

Was ist Data Mining?

Data Mining ist der Prozess der Extraktion unbekannter, aber potenziell nützlicher Informationen, die in großen Datenmengen verborgen sind. Das Ziel des Data Mining besteht darin, ein Entscheidungsmodell zu erstellen, um zukünftiges Verhalten auf der Grundlage vergangener Aktionsdaten vorherzusagen.
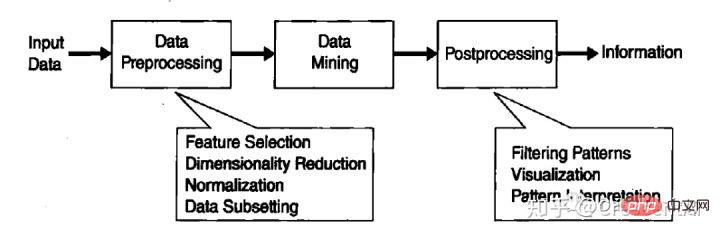
Data Mining bezeichnet den Prozess der Suche nach Informationen, die in großen Datenmengen durch Algorithmen verborgen sind.
Data Mining hängt normalerweise mit der Informatik zusammen und erreicht die oben genannten Ziele durch viele Methoden wie Statistik, analytische Online-Verarbeitung, Informationsabruf, maschinelles Lernen, Expertensysteme (basierend auf früheren Faustregeln) und Mustererkennung.
Data Mining ist ein unverzichtbarer Bestandteil der Wissensermittlung in Datenbanken (KDD), und KDD ist der gesamte Prozess der Umwandlung von Rohdaten in nützliche Informationen. Dieser Prozess umfasst eine Reihe von Konvertierungsschritten von der Datenvorverarbeitung bis zur Nachverarbeitung Data-Mining-Ergebnisse.
Der Ursprung des Data Mining
Forscher aus verschiedenen Disziplinen kamen zusammen und begannen, Tools zu entwickeln, die mit verschiedenen Datentypen umgehen können. Effizientere, skalierbarere Tools. Diese Arbeiten basieren auf den Methoden und Algorithmen, die zuvor von Forschern verwendet wurden, und gipfeln im Bereich des Data Mining.
Data Mining nutzt insbesondere Ideen aus den folgenden Bereichen: (1) Stichprobenziehung, Schätzung und Hypothesentests aus Statistiken (2) Suchalgorithmus-Modellierung von künstlicher Intelligenz, Mustererkennung und maschinellem Lernen. Technologie und Lerntheorie.
Data Mining hat auch schnell Ideen aus anderen Bereichen übernommen, darunter Optimierung, Evolutionsberechnung, Informationstheorie, Signalverarbeitung, Visualisierung und Informationsabruf.
Auch einige andere Bereiche spielen eine wichtige unterstützende Rolle. Datenbanksysteme bieten effiziente Unterstützung für Speicherung, Indizierung und Abfrageverarbeitung. Technologien, die sich aus dem Hochleistungsrechnen (Parallelrechnen) ableiten, sind oft wichtig für die Verarbeitung riesiger Datenmengen. Verteilte Technologien können auch bei der Verarbeitung riesiger Datenmengen hilfreich sein und sind umso wichtiger, wenn die Daten nicht zentral verarbeitet werden können.

KDD (Knowledge Discovery from Database)
-
Datenbereinigung
Rauschen eliminieren und inkonsistente Daten;
-
Datenintegration
Mehrere Datenquellen können miteinander kombiniert werden
-
Datenauswahl
Daten im Zusammenhang mit Analyseaufgaben aus der Datenbank extrahieren;
-
Datentransformation
Transformieren und vereinheitlichen Sie die Daten in für das Mining geeignete Daten durch Zusammenfassungs- oder Aggregationsoperationen
-
Grundschritte des Data Mining
mit intelligenten Methoden Datenmuster extrahieren;
-
Musterauswertung
Identifizieren Sie wirklich interessante Muster, die Wissen basierend auf einem bestimmten Grad an Interesse darstellen.
-
Wissensdarstellung
Verwenden Sie Visualisierungs- und Wissensdarstellungstechnologie, um Benutzern fundiertes Wissen bereitzustellen.

Data-Mining-Methodik
-
Geschäftsverständnis
Verstehen Sie die Ziele und Anforderungen des Projekts aus geschäftlicher Sicht, wandeln Sie dieses Verständnis dann durch theoretische Analyse in umsetzbare Data-Mining-Probleme um und formulieren Sie vorläufige Pläne zur Erreichung der Ziele
-
Datenverständnis
Die Datenverständnisphase beginnt mit der Sammlung von Rohdaten, macht sich dann mit den Daten vertraut, identifiziert Probleme mit der Datenqualität, untersucht ein vorläufiges Verständnis der Daten und entdeckt interessante Teilmengen zur Formulierung der Informationshypothese
-
Datenvorbereitung (Datenvorbereitung)
Die Datenvorbereitungsphase bezieht sich auf die Aktivität der Erstellung der für das Data Mining erforderlichen Informationen aus den unverarbeiteten Daten in den ursprünglichen Rohdaten. Datenvorbereitungsaufgaben können ohne vorgeschriebene Reihenfolge mehrmals durchgeführt werden. Der Hauptzweck dieser Aufgaben besteht darin, die erforderlichen Informationen aus dem Quellsystem gemäß den Anforderungen der Dimensionsanalyse zu erhalten, was eine Datenvorverarbeitung wie Datenkonvertierung, Bereinigung, Konstruktion und Integration erfordert 🎜>Modellieren
In dieser Phase geht es vor allem um die Auswahl und Anwendung verschiedener Modellierungstechniken. Gleichzeitig werden ihre Parameter so abgestimmt, dass optimale Werte erreicht werden. Normalerweise gibt es mehrere Modellierungstechniken für denselben Data-Mining-Problemtyp. Einige Technologien stellen besondere Anforderungen an die Datenform und müssen häufig zur Datenvorbereitungsphase zurückkehren. -
Modellbewertung (Bewertung)
Vor der Modellbereitstellung und -freigabe Es ist notwendig, auf technischer Ebene zu beginnen. Wir beurteilen die Wirkung des Modells, untersuchen jeden Schritt der Modellerstellung und bewerten die Praktikabilität des Modells in tatsächlichen Geschäftsszenarien basierend auf den Geschäftszielen. Der Hauptzweck dieser Phase besteht darin, festzustellen, ob einige wichtige Geschäftsprobleme nicht vollständig berücksichtigt wurden. -
Modellbereitstellung (Bereitstellung)
Nach dem Modell Wenn es abgeschlossen ist, wird es vom Modellbenutzer (Kunden) verwendet. Basierend auf dem aktuellen Hintergrund und dem Abschlussstatus des Ziels erfüllt das Paket die Nutzungsanforderungen des Geschäftssystems.
Data-Mining-Aufgaben
Im Allgemeinen werden Data-Mining-Aufgaben in die folgenden zwei Kategorien unterteilt.
Vorhersageaufgabe. Das Ziel dieser Aufgaben besteht darin, den Wert eines bestimmten Attributs basierend auf dem Wert anderer Attribute vorherzusagen. Die vorherzusagenden Attribute werden im Allgemeinen als Zielvariablen oder abhängige Variablen bezeichnet, und die zur Vorhersage verwendeten Attribute werden als erklärende Variablen oder unabhängige Variablen bezeichnet.
-
Beschreiben Sie die Aufgabe . Ziel ist es, Muster (Korrelationen, Trends, Cluster, Trajektorien und Anomalien) abzuleiten, die die zugrunde liegenden Zusammenhänge in den Daten zusammenfassen. Deskriptive Data-Mining-Aufgaben sind häufig explorativer Natur und erfordern häufig Nachbearbeitungstechniken zur Überprüfung und Interpretation der Ergebnisse.

Prädiktive Modellierung (prädiktive Modellierung) Beinhaltet den Aufbau eines Modells für eine Zielvariable auf eine Weise, die die beschreibt Funktion der Variablen.
Es gibt zwei Arten von Vorhersagemodellierungsaufgaben: Klassifizierung zur Vorhersage diskreter Zielvariablen und Regression zur Vorhersage kontinuierlicher Zielvariablen.
Zum Beispiel ist die Vorhersage, ob ein Webbenutzer ein Buch in einem Online-Buchladen kaufen wird, eine Klassifizierungsaufgabe, da die Zielvariable binär ist, während die Vorhersage des zukünftigen Aktienkurses eine Regressionsaufgabe ist, da der Preis kontinuierlich ist -wertige Attribute.
Ziel beider Aufgaben ist es, ein Modell zu trainieren, um den Fehler zwischen dem vorhergesagten Wert und dem tatsächlichen Wert der Zielvariablen zu minimieren. Mithilfe prädiktiver Modelle können Kundenreaktionen auf Produktwerbung ermittelt, Störungen in den Ökosystemen der Erde vorhergesagt oder anhand von Testergebnissen festgestellt werden, ob ein Patient an einer Krankheit leidet.
Assoziationsanalyse wird verwendet, um Muster zu entdecken, die stark korrelierte Merkmale in Daten beschreiben.
Entdeckte Muster werden normalerweise in Form von Implikationsregeln oder Teilmengen von Merkmalen ausgedrückt. Da der Suchraum eine exponentielle Größe hat, besteht das Ziel der Korrelationsanalyse darin, die interessantesten Muster auf effiziente Weise zu extrahieren. Zu den Anwendungen der Assoziationsanalyse gehören das Auffinden von Genomen mit verwandten Funktionen, das Identifizieren von Webseiten, die Benutzer gemeinsam besuchen, und das Verstehen der Zusammenhänge zwischen verschiedenen Elementen des Klimasystems der Erde.
Clusteranalyse zielt darauf ab, eng verwandte Gruppen von Beobachtungen zu finden, sodass sich Beobachtungen, die zu demselben Cluster gehören, stärker voneinander unterscheiden als Beobachtungen, die zu verschiedenen Clustern gehören und möglichst ähnlich sind. Clustering kann verwendet werden, um verwandte Kunden zu gruppieren, Bereiche des Ozeans zu identifizieren, die das Klima der Erde erheblich beeinflussen, Daten zu komprimieren und vieles mehr.
Anomalieerkennung Die Aufgabe von besteht darin, Beobachtungen zu identifizieren, deren Merkmale sich deutlich von anderen Daten unterscheiden.
Solche Beobachtungen nennt man Anomalien oder Ausreißer. Das Ziel von Anomalieerkennungsalgorithmen besteht darin, echte Anomalien zu entdecken und zu vermeiden, dass normale Objekte fälschlicherweise als Anomalien gekennzeichnet werden. Mit anderen Worten: Ein guter Anomaliedetektor muss eine hohe Erkennungsrate und eine niedrige Fehlalarmrate aufweisen.
Zu den Anwendungen der Anomalieerkennung gehört die Erkennung von Betrug, Cyberangriffen, ungewöhnlichen Krankheitsmustern, Ökosystemstörungen und mehr.
Weitere Informationen zu diesem Thema finden Sie unter: PHP-Website für Chinesisch!
Das obige ist der detaillierte Inhalt vonWas ist Data Mining?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Wie verwende ich die Go-Sprache für Data Mining?
Jun 10, 2023 am 08:39 AM
Wie verwende ich die Go-Sprache für Data Mining?
Jun 10, 2023 am 08:39 AM
Mit dem Aufkommen von Big Data und Data Mining unterstützen immer mehr Programmiersprachen Data Mining-Funktionen. Als schnelle, sichere und effiziente Programmiersprache kann die Go-Sprache auch für das Data Mining verwendet werden. Wie nutzt man also die Go-Sprache für das Data Mining? Hier sind einige wichtige Schritte und Techniken. Datenerfassung Zunächst müssen Sie die Daten beschaffen. Dies kann auf verschiedene Weise erreicht werden, z. B. durch das Crawlen von Informationen auf Webseiten, die Verwendung von APIs zum Abrufen von Daten, das Lesen von Daten aus Datenbanken usw. Die Go-Sprache verfügt über umfangreiches HTTP
 Datenanalyse mit MySql: Umgang mit Data Mining und Statistiken
Jun 16, 2023 am 11:43 AM
Datenanalyse mit MySql: Umgang mit Data Mining und Statistiken
Jun 16, 2023 am 11:43 AM
MySql ist ein beliebtes relationales Datenbankverwaltungssystem, das häufig zur Speicherung und Verwaltung von Unternehmens- und Privatdaten verwendet wird. Neben der Speicherung und Abfrage von Daten bietet MySql auch Funktionen wie Datenanalyse, Data Mining und Statistiken, die Benutzern helfen können, Daten besser zu verstehen und zu nutzen. Daten sind in jedem Unternehmen oder jeder Organisation ein wertvolles Gut, und die Datenanalyse kann Unternehmen dabei helfen, richtige Geschäftsentscheidungen zu treffen. MySql kann Datenanalyse und Data Mining auf viele Arten durchführen. Hier sind einige praktische Techniken und Tools: Verwendung
 Was ist der Unterschied zwischen Data Mining und Datenanalyse?
Dec 07, 2020 pm 03:16 PM
Was ist der Unterschied zwischen Data Mining und Datenanalyse?
Dec 07, 2020 pm 03:16 PM
Unterschiede: 1. Die durch „Datenanalyse“ gezogenen Schlussfolgerungen sind das Ergebnis menschlicher intellektueller Aktivitäten, während die durch „Data Mining“ gezogenen Schlussfolgerungen die von der Maschine aus dem Lernsatz [oder Trainingssatz, Beispielsatz] ermittelten Wissensregeln sind; 2. „Datenanalyse“ kann keine mathematischen Modelle erstellen und erfordert eine manuelle Modellierung, während „Data Mining“ die mathematische Modellierung direkt vervollständigt.
 Tipps zur Zeitreihenvorhersage in Python
Jun 10, 2023 am 08:10 AM
Tipps zur Zeitreihenvorhersage in Python
Jun 10, 2023 am 08:10 AM
Mit Beginn des Datenzeitalters werden immer mehr Daten gesammelt und für Analysen und Vorhersagen verwendet. Zeitreihendaten sind ein allgemeiner Datentyp, der eine Reihe zeitbasierter Daten enthält. Die zur Vorhersage dieser Art von Daten verwendeten Methoden werden als Zeitreihenvorhersagetechniken bezeichnet. Python ist eine sehr beliebte Programmiersprache mit starker Unterstützung für Datenwissenschaft und maschinelles Lernen und daher auch ein sehr geeignetes Werkzeug für Zeitreihenprognosen. In diesem Artikel werden einige häufig verwendete Techniken zur Zeitreihenvorhersage in Python vorgestellt und einige praktische Anwendungen bereitgestellt
 Teilen der Technologie des Volcano-Engine-Tools: Verwenden Sie KI, um das Data Mining und das SQL-Schreiben ohne Schwellenwert von Null abzuschließen
May 18, 2023 pm 08:19 PM
Teilen der Technologie des Volcano-Engine-Tools: Verwenden Sie KI, um das Data Mining und das SQL-Schreiben ohne Schwellenwert von Null abzuschließen
May 18, 2023 pm 08:19 PM
Bei der Verwendung von BI-Tools werden häufig Fragen gestellt: „Wie können wir Daten ohne SQL erzeugen und verarbeiten? Können wir Mining-Analysen ohne Algorithmen durchführen?“ Wenn ein professionelles Algorithmenteam Data Mining durchführt, werden auch Datenanalyse und Visualisierung vorgestellt fragmentiertes Phänomen. Eine optimierte Durchführung der Algorithmenmodellierungs- und Datenanalysearbeiten ist ebenfalls eine gute Möglichkeit, die Effizienz zu verbessern. Gleichzeitig steht für professionelle Data-Warehouse-Teams der Dateninhalt zum gleichen Thema vor dem Problem der „wiederholten Erstellung, relativ verstreuten Nutzung und Verwaltung“ – gibt es eine Möglichkeit, Datensätze mit demselben Thema und unterschiedlichen Inhalten gleichzeitig zu erstellen? Zeit in einer Aufgabe? Kann der erstellte Datensatz als Eingabe für die erneute Teilnahme an der Datenkonstruktion verwendet werden? 1. Die visuelle Modellierungsfunktion von DataWind ist in der von Volcano Engine eingeführten BI-Plattform Da enthalten
 Die Anwendungspraxis von Redis in der künstlichen Intelligenz und im Data Mining
Jun 20, 2023 pm 07:10 PM
Die Anwendungspraxis von Redis in der künstlichen Intelligenz und im Data Mining
Jun 20, 2023 pm 07:10 PM
Mit dem Aufkommen künstlicher Intelligenz und Big-Data-Technologie achten immer mehr Unternehmen und Betriebe darauf, wie Daten effizient gespeichert und verarbeitet werden können. Als leistungsstarke verteilte Speicherdatenbank hat Redis in den Bereichen künstliche Intelligenz und Data Mining immer mehr Aufmerksamkeit auf sich gezogen. Dieser Artikel gibt eine kurze Einführung in die Eigenschaften von Redis und seine Praxis in Anwendungen für künstliche Intelligenz und Data Mining. Redis ist eine leistungsstarke, skalierbare Open-Source-NoSQL-Datenbank. Es unterstützt eine Vielzahl von Datenstrukturen und bietet Caching, Nachrichtenwarteschlangen, Zähler usw.
 Wie führt man in PHP eine automatische Textklassifizierung und Data Mining durch?
May 22, 2023 pm 02:31 PM
Wie führt man in PHP eine automatische Textklassifizierung und Data Mining durch?
May 22, 2023 pm 02:31 PM
PHP ist eine hervorragende serverseitige Skriptsprache, die in Bereichen wie Website-Entwicklung und Datenverarbeitung weit verbreitet ist. Mit der rasanten Entwicklung des Internets und der zunehmenden Datenmenge ist die effiziente Durchführung automatischer Textklassifizierung und Data Mining zu einem wichtigen Thema geworden. In diesem Artikel werden Methoden und Techniken zur automatischen Textklassifizierung und zum Data Mining in PHP vorgestellt. 1. Was ist automatische Textklassifizierung und Data Mining? Unter automatischer Textklassifizierung versteht man den Prozess der automatischen Klassifizierung von Text nach seinem Inhalt, der normalerweise mithilfe von Algorithmen für maschinelles Lernen implementiert wird. Data Mining bezieht sich auf
 Detaillierte Erklärung des Apriori-Algorithmus in Python
Jun 10, 2023 am 08:03 AM
Detaillierte Erklärung des Apriori-Algorithmus in Python
Jun 10, 2023 am 08:03 AM
Der Apriori-Algorithmus ist eine gängige Methode für das Assoziationsregel-Mining im Bereich Data Mining und wird häufig in Business Intelligence, Marketing und anderen Bereichen eingesetzt. Als allgemeine Programmiersprache bietet Python auch mehrere Bibliotheken von Drittanbietern zur Implementierung des Apriori-Algorithmus. In diesem Artikel werden das Prinzip, die Implementierung und die Anwendung des Apriori-Algorithmus in Python ausführlich vorgestellt. 1. Prinzip des Apriori-Algorithmus Bevor wir das Prinzip des Apriori-Algorithmus vorstellen, lernen wir zunächst die nächsten beiden Konzepte beim Assoziationsregel-Mining kennen: häufige Itemsets und Unterstützung.