

Über den Linux-Cache-Speicher (ausführliche Bild- und Texterklärung)
Das Thema der heutigen Erkundung ist Cache. Uns beschäftigen mehrere Fragen. Warum brauchen Sie Cache? Wie kann festgestellt werden, ob Daten im Cache vorhanden sind? Welche Arten von Cache gibt es und was sind die Unterschiede?
Bevor wir darüber nachdenken, was Cache ist, denken wir zunächst über die erste Frage nach: Wie läuft unser Programm? Wir sollten wissen, dass das Programm im RAM läuft, und RAM ist das, was wir oft DDR nennen (wie DDR3, DDR4 usw.). Wir nennen es Hauptspeicher. Wenn wir einen Prozess ausführen müssen, laden wir zuerst das ausführbare Programm vom Flash-Gerät (z. B. eMMC, UFS usw.) in den Hauptspeicher und starten dann die Ausführung. In der CPU gibt es eine Reihe von Allzweckregistern (Registern). Wenn die CPU 1 zu einer Variablen hinzufügen muss (vorausgesetzt, die Adresse ist A), ist dies im Allgemeinen in die folgenden drei Schritte unterteilt:
CPU liest die Daten an Adresse A vom Hauptspeicher zum internen Allzweckregister x0 (eines der Allzweckregister der ARM64-Architektur).
Erhöhen Sie das allgemeine Register x0 um 1.
CPU schreibt den Wert des allgemeinen Registers x0 in den Hauptspeicher.
Wir können diesen Prozess wie folgt ausdrücken:
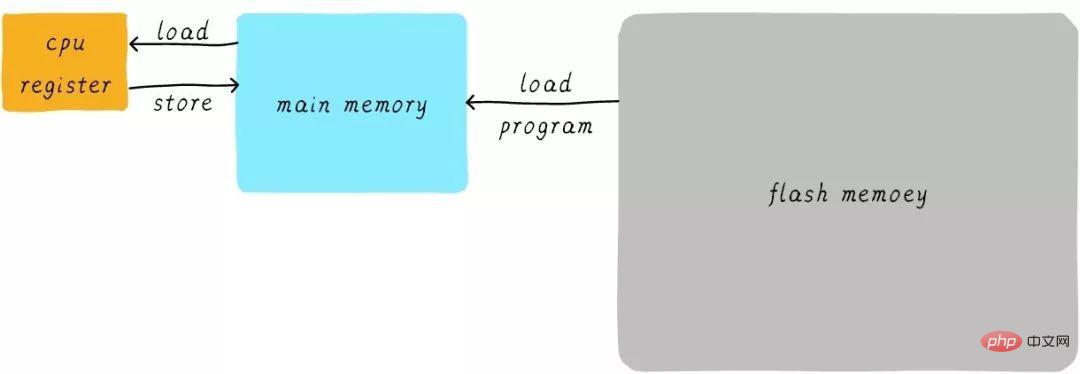
Tatsächlich sind die Geschwindigkeit und das Hauptgedächtnis von Das allgemeine CPU-Register Es gibt einen großen Unterschied zwischen ihnen. Die Geschwindigkeitsbeziehung zwischen den beiden ist ungefähr wie folgt:
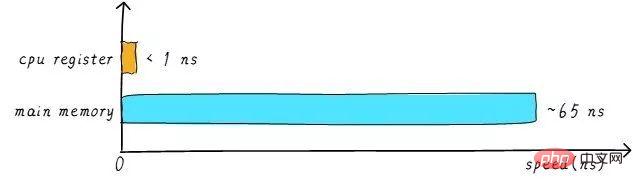
Die Geschwindigkeit des CPU-Registers beträgt im Allgemeinen weniger als 1 ns und die Geschwindigkeit des Hauptspeichers beträgt im Allgemeinen etwa 65 ns. Der Geschwindigkeitsunterschied beträgt fast das Hundertfache. Daher sind von den drei Schritten im obigen Beispiel die Schritte 1 und 3 tatsächlich sehr langsam. Wenn die CPU versucht, Vorgänge aus dem Hauptspeicher zu laden/zu speichern, muss die CPU aufgrund der Geschwindigkeitsbegrenzung des Hauptspeichers diese langen 65 ns warten. Wenn wir die Geschwindigkeit des Hauptspeichers erhöhen können, wird die Leistung des Systems enorm verbessert.
Heutige DDR-Speichergeräte können leicht über mehrere GB verfügen, was eine sehr große Kapazität darstellt. Wenn wir schnellere Materialien verwenden, um einen schnelleren Hauptspeicher herzustellen, haben wir fast die gleiche Kapazität. Seine Kosten werden erheblich steigen. Wir versuchen, die Geschwindigkeit und Kapazität des Hauptspeichers zu erhöhen, gehen aber davon aus, dass die Kosten sehr niedrig sein werden, was etwas peinlich ist. Daher haben wir eine Kompromissmethode gewählt, die darin besteht, ein Speichergerät herzustellen, das extrem schnell ist, aber eine extrem geringe Kapazität hat. Dann werden die Kosten nicht zu hoch sein. Wir nennen dieses Speichergerät Cache-Speicher.
In der Hardware platzieren wir einen Cache zwischen der CPU und dem Hauptspeicher als Cache für Hauptspeicherdaten. Wenn die CPU versucht, Daten aus dem Hauptspeicher zu laden/zu speichern, prüft die CPU zunächst im Cache, ob die Daten an der entsprechenden Adresse im Cache zwischengespeichert sind. Wenn die Daten im Cache zwischengespeichert werden, werden die Daten direkt aus dem Cache abgerufen und an die CPU zurückgegeben. Wenn ein Cache vorhanden ist, sieht der Prozess des obigen Beispiels für die Ausführung des Programms wie folgt aus:
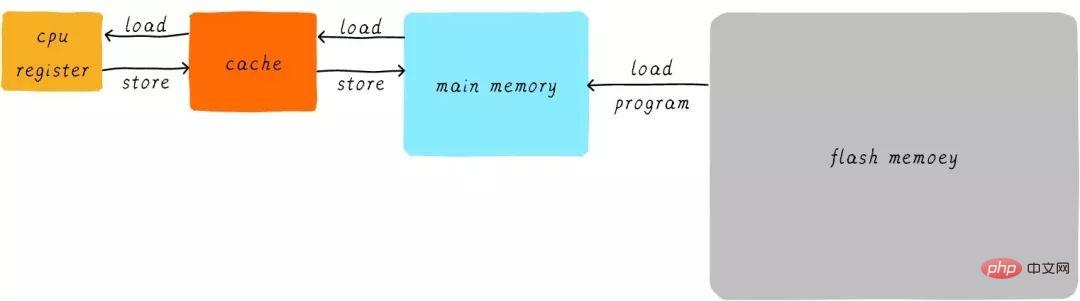
Die direkte Datenübertragungsmethode zwischen der CPU und dem Hauptspeicher ist umgewandelt in eine direkte Datenübertragung zwischen der CPU und dem Hauptspeicher. Direkte Datenübertragung zwischen Caches. Der Cache ist für die Datenübertragung zwischen Hauptspeicher und Hauptspeicher zuständig.
Die Geschwindigkeit des Caches beeinflusst in gewissem Maße auch die Leistung des Systems.
Im Allgemeinen kann die Cache-Geschwindigkeit 1 ns erreichen, was fast mit der CPU-Registergeschwindigkeit vergleichbar ist. Aber befriedigt dies das Leistungsstreben der Menschen? Nicht wirklich. Wenn die gewünschten Daten nicht im Cache zwischengespeichert sind, müssen wir immer noch lange warten, bis die Daten aus dem Hauptspeicher geladen werden. Um die Leistung weiter zu verbessern, wird ein mehrstufiger Cache eingeführt.
Der zuvor erwähnte Cache wird L1-Cache (First-Level-Cache) genannt. Wir verbinden den L2-Cache hinter dem L1-Cache und den L3-Cache zwischen dem L2-Cache und dem Hauptspeicher. Je höher die Stufe, desto langsamer die Geschwindigkeit und desto größer die Kapazität. Aber im Vergleich zum Hauptspeicher ist die Geschwindigkeit immer noch sehr hoch. Die Beziehung zwischen verschiedenen Ebenen der Cache-Geschwindigkeit ist wie folgt:
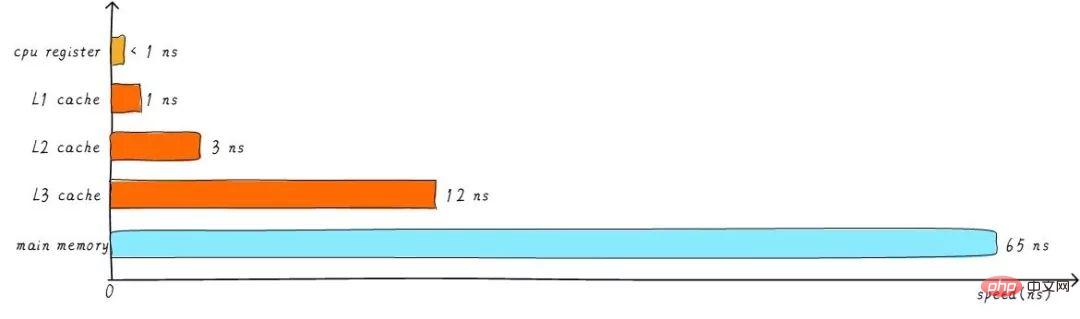
Nach der Pufferung des Level-3-Cache nimmt auch der Geschwindigkeitsunterschied zwischen den einzelnen Cache-Ebenen und dem Hauptspeicher schrittweise ab Schritt. Wie hängt in einem realen System die Hardware zwischen Caches auf allen Ebenen zusammen? Werfen wir einen Blick auf das Hardware-Abstraktionsblockdiagramm zwischen Caches auf allen Ebenen der Cortex-A53-Architektur wie folgt:
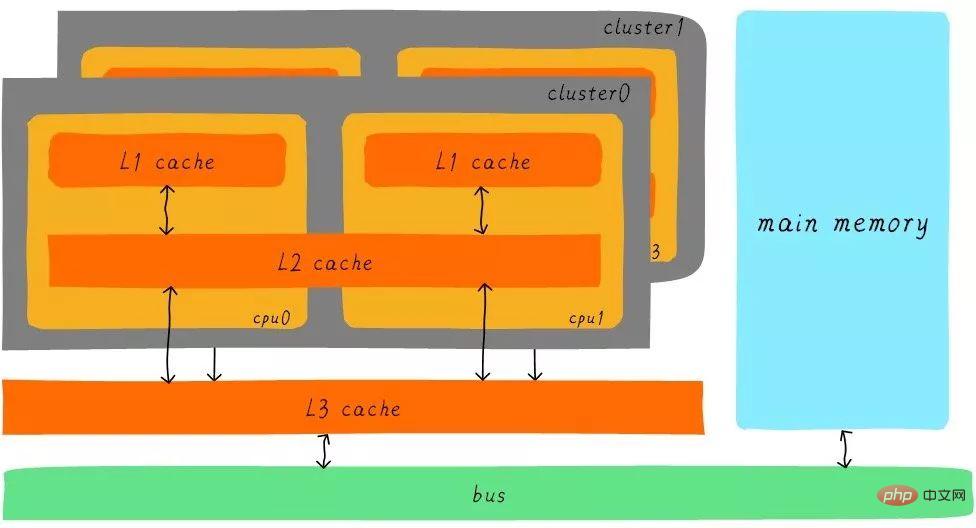
Auf der Cortex-A53-Architektur ist der L1-Cache in einen separaten Befehlscache (ICache) und einen Datencache (DCache) unterteilt. Der L1-Cache ist für die CPU privat und jede CPU verfügt über einen L1-Cache. Alle CPUs in einem Cluster teilen sich einen L2-Cache. Der L2-Cache unterscheidet nicht zwischen Anweisungen und Daten und kann beides zwischenspeichern. Der L3-Cache wird von allen Clustern gemeinsam genutzt. Der L3-Cache ist über einen Bus mit dem Hauptspeicher verbunden.
Führen Sie zunächst zwei Substantivkonzepte ein: Treffer und Fehlschläge. Die Daten, auf die die CPU zugreifen möchte, werden im Cache zwischengespeichert, was als „Hit“ und umgekehrt als „Miss“ bezeichnet wird. Wie arbeiten Multi-Level-Caches zusammen? Wir gehen davon aus, dass das betrachtete System nur über zwei Cache-Ebenen verfügt.
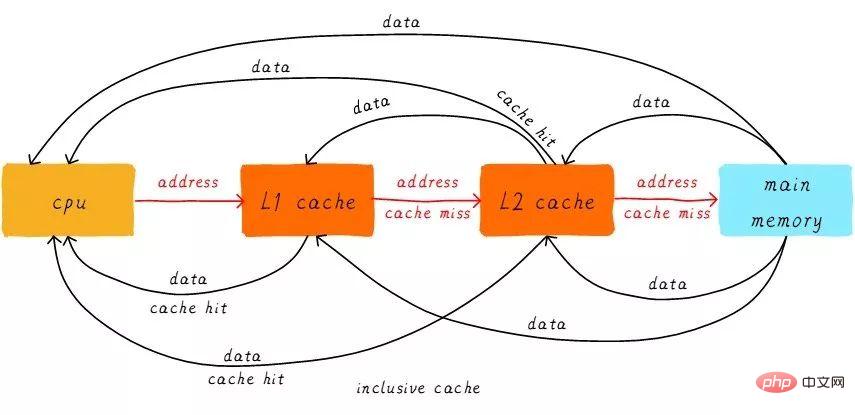
Wenn die CPU versucht, Daten von einer bestimmten Adresse zu laden, prüft sie zunächst, ob ein Treffer aus dem L1-Cache vorliegt. Bei einem Treffer werden die Daten an die Adresse zurückgegeben CPU. Wenn der L1-Cache fehlt, setzen Sie die Suche im L2-Cache fort. Wenn der L2-Cache erreicht wird, werden die Daten an den L1-Cache und die CPU zurückgegeben. Wenn auch der L2-Cache fehlt, müssen wir leider die Daten aus dem Hauptspeicher laden und die Daten an den L2-Cache, L1-Cache und die CPU zurückgeben. Diese mehrstufige Cache-Arbeitsmethode wird als inklusiver Cache bezeichnet.
Daten an einer bestimmten Adresse können in mehrstufigen Caches vorhanden sein. Dem inklusiven Cache entspricht der exklusive Cache, der sicherstellt, dass der Datencache an einer bestimmten Adresse nur auf einer Ebene des mehrstufigen Caches vorhanden ist. Mit anderen Worten: Daten an einer beliebigen Adresse können nicht gleichzeitig im L1- und L2-Cache zwischengespeichert werden.
Wir führen weiterhin einige Cache-bezogene Begriffe ein. Die Größe des Caches wird als Cache-Größe bezeichnet und stellt die Größe der maximalen Daten dar, die der Cache zwischenspeichern kann. Wir teilen den Cache in viele gleiche Blöcke auf, und die Größe jedes Blocks wird als Cache-Zeile bezeichnet, und seine Größe ist die Cache-Zeilengröße.
Zum Beispiel ein Cache mit einer Größe von 64 Bytes. Wenn wir 64 Bytes gleichmäßig in 64 Blöcke aufteilen, beträgt die Cache-Zeile 1 Byte und es gibt insgesamt 64 Cache-Zeilen. Wenn wir die 64 Bytes gleichmäßig in 8 Blöcke aufteilen, beträgt die Cache-Zeile 8 Bytes und es gibt insgesamt 8 Cache-Zeilen. Im aktuellen Hardware-Design beträgt die allgemeine Cache-Zeilengröße 4–128 Byte. Warum gibt es nicht 1 Byte? Auf die Gründe gehen wir später ein.
Hier ist zu beachten, dass die Cache-Zeile die kleinste Einheit der Datenübertragung zwischen Cache und Hauptspeicher ist. Was bedeutet es? Wenn die CPU versucht, ein Datenbyte zu laden und der Cache fehlt, lädt der Cache-Controller sofort Daten in Cache-Zeilengröße aus dem Hauptspeicher in den Cache. Die Cache-Zeilengröße beträgt beispielsweise 8 Byte. Selbst wenn die CPU ein Byte liest, lädt der Cache nach dem Fehlen des Caches 8 Bytes aus dem Hauptspeicher, um die gesamte Cache-Zeile zu füllen. Und warum? Du wirst es verstehen, wenn ich zu Ende darüber gesprochen habe.
Wir gehen davon aus, dass die folgenden Erklärungen für einen 64-Byte-Cache gelten und die Cache-Zeilengröße 8 Byte beträgt. Wir können uns diesen Cache als Array vorstellen. Das Array besteht aus insgesamt 8 Elementen und jedes Element ist 8 Byte groß. Genau wie das Bild unten.

Jetzt betrachten wir ein Problem. Die CPU liest ein Byte von der Adresse 0x0654. Wie ermittelt der Cache-Controller, ob die Daten im Cache liegen. Die Cache-Größe wird vom Hauptspeicher in den Schatten gestellt. Der Cache darf also nur einen sehr kleinen Teil der Daten im Hauptspeicher zwischenspeichern können. Wie finden wir Daten in einem Cache mit begrenzter Größe basierend auf der Adresse? Der aktuelle Hardware-Ansatz besteht darin, die Adresse zu hashen (was als Adress-Modulo-Operation verstanden werden kann). Mal sehen, wie es als nächstes gemacht wird?

Wir haben insgesamt 8 Cache-Zeilen und die Cache-Zeilengröße beträgt 8 Bytes. Wir können also die unteren 3 Bits der Adresse (wie im blauen Teil der Adresse oben gezeigt) verwenden, um ein bestimmtes Byte in 8 Bytes zu adressieren. Wir nennen diese Bitkombination Offset. Auf die gleiche Weise werden 8 Zeilen Cache-Zeilen verwendet, um alle Zeilen abzudecken.
Wir benötigen 3 Bits (wie im gelben Teil der Adresse oben gezeigt), um eine bestimmte Zeile zu finden. Dieser Teil der Adresse wird Index genannt. Jetzt wissen wir, dass, wenn die Bit3-Bit5 zweier verschiedener Adressen genau gleich sind, die beiden Adressen nach dem Hardware-Hashing dieselbe Cache-Zeile finden. Wenn wir also die Cache-Zeile finden, bedeutet dies nur, dass die Daten, die der von uns aufgerufenen Adresse entsprechen, in dieser Cache-Zeile vorhanden sein können, es können sich jedoch auch Daten befinden, die anderen Adressen entsprechen. Daher führen wir den Tag-Array-Bereich ein, und das Tag-Array und das Daten-Array entsprechen eins zu eins.
Jede Cache-Zeile entspricht einem eindeutigen Tag. Was im Tag gespeichert ist, ist die verbleibende Bitbreite der gesamten Adresse mit Ausnahme der von Index und Offset verwendeten Bits (wie im grünen Teil der Adresse oben gezeigt). Die Kombination aus Tag, Index und Offset kann eine Adresse eindeutig bestimmen. Wenn wir daher die Cache-Zeile anhand des Indexbits in der Adresse finden, nehmen wir das Tag heraus, das der aktuellen Cache-Zeile entspricht, und vergleichen es dann mit dem Tag in der Adresse. Wenn sie gleich sind, bedeutet dies einen Cache-Treffer . Wenn sie nicht gleich sind, bedeutet dies, dass die aktuelle Cache-Zeile Daten an anderen Adressen speichert, was einen Cache-Fehler darstellt.
Im obigen Bild sehen wir, dass der Tag-Wert 0x19 ist, was dem Tag-Teil der Adresse entspricht, sodass er bei diesem Zugriff erreicht wird. Aufgrund der Einführung des Tags wurde eine unserer vorherigen Fragen beantwortet: „Warum wird die Hardware-Cache-Zeile nicht in ein Byte umgewandelt?“. Dies wird zu einem Anstieg der Hardwarekosten führen, da ursprünglich 8 Bytes einem Tag entsprachen, nun aber 8 Tags benötigt werden, die viel Speicher belegen.
Auf dem Bild können wir sehen, dass sich neben dem Tag ein gültiges Bit befindet. Dieses Bit wird verwendet, um anzuzeigen, ob die Daten in der Cache-Zeile gültig sind (zum Beispiel: 1 bedeutet gültig; 0 bedeutet ungültig). . Beim ersten Systemstart sollten die Daten im Cache ungültig sein, da noch keine Daten zwischengespeichert wurden. Der Cache-Controller kann anhand des gültigen Bits bestätigen, ob die aktuellen Cache-Zeilendaten gültig sind. Bevor das obige Vergleichs-Tag bestätigt, ob die Cache-Zeile erreicht wurde, prüft es daher auch, ob das gültige Bit gültig ist. Der Vergleich von Tags ist nur dann sinnvoll, wenn sie gültig sind. Wenn es ungültig ist, wird direkt festgestellt, dass der Cache fehlt.
Im obigen Beispiel beträgt die Cache-Größe 64 Byte und die Cache-Zeilengröße 8 Byte. Offset, Index und Tag verwenden jeweils 3 Bit, 3 Bit und 42 Bit (vorausgesetzt, die Adressbreite beträgt 48 Bit). Schauen wir uns jetzt ein anderes Beispiel an: 512 Bytes Cache-Größe, 64 Bytes Cache-Zeilengröße. Gemäß der vorherigen Methode zur Adressteilung verwenden Offset, Index und Tag jeweils 6 Bit, 3 Bit und 39 Bit. Wie unten gezeigt.

Der direkt zugeordnete Cache wird im Hardware-Design einfacher sein, daher sind die Kosten höher niedriger Niedrig. Gemäß der Arbeitsmethode des Direct-Mapping-Cache können wir das Cache-Verteilungsdiagramm zeichnen, das der Hauptspeicheradresse 0x00-0x88 entspricht.
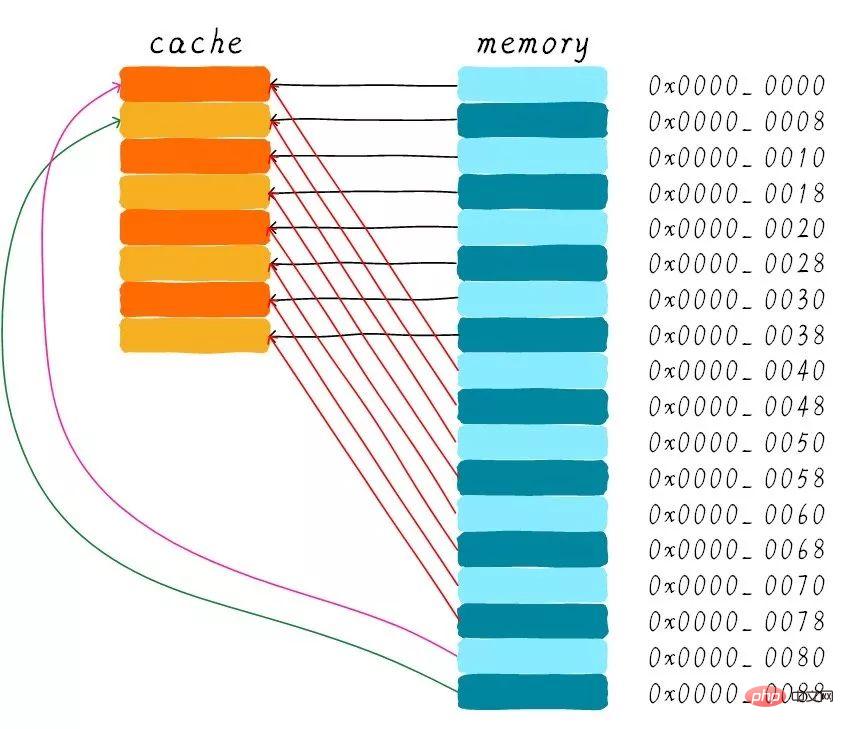
Wir können sehen, dass die Daten, die der Adresse 0x00-0x3f entsprechen, den gesamten Cache abdecken können. Auch die Daten an den Adressen 0x40-0x7f decken den gesamten Cache ab. Lassen Sie uns jetzt über eine Frage nachdenken: Was passiert mit den Daten im Cache, wenn ein Programm versucht, nacheinander auf die Adressen 0x00, 0x40 und 0x80 zuzugreifen?
Zunächst sollten wir verstehen, dass der Indexteil der Adressen 0x00, 0x40 und 0x80 derselbe ist. Daher sind die diesen drei Adressen entsprechenden Cache-Zeilen gleich. Wenn wir also auf die Adresse 0x00 zugreifen, fehlt der Cache und die Daten werden dann aus dem Hauptspeicher in die Cache-Zeile 0 geladen. Wenn wir auf die 0x40-Adresse zugreifen, indizieren wir immer noch die 0. Cache-Zeile im Cache. Da die Cache-Zeile zu diesem Zeitpunkt die Daten speichert, die der Adresse 0x00 entsprechen, fehlt der Cache zu diesem Zeitpunkt noch. Laden Sie dann die 0x40-Adressdaten aus dem Hauptspeicher in die erste Cache-Zeile. Ebenso fehlt der Cache weiterhin, wenn Sie weiterhin auf die 0x80-Adresse zugreifen.
Dies entspricht dem Lesen von Daten jedes Mal aus dem Hauptspeicher, sodass die Existenz eines Caches die Leistung nicht verbessert. Beim Zugriff auf die Adresse 0x40 werden die an der Adresse 0x00 zwischengespeicherten Daten ersetzt. Dieses Phänomen wird Cache-Thrashing genannt. Um dieses Problem zu lösen, führen wir einen über mehrere Gruppen verbundenen Cache ein. Lassen Sie uns zunächst untersuchen, wie der einfachste Zwei-Wege-Set-Connected-Cache funktioniert.
Wir gehen immer noch davon aus, dass die Cache-Größe 64 Byte und die Cache-Zeilengröße 8 Byte beträgt . Was ist der Begriff Straße? Wir teilen den Cache in mehrere gleiche Teile auf, und jeder Teil ist ein Weg. Daher teilt der Zwei-Wege-Set-Connected-Cache den Cache in zwei gleiche Teile, wobei jeder Teil 32 Bytes groß ist. Wie unten gezeigt.
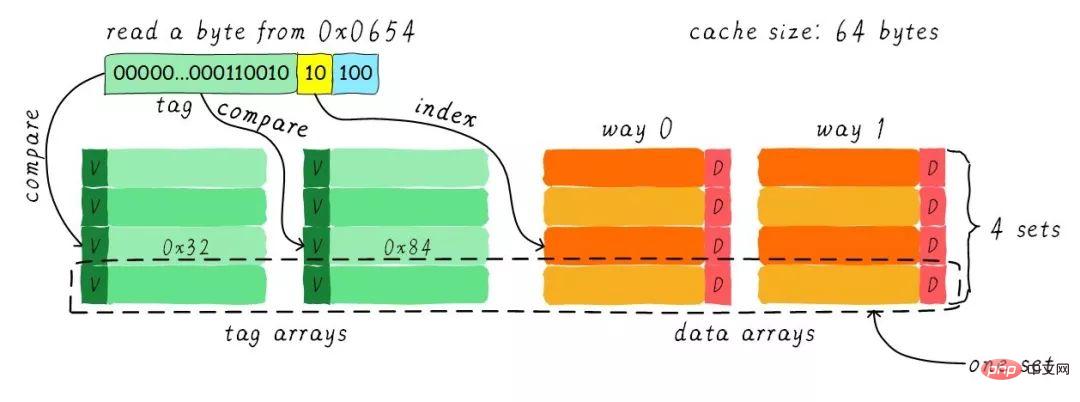
Der Cache ist in 2 Pfade unterteilt, jeder Pfad enthält 4 Cache-Zeilen. Wir gruppieren alle Cache-Zeilen mit demselben Index und nennen sie Gruppen. Im Bild oben hat eine Gruppe beispielsweise zwei Cache-Zeilen, also insgesamt 4 Gruppen. Wir gehen immer noch davon aus, dass ein Byte Daten von der Adresse 0x0654 gelesen wird. Da die Cache-Zeilengröße 8 Byte beträgt, erfordert der Offset 3 Bit, was dem vorherigen Direct-Mapping-Cache entspricht. Der Unterschied besteht im Index. Bei einem in beide Richtungen verbundenen Cache benötigt der Index nur 2 Bits, da in einer Richtung nur 4 Cache-Zeilen vorhanden sind.
Das obige Beispiel findet die 2. Cache-Zeile basierend auf dem Index (berechnet von 0). Die 2. Zeile entspricht 2 Cache-Zeilen, entsprechend Weg 0 bzw. Weg 1. Daher kann der Index auch als Mengenindex (Gruppenindex) bezeichnet werden. Suchen Sie zuerst den Satz anhand des Index, nehmen Sie dann die Tags heraus, die allen Cache-Zeilen in der Gruppe entsprechen, und vergleichen Sie sie mit dem Tag-Teil in der Adresse. Wenn einer von ihnen gleich ist, bedeutet dies einen Treffer.
Daher besteht der größte Unterschied zwischen dem Zwei-Wege-Set-Connected-Cache und dem Direct-Mapping-Cache darin, dass die Daten, die der ersten Adresse entsprechen, zwei Cache-Zeilen entsprechen können, während im Direct-Mapping-Cache Eine Adresse entspricht nur einer Cache-Zeile. Was genau sind also die Vorteile davon?
Die Hardwarekosten des Two-Way Set-Associated Cache sind höher als die des Direct-Mapping-Cache. Da jedes Mal, wenn Tags verglichen werden, Tags verglichen werden müssen, die mehreren Cache-Zeilen entsprechen (einige Hardware führt möglicherweise auch parallele Vergleiche durch, um die Vergleichsgeschwindigkeit zu erhöhen, was die Komplexität des Hardware-Designs erhöht).
Warum brauchen wir immer noch einen bidirektionalen, gruppenverbundenen Cache? Weil es dazu beitragen kann, die Möglichkeit eines Cache-Thrashings zu verringern. Wie wird es reduziert? Gemäß der Arbeitsmethode des Zwei-Wege-Set-Connected-Cache können wir das Cache-Verteilungsdiagramm zeichnen, das der Hauptspeicheradresse 0x00-0x4f entspricht.
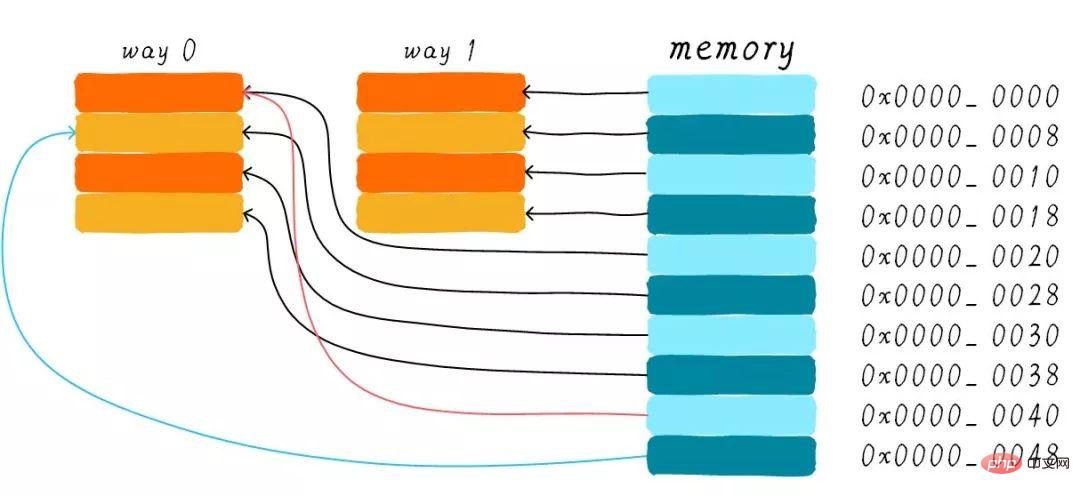
Wir betrachten immer noch die Frage im Abschnitt „Direct Mapped Cache“: „Wenn ein Programm versucht, nacheinander auf die Adressen 0x00, 0x40 und 0x80 zuzugreifen, was passiert dann mit den Daten in.“ der Cache?". Jetzt können die Daten an Adresse 0x00 in Weg 1 und 0x40 in Weg 0 geladen werden. Vermeidet dies bis zu einem gewissen Grad die peinliche Situation des Direct-Mapping-Cache? Bei einem bidirektionalen satzverbundenen Cache werden die Daten an den Adressen 0x00 und 0x40 im Cache zwischengespeichert. Stellen Sie sich vor, wenn wir einen 4-Wege-Gruppenverbindungs-Cache verwenden und später weiterhin auf 0x80 zugreifen, wird dieser möglicherweise auch zwischengespeichert.
Wenn die Cache-Größe sicher ist, ist die Leistungsverbesserung des gruppenverbundenen Caches im schlimmsten Fall dieselbe wie die des direkt zugeordneten Caches besser als der des direkt zugeordneten Caches. Gleichzeitig wird die Häufigkeit von Cache-Thrashing reduziert. In gewisser Weise ist der Direct-Mapping-Cache ein Sonderfall des Set-Linked-Cache mit nur einer Cache-Zeile pro Gruppe. Daher kann ein direkt zugeordneter Cache auch als einseitig satzverbundener Cache bezeichnet werden.
Da der gruppenassoziative Cache so gut ist, wenn alle Cachezeilen in einer Gruppe sind. Wäre die Leistung nicht besser? Ja, dieser Cache-Typ ist ein vollständig verbundener Cache. Als Beispiel nehmen wir immer noch den 64 Byte großen Cache.
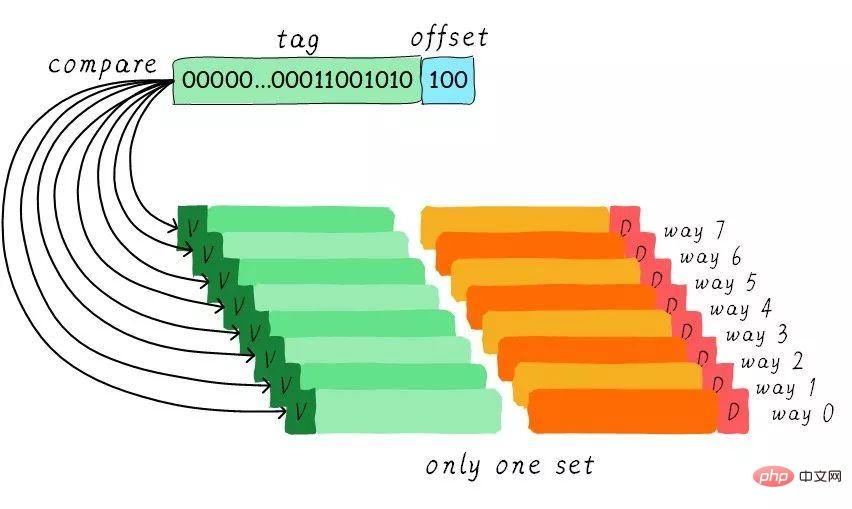
Da sich alle Cache-Zeilen in einer Gruppe befinden, gibt es in der Adresse keinen festgelegten Indexteil. Weil Sie nur eine Gruppe auswählen können, was indirekt bedeutet, dass Sie keine Wahl haben. Wir vergleichen den Tag-Teil in der Adresse mit den Tags, die allen Cache-Zeilen entsprechen (die Hardware kann parallele oder serielle Vergleiche durchführen). Welches Tag gleich ist, bedeutet, dass eine bestimmte Cache-Zeile erreicht wird. Daher können in einem vollständig verbundenen Cache Daten an jeder Adresse in jeder Cache-Zeile zwischengespeichert werden. Dadurch kann die Häufigkeit von Cache-Thrashing minimiert werden. Allerdings sind auch die Hardwarekosten höher.
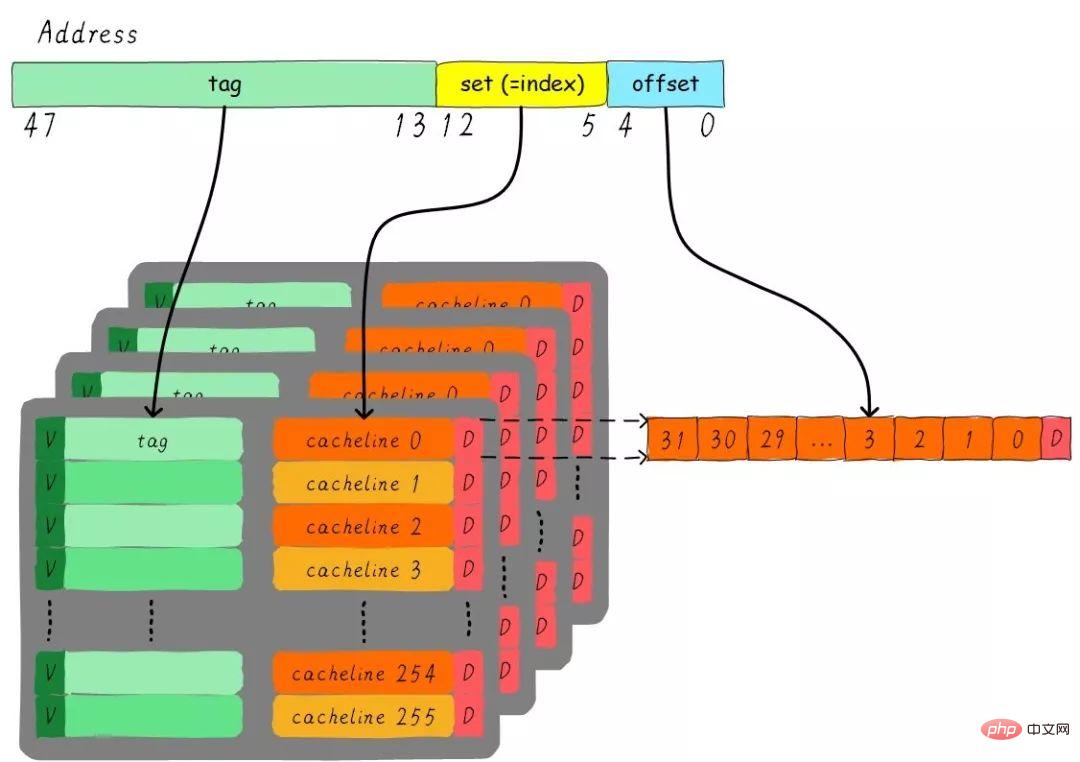
Stellen Sie sich ein solches Problem vor: Ein 4-Wege-Set-Connected-Cache mit einer Größe von 32 KB beträgt die Cache-Zeilengröße 32 Bytes. Bitte denken Sie über die Fragen nach:
1). 2) Unter der Annahme, dass die Adressbreite 48 Bit beträgt, wie viele Bits belegen Index, Offset und Tag?
Es gibt insgesamt 4 Wege, daher beträgt die Größe jedes Weges 8 KB. Die Cache-Zeilengröße beträgt 32 Bytes, es gibt also insgesamt 256 Gruppen (8 KB / 32 Bytes). Da die Cache-Zeilengröße 32 Byte beträgt, sind für den Offset 5 Bit erforderlich. Insgesamt gibt es 256 Gruppen, sodass der Index 8 Bit benötigt und der Rest der Tag-Teil ist, der 35 Bit belegt. Dieser Cache kann durch die folgende Abbildung dargestellt werden.
Die Cache-Zuweisungsrichtlinie bezieht sich auf die Umstände, unter denen wir Cache zuweisen sollten Datenleitung. Die Cache-Zuweisungsstrategie ist in zwei Situationen unterteilt: Lesen und Schreiben.
Lesezuordnung:
Wenn die CPU Daten liest, kommt es zu einem Cache-Fehler. In diesem Fall wird ein Cache-Zeilen-Cache zum Lesen aus dem Hauptspeicher zugewiesen . Standardmäßig unterstützen Caches die Lesezuweisung.
Zuordnung schreiben:
Wenn die CPU Daten schreibt und Cache-Fehler auftreten, wird die Schreibzuweisungsstrategie berücksichtigt. Wenn wir die Schreibzuweisung nicht unterstützen, aktualisiert der Schreibbefehl nur die Hauptspeicherdaten und endet dann. Wenn die Schreibzuweisung unterstützt wird, laden wir zunächst Daten aus dem Hauptspeicher in die Cache-Zeile (entspricht einer ersten Lesezuweisung) und aktualisieren dann die Daten in der Cache-Zeile.
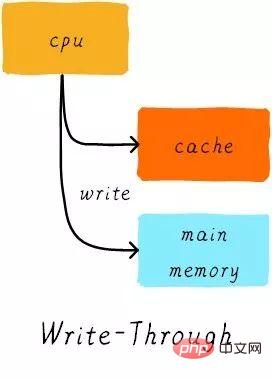
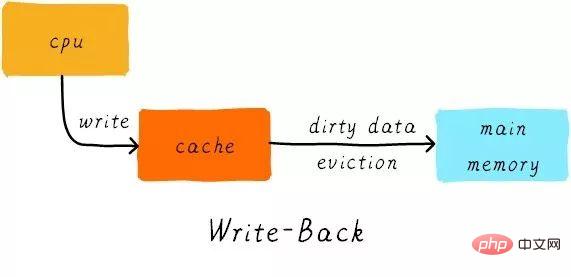
Die Cache-Aktualisierungsrichtlinie bezieht sich darauf, wie Schreibvorgänge Daten aktualisieren sollen, wenn ein Cache-Treffer auftritt. Cache-Aktualisierungsstrategien werden in zwei Typen unterteilt: Durchschreiben und Zurückschreiben.
Durchschreiben:
Wenn die CPU die Speicheranweisung ausführt und der Cache trifft, aktualisieren wir die Daten im Cache und die Daten im Hauptspeicher. Die Daten im Cache und im Hauptspeicher sind stets konsistent.
Zurückschreiben:
Wenn die CPU den Speicherbefehl ausführt und der Cache trifft, aktualisieren wir nur die Cache-Daten. Und in jeder Cache-Zeile gibt es ein Bit, das aufzeichnet, ob die Daten geändert wurden, ein sogenanntes Dirty-Bit (sehen Sie sich das vorherige Bild an, neben der Cache-Zeile befindet sich ein D, das Dirty-Bit). Wir werden das Dirty-Bit setzen. Daten im Hauptspeicher werden nur aktualisiert, wenn die Cache-Zeile ersetzt oder ein Reinigungsvorgang durchgeführt wird. Daher kann es sich bei den Daten im Hauptspeicher um unveränderte Daten handeln, während die geänderten Daten in der Cache-Zeile liegen.
Warum ist gleichzeitig die Cache-Zeilengröße die kleinste Einheit der Datenübertragung zwischen dem Cache-Controller und dem Hauptspeicher? Dies liegt auch daran, dass jede Cache-Zeile nur ein Dirty-Bit hat. Dieses Dirty-Bit repräsentiert den geänderten Status der gesamten Cache-Zeile.
Angenommen, wir haben einen direkt zugeordneten Cache mit einer Größe von 64 Byte, die Cache-Zeilengröße beträgt 8 Byte, unter Verwendung der Schreibzuweisung und Write-Back-Mechanismus. Wie ändern sich die Daten im Cache, wenn die CPU ein Byte von der Adresse 0x2a liest? Gehen Sie davon aus, dass der aktuelle Cache-Status wie in der folgenden Abbildung dargestellt ist.
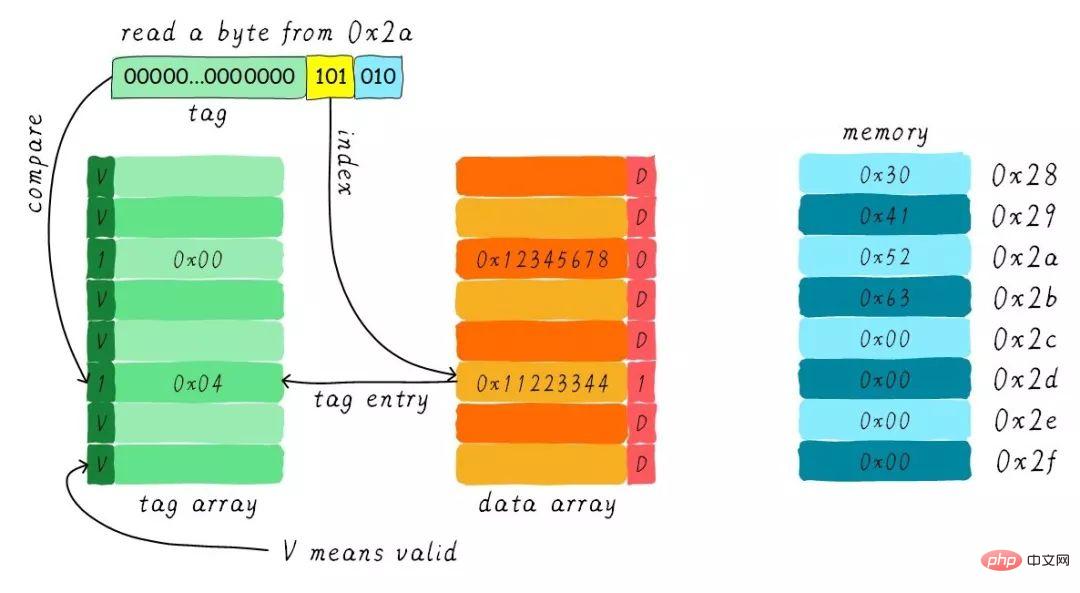
Suchen Sie die entsprechende Cache-Zeile gemäß dem Index. Das gültige Bit des entsprechenden Tag-Teils ist zulässig, aber der Wert des Tags ist nicht gleich, daher erfolgt eine Löschung . Zu diesem Zeitpunkt müssen wir 8 Byte Daten von der Adresse 0x28 in die Cache-Zeile laden. Wir haben jedoch festgestellt, dass das Dirty-Bit der aktuellen Cache-Zeile gesetzt ist. Daher können die Daten in der Cache-Zeile nicht einfach verworfen werden. Aufgrund des Rückschreibmechanismus müssen wir die Daten 0x11223344 im Cache an die Adresse 0x0128 schreiben (diese Adresse wird basierend auf dem Wert im Tag und im Cache berechnet). Zeile, in der es sich befindet) ). Dieser Vorgang ist in der folgenden Abbildung dargestellt.
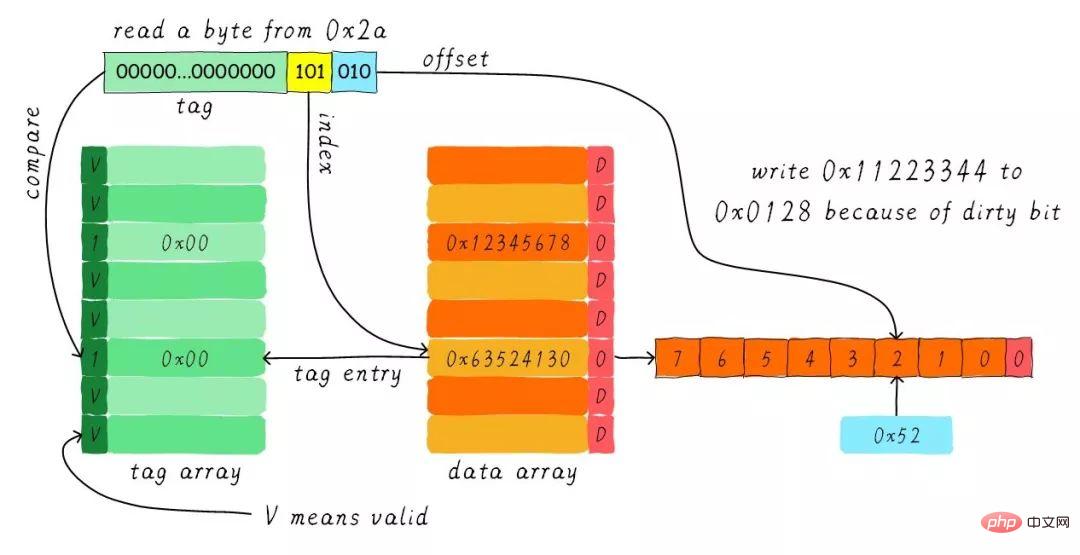
Wenn der Rückschreibvorgang abgeschlossen ist, laden wir die 8 Bytes beginnend bei Adresse 0x28 im Hauptspeicher in die Cache-Zeile und löschen das Dirty-Bit. Suchen Sie dann entsprechend dem Offset 0x52 und geben Sie es an die CPU zurück.
Vielen Dank für Ihre Geduld beim Lesen, ich hoffe, Sie können davon profitieren.
Dieser Artikel ist eine Reproduktion von Wowotech.net/memory_management/458.html
Empfohlenes Tutorial: „Linux-Betrieb und -Wartung“
Das obige ist der detaillierte Inhalt vonÜber den Cache-Speicher von Linux (ausführliche Bild- und Texterklärung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



