

Wie implementiert Redis die Verzögerungswarteschlange? Methodeneinführung


Verzögerungswarteschlange ist, wie der Name schon sagt, eine Nachrichtenwarteschlange mit Verzögerungsfunktion. Unter welchen Umständen benötige ich eine solche Warteschlange?
1. Hintergrund
Sehen wir uns zunächst das folgende Geschäftsszenario an:
- Wenn die Bestellung eingegangen ist unbezahlt So schließen Sie eine Bestellung rechtzeitig ab, wenn der Status lautet
- So überprüfen Sie regelmäßig, ob eine Bestellung im Rückerstattungsstatus erfolgreich erstattet wurde
- So gehen Sie vor, wenn eine Bestellung keine Statusbenachrichtigung erhält vom Downstream-System für eine lange Zeit Strategien zur schrittweisen Synchronisierung des Bestellstatus
- Wenn das System das Upstream-System über den endgültigen Status der erfolgreichen Zahlung benachrichtigt, gibt das Upstream-System einen Benachrichtigungsfehler zurück. So führen Sie eine asynchrone Benachrichtigung durch und senden Sie es in geteilten Frequenzen: 15s 3m 10m 30m 30m 1h 2h 6h 15h
1.1 Lösung
Am einfachsten ist es, den Zähler regelmäßig zu scannen . Wenn beispielsweise die Anforderungen an den Zahlungsablauf bei Bestellungen relativ hoch sind, wird der Zähler alle 2 Sekunden gescannt, um abgelaufene Bestellungen zu überprüfen und die Bestellungen aktiv abzuschließen. Der Vorteil ist, dass es einfach ist, Der Nachteil ist, dass die Tabelle jede Minute global gescannt wird, was Ressourcen verschwendetWenn das Auftragsvolumen der Tabellendaten bald abläuft, ist es groß , wird es zu einer Verzögerung beim Auftragsabschluss kommen.
Verwenden Sie RabbitMq oder andere MQ-Modifikationen, um Verzögerungswarteschlangen zu implementieren. Die Vorteile sind, dass es Open Source und eine vorgefertigte und stabile Implementierungslösung ist . Wenn der Team-Technologie-Stack von Natur aus über MQ verfügt, ist das in Ordnung. Wenn nicht, ist es etwas teuer, einen Satz MQ bereitzustellen, um die Warteschlange zu verzögern Listenfunktionen können wir mit Redis implementieren. Eine Verzögerungswarteschlange
-
2. Designziele
Echtzeitleistung: Fehler der zweiten Ebene sind für einen bestimmten Zeitraum zulässigHohe Verfügbarkeit: Unterstützt einzelne Maschinen, unterstützt Cluster
- Unterstützt das Löschen von Nachrichten: die Das Unternehmen löscht bestimmte Nachrichten jederzeit
- Nachrichtenzuverlässigkeit: wird garantiert mindestens einmal konsumiert
- Nachrichtenpersistenz: Basierend auf den Persistenzeigenschaften von Redis selbst bedeutet dies, dass Redis-Daten verloren gehen den Verlust verzögerter Nachrichten, kann aber als primäre Backup- und Cluster-Garantie verwendet werden. Dies kann für eine spätere Optimierung in Betracht gezogen werden, um Nachrichten in MangoDB zu speichern
- 3. Designplan
Das Design umfasst hauptsächlich die folgenden Punkte : Verwenden Sie das gesamte Redis als Nachrichtenpool und speichern Sie Nachrichten im KV-Format.
Verwenden Sie ZSET als Prioritätswarteschlange und behalten Sie die Priorität gemäß Score bei.
- Verwendung die LIST-Struktur, um den First-out-Verbrauch voranzutreiben
- ZSET und LIST speichern Nachrichtenadressen (entsprechend jedem SCHLÜSSEL im Nachrichtenpool)
- Passen Sie das Routing-Objekt an, speichern Sie ZSET- und LIST-Namen und senden Sie Nachrichten von Punkt zu Punkt auf Punkt-zu-Punkt-Weise ZSET leitet zur richtigen LISTE weiter
- Verwenden Sie den Timer, um das Routing aufrechtzuerhalten
- Implementieren Sie die Nachrichtenverzögerung gemäß den TTL-Regeln
- 3.1 Designdiagramm
Es basiert immer noch auf Youzans Verzögerungswarteschlangendesign, Optimierung und Codeimplementierung. Youzan Design
3.2 Datenstruktur 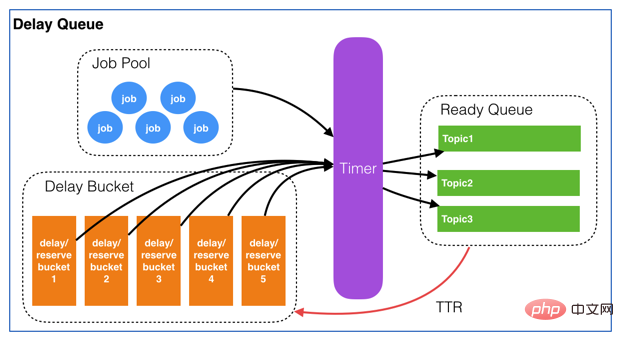
ist eine Hash_Table-Struktur, die Informationen über speichert alle Verzögerungswarteschlangen. KV-Struktur: K=Präfix+Projektname-Feld = Thema+Job-ID V=CONENT;VDie vom Client übergebenen Daten werden bei Verbrauch zurückgegeben
- Der geordnete Satz ZSET der Verzögerungswarteschlange speichert K =ID und der erforderliche Ausführungszeitstempel, sortiert nach dem Zeitstempel
ZING:DELAY_QUEUE:JOB_POOL LIST-Struktur, jedes Thema hat eine LISTE und die Liste speichert die JOBs, die aktuell verbraucht werden müssen ZING:DELAY_QUEUE:BUCKET-
ZING:DELAY_QUEUE:QUEUEDas Bild dient nur als Referenz und kann grundsätzlich die Ausführung des gesamten Prozesses beschreiben. Das Bild stammt aus dem Referenzblog am Ende des Artikels
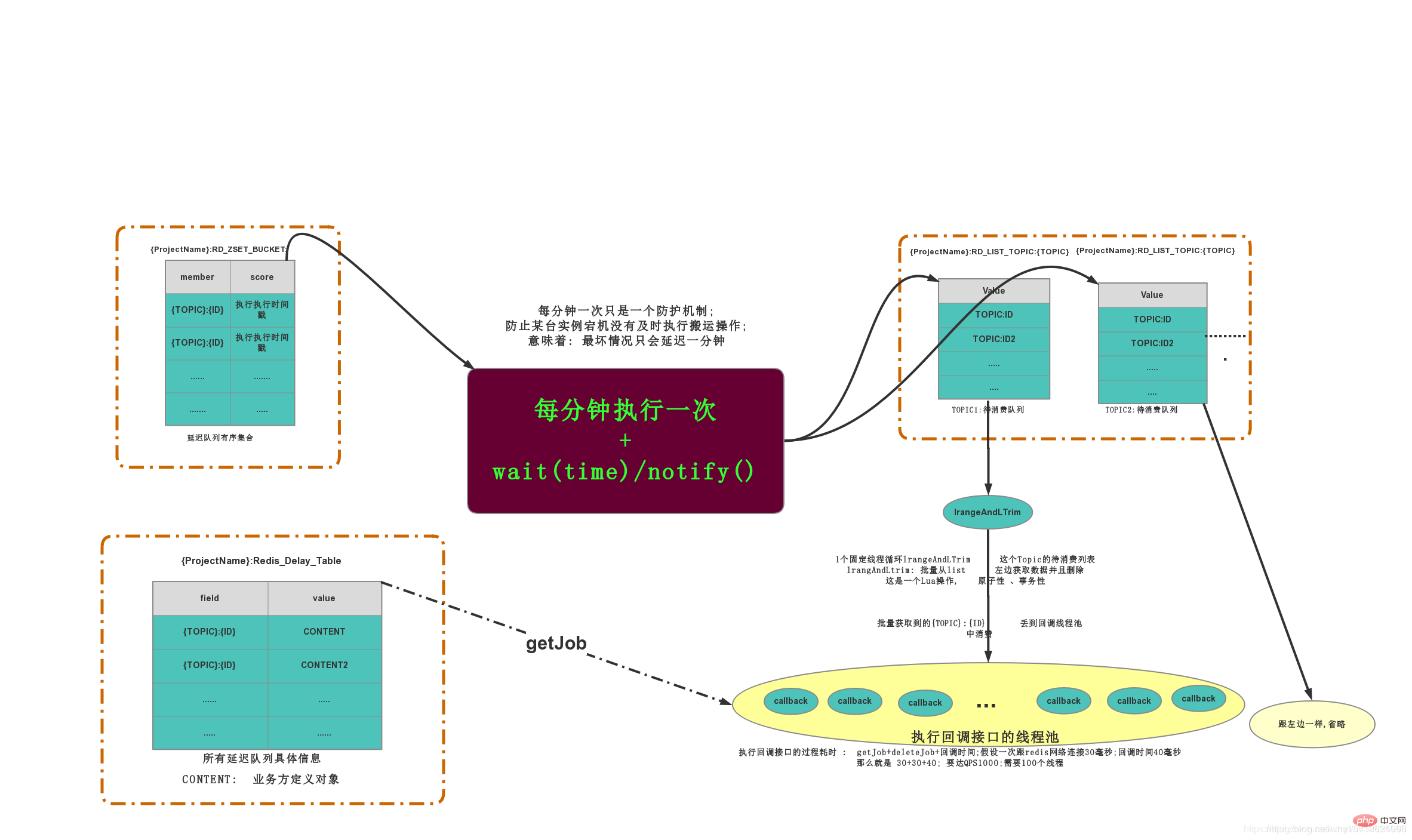 3.3 Aufgabenleben Zyklus
3.3 Aufgabenleben Zyklus
Wenn Sie einen neuen JOB hinzufügen, wird ein Datenelement in eingefügt, um die Geschäftsseite und die Verbraucherseite aufzuzeichnen. fügt außerdem einen Datensatz ein, um den Ausführungszeitstempel aufzuzeichnen.
- Der Bearbeitungsthread geht zu
- , um herauszufinden, welche Ausführungszeitstempel RunTimeMillis kleiner als die aktuelle Zeit haben, und löscht alle diese Datensätze gleichzeitig Zeitlich wird es analysiert, um herauszufinden, was das Thema jeder Aufgabe ist, und dann diese Aufgaben per Push in die Liste verschieben, die dem THEMA entspricht In der LISTE verbraucht und erhalten Alle empfangenen Daten werden in den Consumer-Thread-Pool dieses THEMA
ZING:DELAY_QUEUE:JOB_POOLZING:DELAY_QUEUE:BUCKETgeworfen. Die Ausführung des Consumer-Thread-Pools geht zu , um die Datenstruktur zu finden und sie an die Rückrufstruktur zurückzugeben. und führen Sie die Callback-Methode aus. -
ZING:DELAY_QUEUE:BUCKETZING:DELAY_QUEUE:QUEUE - 3.4 Designpunkte
-
ZING:DELAY_QUEUE:JOB_POOL3.4.1 Grundkonzepte
- JOB: Aufgaben, die eine asynchrone Verarbeitung erfordern, sind die Grundeinheiten in der Verzögerungswarteschlange
- Thema: eine Sammlung (Warteschlange) von Jobs desselben Typs. Damit Verbraucher sich anmelden können
3.4.2 Nachrichtenstruktur
Jeder JOB muss die folgenden Attribute enthalten
- jobId: Die eindeutige Kennung des Jobs. Wird zum Abrufen und Löschen bestimmter Jobinformationen verwendet.
- Thema: Jobtyp. Es kann als spezifischer Firmenname verstanden werden.
- Verzögerung: die Zeit, die der Auftrag verzögert werden muss. Einheit: Sekunden. (Der Server wandelt es in eine absolute Zeit um)
- Körper: der Inhalt des Jobs, damit Verbraucher bestimmte Geschäftsverarbeitungen durchführen können, gespeichert im JSON-Format
- Wiederholung: die Anzahl der fehlgeschlagenen Wiederholungsversuche
- URL: Benachrichtigungs-URL
3.5 Designdetails
3.5.1 Wie schnell verbrauchen
ZING:DELAY_QUEUE:QUEUEDie einfachste Möglichkeit, dies zu implementieren, ist die Verwendung eines Timers für das Scannen der zweiten Ebene, um die Aktualität der Nachrichtenausführung sicherzustellen Sie können alle 1S eine Anfrage für Redis stellen und feststellen, ob sich JOBs in der Warteschlange befinden. Wenn sich jedoch keine Verbrauchsmaterialien in der Warteschlange befinden, ist häufiges Scannen sinnlos und eine Verschwendung von Ressourcen. Wenn die Liste Daten enthält, ist dies jedoch der Fall Wenn keine Daten vorhanden sind, werden sie dort blockiert, bis die Daten zurückgegeben werden. Nach Ablauf des Zeitlimits werden die spezifischen Implementierungsmethoden und -strategien zurückgegeben >
BLPOP阻塞原语3.5.2 Vermeiden Sie die wiederholte Nachrichtenverarbeitung und den zeitbedingten Verbrauch
Verwenden Sie die verteilte Sperre von Redis, um die Nachrichtenverarbeitung zu steuern und so zu vermeiden Wiederholte Verarbeitung von Nachrichten.- Verwendung verteilter Sperren, um die Ausführungshäufigkeit von Timern sicherzustellen
Kerncode-Implementierung
4.1 Technische BeschreibungTechnologie-Stack: SpringBoot, Redisson, Redis, verteilte Sperre, Timer
Hinweis: Dieses Projekt hat den mehrfachen Warteschlangenverbrauch im Entwurfsplan nicht erkannt und nur eine Warteschlange geöffnet. Dies wird in Zukunft optimiert
4.2 Kernentität
4.2.1 Job fügt Objekte hinzu
/** * 消息结构 * * @author 睁眼看世界 * @date 2020年1月15日 */ @Data public class Job implements Serializable { private static final long serialVersionUID = 1L; /** * Job的唯一标识。用来检索和删除指定的Job信息 */ @NotBlank private String jobId; /** * Job类型。可以理解成具体的业务名称 */ @NotBlank private String topic; /** * Job需要延迟的时间。单位:秒。(服务端会将其转换为绝对时间) */ private Long delay; /** * Job的内容,供消费者做具体的业务处理,以json格式存储 */ @NotBlank private String body; /** * 失败重试次数 */ private int retry = 0; /** * 通知URL */ @NotBlank private String url; }Nach dem Login kopieren4.2.2 Job löscht Objekte
/** * 消息结构 * * @author 睁眼看世界 * @date 2020年1月15日 */ @Data public class JobDie implements Serializable { private static final long serialVersionUID = 1L; /** * Job的唯一标识。用来检索和删除指定的Job信息 */ @NotBlank private String jobId; /** * Job类型。可以理解成具体的业务名称 */ @NotBlank private String topic; }Nach dem Login kopieren4.3 Handling-Thread
/** * 搬运线程 * * @author 睁眼看世界 * @date 2020年1月17日 */ @Slf4j @Component public class CarryJobScheduled { @Autowired private RedissonClient redissonClient; /** * 启动定时开启搬运JOB信息 */ @Scheduled(cron = "*/1 * * * * *") public void carryJobToQueue() { System.out.println("carryJobToQueue --->"); RLock lock = redissonClient.getLock(RedisQueueKey.CARRY_THREAD_LOCK); try { boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS); if (!lockFlag) { throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL); } RScoredSortedSet<object> bucketSet = redissonClient.getScoredSortedSet(RD_ZSET_BUCKET_PRE); long now = System.currentTimeMillis(); Collection<object> jobCollection = bucketSet.valueRange(0, false, now, true); List<string> jobList = jobCollection.stream().map(String::valueOf).collect(Collectors.toList()); RList<string> readyQueue = redissonClient.getList(RD_LIST_TOPIC_PRE); readyQueue.addAll(jobList); bucketSet.removeAllAsync(jobList); } catch (InterruptedException e) { log.error("carryJobToQueue error", e); } finally { if (lock != null) { lock.unlock(); } } } }</string></string></object></object>Nach dem Login kopieren4.4 Verbrauchs-Thread
@Slf4j @Component public class ReadyQueueContext { @Autowired private RedissonClient redissonClient; @Autowired private ConsumerService consumerService; /** * TOPIC消费线程 */ @PostConstruct public void startTopicConsumer() { TaskManager.doTask(this::runTopicThreads, "开启TOPIC消费线程"); } /** * 开启TOPIC消费线程 * 将所有可能出现的异常全部catch住,确保While(true)能够不中断 */ @SuppressWarnings("InfiniteLoopStatement") private void runTopicThreads() { while (true) { RLock lock = null; try { lock = redissonClient.getLock(CONSUMER_TOPIC_LOCK); } catch (Exception e) { log.error("runTopicThreads getLock error", e); } try { if (lock == null) { continue; } // 分布式锁时间比Blpop阻塞时间多1S,避免出现释放锁的时候,锁已经超时释放,unlock报错 boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS); if (!lockFlag) { continue; } // 1. 获取ReadyQueue中待消费的数据 RBlockingQueue<string> queue = redissonClient.getBlockingQueue(RD_LIST_TOPIC_PRE); String topicId = queue.poll(60, TimeUnit.SECONDS); if (StringUtils.isEmpty(topicId)) { continue; } // 2. 获取job元信息内容 RMap<string> jobPoolMap = redissonClient.getMap(JOB_POOL_KEY); Job job = jobPoolMap.get(topicId); // 3. 消费 FutureTask<boolean> taskResult = TaskManager.doFutureTask(() -> consumerService.consumerMessage(job.getUrl(), job.getBody()), job.getTopic() + "-->消费JobId-->" + job.getJobId()); if (taskResult.get()) { // 3.1 消费成功,删除JobPool和DelayBucket的job信息 jobPoolMap.remove(topicId); } else { int retrySum = job.getRetry() + 1; // 3.2 消费失败,则根据策略重新加入Bucket // 如果重试次数大于5,则将jobPool中的数据删除,持久化到DB if (retrySum > RetryStrategyEnum.RETRY_FIVE.getRetry()) { jobPoolMap.remove(topicId); continue; } job.setRetry(retrySum); long nextTime = job.getDelay() + RetryStrategyEnum.getDelayTime(job.getRetry()) * 1000; log.info("next retryTime is [{}]", DateUtil.long2Str(nextTime)); RScoredSortedSet<object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE); delayBucket.add(nextTime, topicId); // 3.3 更新元信息失败次数 jobPoolMap.put(topicId, job); } } catch (Exception e) { log.error("runTopicThreads error", e); } finally { if (lock != null) { try { lock.unlock(); } catch (Exception e) { log.error("runTopicThreads unlock error", e); } } } } } }</object></boolean></string></string>Nach dem Login kopieren4.5 JOB hinzufügen und löschen
/** * 提供给外部服务的操作接口 * * @author why * @date 2020年1月15日 */ @Slf4j @Service public class RedisDelayQueueServiceImpl implements RedisDelayQueueService { @Autowired private RedissonClient redissonClient; /** * 添加job元信息 * * @param job 元信息 */ @Override public void addJob(Job job) { RLock lock = redissonClient.getLock(ADD_JOB_LOCK + job.getJobId()); try { boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS); if (!lockFlag) { throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL); } String topicId = RedisQueueKey.getTopicId(job.getTopic(), job.getJobId()); // 1. 将job添加到 JobPool中 RMap<string> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY); if (jobPool.get(topicId) != null) { throw new BusinessException(ErrorMessageEnum.JOB_ALREADY_EXIST); } jobPool.put(topicId, job); // 2. 将job添加到 DelayBucket中 RScoredSortedSet<object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE); delayBucket.add(job.getDelay(), topicId); } catch (InterruptedException e) { log.error("addJob error", e); } finally { if (lock != null) { lock.unlock(); } } } /** * 删除job信息 * * @param job 元信息 */ @Override public void deleteJob(JobDie jobDie) { RLock lock = redissonClient.getLock(DELETE_JOB_LOCK + jobDie.getJobId()); try { boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS); if (!lockFlag) { throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL); } String topicId = RedisQueueKey.getTopicId(jobDie.getTopic(), jobDie.getJobId()); RMap<string> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY); jobPool.remove(topicId); RScoredSortedSet<object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE); delayBucket.remove(topicId); } catch (InterruptedException e) { log.error("addJob error", e); } finally { if (lock != null) { lock.unlock(); } } } }</object></string></object></string>Nach dem Login kopieren5. Zu optimierender Inhalt
Derzeit gibt es nur eine Warteschlange. In der Warteschlange werden Nachrichten gespeichert. Wenn sich eine große Anzahl von Nachrichten ansammelt, die verarbeitet werden müssen, wird die Aktualität der Nachrichtenbenachrichtigungen beeinträchtigt. Die Verbesserungsmethode besteht darin, mehrere Warteschlangen zu öffnen, eine Nachrichtenweiterleitung durchzuführen und dann mehrere Verbraucherthreads für den Verbrauch zu öffnen, um Durchsatz bereitzustellen.- Die Nachricht wird nicht beibehalten, was riskant ist. Die Nachricht wird in Zukunft in MangoDB gespeichert .
QuellcodeDetailliertere Quellcodes erhalten Sie unter der untenstehenden Adresse
- zing-delay-queue (https://gitee.com/whyCodeData/zing-project/tree/master/zing-delay-queue)
RedisDelayQueue实现 redisson-spring-boot-starter (https://gitee.com/whyCodeData/zing-project/tree/master/zing-starter/redisson-spring-boot-starter) RedissonStarter zing-pay (https://gitee. com/ whyCodeData/zing-pay)项目应用
7. Referenz
https://tech.youzan.com /queuing_delay /- https://blog.csdn.net/u010634066/article/details/98864764
- Für weitere Redis-Kenntnisse beachten Sie bitte:
Das obige ist der detaillierte Inhalt vonWie implementiert Redis die Verzögerungswarteschlange? Methodeneinführung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
