
 Web-Frontend
Front-End-Fragen und Antworten
Das ausführlichste Teilen von Android-Interviewfragen
Web-Frontend
Front-End-Fragen und Antworten
Das ausführlichste Teilen von Android-Interviewfragen
Das ausführlichste Teilen von Android-Interviewfragen

Empfohlen: „Zusammenfassung der Android-Interviewfragen 2020 [Sammlung] “
Grundlegende Android-Wissenspunkte
1. Allgemeine Wissenspunkte
1. In der Android-Entwicklung, ob es sich um ein Plug-in handelt Unabhängig davon, ob es sich um Komponentisierung oder Komponentisierung handelt, basieren sie alle auf dem ClassLoader des Android-Systems. Es ist nur so, dass die virtuelle Maschine auf der Android-Plattform Dex-Bytecode ausführt, ein Produkt der Klassendateioptimierung. Eine herkömmliche Klassendatei ist eine Java-Quellcodedatei, die eine .class-Datei generiert, während Android alle Klassendateien zusammenführt und optimiert Generieren Sie eine endgültige class.dex. Der Zweck besteht darin, nur eine Kopie der doppelten Dinge in verschiedenen Klassendateien zu behalten. Wenn die Android-Anwendung in der frühen Android-Anwendung nicht in dex unterteilt war, wäre dies nur die APK der letzten Anwendung Es wird eine Dex-Datei geben.
Es gibt zwei häufig verwendete Klassenlader in Android, DexClassLoader und PathClassLoader, die beide von BaseDexClassLoader erben. Der Unterschied besteht darin, dass DexClassLoader beim Aufruf des übergeordneten Klassenkonstruktors einen zusätzlichen Parameter „OptimizedDirectory“ übergibt. Dieses Verzeichnis muss ein interner Speicherpfad sein und wird zum Zwischenspeichern von vom System erstellten Dex-Dateien verwendet. Der Parameter von PathClassLoader ist null und kann nur Dex-Dateien im internen Speicherverzeichnis laden. So können wir DexClassLoader zum Laden externer APK-Dateien verwenden, was auch die Grundlage vieler Plug-in-Technologien ist.
 2. Service
2. Service
Das Verständnis des Android-Dienstes kann unter folgenden Aspekten verstanden werden:
Der Dienst steht im Mittelpunkt der Thread-Ausführung, der Zeit -Aufwändige Vorgänge (Netzwerkanfragen, Kopieren von Datenbanken, große Dateien) können im Service nicht ausgeführt werden.- Sie können den Prozess, in dem sich der Dienst befindet, in XML festlegen, sodass der Dienst in einem anderen Prozess ausgeführt werden kann.
- Der vom Dienst ausgeführte Vorgang dauert bis zu 20 Sekunden, BroadcastReceiver beträgt 10 Sekunden und Aktivität beträgt 5 Sekunden.
- Aktivität ist über bindService (Intent, ServiceConnection, Flag) an den Service gebunden.
- Aktivität kann den Dienst über startService und bindService starten.
- IntentService
IntentService ist eine abstrakte Klasse, geerbt von Service, mit einem ServiceHandler (Handler) und einem HandlerThread (Thread) intern. IntentService ist eine Klasse, die asynchrone Anforderungen verarbeitet. In IntentService gibt es einen Arbeitsthread (HandlerThread), um zeitaufwändige Vorgänge abzuwickeln. Die Methode zum Starten von IntentService ist dieselbe wie normal, aber wenn die Aufgabe abgeschlossen ist, wird IntentService automatisch gestoppt. Darüber hinaus kann IntentService mehrmals gestartet werden. Jeder zeitaufwändige Vorgang wird im onHandleIntent-Rückruf von IntentService in Form einer Arbeitswarteschlange ausgeführt, und jedes Mal wird ein Arbeitsthread ausgeführt. Die Essenz von IntentService ist: ein asynchrones Framework, das einen HandlerThread und einen Handler kapselt.
2.1. Lebenszyklusdiagramm
Der Dienst ist eine der vier Hauptkomponenten von Android und wird häufig verwendet. Wie die Aktivität verfügt auch der Dienst über eine Reihe von Rückruffunktionen für den Lebenszyklus, wie in der folgenden Abbildung dargestellt.
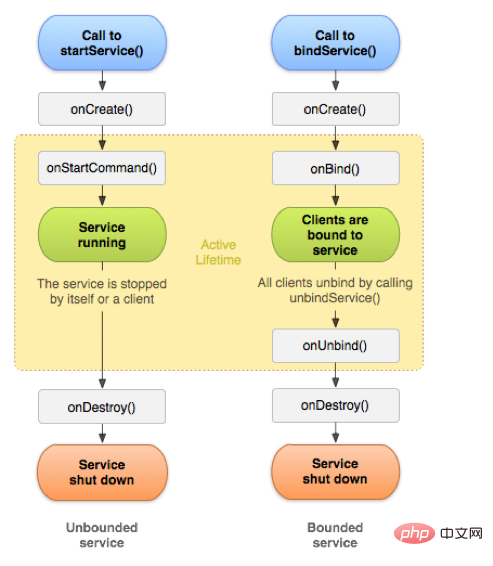 Normalerweise gibt es zwei Möglichkeiten, den Dienst zu starten: startService und bindService.
Normalerweise gibt es zwei Möglichkeiten, den Dienst zu starten: startService und bindService.
2.2. startService-Lebenszyklus
Wenn wir die startService-Methode von Context aufrufen, wird der von der startService-Methode gestartete Dienst auf unbestimmte Zeit ausgeführt werden nur zerstört, wenn der stopService von Context extern oder die stopSelf-Methode von Service intern aufgerufen wird.
onCreate
onCreate: Wenn der Dienst nicht ausgeführt wird, wird der Dienst erstellt, und wenn der Dienst bereits ausgeführt wird, wird die Rückrufmethode onCreate ausgeführt ausgeführt wird, wird die startService-Methode nicht ausgeführt. Die onCreate-Methode von Service wird ausgeführt. Das heißt, wenn die startService-Methode von Context mehrmals ausgeführt wird, um den Dienst zu starten, wird die onCreate-Methode der Service-Methode nur einmal aufgerufen, wenn der Dienst zum ersten Mal erstellt wird, und nicht erneut aufgerufen Zukunft. Wir können einige Vorgänge im Zusammenhang mit der Dienstinitialisierung in der onCreate-Methode abschließen.
onStartCommand
onStartCommand: Nach der Ausführung der startService-Methode kann die onCreate-Methode des Dienstes aufgerufen werden, woraufhin die onStartCommand-Rückrufmethode des Dienstes definitiv ausgeführt wird. Mit anderen Worten: Wenn die startService-Methode von Context mehrmals ausgeführt wird, wird die onStartCommand-Methode von Service entsprechend auch mehrmals aufgerufen. Die onStartCommand-Methode ist sehr wichtig. Bei dieser Methode führen wir tatsächliche Vorgänge basierend auf den eingehenden Intent-Parametern aus. Beispielsweise wird hier ein Thread erstellt, um Daten herunterzuladen oder Musik abzuspielen.
public @StartResult int onStartCommand(Intent intent, @StartArgFlags int flags, int startId) {
}Wenn bei Android ein Speichermangel auftritt, kann es sein, dass der aktuell ausgeführte Dienst zerstört wird und der Dienst dann neu erstellt wird, wenn der Speicher ausreicht. Das Verhalten des Dienstes, der vom Android-System zwangsweise zerstört und neu erstellt wird, hängt davon ab auf der onStartCommand-Methode im Rückgabewert. Es gibt drei Arten von Rückgabewerten, die wir üblicherweise verwenden: START_NOT_STICKY, START_STICKY und START_REDELIVER_INTENT. Diese drei Werte sind alle statische Konstanten im Service.
START_NOT_STICKY
Wenn START_NOT_STICKY zurückgegeben wird, bedeutet dies, dass der Dienst natürlich nicht neu erstellt wird, wenn der Prozess, der den Dienst ausführt, vom Android-System gewaltsam beendet wird Es wird für einen bestimmten Zeitraum beendet. Wenn startService erneut aufgerufen wird, wird der Dienst erneut instanziiert. Unter welchen Umständen ist es also angemessen, diesen Wert zurückzugeben? Wenn es keine Rolle spielt, wie oft die von einem unserer Dienste ausgeführte Arbeit unterbrochen wird oder dieser beendet und nicht sofort neu erstellt werden muss, wenn der Android-Speicher knapp ist, ist dieses Verhalten akzeptabel, dann können wir den Rückgabewert festlegen onStartCommand auf START_NOT_STICKY. Beispielsweise muss ein Dienst regelmäßig die neuesten Daten vom Server abrufen: Verwenden Sie einen Timer, um den Dienst alle angegebenen N Minuten zu starten und die neuesten Daten vom Server abzurufen. Wenn der onStartCommand des Dienstes ausgeführt wird, ist in dieser Methode ein Timer für N Minuten geplant, um den Dienst erneut zu starten und einen neuen Thread zur Durchführung von Netzwerkvorgängen zu öffnen. Unter der Annahme, dass der Dienst vom Android-System beim Abrufen der neuesten Daten vom Server zwangsweise beendet wird, wird der Dienst nicht neu erstellt. Dies spielt keine Rolle, da der Timer den Dienst erneut startet und die Daten erneut abruft Daten nach N Minuten.
START_STICKY
Wenn START_STICKY zurückgegeben wird, bedeutet dies, dass das Android-System den Dienst weiterhin in den gestarteten Zustand versetzt, nachdem der Prozess, der den Dienst ausführt, vom Android-System gewaltsam beendet wurde ( d. h. Ausführungsstatus), aber das von der onStartCommand-Methode übergebene Absichtsobjekt wird nicht mehr gespeichert, und dann versucht das Android-System, den Dienst erneut zu erstellen und die onStartCommand-Rückrufmethode auszuführen, aber der Intent-Parameter der onStartCommand-Rückrufmethode ist null Das heißt, obwohl die onStartCommand-Methode ausgeführt wird, können keine Informationen zur Absicht abgerufen werden. Wenn Ihr Dienst jederzeit problemlos ausgeführt oder beendet werden kann und keine Absichtsinformationen benötigt, können Sie START_STICKY in der onStartCommand-Methode zurückgeben. Beispielsweise eignet sich ein Dienst, der zum Abspielen von Hintergrundmusik verwendet wird, für die Rückgabe dieses Werts.
START_REDELIVER_INTENT
Wenn START_REDELIVER_INTENT zurückgegeben wird, bedeutet dies, dass das Android-System neu erstellt wird, nachdem der Prozess, der den Dienst ausführt, vom Android-System gewaltsam beendet wird, ähnlich wie bei der Rückgabe von START_STICKY Rufen Sie den Dienst erneut auf und führen Sie die Rückrufmethode onStartCommand aus. Der Unterschied besteht jedoch darin, dass das Android-System die Absicht behält, die zuletzt an die Methode onStartCommand übergeben wurde, bevor der Dienst beendet wurde, und sie erneut an die Methode onStartCommand des neu erstellten Dienstes übergibt wir Sie können die Absichtsparameter lesen. Solange START_REDELIVER_INTENT zurückgegeben wird, darf die Absicht in onStartCommand nicht null sein. Wenn unser Dienst für die Ausführung auf eine bestimmte Absicht angewiesen ist (relevante Dateninformationen aus der Absicht lesen muss usw.) und es nach der erzwungenen Zerstörung neu erstellt werden muss, ist ein solcher Dienst für die Rückgabe von START_REDELIVER_INTENT geeignet.
onBind
Die onBind-Methode in Service ist eine abstrakte Methode, daher ist die Service-Klasse selbst eine abstrakte Klasse, das heißt, die onBind-Methode muss neu geschrieben werden, auch wenn wir sie nicht verwenden Es. Wenn wir Service über startService verwenden, müssen wir beim Überschreiben der onBind-Methode nur null zurückgeben. Die onBind-Methode wird hauptsächlich beim Aufrufen von Service für die bindService-Methode verwendet.
onDestroy
onDestroy: Der über die startService-Methode gestartete Dienst wird auf unbestimmte Zeit ausgeführt. Nur wenn der StopService des Kontexts oder die stopSelf-Methode innerhalb des Dienstes aufgerufen wird, wird die Ausführung des Dienstes gestoppt und zerstört werden. Die Service-Callback-Funktion wird ausgeführt, wenn sie zerstört wird.
2.3. bindService-Lebenszyklus
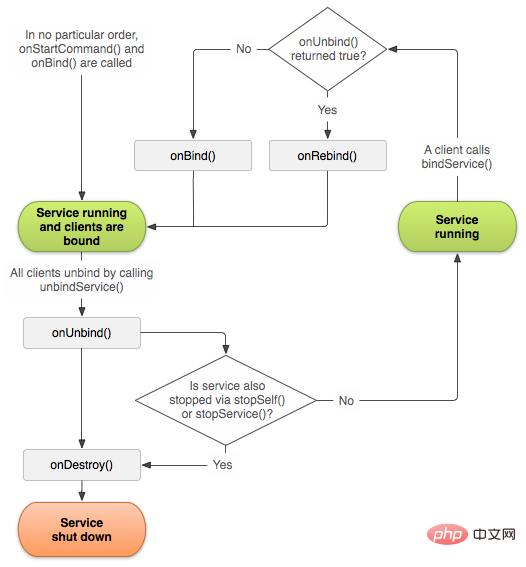
Das Starten des Dienstes über bindService hat hauptsächlich die folgenden Lebenszyklusfunktionen:
onCreate():
Das System ruft diese Methode auf, wenn der Dienst zum ersten Mal erstellt wird. Wenn der Dienst bereits ausgeführt wird, wird diese Methode nicht aufgerufen und nur einmal aufgerufen.
onStartCommand():
Diese Methode wird vom System aufgerufen, wenn eine andere Komponente den Start des Dienstes durch Aufruf von startService() anfordert.
onDestroy():
Das System ruft diese Methode auf, wenn der Dienst nicht mehr verwendet wird und zerstört wird.
onBind():
Das System ruft diese Methode auf, wenn eine andere Komponente durch Aufruf von bindService() eine Bindung an den Dienst herstellt.
onUnbind():
Das System ruft diese Methode auf, wenn eine andere Komponente durch Aufruf von unbindService() die Bindung zum Dienst aufhebt.
onRebind():
Wenn die alte Komponente vom Dienst getrennt wird, eine andere neue Komponente an den Dienst gebunden wird und onUnbind() true zurückgibt, ruft das System diese Methode auf.
3、fragemnt
3.1、创建方式
(1)静态创建
首先我们需要创建一个xml文件,然后创建与之对应的java文件,通过onCreatView()的返回方法进行关联,最后我们需要在Activity中进行配置相关参数即在Activity的xml文件中放上fragment的位置。
<fragment
android:name="xxx.BlankFragment"
android:layout_width="match_parent"
android:layout_height="match_parent">
</fragment>(2)动态创建
动态创建Fragment主要有以下几个步骤:
- 创建待添加的fragment实例。
- 获取FragmentManager,在Activity中可以直接通过调用 getSupportFragmentManager()方法得到。
- 开启一个事务,通过调用beginTransaction()方法开启。
- 向容器内添加或替换fragment,一般使用repalce()方法实现,需要传入容器的id和待添加的fragment实例。
- 提交事务,调用commit()方法来完成。
3.2、Adapter对比
FragmnetPageAdapter在每次切换页面时,只是将Fragment进行分离,适合页面较少的Fragment使用以保存一些内存,对系统内存不会多大影响。
FragmentPageStateAdapter在每次切换页面的时候,是将Fragment进行回收,适合页面较多的Fragment使用,这样就不会消耗更多的内存
3.3、Activity生命周期
Activity的生命周期如下图:
(1)动态加载:
动态加载时,Activity的onCreate()调用完,才开始加载fragment并调用其生命周期方法,所以在第一个生命周期方法onAttach()中便能获取Activity以及Activity的布局的组件;
(2)静态加载:
1.静态加载时,Activity的onCreate()调用过程中,fragment也在加载,所以fragment无法获取到Activity的布局中的组件,但为什么能获取到Activity呢?
2.原来在fragment调用onAttach()之前其实还调用了一个方法onInflate(),该方法被调用时fragment已经是和Activity相互结合了,所以可以获取到对方,但是Activity的onCreate()调用还未完成,故无法获取Activity的组件;
3.Activity的onCreate()调用完成是,fragment会调用onActivityCreated()生命周期方法,因此在这儿开始便能获取到Activity的布局的组件;
3.4、与Activity通信
fragment不通过构造函数进行传值的原因是因为横屏切换的时候获取不到值。
Activity向Fragment传值:
Activity向Fragment传值,要传的值放到bundle对象里;
在Activity中创建该Fragment的对象fragment,通过调用setArguments()传递到fragment中;
在该Fragment中通过调用getArguments()得到bundle对象,就能得到里面的值。
Fragment向Activity传值:
第一种:
在Activity中调用getFragmentManager()得到fragmentManager,,调用findFragmentByTag(tag)或者通过findFragmentById(id),例如:
FragmentManager fragmentManager = getFragmentManager(); Fragment fragment = fragmentManager.findFragmentByTag(tag);
第二种:
通过回调的方式,定义一个接口(可以在Fragment类中定义),接口中有一个空的方法,在fragment中需要的时候调用接口的方法,值可以作为参数放在这个方法中,然后让Activity实现这个接口,必然会重写这个方法,这样值就传到了Activity中
Fragment与Fragment之间是如何传值的:
第一种:
通过findFragmentByTag得到另一个的Fragment的对象,这样就可以调用另一个的方法了。
第二种:
通过接口回调的方式。
第三种:
通过setArguments,getArguments的方式。
3.5、api区别
add
一种是add方式来进行show和add,这种方式你切换fragment不会让fragment重新刷新,只会调用onHiddenChanged(boolean isHidden)。
replace
而用replace方式会使fragment重新刷新,因为add方式是将fragment隐藏了而不是销毁再创建,replace方式每次都是重新创建。
commit/commitAllowingStateLoss
两者都可以提交fragment的操作,唯一的不同是第二种方法,允许丢失一些界面的状态和信息,几乎所有的开发者都遇到过这样的错误:无法在activity调用了onSaveInstanceState之后再执行commit(),这种异常时可以理解的,界面被系统回收(界面已经不存在),为了在下次打开的时候恢复原来的样子,系统为我们保存界面的所有状态,这个时候我们再去修改界面理论上肯定是不允许的,所以为了避免这种异常,要使用第二种方法。
3. Lazy Loading
Wenn wir Fragmente häufig verwenden, wird es häufig in Verbindung mit Viewpager verwendet. Dann tritt ein Problem auf, das heißt, dass das Fragment beim Initialisieren in das Netzwerk aufgenommen wird Die von uns geschriebene Anfrage ist sehr leistungsintensiv. Der ideale Weg besteht darin, das Netzwerk nur dann anzufordern, wenn der Benutzer auf das aktuelle Fragment klickt oder dorthin wechselt. Deshalb haben wir den Begriff Lazy Loading erfunden.
Viewpager wird mit Fragmenten verwendet und die ersten beiden Fragmente werden standardmäßig geladen. Es kann leicht zu Problemen wie Netzwerkpaketverlust und Überlastung kommen.
Es gibt eine setUserVisibleHint-Methode in Fragment, und diese Methode ist besser als die onCreate()-Methode. Sie teilt uns mit, ob das aktuelle Fragment über isVisibleToUser sichtbar ist.
Aus dem Protokoll geht hervor, dass setUserVisibleHint() früher als onCreateView aufgerufen wird. Wenn Sie also Lazy Loading in setUserVisibleHint() implementieren möchten, müssen Sie sicherstellen, dass die View und andere Variablen initialisiert wurden, um dies zu vermeiden Nullzeiger.
Verwendungsschritte:
Deklarieren Sie eine Variable isPrepare=false, isVisible=false, die angibt, ob die aktuelle Seite erstellt wurde
Setzen Sie isPrepare=true während des onViewCreated-Zyklus
In setUserVisibleHint (boolean isVisible) Um zu bestimmen, ob angezeigt werden soll, setzen Sie isVisible=true
, um isPrepare und isVisible zu bestimmen. Beide sind true, um mit dem Laden der Daten zu beginnen, und stellen dann isPrepare und isVisible auf false wieder her, um wiederholtes Laden zu verhindern.
Informationen zum verzögerten Laden von Android-Fragmenten finden Sie unter folgendem Link: Verzögertes Laden von Fragmenten
4, Aktivität
4.1, Aktivitätsstartvorgang
Benutzer Klicken Sie im Launcher-Programm auf das Anwendungssymbol, um die Eintragsaktivität der Anwendung zu starten. Wenn die Aktivität gestartet wird, ist eine Interaktion zwischen mehreren Prozessen im Android-System erforderlich, die der Inkubation der Prozesse der Android-Framework-Ebene und -Anwendung gewidmet ist Layer-Programme. Es gibt auch einen system_server-Prozess, der viele Binder-Dienste ausführt. Beispielsweise werden ActivityManagerService, PackageManagerService und WindowManagerService ausgeführt. Diese Bindemitteldienste werden jeweils in unterschiedlichen Threads ausgeführt, wobei ActivityManagerService für die Verwaltung des Aktivitätsstapels, des Anwendungsprozesses und der Aufgabe verantwortlich ist.
Klicken Sie auf das Launcher-Symbol, um die Aktivität zu starten
Wenn der Benutzer auf das Anwendungssymbol im Launcher-Programm klickt, wird der ActivityManagerService benachrichtigt, die Eintragsaktivität der Anwendung zu starten, wenn der ActivityManagerService findet Wenn die Anwendung nicht gestartet wurde, benachrichtigt sie den Zygote-Prozess über den Hatch-Anwendungsprozess und führt dann die Hauptmethode von ActivityThread in diesem Dalvik-Anwendungsprozess aus. Der Anwendungsprozess benachrichtigt ActivityManagerService als Nächstes, dass der Anwendungsprozess gestartet wurde. ActivityManagerService speichert ein Proxy-Objekt des Anwendungsprozesses, sodass ActivityManagerService den Anwendungsprozess über dieses Proxy-Objekt steuern kann. Anschließend benachrichtigt ActivityManagerService den Anwendungsprozess, um eine Instanz der Eintragsaktivität zu erstellen und führen Sie seine Lebenszyklusmethode aus.
Android-Zeichenprozessfenster-Startprozessanalyse
4.2, Aktivitätslebenszyklus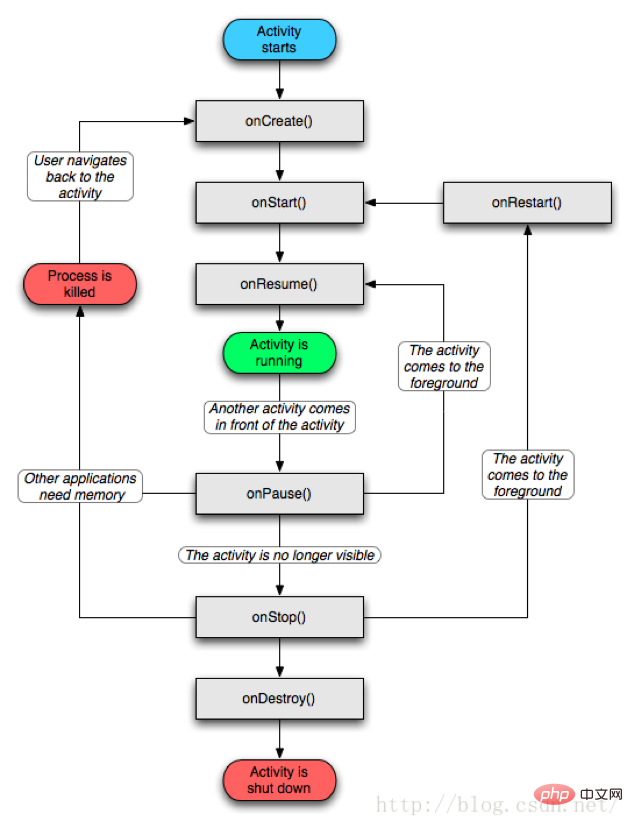
(1) Aktivitätsformular
Aktiv/Laufend :
Aktivität befindet sich im aktiven Zustand. Zu diesem Zeitpunkt befindet sich die Aktivität oben im Stapel, ist sichtbar und kann mit dem Benutzer interagieren.
Pausiert:
Wenn die Aktivität den Fokus verliert oder durch eine neue Nicht-Vollbildaktivität oder durch eine transparente Aktivität oben auf dem Stapel platziert wird, wird die Aktivität in umgewandelt der Pausenzustand. Wir müssen jedoch verstehen, dass die Aktivität zu diesem Zeitpunkt nur die Fähigkeit zur Interaktion mit dem Benutzer verloren hat und alle ihre Statusinformationen und Mitgliedsvariablen noch vorhanden sind. Nur wenn der Systemspeicher knapp ist, kann sie vom System recycelt werden.
Gestoppt:
Wenn eine Aktivität vollständig von einer anderen Aktivität abgedeckt wird, wechselt die abgedeckte Aktivität in den Status „Gestoppt“. Zu diesem Zeitpunkt ist sie nicht mehr sichtbar, behält aber ihren Status als „Pausiert“. Zustand. Alle Statusinformationen und ihre Mitgliedsvariablen.
Getötet:
Wenn die Aktivität vom System recycelt wird, befindet sich die Aktivität im Status „Getötet“.
Die Aktivität wechselt zwischen den oben genannten vier Formen. Die Art und Weise des Wechsels hängt von der Bedienung des Benutzers ab. Nachdem wir die vier Formen der Aktivität verstanden haben, sprechen wir über den Lebenszyklus der Aktivität.
Aktivitätslebenszyklus
Der sogenannte typische Lebenszyklus besteht darin, dass die Aktivität unter Beteiligung des Benutzers den normalen Lebenszyklusprozess von der Erstellung über die Ausführung, das Anhalten, die Zerstörung usw. durchläuft.
onCreate
Diese Methode wird beim Erstellen der Aktivität als erste aufgerufen. Im Allgemeinen müssen wir diese Methode beim Erstellen der Aktivität überschreiben Führen Sie einige Initialisierungsvorgänge in der Methode durch, z. B. das Festlegen von Ressourcen für das Schnittstellenlayout über setContentView, das Initialisieren erforderlicher Komponenteninformationen usw.
onStart
Wenn diese Methode zurückgerufen wird, bedeutet dies, dass die Aktivität zu diesem Zeitpunkt bereits sichtbar ist, aber noch nicht im Vordergrund angezeigt wurde Es kann nicht mit dem Benutzer interagieren. Es kann einfach verstanden werden, dass die Aktivität angezeigt wurde und wir sie nicht sehen können.
onResume
Wenn diese Methode zurückgerufen wird, bedeutet dies, dass die Aktivität im Vordergrund sichtbar ist und mit dem Benutzer interagieren kann (im oben erwähnten Status „Aktiv/Ausgeführt“). Die onResume-Methode weist zwei Ähnlichkeiten auf Mit onStart hat jeder gesagt, dass die Aktivität sichtbar ist, aber wenn onStart zurückgerufen wird, befindet sich die Aktivität immer noch im Hintergrund und kann nicht mit dem Benutzer interagieren, während onResume bereits im Vordergrund angezeigt wird und mit dem Benutzer interagieren kann. Aus dem Flussdiagramm können wir natürlich auch ersehen, dass beim Stoppen der Aktivität (onPause-Methode und onStop-Methode aufgerufen) auch die onResume-Methode aufgerufen wird, wenn sie in den Vordergrund zurückkehrt, sodass wir auch einige Ressourcen in onResume initialisieren können Methode, wie z. B. Neuinitialisierung Ressourcen, die in der onPause- oder onStop-Methode freigegeben werden.
onPause
Wenn diese Methode zurückgerufen wird, bedeutet dies, dass die Aktivität gestoppt wird (angehaltener Zustand). Unter normalen Umständen wird die onStop-Methode sofort zurückgerufen. Anhand des Flussdiagramms können wir jedoch auch eine Situation erkennen, in der die onResume-Methode direkt nach der Ausführung der onPause-Methode ausgeführt wird. Dies ist ein relativ extremes Phänomen. Dies kann auf die Benutzeroperation zurückzuführen sein, die dazu geführt hat, dass die aktuelle Aktivität zurückgezogen wird Hintergrund und kehren Sie dann schnell zu dieser Aktivität zurück. Zu diesem Zeitpunkt wird die onResume-Methode aufgerufen. Natürlich können wir in der onPause-Methode einige Datenspeicherungs- oder Animationsstopp- oder Ressourcenrecycling-Vorgänge durchführen, dies sollte jedoch nicht zu zeitaufwändig sein, da dies Auswirkungen auf die Anzeige der neuen Aktivität haben kann – nachdem die onPause-Methode ausgeführt wurde onResume der neuen Aktivitätsmethode wird ausgeführt.
onStop
wird im Allgemeinen direkt nach Abschluss der onPause-Methode ausgeführt, was anzeigt, dass die Aktivität kurz vor dem Stoppen steht oder vollständig abgedeckt ist (Formular „Gestoppt“) läuft nur im Hintergrund. Ebenso können einige Ressourcenfreigabevorgänge in der onStop-Methode durchgeführt werden (nicht zu zeitaufwändig).
onRestart
zeigt an, dass die Aktivität neu gestartet wird. Wenn die Aktivität von unsichtbar zu sichtbar wechselt, wird diese Methode zurückgerufen. Diese Situation liegt im Allgemeinen vor, wenn der Benutzer eine neue Aktivität öffnet, die aktuelle Aktivität angehalten wird (onPause und onStop werden ausgeführt) und wenn der Benutzer dann zur aktuellen Aktivitätsseite zurückkehrt, wird die onRestart-Methode zurückgerufen.
onDestroy
Zu diesem Zeitpunkt wird die Aktivität zerstört. Dies ist auch die letzte Methode, die im Lebenszyklus ausgeführt wird. Im Allgemeinen können wir einige Recyclingarbeiten und die endgültige Ressourcenfreigabe durchführen diese Methode.
Zusammenfassung
Hier kommen wir zu einer Zusammenfassung: Wenn die Aktivität startet, werden onCreate(), onStart() und onResume() nacheinander aufgerufen, und wenn die Aktivität in den Hintergrund tritt (unsichtbar). , klicken Sie auf „Startseite“ oder werden Sie vollständig von einer neuen Aktivität abgedeckt), onPause() und onStop() werden nacheinander aufgerufen. Wenn die Aktivität in den Vordergrund zurückkehrt (vom Desktop zur ursprünglichen Aktivität zurückkehrt oder nach dem Überschreiben zur ursprünglichen Aktivität zurückkehrt), werden onRestart (), onStart () und onResume () nacheinander aufgerufen. Wenn die Aktivität beendet und zerstört wird (klicken Sie auf die Schaltfläche „Zurück“), werden nacheinander onPause(), onStop() und onDestroy() aufgerufen. Zu diesem Zeitpunkt ist der gesamte Rückruf der Lebenszyklusmethode der Aktivität abgeschlossen. Schauen wir uns nun das vorherige Flussdiagramm noch einmal an. Es sollte ziemlich klar sein. Nun, das ist der gesamte typische Lebenszyklusprozess einer Aktivität.
2. Wissenspunkte anzeigen
Die Beziehung zwischen Androids Aktivität, PhoneWindow und DecorView kann durch das folgende Diagramm dargestellt werden: 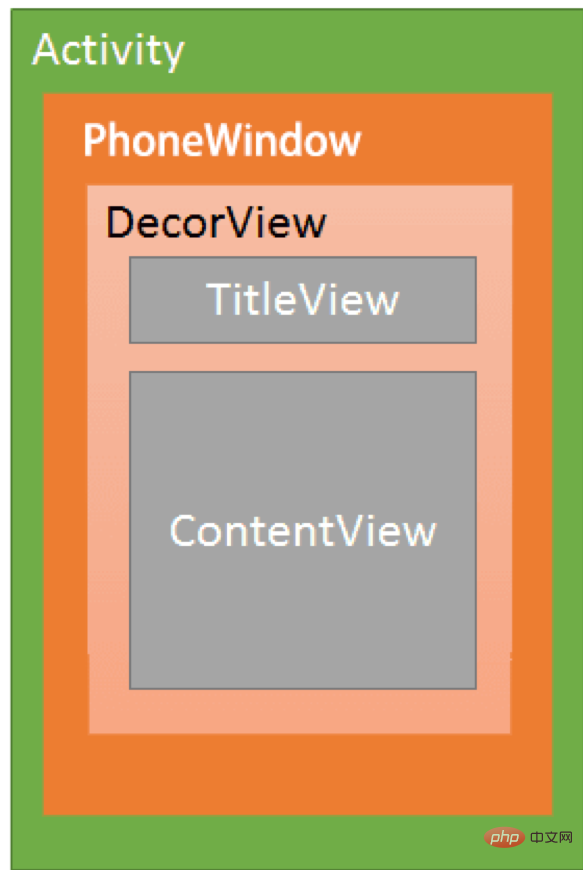
2.1, DecorView in Kurze Analyse
Zum Beispiel gibt es die folgende Ansicht: DecorView ist die oberste Ebene der gesamten Window-Schnittstelle und hat nur ein untergeordnetes Element, LinearLayout. Stellt die gesamte Fensteroberfläche dar, einschließlich der Benachrichtigungsleiste, der Titelleiste und der Inhaltsanzeigeleiste. In LinearLayout gibt es zwei untergeordnete FrameLayout-Elemente. 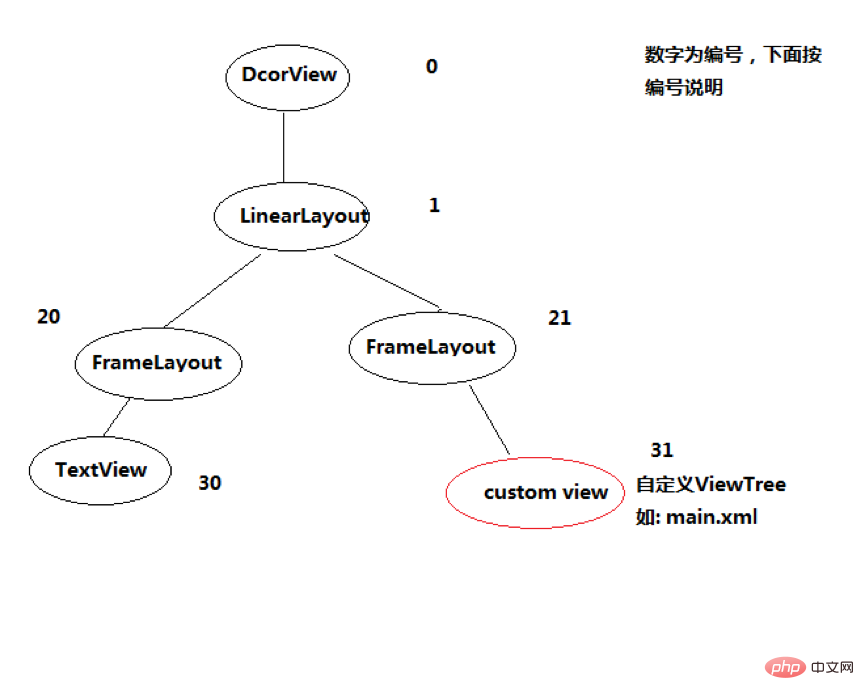
Die Rolle von DecorView
DecorView ist eine Ansicht der obersten Ebene, die im Wesentlichen ein FrameLayout ist. Sie enthält zwei Teile, die Titelleiste und die Inhaltsleiste davon sind FrameLayout. Die Inhaltsspalten-ID ist Inhalt. Dies ist der Teil der Aktivität, in dem setContentView festgelegt wird. Schließlich wird das Layout mit der Inhalts-ID zum FrameLayout hinzugefügt.
Inhalt abrufen: ViewGroup content=findViewById(android.id.content)
Set-Ansicht abrufen: getChildAt(0).
Nutzungszusammenfassung
Jede Aktivität enthält ein Fensterobjekt , das Window-Objekt wird normalerweise von PhoneWindow implementiert.
PhoneWindow: Legen Sie DecorView als Stammansicht des gesamten Anwendungsfensters fest, bei dem es sich um die Implementierungsklasse von Window handelt. Es ist das grundlegendste Fenstersystem in Android. Jede Aktivität erstellt ein PhoneWindow-Objekt, das die Schnittstelle für die Interaktion zwischen Aktivität und dem gesamten Ansichtssystem darstellt.
DecorView: Es handelt sich um eine Ansicht der obersten Ebene, die den spezifischen Inhalt darstellt, der im PhoneWindow angezeigt werden soll. DecorView ist der Vorfahre aller Ansichten in der aktuellen Aktivität. Sie stellt dem Benutzer nichts dar.
2.2. Die Ereignisverteilung von View
Der Ereignisverteilungsmechanismus von View kann durch die folgende Abbildung dargestellt werden: 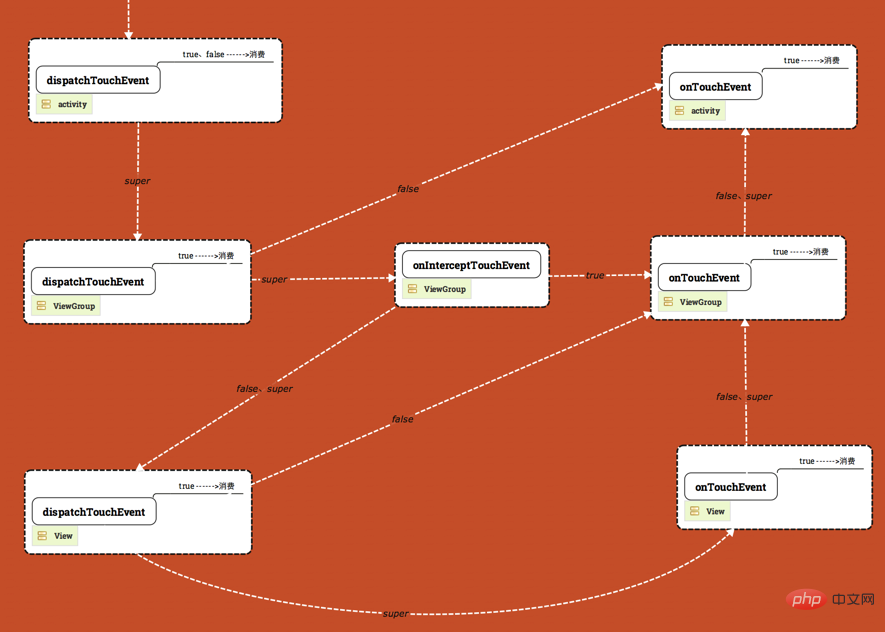
Wie oben gezeigt, ist die Abbildung in drei Ebenen unterteilt: Von oben nach unten: Als nächstes folgen Activity, ViewGroup und View.
- Das Ereignis beginnt mit dem weißen Pfeil in der oberen linken Ecke und wird durch das „dispatchTouchEvent“ der Aktivität verteilt.
- Die Wörter über dem Pfeil stellen den Rückgabewert der Methode dar (true zurückgeben, falsch zurückgeben, super zurückgeben). .xxxxx(), super
bedeutet, dass die Implementierung der übergeordneten Klasse aufgerufen wird. In den Feldern von - dispatchTouchEvent und onTouchEvent steht das Wort [true---->Consumption], was bedeutet, dass die Methode zurückkehrt wahr, das bedeutet, dass das Ereignis hier verbraucht wird und nicht an andere Stellen weitergegeben wird.
- Derzeit sind alle Ereignisse des Diagramms für ACTION_DOWN vor
- . Das „dispatchTouchEvent“ der Aktivität im Bild ist falsch (das Bild wurde korrigiert). Nur „super.dispatchTouchEvent(ev)“ wird deaktiviert verbraucht werden (Beendigung der Zustellung). >
ViewGroup-Ereignisverteilung
Der Ereignisverteilungsprozess von ViewGroup ist wahrscheinlich wie folgt: Wenn das ViewGroup-Abfangereignis der obersten Ebene, also onInterceptTouchEvent, true zurückgibt, wird das Ereignis zur Verarbeitung an den ViewGroup-OnTouchListener übergeben Wenn beides festgelegt ist, wird onTouch aufgerufen, andernfalls wird onTouchEvent aufgerufen. Wenn beides festgelegt ist, blockiert onTouchEvent. Wenn onClickerListener festgelegt ist, wird onClick aufgerufen Wenn Sie es nicht abfangen, wird das Ereignis an die untergeordnete Ansicht des Klickereignisses weitergeleitet, in der es sich befindet. Zu diesem Zeitpunkt wird das DispatchTouchEvent der Unteransicht aufgerufen
Ereignisverteilung der Ansicht
"dispatchTouchEvent -> onTouchEvent -> onTouchEvent" Der Unterschied zwischen "onTouchEvent" und "onTouch" hat Vorrang vor "onTouchEvent". nicht ausgeführt werden, und onClick wird nicht ausgeführt.
2.3. Zeichnung anzeigen
In der XML-Layoutdatei müssen unsere Parameter „layout_width“ und „layout_height“ keine bestimmten Größen schreiben, sondern „wrap_content“ oder „match_parent“. Diese beiden Einstellungen geben nicht die tatsächliche Größe an, aber die Ansicht, die wir auf dem Bildschirm zeichnen, muss eine bestimmte Breite und Höhe haben. Aus diesem Grund müssen wir die Größe selbst verwalten und festlegen. Natürlich bietet die View-Klasse eine Standardverarbeitung, aber wenn die Standardverarbeitung der View-Klasse nicht unseren Anforderungen entspricht, müssen wir die onMeasure-Funktion ~ neu schreiben.
Die onMeasure-Funktion ist eine int-Ganzzahl, die den Messmodus und die Größe enthält. Daten vom Typ „int“ belegen 32 Bit, und was Google implementiert, ist, dass die ersten 2 Bit der int-Daten zur Unterscheidung verschiedener Layoutmodi verwendet werden und die nächsten 30 Bit Größendaten speichern. Die Verwendung der Funktion
onMeasure ist wie folgt:
match_parent –>GENAU. Wie ist es zu verstehen? match_parent soll den gesamten verbleibenden Speicherplatz der übergeordneten Ansicht verwenden und den verbleibenden Speicherplatz der übergeordneten Ansicht bestimmen. Dies ist die in der Ganzzahl dieses Messmodus gespeicherte Größe.  wrap_content –>AT_MOST. So verstehen Sie: Wir möchten die Größe festlegen, um den Inhalt unserer Ansicht zu umschließen. Die Größe entspricht dann der Größe, die uns von der übergeordneten Ansicht als Referenz angegeben wurde. Solange diese Größe nicht überschritten wird, wird die spezifische Größe entsprechend festgelegt auf unsere Bedürfnisse.
wrap_content –>AT_MOST. So verstehen Sie: Wir möchten die Größe festlegen, um den Inhalt unserer Ansicht zu umschließen. Die Größe entspricht dann der Größe, die uns von der übergeordneten Ansicht als Referenz angegeben wurde. Solange diese Größe nicht überschritten wird, wird die spezifische Größe entsprechend festgelegt auf unsere Bedürfnisse.
Feste Größe (z. B. 100 dp) –>GENAU. Wenn der Benutzer die Größe angibt, müssen wir nicht mehr eingreifen. Natürlich ist die angegebene Größe die Hauptgröße. 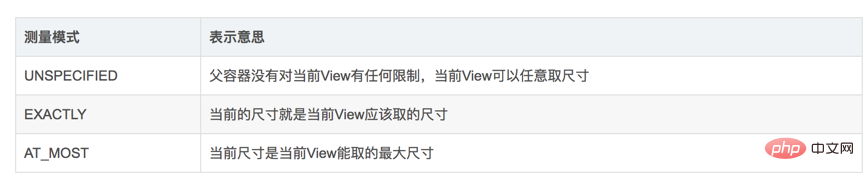
2.4. Zeichnen von ViewGroup
Das Anpassen von ViewGroup ist nicht so einfach~, weil es sich nicht nur um sich selbst kümmern muss , und seine Unteransichten müssen ebenfalls berücksichtigt werden. Wir alle wissen, dass ViewGroup ein View-Container ist, der die untergeordnete Ansicht enthält und dafür verantwortlich ist, die untergeordnete Ansicht am angegebenen Ort zu platzieren. 

ViewGroup和子View的大小算出来了之后,接下来就是去摆放了吧,具体怎么去摆放呢?这得根据你定制的需求去摆放了,比如,你想让子View按照垂直顺序一个挨着一个放,或者是按照先后顺序一个叠一个去放,这是你自己决定的。
已经知道怎么去摆放还不行啊,决定了怎么摆放就是相当于把已有的空间”分割”成大大小小的空间,每个空间对应一个子View,我们接下来就是把子View对号入座了,把它们放进它们该放的地方去。

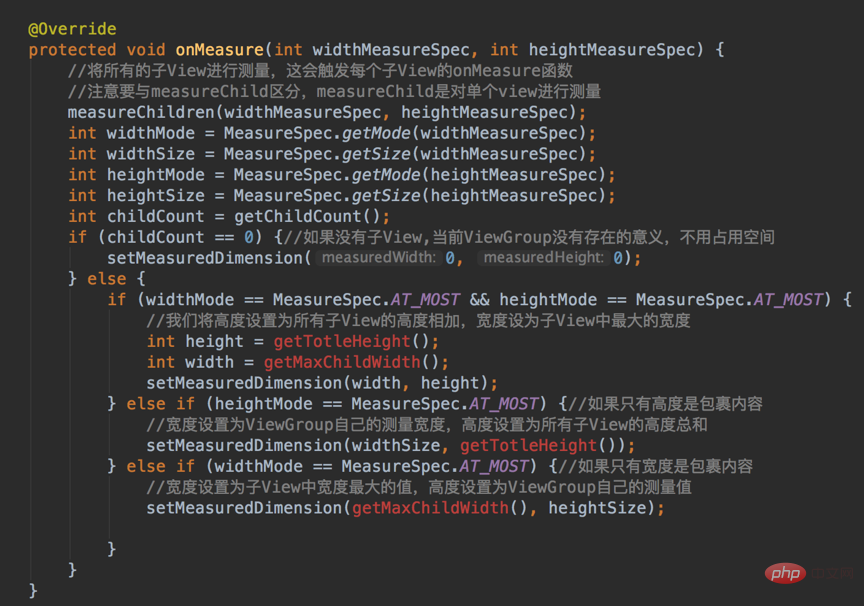

自定义ViewGroup可以参考:Android自定义ViewGroup
3、系统原理
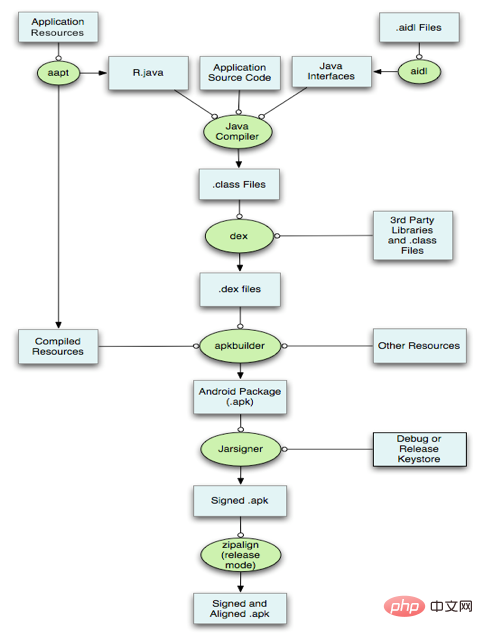
3.1、打包原理
Android的包文件APK分为两个部分:代码和资源,所以打包方面也分为资源打包和代码打包两个方面,这篇文章就来分析资源和代码的编译打包原理。
具体说来:
- 通过AAPT工具进行资源文件(包括AndroidManifest.xml、布局文件、各种xml资源等)的打包,生成R.java文件。
- 通过AIDL工具处理AIDL文件,生成相应的Java文件。
- 通过Javac工具编译项目源码,生成Class文件。
- 通过DX工具将所有的Class文件转换成DEX文件,该过程主要完成Java字节码转换成Dalvik字节码,压缩常量池以及清除冗余信息等工作。
- 通过ApkBuilder工具将资源文件、DEX文件打包生成APK文件。
- 利用KeyStore对生成的APK文件进行签名。
- 如果是正式版的APK,还会利用ZipAlign工具进行对齐处理,对齐的过程就是将APK文件中所有的资源文件举例文件的起始距离都偏移4字节的整数倍,这样通过内存映射访问APK文件的速度会更快。
3.2、安装流程
Android apk的安装过程主要氛围以下几步:
- 复制APK到/data/app目录下,解压并扫描安装包。
- 资源管理器解析APK里的资源文件。
- 解析AndroidManifest文件,并在/data/data/目录下创建对应的应用数据目录。
- 然后对dex文件进行优化,并保存在dalvik-cache目录下。
- 将AndroidManifest文件解析出的四大组件信息注册到PackageManagerService中。
- 安装完成后,发送广播。
可以使用下面的图表示: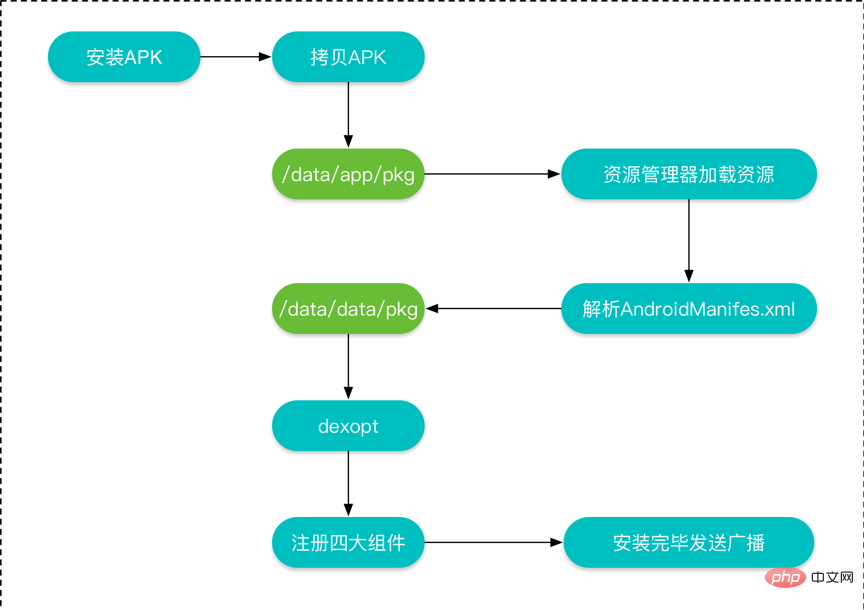
4、 第三方库解析
4.1、Retrofit网络请求框架
概念:Retrofit是一个基于RESTful的HTTP网络请求框架的封装,其中网络请求的本质是由OKHttp完成的,而Retrofit仅仅负责网络请求接口的封装。
原理:App应用程序通过Retrofit请求网络,实际上是使用Retrofit接口层封装请求参数,Header、URL等信息,之后由OKHttp完成后续的请求,在服务器返回数据之后,OKHttp将原始的结果交给Retrofit,最后根据用户的需求对结果进行解析。
retrofit使用
1.在retrofit中通过一个接口作为http请求的api接口
public interface NetApi {
@GET("repos/{owner}/{repo}/contributors")
Call<ResponseBody> contributorsBySimpleGetCall(@Path("owner") String owner, @Path("repo") String repo);
}2.创建一个Retrofit实例
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.build();3.调用api接口
NetApi repo = retrofit.create(NetApi.class);
//第三步:调用网络请求的接口获取网络请求
retrofit2.Call<ResponseBody> call = repo.contributorsBySimpleGetCall("username", "path");
call.enqueue(new Callback<ResponseBody>() { //进行异步请求
@Override
public void onResponse(Call<ResponseBody> call, Response<ResponseBody> response) {
//进行异步操作
}
@Override
public void onFailure(Call<ResponseBody> call, Throwable t) {
//执行错误回调方法
}
});retrofit动态代理
retrofit执行的原理如下:
1.首先,通过method把它转换成ServiceMethod。
2.然后,通过serviceMethod,args获取到okHttpCall对象。
3.最后,再把okHttpCall进一步封装并返回Call对象。
首先,创建retrofit对象的方法如下:
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.build();在创建retrofit对象的时候用到了build()方法,该方法的实现如下:
public Retrofit build() {
if (baseUrl == null) {
throw new IllegalStateException("Base URL required.");
}
okhttp3.Call.Factory callFactory = this.callFactory;
if (callFactory == null) {
callFactory = new OkHttpClient(); //设置kHttpClient
}
Executor callbackExecutor = this.callbackExecutor;
if (callbackExecutor == null) {
callbackExecutor = platform.defaultCallbackExecutor(); //设置默认回调执行器
}
// Make a defensive copy of the adapters and add the default Call adapter.
List<CallAdapter.Factory> adapterFactories = new ArrayList<>(this.adapterFactories);
adapterFactories.add(platform.defaultCallAdapterFactory(callbackExecutor));
// Make a defensive copy of the converters.
List<Converter.Factory> converterFactories = new ArrayList<>(this.converterFactories);
return new Retrofit(callFactory, baseUrl, converterFactories, adapterFactories,
callbackExecutor, validateEagerly); //返回新建的Retrofit对象
}该方法返回了一个Retrofit对象,通过retrofit对象创建网络请求的接口的方式如下:
NetApi repo = retrofit.create(NetApi.class);
retrofit对象的create()方法的实现如下:‘
public <T> T create(final Class<T> service) {
Utils.validateServiceInterface(service);
if (validateEagerly) {
eagerlyValidateMethods(service);
}
return (T) Proxy.newProxyInstance(service.getClassLoader(), new Class<?>[] { service },
new InvocationHandler() {
private final Platform platform = Platform.get();
@Override public Object invoke(Object proxy, Method method, Object... args)
throws Throwable {
// If the method is a method from Object then defer to normal invocation.
if (method.getDeclaringClass() == Object.class) {
return method.invoke(this, args); //直接调用该方法
}
if (platform.isDefaultMethod(method)) {
return platform.invokeDefaultMethod(method, service, proxy, args); //通过平台对象调用该方法
}
ServiceMethod serviceMethod = loadServiceMethod(method); //获取ServiceMethod对象
OkHttpCall okHttpCall = new OkHttpCall<>(serviceMethod, args); //传入参数生成okHttpCall对象
return serviceMethod.callAdapter.adapt(okHttpCall); //执行okHttpCall
}
});
}4.2、图片加载库对比
Picasso:120K
Glide:475K
Fresco:3.4M
Android-Universal-Image-Loader:162K
图片函数库的选择需要根据APP的具体情况而定,对于严重依赖图片缓存的APP,例如壁纸类,图片社交类APP来说,可以选择最专业的Fresco。对于一般的APP,选择Fresco会显得比较重,毕竟Fresco3.4M的体量摆在这。根据APP对图片的显示和缓存的需求从低到高,我们可以对以上函数库做一个排序。
Picasso < Android-Universal-Image-Loader < Glide < Fresco
2. Einführung:
Picasso: Es funktioniert am besten mit der Netzwerkbibliothek von Square, da Picasso den Caching-Teil der Netzwerkanforderung an die okhttp-Implementierung übergeben kann.
Glide: Es imitiert die API von Picasso und fügt viele Erweiterungen hinzu (z. B. GIF und andere Unterstützung). Das Standard-Bitmap-Format von Glide hat einen höheren Speicheraufwand als das Standard-ARGB_8888-Format von Picasso die volle Größe (cachet nur einen Typ), während Glide die gleiche Größe wie ImageView zwischenspeichert (d. h. 5656 und 128128 sind zwei Caches).
FBs Bildlade-Framework Fresco: Der größte Vorteil ist das Laden von Bitmaps unter 5,0 (mindestens 2,3). In Systemen unter 5.0 platziert Fresco Bilder in einem speziellen Speicherbereich (Ashmem-Bereich). Wenn das Bild nicht angezeigt wird, wird der belegte Speicher natürlich automatisch freigegeben. Dadurch wird die APP flüssiger und der durch die Bildspeichernutzung verursachte OOM wird reduziert. Warum soll es unter 5.0 liegen, weil das System es standardmäßig im Ashmem-Bereich speichert?
3. Zusammenfassung:
Glide kann alle Funktionen ausführen, die Picasso erreichen kann, aber die erforderlichen Einstellungen sind unterschiedlich. Allerdings ist die Größe von Picasso viel kleiner als die von Glide. Wenn die Netzwerkanforderung im Projekt selbst okhttp oder retrofit verwendet (im Wesentlichen ist es immer noch okhttp), wird empfohlen, Picasso zu verwenden, was viel kleiner ist (die Arbeit). des quadratischen Familieneimers). Der Vorteil von Glide sind große Bildströme wie GIF und Video. Wenn Sie Videoanwendungen wie Meipai und Aipai erstellen, wird die Verwendung empfohlen.
Die Speicheroptimierung von Fresco unter 5.0 ist sehr gut, aber der Preis ist, dass das Volumen auch sehr groß ist.
Aber die Verwendung ist auch etwas umständlich (kleiner Vorschlag). : he Diese Funktionen können nur mit einer integrierten ImageView implementiert werden, was mühsam zu verwenden ist. Wir ändern sie normalerweise entsprechend Fresco und verwenden direkt ihre Bitmap-Ebene)
Verwendung verschiedener JSON-Parsing-Bibliotheken
Referenzlink: https://www.cnblogs.com/kunpengit/p/4001680.html
(1) Googles Gson
Gson ist derzeit der vielseitigste Json-Parser Gson, ein Artefakt, wurde ursprünglich von Google als Reaktion auf den internen Bedarf von Google entwickelt. Seit der Veröffentlichung der ersten Version im Mai 2008 wurde es jedoch von vielen Unternehmen oder Benutzern verwendet. Die Anwendung von Gson besteht hauptsächlich aus zwei Konvertierungsfunktionen: toJson und fromJson. Sie weist keine Abhängigkeiten auf und erfordert keine zusätzlichen Jars. Sie kann direkt auf dem JDK ausgeführt werden. Bevor Sie diese Art der Objektkonvertierung verwenden, müssen Sie den Objekttyp und seine Mitglieder erstellen, bevor Sie die JSON-Zeichenfolge erfolgreich in das entsprechende Objekt konvertieren können. Solange die Klasse Get- und Set-Methoden enthält, kann Gson komplexe JSON-Typen vollständig in Beans oder Beans in JSON konvertieren. Dies ist ein Artefakt der JSON-Analyse. Von der Funktionalität her ist Gson einwandfrei, die Leistung hinkt jedoch der von FastJson hinterher.
(2) Alibabas FastJson
Fastjson ist ein leistungsstarker JSON-Prozessor, der in der Java-Sprache geschrieben und von Alibaba entwickelt wurde.
Keine Abhängigkeiten, keine Notwendigkeit für zusätzliche JARs und kann direkt auf dem JDK ausgeführt werden. Bei der Konvertierung komplexer Bean-Typen in Json kann es zu Problemen mit FastJson kommen. Referenztypen können zu Json-Konvertierungsfehlern führen und Referenzen müssen angegeben werden. FastJson verwendet einen Originalalgorithmus, um die Analysegeschwindigkeit auf das Äußerste zu erhöhen und übertrifft damit alle JSON-Bibliotheken.
Um den Vergleich der Json-Technologie zusammenzufassen: Googles Gson und Alibabas FastJson können bei der Auswahl von Projekten parallel verwendet werden. Wenn es nur um eine funktionale Anforderung und keine Leistungsanforderungen geht, können Sie Googles Gson verwenden Leistungsanforderungen: Sie können Gson zum Konvertieren von Beans in JSON verwenden, um die Genauigkeit der Daten sicherzustellen.
Hotspot-Technologie
Referenzlink – Android-Komponentisierungslösung
5.1. Komponentisierung
Komponentisierung: Dabei handelt es sich um die Aufteilung einer APP in mehrere Module oder eine Basisbibliothek. Einige Komponenten können während der Entwicklung separat debuggt werden. Die Komponenten müssen nicht voneinander abhängig sein, sondern können sich gegenseitig aufrufen. Bei der endgültigen Veröffentlichung werden alle Komponenten durch die Hauptabhängigkeit des APP-Projekts in eine APK gepackt.
(2) Ursprung:
- APP-Versionsiteration, neue Funktionen werden ständig hinzugefügt, das Geschäft wird komplex und die Wartungskosten sind hoch
- Die Geschäftskopplung ist hoch Der Code ist aufgebläht und das Team hat Schwierigkeiten bei der kollaborativen Entwicklung mit mehreren Personen.
- Der Android-Kompilierungscode steckt fest. Die Codekopplung in einem einzelnen Projekt ist schwerwiegend und erfordert eine Neukompilierung und Verpackung und arbeitsintensiv.
- Praktisch für Unit-Tests, da Sie nur ein Geschäftsmodul ändern können, ohne sich auf andere Module konzentrieren zu müssen.
(3) Vorteile:
- Durch die Komponentisierung werden gängige Module getrennt und einheitlich verwaltet, um die Wiederverwendung zu verbessern und die Seite in Komponenten mit geringerer Granularität aufzuteilen. Die Komponente enthält eine UI-Implementierung. und kann auch eine Datenschicht und eine Logikschicht umfassen
- Jede Komponente kann unabhängig kompiliert werden, was die Kompilierung beschleunigt, und unabhängig verpackt werden.
- Änderungen innerhalb jedes Projekts haben keine Auswirkungen auf andere Projekte.
- Business-Bibliotheksprojekte können schnell separiert und in andere Apps integriert werden.
- Geschäftsmodule mit häufigen Iterationen verfolgen einen Komponentenansatz und können sich nicht gegenseitig beeinträchtigen, die Effizienz der Zusammenarbeit verbessern, die Produktqualität kontrollieren und die Stabilität erhöhen.
- Bei der parallelen Entwicklung konzentrieren sich die Teammitglieder nur auf kleine, von ihnen selbst entwickelte Module, wodurch die Kopplung reduziert und die spätere Wartung erleichtert wird.
(4) Überlegungen:
Moduswechsel: So können Sie die APP frei zwischen individuellem Debugging und Gesamt-Debugging umschalten
Module für jedes Unternehmen nach der Komponentisierung kann eine separate APP sein (isModuleRun=false). Bei der Veröffentlichung des Pakets wird jedes Geschäftsmodul als lib-Abhängigkeit verwendet. Dies wird vollständig durch eine Variable im Root-Projekt gradle.properties gesteuert. Der Status von isModuleRun ist unterschiedlich, und die Ladeanwendung und AndroidManifest unterscheiden sich, um zu unterscheiden, ob es sich um eine unabhängige APK oder eine Bibliothek handelt.
Konfigurieren Sie in build.grade:

Ressourcenkonflikt
Wenn wir mehrere Module erstellen, wie können dieselben Ressourcenkonflikte in der Datei gelöst werden? Das Zusammenführen von Namen führt zu Konflikten:
Um doppelte Ressourcennamen zu vermeiden, fügen Sie im Build jeder Komponente das Präfix „xxx_“ hinzu. um das Ressourcennamenpräfix in Gradle zu erzwingen. Der Wert „resourcePrefix“ kann jedoch nur die Ressourcen in XML begrenzen und nicht die Bildressourcen So referenzieren Sie einige gängige Bibliotheken und Toolklassen zwischen mehreren Modulen
Komponentenkommunikation
Nach der Komponentisierung sind die Module voneinander isoliert, wie werden UI-Sprünge und Methoden ausgeführt? Zum Aufrufen können Sie Routing verwenden Frameworks wie Alibaba ARouter oder Meituans WMRouter
Jedes Geschäftsmodul benötigt keine Abhängigkeiten, bevor es durch das Routing gesprungen werden kann, wodurch die Kopplung zwischen Unternehmen perfekt gelöst wird.
Das wissen wir Komponenten sind miteinander verbunden, also wie man die Parameter erhält, die von anderen Modulen übergeben werden, wenn man alleine debuggt
Anwendung
Wenn die Komponenten alleine sind. Beim Ausführen bildet jedes Modul seine eigene APK, was bedeutet, dass es welche gibt Mehrere Anwendungen. Offensichtlich möchten wir nicht so viel Code schreiben, daher müssen wir nur eine BaseApplication definieren, und andere Anwendungen können diese BaseApplication auch direkt erben >Informationen zur Implementierung der Komponentisierung finden Sie unter: Anjuke Android Project Architecture Evolution
5.2, Plug-in
Referenzlink – Einführung in das Plug-in
( 1) Übersicht
Wenn es um Plug-Ins geht, müssen wir das Problem erwähnen, dass die Anzahl der Methoden 65535 übersteigt. Wir können es durch Dex-Unterauftragsvergabe lösen, und wir können es auch durch die Verwendung von Plug-In-Entwicklung lösen . Das Konzept des Plug-Ins besteht darin, die Plug-In-APP zu laden und auszuführen (2 Vorteile)
Um eine klare Arbeitsteilung zu gewährleisten, sind häufig verschiedene Teams verantwortlich Verschiedene Plug-in-APPs, sodass die Arbeitsteilung klarer ist. Jedes Modul ist in verschiedene Plug-in-APKs gepackt, und verschiedene Module können separat kompiliert werden, was die Entwicklungseffizienz verbessert und das oben erwähnte Problem der Überschreitung der Methodengrenze löst . Online-Fehler können durch die Einführung neuer Plug-Ins behoben werden, um einen „Hotfix“-Effekt zu erzielen.
Die Größe des Host-APK wurde reduziert. (3 Nachteile) Apps, die als Plug-Ins entwickelt wurden, können nicht auf Google Play gestartet werden, was bedeutet, dass es keinen Überseemarkt gibt. 6. Bildschirmanpassung6.1, Grundkonzepte
Bildschirmgröße
Bildschirmpixeldichte
Bedeutung: Anzahl der Pixel pro Zoll Einheit: dpi (Punkte pro Zoll)
Angenommen, das Gerät verfügt über 160 Pixel pro Zoll, dann beträgt die Bildschirmpixeldichte das Gerät =160dpi
6.2. Anpassungsmethode
1. Um die Flexibilität des Layouts zu gewährleisten und sich an verschiedene Bildschirmgrößen anzupassen Verwenden Sie „wrap_content“, „match_parent“, um die Breite und Höhe bestimmter Ansichtskomponenten zu steuern.
2. Relatives Layout verwenden und absolutes Layout deaktivieren.
3. Verwenden Sie das Weight-Attribut von LinearLayout
Wenn unsere Breite nicht 0dp ist (wrap_content und 0dp haben den gleichen Effekt), was ist mit match_parent?
Die wahre Bedeutung von android:layout_weight ist: Wenn die Ansicht dieses Attribut festlegt und es gültig ist, entspricht die Breite der Ansicht der ursprünglichen Breite (android:layout_width) plus dem Anteil des verbleibenden Platzes .
Aus dieser Perspektive erklären wir das obige Phänomen. Im obigen Code setzen wir die Breite jeder Schaltfläche auf match_parent. Angenommen, die Bildschirmbreite beträgt L, dann sollte die Breite jeder Schaltfläche auch L sein und die verbleibende Breite ist gleich L-(L+L) = -L .
Gewicht von Button1 = 1, das verbleibende Breitenverhältnis beträgt 1/(1+2)= 1/3, also ist die endgültige Breite L+1/3*(-L)=2/3L, Button2 ist The Die Berechnung ist ähnlich, die endgültige Breite beträgt L+2/3(-L)=1/3L.
4. Verwenden Sie .9-Bilder
6.3. Die heutige Toutiao-Bildschirmanpassungslösung, ultimative Version
7
Referenzlink: Android-Leistungsüberwachungstool, Methoden zur Optimierung von Speicher, Verzögerung, Stromverbrauch und APK-Größe
Die Android-Leistungsoptimierung wird hauptsächlich unter folgenden Gesichtspunkten optimiert: Stabil (Speicherüberlauf, Absturz). )
Glatt (steckt fest)
Verbrauch (Stromverbrauch, Verkehr)
Installationspaket (APK-Verschlankung)
Es gibt viele Gründe, die die Stabilität beeinträchtigen, wie z. B. unangemessene Speichernutzung, unzureichende Berücksichtigung von Code-Ausnahmeszenarien , unangemessene Codelogik usw. wirken sich alle auf die Stabilität der Anwendung aus. Die beiden häufigsten Szenarien sind: Absturz und ANR. Diese beiden Fehler machen das Programm unbrauchbar. Machen Sie daher bei der globalen Überwachung von Abstürzen gute Arbeit, behandeln Sie Abstürze und sammeln und zeichnen Sie Absturzinformationen und Ausnahmeinformationen für die spätere Analyse auf. Verwenden Sie den Hauptthread, um das Geschäft ordnungsgemäß zu verarbeiten, und führen Sie keine zeitaufwändigen Vorgänge im Hauptthread aus verhindern, dass ANR-Programme nicht mehr reagieren.
(1) Stabilität – Speicheroptimierung
(1) Speicherüberwachungstool:
Es handelt sich um ein Speicherüberwachungstool, das mit Android Studio geliefert wird und sehr gut verwendet werden kann Helfen Sie uns, eine Echtzeitanalyse des Gedächtnisses durchzuführen. Wenn Sie auf die Registerkarte „Speichermonitor“ in der unteren rechten Ecke von Android Studio klicken und das Tool öffnen, können Sie sehen, dass das hellere Blau den freien Speicher darstellt, während der dunklere Teil den verwendeten Speicher darstellt. Aus dem Trenddiagramm der Speichertransformation können Sie dies ermitteln Wenn der Speicher beispielsweise weiter zunimmt, kann es zu Speicherlecks kommen. Wenn der Speicher plötzlich abnimmt, kann es zu GC usw. kommen, wie in der folgenden Abbildung dargestellt.
LeakCanary-Tool:
LeakCanary ist ein von Square entwickeltes Open-Source-Framework auf Basis von MAT zur Überwachung von Android-Speicherlecks. Das Arbeitsprinzip lautet:Der Überwachungsmechanismus verwendet Javas WeakReference und ReferenceQueue. Wenn das von WeakReference umschlossene Aktivitätsobjekt recycelt wird, wird die WeakReference-Referenz in die ReferenceQueue eingefügt ReferenceQueue kann verwendet werden, um zu überprüfen, ob die Aktivität recycelt werden kann (in der ReferenceQueue wird angegeben, dass sie recycelt werden kann und kein Leck vorliegt; andernfalls liegt möglicherweise ein Leck vor. LeakCanary führt GC einmal aus. Wenn es nicht in der ist ReferenceQueue, es wird als Leck betrachtet.
Wenn festgestellt wird, dass die Aktivität durchgesickert ist, greifen Sie auf die Speicherabbilddatei (Debug.dumpHprofData) zu. Analysieren Sie dann die Speicherdatei über HeapAnalyzer (checkForLeak – findLeakingReference – findLeakTrace). Analyse. Schließlich wird der Speicherverlust über DisplayLeakService angezeigt.
(3) Android Lint Tool:
Android Lint Tool ist ein in Android Sutido integriertes Android-Code-Eingabeaufforderungstool, das sehr leistungsstarke Hilfe für Ihr Layout und Ihren Code bieten kann. Bei harter Codierung wird eine Ebenenwarnung ausgegeben. Beispiel: Wenn Sie drei redundante LinearLayout-Layouts in die Layoutdatei schreiben, den Text direkt in TextView schreiben und dp anstelle von sp als Einheit für die Schriftgröße verwenden, wird auf der rechten Seite angezeigt des Herausgebers.
(2) Glätte – Optimierung des Stotterns
Stotterszenarien treten normalerweise in den direktesten Aspekten der Benutzerinteraktion auf. Die beiden Hauptfaktoren, die die Verzögerung beeinflussen, sind das Zeichnen der Schnittstelle und die Datenverarbeitung.
Schnittstellenzeichnung: Der Hauptgrund ist, dass die Zeichnungsebene tief ist, die Seite komplex ist und die Aktualisierung unangemessen ist. Aus diesen Gründen werden in der Benutzeroberfläche, der ersten Schnittstelle nach dem Start, häufiger hängende Szenen angezeigt , und die Zeichnung, die zur Seite springt.
Datenverarbeitung: Der Grund für dieses Verzögerungsszenario ist, dass die Datenverarbeitung zu groß ist, was im Allgemeinen in drei Situationen unterteilt ist: Die eine ist, dass die Daten im UI-Thread verarbeitet werden, und die andere ist dass die Datenverarbeitung viel CPU beansprucht, was dazu führt, dass der Hauptthread nicht abgerufen werden kann. Drittens führt die Erhöhung des Speichers zu häufigem GC, was zu Verzögerungen führt.
(1) Layout-Optimierung
Wenn das Android-System Ansichten misst, anordnet und zeichnet, durchläuft es die Anzahl der Ansichten. Wenn die Höhe einer Ansichtszahl zu hoch ist, wird die Geschwindigkeit der Messung, des Layouts und des Zeichnens erheblich beeinträchtigt. Google empfiehlt in seiner API-Dokumentation außerdem, dass die Ansichtshöhe 10 Ebenen nicht überschreiten sollte. In der aktuellen Version verwendet Google RelativeLayout anstelle von LineraLayout als Standard-Root-Layout. Der Zweck besteht darin, die Höhe des durch die LineraLayout-Verschachtelung generierten Layoutbaums zu reduzieren und so die Effizienz des UI-Renderings zu verbessern.
Layout wiederverwenden, Beschriftungen verwenden, um das Layout wiederzuverwenden;
Anzeigegeschwindigkeit erhöhen, verzögertes Laden der Ansicht verwenden;
Beachten Sie, dass die Verwendung von wrap_content das Maß erhöht Berechnen Sie die Kosten;
Löschen Sie nutzlose Attribute im Steuerelement
.×10***), ihre Darstellung ist 0,*****×10, in der Form .*** e ±**) im Computer stellt das Sternchen davor eine Festkomma-Dezimalzahl dar, also eine reine Dezimalzahl mit dem Der ganzzahlige Teil ist 0 und das Sternchen hinten. Der Exponententeil ist eine Festkomma-Ganzzahl. Jede ganze Zahl oder Dezimalzahl kann mit dieser Form ausgedrückt werden. Beispielsweise kann 1024 als 0,1024×10^4 ausgedrückt werden, was .1024e+004 ist, und 3,1415926 kann als 0,31415926×10^1 ausgedrückt werden, was .31415926e+001 ist , das ist eine Gleitkommazahl. Die an Gleitkommazahlen ausgeführten Operationen sind Gleitkommaoperationen. Gleitkommaoperationen sind komplexer als reguläre Operationen, daher führen Computer Gleitkommaoperationen viel langsamer aus als reguläre Operationen.
(2) Vermeiden Sie die unsachgemäße Verwendung von Wake Lock. Wake Lock ist ein Sperrmechanismus, der sich hauptsächlich auf den Ruhezustand des Systems bezieht. Solange jemand diese Sperre hält, kann das System nicht in den Ruhezustand versetzt werden Das System wird nicht schlafen. Der Zweck besteht darin, den Betrieb unseres Programms vollständig zu unterstützen. Wenn Sie dies nicht tun, treten in einigen Fällen Probleme auf. Beispielsweise stoppen Heartbeat-Pakete für Instant Messaging wie WeChat den Netzwerkzugriff kurz nach dem Ausschalten des Bildschirms. Daher wird Wake_Lock in WeChat häufig verwendet. Um Strom zu sparen, geht das System automatisch in den Ruhezustand, wenn die CPU nicht mit Aufgaben beschäftigt ist. Wenn es eine Aufgabe gibt, die die CPU für eine effiziente Ausführung aufwecken muss, wird der CPU ein Wake_Lock hinzugefügt. Ein häufiger Fehler, den jeder macht, ist, dass es leicht ist, die CPU zum Arbeiten aufzuwecken, aber leicht vergisst, Wake_Lock freizugeben. (3) Verwenden Sie Job Scheduler, um Hintergrundaufgaben zu verwalten. In Android 5.0 API 21 stellt Google eine Komponente namens JobScheduler API bereit, um das Szenario der Ausführung einer Aufgabe zu einem bestimmten Zeitpunkt oder wenn eine bestimmte Bedingung erfüllt ist, zu verarbeiten, z. B. wenn der Benutzer nachts ist Im Ruhezustand oder wenn das Gerät an das Netzteil angeschlossen und mit WLAN verbunden ist, beginnt es mit dem Herunterladen von Updates. Dies kann die Anwendungseffizienz verbessern und gleichzeitig den Ressourcenverbrauch reduzieren. (4) Installationspaket – APK-Verschlankung (1) Struktur des Installationspakets Assets-Ordner. Zum Speichern einiger Konfigurationsdateien und Ressourcendateien generieren Assets nicht automatisch entsprechende IDs, sondern erhalten diese über die Schnittstelle der AssetManager-Klasse. res. res ist die Abkürzung für Ressource. Die entsprechende ID wird automatisch generiert und der .R-Datei direkt zugeordnet. META-INF. Speichern Sie die Signaturinformationen der Anwendung, um die Integrität der APK-Datei zu überprüfen. AndroidManifest.xml. Diese Datei wird verwendet, um die Konfigurationsinformationen der Android-Anwendung, die Registrierungsinformationen einiger Komponenten, verwendbare Berechtigungen usw. zu beschreiben.classes.dex. Das Dalvik-Bytecode-Programm macht die virtuelle Dalvik-Maschine ausführbar. Im Allgemeinen verwenden Android-Anwendungen das dx-Tool im Android SDK, um beim Packen Java-Bytecode in Dalvik-Bytecode zu konvertieren.
resources.arsc. Es zeichnet die Zuordnungsbeziehung zwischen Ressourcendateien und Ressourcen-IDs auf und wird verwendet, um Ressourcen basierend auf Ressourcen-IDs zu finden.
(2) Reduzieren Sie die Größe des Installationspakets
Code-Verschleierung. Verwenden Sie das mit der IDE gelieferte Code-Obfuscator-Tool proGuard, das Komprimierung, Optimierung, Verschleierung und andere Funktionen umfasst.
Ressourcenoptimierung. Verwenden Sie beispielsweise Android Lint, um redundante Ressourcen zu löschen, Ressourcendateien zu minimieren usw.
Bildoptimierung. Verwenden Sie beispielsweise PNG-Optimierungstools, um Bilder zu komprimieren. Empfehlen Sie das fortschrittlichste Komprimierungstool Googlek, die Open-Source-Bibliothek Zopfli. Wenn die Anwendung Version 0 oder höher ist, wird empfohlen, das WebP-Bildformat zu verwenden.
Vermeiden Sie Bibliotheken von Drittanbietern mit doppelter oder nutzloser Funktionalität. Beispielsweise können Baidu Maps mit der Basiskarte verbunden werden, iFlytek Voice muss nicht offline verbunden werden, die Bildbibliothek GlidePicasso usw.
Plug-in-Entwicklung. Beispielsweise kann die Größe des Installationspakets reduziert werden, indem Funktionsmodule auf dem Server platziert und bei Bedarf heruntergeladen werden.
Sie können das Open-Source-Tool zur Dateiverschleierung von WeChat – AndResGuard – verwenden. Im Allgemeinen kann die APK-Größe auf etwa 1 MB komprimiert werden.
7.1. Kaltstart und Heißstart
Referenzlink: https://www.jianshu.com/p/03c0fd3fc245
Kaltstart
Beim Starten einer Anwendung gibt es keinen Prozess für die Anwendung. Zu diesem Zeitpunkt erstellt das System einen neuen Prozess und weist ihn der Anwendung zu
Unterschied
Kaltstartprozess
Kaltstartoptimierung
8.1 MVP-Architektur Entwickelt aus MVC. In MVP steht M für Model, V für View und P für Presenter.
Modellschicht (Modell): Wird hauptsächlich zum Abrufen von Datenfunktionen, Geschäftslogik und Entitätsmodellen verwendet.
Ansichtsebene (Ansicht): Entspricht der Aktivität oder dem Fragment und ist für die teilweise Anzeige der Ansicht und die Benutzerinteraktion der Geschäftslogik verantwortlich.
Kontrollebene (Präsentator): Verantwortlich für die Vervollständigung der Interaktion zwischen der Ansicht Schicht und Modellschicht: Erhalten Sie die Daten in der M-Schicht über die P-Schicht und geben Sie sie an die V-Schicht zurück, sodass keine Kopplung zwischen der V-Schicht und der M-Schicht besteht.
In MVP trennt die Presenter-Ebene die Ansichtsebene und die Modellebene vollständig und implementiert die Hauptprogrammlogik in der Presenter-Ebene. Der Presenter steht nicht in direktem Zusammenhang mit der spezifischen Ansichtsebene (Aktivität), ist jedoch vorhanden implementiert durch Definieren einer Schnittstelle für die Interaktion, sodass der Präsentator bei Änderungen der Ansichtsebene (Aktivität) weiterhin unverändert bleiben kann. Die Schnittstellenklasse der Ansichtsschicht sollte nur über Set/Get-Methoden verfügen und einige Schnittstelleninhalte und Benutzereingaben sollten nicht überflüssig sein. Der Ansichtsschicht ist es niemals gestattet, direkt auf die Modellschicht zuzugreifen. Dies ist der größte Unterschied zu MVC und der Hauptvorteil von MVP.
9. Virtuelle Maschine
9.1. Vergleich zwischen der virtuellen Maschine von Android Dalvik und der virtuellen Maschine von ART
Dalvik
Android 4.4 und früher verwenden die virtuelle Maschine von Dalvik. Wir wissen, dass Apk während des Verpackungsprozesses zunächst Java und andere Quellcodes über Javac in .class-Dateien kompiliert, unsere virtuelle Dalvik-Maschine jedoch nur .dex-Dateien ausführt. Zu diesem Zeitpunkt konvertiert dx die .class-Dateien in virtuelle Dalvik Maschinen. .dex-Datei für die Maschinenausführung. Wenn die virtuelle Dalvik-Maschine gestartet wird, konvertiert sie zunächst die .dex-Datei in einen schnell laufenden Maschinencode. Aufgrund des Problems von 65535 haben wir beim Kaltstart der Anwendung einen Co-Packing-Prozess Die App startet langsam. Dies ist die JIT-Funktion (Just In Time) der virtuellen Dalvik-Maschine.
ART
Die virtuelle ART-Maschine ist eine virtuelle Android-Maschine, die erst in Android 5.0 verwendet werden sollte. Die virtuelle ART-Maschine muss jedoch mit den Eigenschaften der virtuellen Dalvik-Maschine kompatibel sein ART verfügt über eine sehr gute AOT-Funktion (im Voraus). Diese Funktion besteht darin, dass wir bei der Installation der APK Dex direkt in Maschinencode verarbeiten, der direkt von der virtuellen ART-Maschine verwendet werden kann. Die virtuelle ART-Maschine konvertiert die .dex-Datei in eine .oat-Datei, die direkt ausgeführt werden kann. ART Die virtuelle Maschine unterstützt von Natur aus mehrere Dexes, daher gibt es keinen Synchronisierungsprozess, sodass die virtuelle ART-Maschine die Kaltstartgeschwindigkeit der APP erheblich verbessert.
ART-Vorteile:
App-Kaltstartgeschwindigkeit beschleunigen
GC-Geschwindigkeit verbessern
提供功能全面的Debug特性
ART缺点:
APP安装速度慢,因为在APK安装的时候要生成可运行.oat文件
APK占用空间大,因为在APK安装的时候要生成可运行.oat文件
arm处理器
关于ART更详细的介绍,可以参考Android ART详解
总结
熟悉Android性能分析工具、UI卡顿、APP启动、包瘦身和内存性能优化
熟悉Android APP架构设计,模块化、组件化、插件化开发
熟练掌握Java、设计模式、网络、多线程技术
Java基本知识点
1、Java的类加载过程
jvm将.class类文件信息加载到内存并解析成对应的class对象的过程,注意:jvm并不是一开始就把所有的类加载进内存中,只是在第一次遇到某个需要运行的类才会加载,并且只加载一次
主要分为三部分:1、加载,2、链接(1.验证,2.准备,3.解析),3、初始化
1:加载
类加载器包括 BootClassLoader、ExtClassLoader、APPClassLoader
2:链接
验证:(验证class文件的字节流是否符合jvm规范)
准备:为类变量分配内存,并且进行赋初值
解析:将常量池里面的符号引用(变量名)替换成直接引用(内存地址)过程,在解析阶段,jvm会把所有的类名、方法名、字段名、这些符号引用替换成具体的内存地址或者偏移量。
3:初始化
主要对类变量进行初始化,执行类构造器的过程,换句话说,只对static修试的变量或者语句进行初始化。
范例:Person person = new Person();为例进行说明。
Java编程思想中的类的初始化过程主要有以下几点:
- 找到class文件,将它加载到内存
- 在堆内存中分配内存地址
- 初始化
- 将堆内存地址指给栈内存中的p变量
2、String、StringBuilder、StringBuffer
StringBuffer里面的很多方法添加了synchronized关键字,是可以表征线程安全的,所以多线程情况下使用它。
执行速度:
StringBuilder > StringBuffer > String
StringBuilder牺牲了性能来换取速度的,这两个是可以直接在原对象上面进行修改,省去了创建新对象和回收老对象的过程,而String是字符串常量(final)修试,另外两个是字符串变量,常量对象一旦创建就不可以修改,变量是可以进行修改的,所以对于String字符串的操作包含下面三个步骤:
- 创建一个新对象,名字和原来的一样
- 在新对象上面进行修改
- 原对象被垃圾回收掉
3、JVM内存结构
Java对象实例化过程中,主要使用到虚拟机栈、Java堆和方法区。Java文件经过编译之后首先会被加载到jvm方法区中,jvm方法区中很重的一个部分是运行时常量池,用以存储class文件类的版本、字段、方法、接口等描述信息和编译期间的常量和静态常量。
3.1、JVM基本结构
类加载器classLoader,在JVM启动时或者类运行时将需要的.class文件加载到内存中。
执行引擎,负责执行class文件中包含的字节码指令。
本地方法接口,主要是调用C/C++实现的本地方法及返回结果。
内存区域(运行时数据区),是在JVM运行的时候操作所分配的内存区,
主要分为以下五个部分,如下图: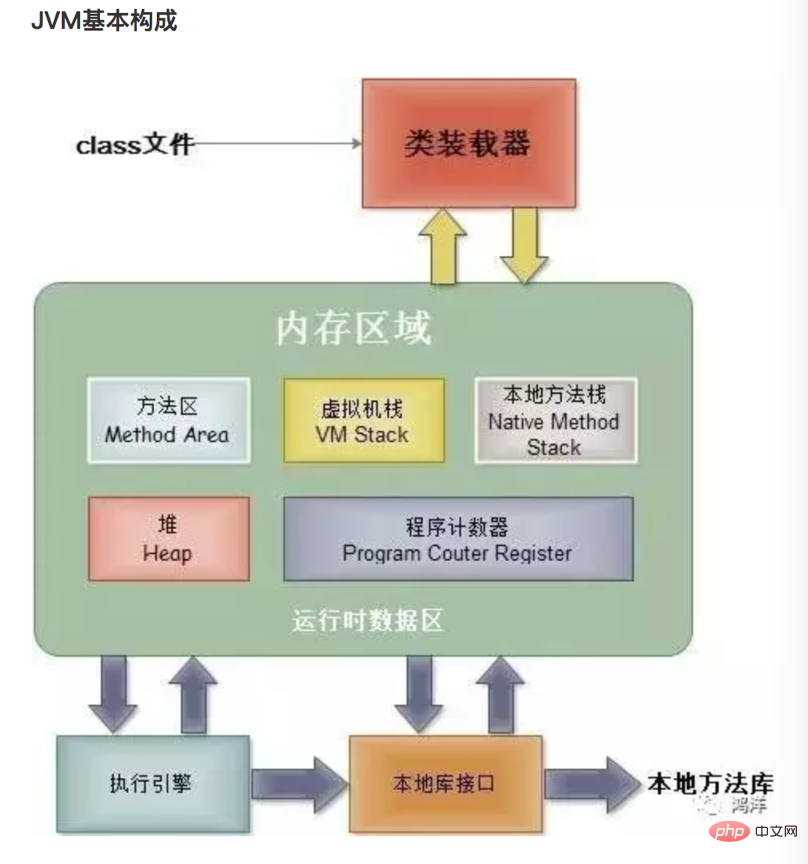
- 方法区:用于存储类结构信息的地方,包括常量池、静态变量、构造函数等。
- Java堆(heap):存储Java实例或者对象的地方。这块是gc的主要区域。
- Java栈(stack):Java栈总是和线程关联的,每当创建一个线程时,JVM就会为这个线程创建一个对应的Java栈。在这个java栈中又会包含多个栈帧,每运行一个方法就创建一个栈帧,用于存储局部变量表、操作栈、方法返回值等。每一个方法从调用直至执行完成的过程,就对应一个栈帧在java栈中入栈到出栈的过程。所以java栈是线程私有的。
- 程序计数器:用于保存当前线程执行的内存地址,由于JVM是多线程执行的,所以为了保证线程切换回来后还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方,可见程序计数器也是线程私有的。
- 本地方法栈:和Java栈的作用差不多,只不过是为JVM使用到的native方法服务的。
3.2、JVM源码分析
https://www.jianshu.com/nb/12554212
4、GC机制
垃圾收集器一般完成两件事
- 检测出垃圾;
- 回收垃圾;
4.1 Java对象引用
通常,Java对象的引用可以分为4类:强引用、软引用、弱引用和虚引用。
强引用:通常可以认为是通过new出来的对象,即使内存不足,GC进行垃圾收集的时候也不会主动回收。
Object obj = new Object();
软引用:在内存不足的时候,GC进行垃圾收集的时候会被GC回收。
Object obj = new Object(); SoftReference<Object> softReference = new SoftReference<>(obj);
弱引用:无论内存是否充足,GC进行垃圾收集的时候都会回收。
Object obj = new Object(); WeakReference<Object> weakReference = new WeakReference<>(obj);
虚引用:和弱引用类似,主要区别在于虚引用必须和引用队列一起使用。
Object obj = new Object(); ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>(); PhantomReference<Object> phantomReference = new PhantomReference<>(obj, referenceQueue);
引用队列:如果软引用和弱引用被GC回收,JVM就会把这个引用加到引用队列里,如果是虚引用,在回收前就会被加到引用队列里。
垃圾检测方法:
引用计数法:给每个对象添加引用计数器,每个地方引用它,计数器就+1,失效时-1。如果两个对象互相引用时,就导致无法回收。
可达性分析算法:以根集对象为起始点进行搜索,如果对象不可达的话就是垃圾对象。根集(Java栈中引用的对象、方法区中常量池中引用的对象、本地方法中引用的对象等。JVM在垃圾回收的时候,会检查堆中所有对象是否被这些根集对象引用,不能够被引用的对象就会被垃圾回收器回收。)
垃圾回收算法:
常见的垃圾回收算法有:
标记-清除
标记:首先标记所有需要回收的对象,在标记完成之后统计回收所有被标记的对象,它的标记过程即为上面的可达性分析算法。
清除:清除所有被标记的对象
缺点:
效率不足,标记和清除效率都不高
空间问题,标记清除之后会产生大量不连续的内存碎片,导致大对象分配无法找到足够的空间,提前进行垃圾回收。
复制回收算法
将可用的内存按容量划分为大小相等的2块,每次只用一块,当这一块的内存用完了,就将存活的对象复制到另外一块上面,然后把已使用过的内存空间一次清理掉。
缺点:
将内存缩小了原本的一般,代价比较高
大部分对象是“朝生夕灭”的,所以不必按照1:1的比例划分。
现在商业虚拟机采用这种算法回收新生代,但不是按1:1的比例,而是将内存区域划分为eden 空间、from 空间、to 空间 3 个部分。
其中 from 空间和 to 空间可以视为用于复制的两块大小相同、地位相等,且可进行角色互换的空间块。from 和 to 空间也称为 survivor 空间,即幸存者空间,用于存放未被回收的对象。
在垃圾回收时,eden 空间中的存活对象会被复制到未使用的 survivor 空间中 (假设是 to),正在使用的 survivor 空间 (假设是 from) 中的年轻对象也会被复制到 to 空间中 (大对象,或者老年对象会直接进入老年带,如果 to 空间已满,则对象也会直接进入老年代)。此时,eden 空间和 from 空间中的剩余对象就是垃圾对象,可以直接清空,to 空间则存放此次回收后的存活对象。这种改进的复制算法既保证了空间的连续性,又避免了大量的内存空间浪费。
标记-整理
在老年代的对象大都是存活对象,复制算法在对象存活率教高的时候,效率就会变得比较低。根据老年代的特点,有人提出了“标记-压缩算法(Mark-Compact)”
标记过程与标记-清除的标记一样,但后续不是对可回收对象进行清理,而是让所有的对象都向一端移动,然后直接清理掉端边界以外的内存。
这种方法既避免了碎片的产生,又不需要两块相同的内存空间,因此,其性价比比较高。
分带收集算法
根据对象存活的周期不同将内存划分为几块,一般是把Java堆分为老年代和新生代,这样根据各个年代的特点采用适当的收集算法。
新生代每次收集都有大量对象死去,只有少量存活,那就选用复制算法,复制的对象数较少就可完成收集。
老年代对象存活率高,使用标记-压缩算法,以提高垃圾回收效率。
5、类加载器
程序在启动的时候,并不会一次性加载程序所要用的所有class文件,而是根据程序的需要,通过Java的类加载机制(ClassLoader)来动态加载某个class文件到内存当中的,从而只有class文件被载入到了内存之后,才能被其它class所引用。所以ClassLoader就是用来动态加载class文件到内存当中用的。
5.1、双亲委派原理
每个ClassLoader实例都有一个父类加载器的引用(不是继承关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但是可以用做其他ClassLoader实例的父类加载器。
当一个ClassLoader 实例需要加载某个类时,它会试图在亲自搜索这个类之前先把这个任务委托给它的父类加载器,这个过程是由上而下依次检查的,首先由顶层的类加载器Bootstrap CLassLoader进行加载,如果没有加载到,则把任务转交给Extension CLassLoader视图加载,如果也没有找到,则转交给AppCLassLoader进行加载,还是没有的话,则交给委托的发起者,由它到指定的文件系统或者网络等URL中进行加载类。还没有找到的话,则会抛出CLassNotFoundException异常。否则将这个类生成一个类的定义,并将它加载到内存中,最后返回这个类在内存中的Class实例对象。
5.2、 为什么使用双亲委托模型
JVM在判断两个class是否相同时,不仅要判断两个类名是否相同,还要判断是否是同一个类加载器加载的。
避免重复加载,父类已经加载了,则子CLassLoader没有必要再次加载。
考虑安全因素,假设自定义一个String类,除非改变JDK中CLassLoader的搜索类的默认算法,否则用户自定义的CLassLoader如法加载一个自己写的String类,因为String类在启动时就被引导类加载器Bootstrap CLassLoader加载了。
关于Android的双亲委托机制,可以参考android classloader双亲委托模式
6、集合
Java集合类主要由两个接口派生出:Collection和Map,这两个接口是Java集合的根接口。
Collection接口是集合类的根接口,Java中没有提供这个接口的直接的实现类。但是却让其被继承产生了两个接口,就是 Set和List。Set中不能包含重复的元素。List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式。
Map是Java.util包中的另一个接口,它和Collection接口没有关系,是相互独立的,但是都属于集合类的一部分。Map包含了key-value对。Map不能包含重复的key,但是可以包含相同的value。
6.1、区别
List,Set都是继承自Collection接口,Map则不是;
List特点:元素有放入顺序,元素可重复; Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法;
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
6.2、List和Vector比较
Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
Vector可以设置增长因子,而ArrayList不可以。
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
6.3、HashSet如何保证不重复
HashSet底层通过HashMap来实现的,在往HashSet中添加元素是
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();在HashMap中进行查找是否存在这个key,value始终是一样的,主要有以下几种情况:
- 如果hash码值不相同,说明是一个新元素,存;
- 如果hash码值相同,且equles判断相等,说明元素已经存在,不存;
- 如果hash码值相同,且equles判断不相等,说明元素不存在,存;
- 如果有元素和传入对象的hash值相等,那么,继续进行equles()判断,如果仍然相等,那么就认为传入元素已经存在,不再添加,结束,否则仍然添加;
6.4、HashSet与Treeset的适用场景
- HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
- TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值
- HashSet是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
- HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
6.5、HashMap与TreeMap、HashTable的区别及适用场景
HashMap 非线程安全,基于哈希表(散列表)实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。其中散列表的冲突处理主要分两种,一种是开放定址法,另一种是链表法。HashMap的实现中采用的是链表法。
TreeMap:非线程安全基于红黑树实现,TreeMap没有调优选项,因为该树总处于平衡状态
7、 常量池
7.1、Interger中的128(-128~127)
当数值范围为-128~127时:如果两个new出来Integer对象,即使值相同,通过“”比较结果为false,但两个对象直接赋值,则通过“”比较结果为“true,这一点与String非常相似。
当数值不在-128~127时,无论通过哪种方式,即使两个对象的值相等,通过“”比较,其结果为false;
当一个Integer对象直接与一个int基本数据类型通过“”比较,其结果与第一点相同;
Integer对象的hash值为数值本身;
@Override
public int hashCode() {
return Integer.hashCode(value);
}7.2、为什么是-128-127?
在Integer类中有一个静态内部类IntegerCache,在IntegerCache类中有一个Integer数组,用以缓存当数值范围为-128~127时的Integer对象。
8、泛型
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 Java语言引入泛型的好处是安全简单。
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
它提供了编译期的类型安全,确保你只能把正确类型的对象放入 集合中,避免了在运行时出现ClassCastException。
使用Java的泛型时应注意以下几点:
- 泛型的类型参数只能是类类型(包括自定义类),不能是简单类型。
- 同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
- 泛型的类型参数可以有多个。
- 泛型的参数类型可以使用extends语句,例如。习惯上称为“有界类型”。
- 泛型的参数类型还可以是通配符类型。例如Class> classType =
Class.forName(“java.lang.String”);
8.1 T泛型和通配符泛型
- ? 表示不确定的java类型。
- T 表示java类型。
- K V 分别代表java键值中的Key Value。
- E 代表Element。
8.2 泛型擦除
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如 List在运行时仅用一个List来表示。这样做的目的,是确保能和Java 5之前的版本开发二进制类库进行兼容。你无法在运行时访问到类型参数,因为编译器已经把泛型类型转换成了原始类型。
8.3 限定通配符
限定通配符对类型进行了限制。
Einer ist erweitert T>, der die Obergrenze des Typs festlegt, indem er sicherstellt, dass der Typ eine Unterklasse von T sein muss.
Der andere ist Typ, indem sichergestellt wird, dass der Typ eine Unterklasse der T-Elternklasse sein muss, um die untere Grenze des Typs festzulegen.
Andererseits stellt > einen unqualifizierten Platzhalter dar, da >
Liste erweitert Nummer> kann beispielsweise Liste oder Liste akzeptieren.
8.4 Fragen zum Generics-Interview
Können Sie eine Liste an eine Methode übergeben, die einen Listenparameter akzeptiert?
Für alle, die sich mit Generika nicht auskennen, mag diese Frage zu Java-Generika verwirrend erscheinen, denn auf den ersten Blick ist String eine Art Objekt, daher sollte List überall dort verwendet werden, wo List benötigt wird, aber das ist nicht der Fall Fall. Dies führt zu Kompilierungsfehlern. Wenn Sie weiter darüber nachdenken, werden Sie feststellen, dass dies für Java sinnvoll ist, da List jede Art von Objekt speichern kann, einschließlich String, Integer usw., List jedoch nur zum Speichern von Strings.
Können Generika in Arrays verwendet werden?
Array unterstützt eigentlich keine Generika, weshalb Joshua Bloch im Buch „Effective Java“ die Verwendung von List anstelle von Array vorgeschlagen hat, da List die Kompilierungszeit bereitstellen kann Typsicherheitsgarantien, Array dagegen nicht.
Was ist der Unterschied zwischen List und primitiven Typen List in Java?
Der Hauptunterschied zwischen primitiven Typen und parametrisierten Typen besteht darin, dass der Compiler die primitiven Typen zur Kompilierungszeit nicht auf Typsicherheit prüft , aber der Typ mit Parametern wird überprüft. Indem Sie Object als Typ verwenden, können Sie dem Compiler mitteilen, dass die Methode jeden Objekttyp akzeptieren kann, z. B. String oder Integer. Der Testpunkt dieser Frage liegt im richtigen Verständnis primitiver Typen in Generika. Der zweite Unterschied zwischen ihnen besteht darin, dass Sie jeden Typ mit Parametern an den primitiven Typ List übergeben können, aber Sie können keine List an eine Methode übergeben, die eine List akzeptiert, da sonst ein Kompilierungsfehler auftritt.
Liste> ist eine Liste unbekannten Typs, und Liste ist eigentlich eine Liste beliebigen Typs. Sie können Liste, Liste zu Liste> zuweisen, aber Sie können keine Liste zu Liste zuweisen.
9. Reflexion
9.1. Konzept
Für jede Klasse kann sie alle Eigenschaften und Methoden kennen. Für jedes Objekt kann jede seiner Methoden aufgerufen werden. Diese dynamische Erfassung von Informationen und die Funktion des dynamischen Aufrufs der Methoden des Objekts werden als Reflexionsmechanismus der Java-Sprache bezeichnet.
9.2. Funktion
Der Java-Reflektionsmechanismus bietet hauptsächlich die folgenden Funktionen: Bestimmen Sie die Klasse, zu der ein Objekt zur Laufzeit gehört Mitgliedsvariablen und Methoden einer Klasse; Aufrufen von Methoden eines beliebigen Objekts zur Laufzeit;
10. Agent
Jeder muss mit dem Wort Agent vertraut sein, da es in der Realität häufig verwendet wird. Tatsächlich können Dinge in der Realität den abstrakten Prozess sehr anschaulich und intuitiv widerspiegeln Muster und Natur. Ist das Haus jetzt nicht sehr laut? Nehmen wir ein Haus als Beispiel, um den Schleier der Entscheidungsfreiheit zu lüften.
Angenommen, Sie möchten ein Haus verkaufen, indem Sie die Verkaufsinformationen direkt online veröffentlichen und dann die Personen, die das Haus kaufen möchten, direkt dorthin bringen, um das Haus zu besichtigen, den Eigentumstitel zu übertragen usw. bis zum Das Haus ist verkauft, aber es kann für Sie schwierig sein, dies zu tun. Wenn Sie beschäftigt sind und keine Zeit haben, sich mit diesen Dingen zu befassen, können Sie sich an einen Vermittler wenden und sich von diesem bei der Abwicklung dieser trivialen Dinge helfen lassen. Der Vermittler ist eigentlich Ihr Agent. Ursprünglich mussten Sie das tun, aber jetzt hilft Ihnen der Vermittler einzeln bei der Abwicklung. Für den Käufer gibt es keinen Unterschied zwischen direkten Transaktionen mit Ihnen und direkten Transaktionen mit dem Vermittler Das ist eigentlich ein Teil der Agentur.
Lassen Sie uns als Nächstes ausführlich darüber nachdenken, warum Sie ein Haus nicht direkt kaufen, sondern einen Makler benötigen. Tatsächlich beantwortet eine Frage genau die Frage, wann der Proxy-Modus verwendet werden sollte.
Grund 1: Sie arbeiten möglicherweise außerhalb der Stadt und Hauskäufer können Sie für direkte Transaktionen nicht finden.
Entsprechend unserem Programmdesign gilt: Der Client kann das eigentliche Objekt nicht direkt bedienen. Warum kann das nicht direkt gemacht werden? Eine Situation besteht darin, dass sich das Objekt, das Sie aufrufen müssen, auf einem anderen Computer befindet und Sie über das Netzwerk darauf zugreifen müssen. Wenn Sie es direkt aufrufen, müssen Sie sich um Netzwerkverbindungen, Verpackung, Entpacken und andere sehr komplizierte Schritte kümmern. Um die Verarbeitung des Clients zu vereinfachen, verwenden wir den Proxy-Modus, um einen Proxy für das Remote-Objekt auf dem Client einzurichten. Der Client ruft den Proxy auf, genau wie beim Aufrufen des lokalen Objekts, und dann kontaktiert der Proxy das eigentliche Objekt Beim Client gibt es möglicherweise keine. Es fühlt sich an, als ob sich das aufgerufene Ding am anderen Ende des Netzwerks befindet. So funktioniert der Webdienst tatsächlich. In einem anderen Fall haben Sie Angst, Ihren normalen Betrieb zu beeinträchtigen, obwohl es sich bei dem Objekt, das Sie anrufen möchten, um ein lokales Objekt handelt Um zu verstehen, dass in Word ein großes Bild installiert ist, müssen wir den Inhalt laden und gemeinsam öffnen. Wenn der Benutzer jedoch wartet, bis das große Bild geladen ist, ist der Benutzer möglicherweise bereits gesprungen in der Warteschleife, damit wir einen Proxy einrichten und den Proxy das Bild langsam öffnen lassen können, ohne die ursprüngliche Öffnungsfunktion von Word zu beeinträchtigen. Lassen Sie mich klarstellen, dass ich nur vermutet habe, dass Word dies tun könnte. Ich weiß nicht genau, wie es gemacht wird.
Grund 2: Sie wissen nicht, wie Sie die Transferverfahren durchführen sollen, oder Sie müssen zusätzlich zu dem, was Sie jetzt tun können, noch andere Dinge tun, um Ihr Ziel zu erreichen.
Entspricht unserem Programmdesign: Zusätzlich zu den Funktionen, die die aktuelle Klasse bereitstellen kann, müssen wir auch einige andere Funktionen hinzufügen. Die einfachste Situation ist die Berechtigungsfilterung. Ich habe eine Klasse, die ein bestimmtes Geschäft ausführt, aber aus Sicherheitsgründen können nur bestimmte Benutzer diese Klasse aufrufen. Zu diesem Zeitpunkt können wir eine Proxy-Klasse dieser Klasse erstellen, die alle Anforderungen erfordert Durchlaufen Diese Proxy-Klasse führt eine Berechtigungsbeurteilung durch. Wenn dies sicher ist, wird das Geschäft der tatsächlichen Klasse aufgerufen, um mit der Verarbeitung zu beginnen. Manche Leute fragen sich vielleicht, warum ich eine zusätzliche Proxy-Klasse hinzufügen muss? Ich muss nur die Berechtigungsfilterung zur Methode der ursprünglichen Klasse hinzufügen, oder? Bei der Programmierung gibt es ein Problem des Einheitsprinzips von Klassen. Dieses Prinzip ist sehr einfach, das heißt, die Funktion jeder Klasse ist so einheitlich wie möglich. Warum sollte es Single sein? Da nur eine Klasse mit einer einzigen Funktion am wenigsten geändert wird. Wenn Sie das Berechtigungsurteil in die aktuelle Klasse einfügen, muss die aktuelle Klasse für ihre eigene Geschäftslogik verantwortlich sein , Auch für die Berechtigungsbeurteilung verantwortlich, gibt es zwei Gründe für die Änderung dieser Klasse. Wenn sich nun die Berechtigungsregeln ändern, muss diese Klasse offensichtlich nicht geändert werden.
Okay, ich habe fast über die Prinzipien gesprochen. Wenn ich noch lange darüber rede, werden vielleicht alle mit Ziegeln werfen. Haha, mal sehen, wie wir als nächstes die Agentur implementieren.
Datenstrukturen und Algorithmen
https://zhuanlan.zhihu.com/p/27005757?utm_source=weibo&utm_medium=social
http://crazyandcoder.tech/2016 /09/14/Android-Algorithmus und Datenstruktur – Sortierung/
1. Sortierung hat interne und externe Sortierung. Interne Sortierung bedeutet, dass Datensätze im Speicher sortiert werden, während externe Sortierung erfolgt Dies liegt daran, dass die sortierten Daten sehr groß sind und nicht alle sortierten Datensätze gleichzeitig aufnehmen können. Während des Sortiervorgangs muss auf externen Speicher zugegriffen werden.
1.1. Direkte Einfügungssortierung
Idee:
Sortieren Sie die erste Zahl und die zweite Zahl und bilden Sie dann eine geordnete Reihenfolge.
Sortieren Sie die dritte Zahl. Die Zahlen sind eingefügt, um eine neue geordnete Sequenz zu bilden.Wiederholen Sie den zweiten Schritt für die vierte Zahl, die fünfte Zahl ... bis zur letzten Zahl. 2.1. Singleton-Designmuster Funktionen: Singleton verhindert, dass die Klasse extern instanziiert wird, indem die Konstruktionsmethode auf privat beschränkt wird. Innerhalb derselben virtuellen Maschine kann die einzige Instanz von Singleton nur die Methode getInstance() übergeben . Zugang. (Tatsächlich ist es möglich, Klassen mit privaten Konstruktoren über den Java-Reflexionsmechanismus zu instanziieren, wodurch grundsätzlich alle Java-Singleton-Implementierungen ungültig werden.
Code:
Legen Sie zunächst die Anzahl der Einfügungen fest, dh die Anzahl der Schleifen. Für (int i=1;i
2. DesignmusterReferenz: Einige Designmuster in der Android-Entwicklung
Einzelfälle werden hauptsächlich unterteilt in: faule Leute Geben Sie Singleton ein, Singleton im hungrigen Stil, registrierter Singleton.
Lazy Singleton:
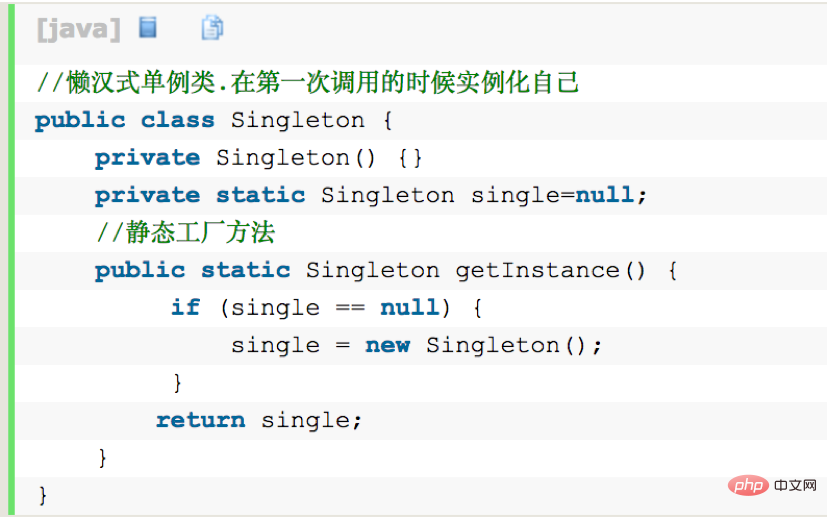
Es ist threadunsicher und gleichzeitig Es ist sehr wahrscheinlich, dass dort Um mehrere Singleton-Instanzen zu erreichen, gibt es drei Möglichkeiten:
1 Synchronisierung zur getInstance-Methode hinzufügen 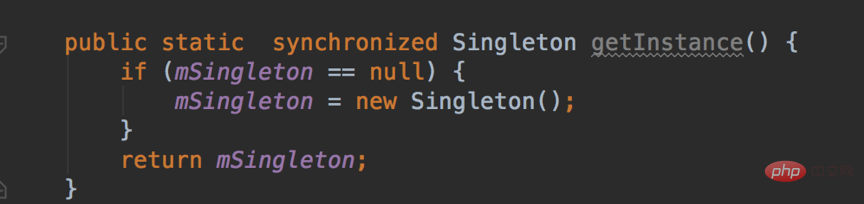
3. Statische innere Klasse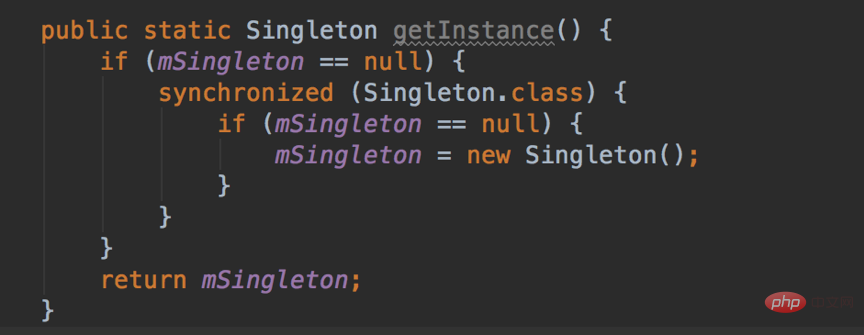
Im Vergleich zu den ersten beiden Methoden erreicht diese Methode nicht nur Thread-Sicherheit, sondern vermeidet auch die durch die Synchronisierung verursachten Leistungseinbußen >Hungry-Style-Singleton: 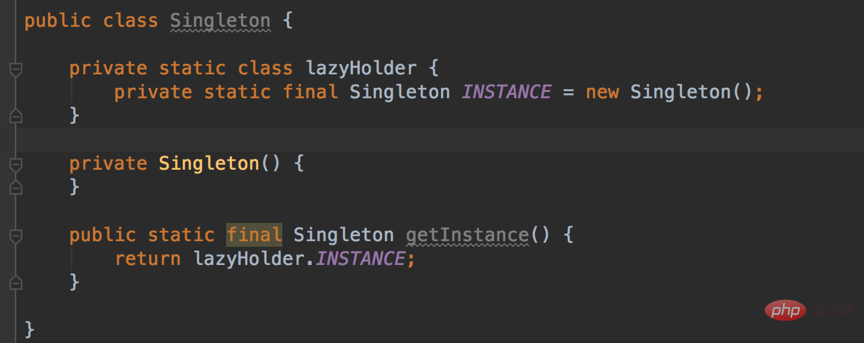 Hungry-style hat beim Erstellen der Klasse bereits ein statisches Objekt für die Systemverwendung erstellt und wird es in Zukunft nicht ändern, sodass es von Natur aus systemsicher ist >
Hungry-style hat beim Erstellen der Klasse bereits ein statisches Objekt für die Systemverwendung erstellt und wird es in Zukunft nicht ändern, sodass es von Natur aus systemsicher ist >
Das obige ist der detaillierte Inhalt vonDas ausführlichste Teilen von Android-Interviewfragen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Was ist Useffizität? Wie verwenden Sie es, um Nebenwirkungen auszuführen?
Mar 19, 2025 pm 03:58 PM
Was ist Useffizität? Wie verwenden Sie es, um Nebenwirkungen auszuführen?
Mar 19, 2025 pm 03:58 PM
In dem Artikel wird die Verwendung von UseEffect in React, einen Haken für die Verwaltung von Nebenwirkungen wie Datenabrufen und DOM -Manipulation in funktionellen Komponenten erläutert. Es erklärt die Verwendung, gemeinsame Nebenwirkungen und Reinigung, um Probleme wie Speicherlecks zu verhindern.
 Wie funktioniert der React -Versöhnungsalgorithmus?
Mar 18, 2025 pm 01:58 PM
Wie funktioniert der React -Versöhnungsalgorithmus?
Mar 18, 2025 pm 01:58 PM
Der Artikel erläutert den Versöhnungsalgorithmus von React, der das DOM effizient aktualisiert, indem virtuelle DOM -Bäume verglichen werden. Es werden Leistungsvorteile, Optimierungstechniken und Auswirkungen auf die Benutzererfahrung erörtert.
 Was sind Funktionen höherer Ordnung in JavaScript und wie können sie verwendet werden, um prägnanter und wiederverwendbarer Code zu schreiben?
Mar 18, 2025 pm 01:44 PM
Was sind Funktionen höherer Ordnung in JavaScript und wie können sie verwendet werden, um prägnanter und wiederverwendbarer Code zu schreiben?
Mar 18, 2025 pm 01:44 PM
Funktionen höherer Ordnung in JavaScript verbessern die Übersichtlichkeit, Wiederverwendbarkeit, Modularität und Leistung von Code durch Abstraktion, gemeinsame Muster und Optimierungstechniken.
 Wie funktioniert das Currying in JavaScript und wie hoch sind ihre Vorteile?
Mar 18, 2025 pm 01:45 PM
Wie funktioniert das Currying in JavaScript und wie hoch sind ihre Vorteile?
Mar 18, 2025 pm 01:45 PM
In dem Artikel wird das Currying in JavaScript, einer Technik, die Multi-Argument-Funktionen in Einzelargument-Funktionssequenzen verwandelt. Es untersucht die Implementierung von Currying, Vorteile wie teilweise Anwendungen und praktische Verwendungen, Verbesserung des Code -Lesens
 Wie verbinden Sie React -Komponenten mit Connect () an den Redux -Store?
Mar 21, 2025 pm 06:23 PM
Wie verbinden Sie React -Komponenten mit Connect () an den Redux -Store?
Mar 21, 2025 pm 06:23 PM
In Artikel werden die Verbindungskomponenten an Redux Store mit Connect () verbinden, wobei MapStatetoprops, MapDispatchtoprops und Leistungsauswirkungen erläutert werden.
 Was ist usecontext? Wie verwenden Sie es, um den Zustand zwischen Komponenten zu teilen?
Mar 19, 2025 pm 03:59 PM
Was ist usecontext? Wie verwenden Sie es, um den Zustand zwischen Komponenten zu teilen?
Mar 19, 2025 pm 03:59 PM
Der Artikel erläutert den Usecontext in React, was das staatliche Management durch Vermeidung von Prop -Bohrungen vereinfacht. Es wird von Vorteilen wie zentraler Staat und Leistungsverbesserungen durch reduzierte Neulehre erörtert.
 Wie verhindern Sie das Standardverhalten bei Ereignishandlern?
Mar 19, 2025 pm 04:10 PM
Wie verhindern Sie das Standardverhalten bei Ereignishandlern?
Mar 19, 2025 pm 04:10 PM
In Artikeln werden das Standardverhalten bei Ereignishandlern mithilfe von PURDDEFAULT () -Methoden, seinen Vorteilen wie verbesserten Benutzererfahrungen und potenziellen Problemen wie Barrierefreiheitsproblemen verhindern.
 Was sind die Vor- und Nachteile kontrollierter und unkontrollierter Komponenten?
Mar 19, 2025 pm 04:16 PM
Was sind die Vor- und Nachteile kontrollierter und unkontrollierter Komponenten?
Mar 19, 2025 pm 04:16 PM
Der Artikel erörtert die Vor- und Nachteile kontrollierter und unkontrollierter Komponenten bei React, wobei sich auf Aspekte wie Vorhersehbarkeit, Leistung und Anwendungsfälle konzentriert. Es rät zu Faktoren, die bei der Auswahl zwischen ihnen berücksichtigt werden müssen.
