshots fest. Der Standardwert ist dump.rdb
⑥, dir: Legen Sie den Speicherpfad der Snapshot-Datei fest. Dieses Konfigurationselement muss ein Verzeichnis sein , kein Dateiname. Standardmäßig wird es im selben Verzeichnis wie die aktuelle Konfigurationsdatei gespeichert.
Das heißt, wenn der tatsächliche Vorgang über die in der Konfigurationsdatei konfigurierte Speichermethode dem Konfigurationsformular entspricht, wird die RDB-Persistenz ausgeführt und der aktuelle Speicher-Snapshot im durch dir konfigurierten Verzeichnis gespeichert . Der Dateiname wird durch den konfigurierten Datenbankdateinamen bestimmt.
②. Manueller Auslöser
Es gibt zwei Befehle zum manuellen Auslösen von Redis für die RDB-Persistenz:
1. Speichern
Dieser Befehl blockiert das aktuelle Redis Server: Während der Ausführung des Speicherbefehls kann Redis keine anderen Befehle verarbeiten, bis der RDB-Prozess abgeschlossen ist.
Offensichtlich führt dieser Befehl zu einer langfristigen Blockierung von Instanzen mit relativ großem Speicher. Dies ist ein schwerwiegender Fehler. Um dieses Problem zu lösen, bietet Redis eine zweite Möglichkeit.
2. bgsave
Beim Ausführen dieses Befehls führt Redis Snapshot-Vorgänge asynchron im Hintergrund aus und der Snapshot kann auch auf Client-Anfragen reagieren. Der spezifische Vorgang besteht darin, dass der Redis-Prozess einen Fork-Vorgang ausführt, um einen untergeordneten Prozess zu erstellen. Der RDB-Persistenzprozess ist für den untergeordneten Prozess verantwortlich und endet automatisch nach Abschluss. Die Blockierung erfolgt nur während der Fork-Phase und ist im Allgemeinen nur von kurzer Dauer.
Grundsätzlich verwenden alle RDB-Vorgänge in Redis den Befehl bgsave.
ps: Durch Ausführen des Befehls „flushall“ wird auch die Datei dump.rdb generiert, diese ist jedoch leer und bedeutungslos
3. Daten wiederherstellen
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
获取 redis 的安装目录可以使用 config get dir 命令

4、停止 RDB 持久化
有些情况下,我们只想利用Redis的缓存功能,并不像使用 Redis 的持久化功能,那么这时候我们最好停掉 RDB 持久化。可以通过上面讲的在配置文件 redis.conf 中,可以注释掉所有的 save 行来停用保存功能或者直接一个空字符串来实现停用:save ""
也可以通过命令:
redis-cli config set save " "
回到顶部
5、RDB 的优势和劣势
①、优势
1.RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
3.RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
1、RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
2、RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题(版本不兼容)
3、在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
回到顶部
6、RDB 自动保存的原理
Redis有个服务器状态结构:
struct redisService{
//1、记录保存save条件的数组
struct saveparam *saveparams;
//2、修改计数器
long long dirty;
//3、上一次执行保存的时间
time_t lastsave;
}①、首先看记录保存save条件的数组 saveparam,里面每个元素都是一个 saveparams 结构:
struct saveparam{
//秒数
time_t seconds;
//修改数
int changes;
};前面我们在 redis.conf 配置文件中进行了关于save 的配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
那么服务器状态中的saveparam 数组将会是如下的样子:
②、dirty 计数器和lastsave 属性
dirty 计数器记录距离上一次成功执行 save 命令或者 bgsave 命令之后,Redis服务器进行了多少次修改(包括写入、删除、更新等操作)。
lastsave 属性是一个时间戳,记录上一次成功执行 save 命令或者 bgsave 命令的时间。
通过这两个命令,当服务器成功执行一次修改操作,那么dirty 计数器就会加 1,而lastsave 属性记录上一次执行save或bgsave的时间,Redis 服务器还有一个周期性操作函数 severCron ,默认每隔 100 毫秒就会执行一次,该函数会遍历并检查 saveparams 数组中的所有保存条件,只要有一个条件被满足,那么就会执行 bgsave 命令。
执行完成之后,dirty 计数器更新为 0 ,lastsave 也更新为执行命令的完成时间。
更多redis知识请关注redis数据库教程栏目。
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der RDB-Persistenz in Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Lösung für den Fehler 0x80242008 bei der Installation von Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
Lösung für den Fehler 0x80242008 bei der Installation von Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
1. Starten Sie das Menü [Start], geben Sie [cmd] ein, klicken Sie mit der rechten Maustaste auf [Eingabeaufforderung] und wählen Sie Als [Administrator] ausführen. 2. Geben Sie nacheinander die folgenden Befehle ein (kopieren und fügen Sie sie sorgfältig ein): SCconfigwuauservstart=auto, drücken Sie die Eingabetaste. SCconfigbitsstart=auto, drücken Sie die Eingabetaste. SCconfigcryptsvcstart=auto, drücken Sie die Eingabetaste. SCconfigtrustedinstallerstart=auto, drücken Sie die Eingabetaste. SCconfigwuauservtype=share, drücken Sie die Eingabetaste. netstopwuauserv, drücken Sie die Eingabetaste für netstopcryptS
 Golang API-Caching-Strategie und -Optimierung
May 07, 2024 pm 02:12 PM
Golang API-Caching-Strategie und -Optimierung
May 07, 2024 pm 02:12 PM
Die Caching-Strategie in GolangAPI kann die Leistung verbessern und die Serverlast reduzieren. Häufig verwendete Strategien sind: LRU, LFU, FIFO und TTL. Zu den Optimierungstechniken gehören die Auswahl geeigneter Cache-Speicher, hierarchisches Caching, Invalidierungsmanagement sowie Überwachung und Optimierung. Im praktischen Fall wird der LRU-Cache verwendet, um die API zum Abrufen von Benutzerinformationen aus der Datenbank zu optimieren. Andernfalls kann der Cache nach dem Abrufen aus der Datenbank aktualisiert werden.
 Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
In der PHP-Entwicklung verbessert der Caching-Mechanismus die Leistung, indem er häufig aufgerufene Daten vorübergehend im Speicher oder auf der Festplatte speichert und so die Anzahl der Datenbankzugriffe reduziert. Zu den Cache-Typen gehören hauptsächlich Speicher-, Datei- und Datenbank-Cache. In PHP können Sie integrierte Funktionen oder Bibliotheken von Drittanbietern verwenden, um Caching zu implementieren, wie zum Beispiel Cache_get() und Memcache. Zu den gängigen praktischen Anwendungen gehören das Zwischenspeichern von Datenbankabfrageergebnissen zur Optimierung der Abfrageleistung und das Zwischenspeichern von Seitenausgaben zur Beschleunigung des Renderings. Der Caching-Mechanismus verbessert effektiv die Reaktionsgeschwindigkeit der Website, verbessert das Benutzererlebnis und reduziert die Serverlast.
 So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000_So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000
May 08, 2024 pm 05:10 PM
So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000_So aktualisieren Sie Win11 Englisch 21996 auf vereinfachtes Chinesisch 22000
May 08, 2024 pm 05:10 PM
Zuerst müssen Sie die Systemsprache auf die Anzeige in vereinfachtem Chinesisch einstellen und neu starten. Wenn Sie die Anzeigesprache zuvor auf vereinfachtes Chinesisch geändert haben, können Sie diesen Schritt natürlich einfach überspringen. Beginnen Sie als Nächstes mit dem Betrieb der Registrierung regedit.exe, navigieren Sie direkt zu HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage in der linken Navigationsleiste oder der oberen Adressleiste und ändern Sie dann den InstallLanguage-Schlüsselwert und den Standardschlüsselwert auf 0804 (wenn Sie ihn in Englisch ändern möchten). us, Sie müssen zunächst die Anzeigesprache des Systems auf en-us einstellen, das System neu starten und dann alles auf 0409 ändern) Sie müssen das System an dieser Stelle neu starten.
 Wie verwende ich den Redis-Cache bei der PHP-Array-Paginierung?
May 01, 2024 am 10:48 AM
Wie verwende ich den Redis-Cache bei der PHP-Array-Paginierung?
May 01, 2024 am 10:48 AM
Durch die Verwendung des Redis-Cache kann die Leistung des PHP-Array-Pagings erheblich optimiert werden. Dies kann durch die folgenden Schritte erreicht werden: Installieren Sie den Redis-Client. Stellen Sie eine Verbindung zum Redis-Server her. Erstellen Sie Cache-Daten und speichern Sie jede Datenseite in einem Redis-Hash mit dem Schlüssel „page:{page_number}“. Rufen Sie Daten aus dem Cache ab und vermeiden Sie teure Vorgänge auf großen Arrays.
 So finden Sie die von Win11 heruntergeladene Update-Datei. Geben Sie den Speicherort der von Win11 heruntergeladenen Update-Datei an
May 08, 2024 am 10:34 AM
So finden Sie die von Win11 heruntergeladene Update-Datei. Geben Sie den Speicherort der von Win11 heruntergeladenen Update-Datei an
May 08, 2024 am 10:34 AM
1. Doppelklicken Sie zunächst auf dem Desktop auf das Symbol [Dieser PC], um es zu öffnen. 2. Doppelklicken Sie dann mit der linken Maustaste, um [Laufwerk C] einzugeben. Systemdateien werden im Allgemeinen automatisch auf Laufwerk C gespeichert. 3. Suchen Sie dann den Ordner [Windows] auf dem Laufwerk C und doppelklicken Sie, um ihn aufzurufen. 4. Nachdem Sie den Ordner [Windows] aufgerufen haben, suchen Sie den Ordner [SoftwareDistribution]. 5. Suchen Sie nach der Eingabe den Ordner [Download], der alle Win11-Download- und Update-Dateien enthält. 6. Wenn wir diese Dateien löschen möchten, löschen Sie sie einfach direkt in diesem Ordner.
 PHP-Redis-Caching-Anwendungen und Best Practices
May 04, 2024 am 08:33 AM
PHP-Redis-Caching-Anwendungen und Best Practices
May 04, 2024 am 08:33 AM
Redis ist ein leistungsstarker Schlüsselwert-Cache. Die PHPRedis-Erweiterung stellt eine API für die Interaktion mit dem Redis-Server bereit. Führen Sie die folgenden Schritte aus, um eine Verbindung zu Redis herzustellen sowie Daten zu speichern und abzurufen: Verbinden: Verwenden Sie die Redis-Klassen, um eine Verbindung zum Server herzustellen. Speicherung: Verwenden Sie die Set-Methode, um Schlüssel-Wert-Paare festzulegen. Abrufen: Verwenden Sie die get-Methode, um den Wert des Schlüssels abzurufen.
 Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Ursachen und Lösungen für Fehler Bei der Verwendung von PECL zur Installation von Erweiterungen in der Docker -Umgebung, wenn die Docker -Umgebung verwendet wird, begegnen wir häufig auf einige Kopfschmerzen ...
