

Was sind die Merkmale von Kafka?
Die Eigenschaften von Kafka sind: 1. Bietet einen hohen Durchsatz sowohl für die Veröffentlichung als auch für das Abonnement. 2. Kann Persistenzvorgänge ausführen und Nachrichten auf der Festplatte speichern, sodass es für den Stapelverbrauch verwendet werden kann 4. Unterstützt Online- und Offline-Szenarien.

Kafkas Funktionen und Nutzungsszenarien
Kafka ist ein verteiltes Publish-Subscribe-Nachrichtensystem. Es wurde ursprünglich von der LinkedIn Corporation entwickelt und wurde später Teil des Apache-Projekts. Kafka ist ein verteilter, partitionierbarer, redundanter und persistenter Protokolldienst.
Es wird hauptsächlich zur Verarbeitung aktiver Streaming-Daten verwendet. In Big-Data-Systemen stoßen wir häufig auf ein Problem: Die gesamten Big Data bestehen aus verschiedenen Subsystemen. Daten müssen in jedem Subsystem kontinuierlich mit hoher Leistung und geringer Latenz zirkulieren.
Herkömmliche Enterprise-Messaging-Systeme sind für die Datenverarbeitung in großem Maßstab nicht sehr geeignet. Um gleichzeitig Online-Anwendungen (Nachrichten) und Offline-Anwendungen (Datendateien, Protokolle) verarbeiten zu können, erschien Kafka. Kafka kann zwei Rollen spielen:
Reduzieren Sie die Komplexität der Systemvernetzung.
Reduziert die Programmierkomplexität. Jedes Subsystem wird nicht mehr wie ein Socket an einen Socket angeschlossen.
Hauptfunktionen von Kafka:
Bietet hohen Durchsatz sowohl für Veröffentlichungen als auch für Abonnements. Es wird davon ausgegangen, dass Kafka etwa 250.000 Nachrichten (50 MB) pro Sekunde produzieren und 550.000 Nachrichten (110 MB) pro Sekunde verarbeiten kann.
kann Persistenzoperationen durchführen. Behalten Sie Nachrichten auf der Festplatte bei, damit sie für die Stapelverarbeitung, z. B. ETL, sowie für Echtzeitanwendungen verwendet werden können. Verhindern Sie Datenverlust, indem Sie Daten auf der Festplatte speichern und replizieren.
Verteiltes System, leicht nach außen erweiterbar. Alle Produzenten, Makler und Verbraucher werden mehrere haben, und sie sind alle verteilt. Maschinen können ohne Ausfallzeiten erweitert werden.
Der Status der Nachrichtenverarbeitung wird auf der Verbraucherseite und nicht auf der Serverseite verwaltet. Gleicht automatisch aus, wenn ein Fehler auftritt.
Unterstützt Online- und Offline-Szenarien.
Die Designpunkte von Kafka:
1. Verwenden Sie direkt den Cache des Linux-Dateisystems, um Daten effizient zwischenzuspeichern.
2. Verwenden Sie Linux Zero-Copy, um die Sendeleistung zu verbessern. Beim herkömmlichen Senden von Daten sind vier Kontextwechsel erforderlich. Nach Verwendung des Systemaufrufs sendfile werden die Daten direkt im Kernelstatus ausgetauscht und der Systemkontextwechsel wird auf zwei reduziert. Den Testergebnissen zufolge kann die Datensendeleistung um 60 % verbessert werden.
3. Die Kosten für den Datenzugriff auf die Festplatte betragen O(1). Kafka verwendet Themen für die Nachrichtenverwaltung. Jedes Thema enthält mehrere Teile (itionen). Jeder Teil entspricht einem logischen Protokoll und besteht aus mehreren Segmenten. In jedem Segment werden mehrere Nachrichten gespeichert (siehe Abbildung unten). Die Nachrichten-ID wird durch ihren logischen Speicherort bestimmt, d. h. die Nachrichten-ID kann direkt dem Speicherort der Nachricht zugeordnet werden, wodurch eine zusätzliche Zuordnung der ID zum Speicherort vermieden wird. Jeder Teil entspricht einem Index im Speicher, und der Offset der ersten Nachricht in jedem Segment wird aufgezeichnet. Die vom Herausgeber an ein Thema gesendete Nachricht wird gleichmäßig auf mehrere Teile verteilt (zufällig oder gemäß der vom Benutzer angegebenen Rückruffunktion verteilt). Der Broker empfängt die veröffentlichte Nachricht und fügt die Nachricht dem letzten Segment des entsprechenden Teils hinzu. Wenn die Anzahl der Nachrichten in einem Segment den konfigurierten Wert erreicht oder die Nachrichtenveröffentlichungszeit den Schwellenwert überschreitet, werden die Nachrichten auf dem Segment auf die Festplatte geleert. Nur Abonnenten der auf die Festplatte geleerten Nachrichten können abonnieren Ab einer bestimmten Größe werden die Daten nicht mehr in das Segment geschrieben und der Broker erstellt ein neues Segment.
4. Explizite Verteilung, das heißt, alle Produzenten, Makler und Verbraucher werden mehrfach verteilt. Es gibt keinen Lastausgleichsmechanismus zwischen Produzent und Broker. Zookeeper wird für den Lastausgleich zwischen Brokern und Verbrauchern verwendet.
Alle Makler und Verbraucher werden in zookeeper registriert und zookeeper speichert einige ihrer Metadateninformationen. Bei einem Wechsel eines Maklers oder Verbrauchers werden alle anderen Makler und Verbraucher benachrichtigt.
Das obige ist der detaillierte Inhalt vonWas sind die Merkmale von Kafka?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
Mit der Entwicklung des Internets und der Technologie sind digitale Investitionen zu einem Thema mit zunehmender Besorgnis geworden. Viele Anleger erforschen und studieren weiterhin Anlagestrategien in der Hoffnung, eine höhere Kapitalrendite zu erzielen. Im Aktienhandel ist die Aktienanalyse in Echtzeit für die Entscheidungsfindung sehr wichtig, und der Einsatz der Kafka-Echtzeit-Nachrichtenwarteschlange und der PHP-Technologie ist ein effizientes und praktisches Mittel. 1. Einführung in Kafka Kafka ist ein von LinkedIn entwickeltes verteiltes Publish- und Subscribe-Messagingsystem mit hohem Durchsatz. Die Hauptmerkmale von Kafka sind
 So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
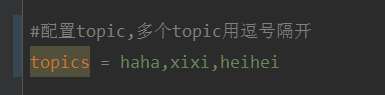
Erklären Sie, dass es sich bei diesem Projekt um ein Springboot+Kafak-Integrationsprojekt handelt und daher die Kafak-Verbrauchsanmerkung @KafkaListener in Springboot verwendet. Konfigurieren Sie zunächst mehrere durch Kommas getrennte Themen in application.properties. Methode: Verwenden Sie den SpEl-Ausdruck von Spring, um Themen wie folgt zu konfigurieren: @KafkaListener(topics="#{’${topics}’.split(',')}"), um das Programm auszuführen. Der Konsolendruckeffekt ist wie folgt
 Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Spring-Kafka basiert auf der Integration der Java-Version von Kafkaclient und Spring. Es bietet KafkaTemplate, das verschiedene Methoden für eine einfache Bedienung kapselt. Es kapselt den Kafka-Client von Apache und es ist nicht erforderlich, den Client zu importieren, um von der Organisation abhängig zu sein .springframework.kafkaspring-kafkaYML-Konfiguration. kafka:#bootstrap-servers:server1:9092,server2:9093#kafka-Entwicklungsadresse,#producer-Konfigurationsproduzent:#Serialisierungs- und Deserialisierungsklassenschlüssel, bereitgestellt von Kafka
 So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So verwenden Sie React und Apache Kafka zum Erstellen von Echtzeit-Datenverarbeitungsanwendungen. Einführung: Mit dem Aufkommen von Big Data und Echtzeit-Datenverarbeitung ist die Erstellung von Echtzeit-Datenverarbeitungsanwendungen für viele Entwickler zum Ziel geworden. Die Kombination von React, einem beliebten Front-End-Framework, und Apache Kafka, einem leistungsstarken verteilten Messaging-System, kann uns beim Aufbau von Echtzeit-Datenverarbeitungsanwendungen helfen. In diesem Artikel wird erläutert, wie Sie mit React und Apache Kafka Echtzeit-Datenverarbeitungsanwendungen erstellen
 Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Optionen für Kafka-Visualisierungstools ApacheKafka ist eine verteilte Stream-Verarbeitungsplattform, die große Mengen an Echtzeitdaten verarbeiten kann. Es wird häufig zum Aufbau von Echtzeit-Datenpipelines, Nachrichtenwarteschlangen und ereignisgesteuerten Anwendungen verwendet. Die Visualisierungstools von Kafka können Benutzern dabei helfen, Kafka-Cluster zu überwachen und zu verwalten und Kafka-Datenflüsse besser zu verstehen. Im Folgenden finden Sie eine Einführung in fünf beliebte Kafka-Visualisierungstools: ConfluentControlCenterConfluent
 Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Wie wählt man das richtige Kafka-Visualisierungstool aus? Vergleichende Analyse von fünf Tools Einführung: Kafka ist ein leistungsstarkes verteiltes Nachrichtenwarteschlangensystem mit hohem Durchsatz, das im Bereich Big Data weit verbreitet ist. Mit der Popularität von Kafka benötigen immer mehr Unternehmen und Entwickler ein visuelles Tool zur einfachen Überwachung und Verwaltung von Kafka-Clustern. In diesem Artikel werden fünf häufig verwendete Kafka-Visualisierungstools vorgestellt und ihre Merkmale und Funktionen verglichen, um den Lesern bei der Auswahl des Tools zu helfen, das ihren Anforderungen entspricht. 1. KafkaManager
 Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Informationen zur Konfigurationsdatei kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#Die Anzahl der Threads, die gleichzeitig verwendet werden können (normalerweise konsistent). mit der Anzahl der Partitionen )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
In den letzten Jahren haben mit dem Aufkommen von Big Data und aktiven Open-Source-Communities immer mehr Unternehmen begonnen, nach leistungsstarken interaktiven Datenverarbeitungssystemen zu suchen, um den wachsenden Datenanforderungen gerecht zu werden. In dieser Welle von Technologie-Upgrades werden Go-Zero und Kafka+Avro von immer mehr Unternehmen beachtet und übernommen. go-zero ist ein auf der Golang-Sprache entwickeltes Microservice-Framework. Es zeichnet sich durch hohe Leistung, Benutzerfreundlichkeit, einfache Erweiterung und einfache Wartung aus und soll Unternehmen dabei helfen, schnell effiziente Microservice-Anwendungssysteme aufzubauen. sein schnelles Wachstum