

Organisieren Sie Fragen und Antworten zu Oracle-Interviews


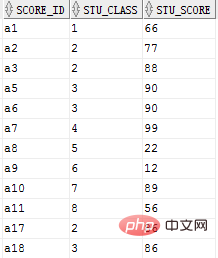
Die folgenden Fragen werden gemäß dieser Tabelle transformiert
Tabelle: Tabelle1 (FId, Fclass, Fscore), verwenden Die effizienteste und einfachste SQL-Anweisung listet die Liste der höchsten Noten in jeder Klasse auf und zeigt zwei Felder an: Klasse und Note.
select stu_class, max(stu_score) from core group by stu_class ;
2. Es gibt eine Tabelle table1 mit zwei Feldern FID und Fno. Beide Felder sind nicht leer. Schreiben Sie eine SQL-Anweisung, um die Datensätze in der Tabelle aufzulisten, die einer FID und mehreren verschiedenen Fnos entsprechen.
select t2.* from table1 t1, table1 t2 where t1.fid = t2.fid and t1.fno <> t2.fno;
Drei Möglichkeiten zu schreiben:
select * from core co1 where co1.STU_CLASS in ( select co.STU_CLASS from CORE co group by co.STU_CLASS having count(co.STU_CLASS) >1); select DISTINCT c2.* from core c1 ,core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE; SELECT * FROM core c1 where 1=1 and EXISTS (select 1 from core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE);
3. Es gibt eine Mitarbeitertabelle empinfo
( Fempno varchar2(10) not null pk, Fempname varchar2(20) not null, Fage number not null, Fsalary number not null );
Wenn die Datenmenge sehr groß ist, etwa 10 Millionen Teile ; Schreiben Sie eine SQL, die Ihrer Meinung nach die effizienteste ist. Verwenden Sie eine SQL, um die folgenden vier Arten von Personen zu berechnen:
fsalary>9999 and fage > 35 fsalary>9999 and fage < 35 fsalary <9999 and fage > 35 fsalary <9999 and fage < 35
Die Anzahl jeder Art von Mitarbeitern
select sum(case when fsalary > 9999 and fage > 35then 1else 0end) as "fsalary>9999_fage>35",sum(case when fsalary > 9999 and fage < 35then 1else 0end) as "fsalary>9999_fage<35",sum(case when fsalary < 9999 and fage > 35then 1else 0end) as "fsalary<9999_fage>35",sum(case when fsalary < 9999 and fage < 35then 1else 0end) as "fsalary<9999_fage<35"from empinfo;
month person income Monatliches Personaleinkommen
Es ist erforderlich, eine SQL-Anweisung zu verwenden (beachten Sie, dass es sich um eine handelt) das Gesamteinkommen des Eigentümers (nicht). Unterscheidung zwischen Personal) jeden Monat und den Vormonat und den Folgemonat
Die erforderliche Listenausgabe ist
Monat Einkommen des aktuellen Monats Einkommen des Vormonats Einkommen des nächsten Monats
select sum(case when stu_score < 60 then 1 else 0 end ) as "60分以下人数" ,sum(case when stu_score > 60 and stu_score <= 70 then 1 else 0 end ) as "60到70分人数" ,sum(case when stu_score > 70 and stu_score <= 80 then 1 else 0 end ) as "70到80分人数" ,sum(case when stu_score > 80 and stu_score <= 100 then 1 else 0 end ) as "80分以上人数" from core;
MONTHS PERSON INCOME ---------- ---------- ----------200807 mantisXF 5000200806 mantisXF2 3500200806 mantisXF3 3000200805 mantisXF1 2000200805 mantisXF6 2200200804 mantisXF7 1800200803 8mantisXF 4000200802 9mantisXF 4200200802 10mantisXF 3300200801 11mantisXF 4600200809 11mantisXF 6800
C1 c2
2005-01-01 1
2005 -01-01 3
2005-01-02 5
2005-01-01 4
2005-01-02 5
Gesamt 9
Versuchen Sie zum Vervollständigen eine SQL-Anweisung.
months, (incomes), (prev_months), (( ), ), ), lag(incomes) ( months), ) prev_months, decode(lead(months) ( months), to_char(add_months(to_date(months, ), ), ), lead(incomes) ( months), ) next_months ( months, (income) incomes a months) aa) aaagroup (INCOMES) (PREV_MONTHS) (NEXT_MONTHS)
führt kurz 1NF (erste Normalform), 2NF (zweite Normalform), 3NF (dritte Normalform),
erste Normalform (1NF) ein: jeden spezifischen Parameter im relationalen Modell R In eine Relation r, wenn jeder Attributwert die kleinste Dateneinheit ist, die nicht weiter unterteilt werden kann, dann wird R als Relation in erster Normalform bezeichnet.
Eine besteht darin, die Mitarbeiternummer und den Namen wiederholt zu speichern. In diesem Fall kann das Schlüsselwort nur eine Telefonnummer sein.
Zweitens ist die Mitarbeiternummer ein Schlüsselwort und die Telefonnummer ist in zwei Attribute unterteilt: geschäftliche Telefonnummer und private Telefonnummer.
Drittens ist die Mitarbeiternummer ein Schlüsselwort, aber das ist zwingend erforderlich Jeder Datensatz kann nur eine Telefonnummer enthalten.
Von den oben genannten drei Methoden ist die erste Methode die am wenigsten empfehlenswerte. Wählen Sie die beiden letztgenannten Fälle entsprechend der tatsächlichen Situation aus.
Beispiel: Kursauswahlbeziehung SCI (SNO, CNO, GRADE, CREDIT), wobei SNO die Studentennummer, CNO die Kursnummer, GRADEGE die Note und CREDIT die Credits ist. Basierend auf den oben genannten
Bedingungen ist das Schlüsselwort ein Kombinationsschlüsselwort (SNO, CNO)
Die Verwendung des obigen Beziehungsmodells in einer Anwendung führt zu folgenden Problemen:
a. vorausgesetzt, die gleiche Tür Der Kurs wird von 40 Studenten belegt und 40 Mal zur Anrechnung wiederholt.Grund: Das Nicht-Keyword-Attribut CREDIT hängt nur funktional von CNO ab, d. h. CREDIT hängt teilweise und nicht vollständig vom kombinierten Keyword (SNO, CNO) ab. Lösung: Aufteilung in zwei Beziehungsmodi SC1 (SNO, CNO, GRADE), C2 (CNO, CREDIT). Die neue Beziehung umfasst zwei Beziehungsmuster, die durch das Fremdschlüsselwort CNO vonb. Wenn die Credits eines bestimmten Kurses angepasst werden, wird der entsprechende Tupel-CREDIT-Wert aktualisiert und die Credits desselben Kurses können unterschiedlich sein.
c. Wenn Sie beispielsweise planen, einen neuen Kurs zu eröffnen, können Sie nur darauf warten, dass jemand daran teilnimmt, bevor Sie den Kurs hinterlegen können, da niemand daran teilnimmt und Credits.
d. Ausnahme löschen Wenn der Student den Kurs abgeschlossen hat, löschen Sie den Wahlfachdatensatz aus der aktuellen Datenbank. Wenn Studienanfänger einige Kurse noch nicht belegt haben, können die Kurs- und Leistungsnachweise nicht gespeichert werden.
in SCN verbunden sind. Bei Bedarf werden natürliche Verbindungen hergestellt, um die ursprüngliche Beziehung
wiederherzustellen: Wenn das Beziehungsmuster Alle nicht-primären Attribute in R (U, F) haben keine transitive Abhängigkeit von irgendeinem Kandidatenschlüsselwort, dann soll die Beziehung R zur dritten Normalform gehören.
Zum Beispiel: S1 (SNO, SNAME, DNO, DNAME, STANDORT) Jedes Attribut repräsentiert die Studentennummer,Name, Abteilung, Abteilungsname, Abteilungsadresse.
Das Schlüsselwort SNO bestimmt jedes Attribut. Da es sich um ein einzelnes Schlüsselwort handelt, besteht kein Problem einer teilweisen Abhängigkeit und es muss 2NF sein. In dieser Beziehung muss jedoch eine Menge Redundanz vorhanden sein. Mehrere
-Attribute DNO, DNAME und STANDORT, an dem sich der Schüler befindet, werden wiederholt gespeichert, eingefügt, gelöscht und geändert, und es treten ähnliche Situationen wie im obigen Beispiel auf.
Ursache: Es besteht eine transitive Abhängigkeit in der Beziehung. Das ist SNO -> DNO. Aber DNO -> SNO existiert nicht, DNO -> LOCATION, also ist der Schlüssel SNO vs. LOCATIO
N 函数决定是通过传递依赖 SNO -> LOCATION 实现的。也就是说,SNO不直接决定非主属性LOCATION。
解决目地:每个关系模式中不能留有传递依赖。
解决方法:分为两个关系 S(SNO,SNAME,DNO),D(DNO,DNAME,LOCATION)
注意:关系S中不能没有外关键字DNO。否则两个关系之间失去联系。
7,简述oracle行触发器的变化表限制表的概念和使用限制,行触发器里面对这两个表有什么限制。
变化表mutating table
被DML语句正在修改的表
需要作为DELETE CASCADE参考完整性限制的结果进行更新的表也是变化的
限制:对于Session本身,不能读取正在变化的表
限制表constraining table
需要对参考完整性限制执行读操作的表
限制:如果限制列正在被改变,那么读取或修改会触发错误,但是修改其它列是允许的。
8、oracle临时表有几种。
临时表和普通表的主要区别有哪些,使用临时表的主要原因是什么?
在Oracle中,可以创建以下两种临时表:
a。会话特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT PRESERVE ROWS;
b。事务特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT DELETE ROWS; CREATE GLOBAL TEMPORARY TABLE MyTempTable
所建的临时表虽然是存在的,但是你试一下insert 一条记录然后用别的连接登上去select,记录是空的,明白了吧。
下面两句话再贴一下:
ON COMMIT DELETE ROWS说明临时表是事务指定,每次提交后ORACLE将截断表(删除全部行)ON COMMIT PRESERVE ROWS说明临时表是会话指定,当中断会话时ORACLE将截断表。
9,怎么实现:使一个会话里面执行的多个过程函数或触发器里面都可以访问的全局变量的效果,并且要实现会话间隔离?
--个人理解就是建立一个包,将常量或所谓的全局变量用包中的函数返回出来就可以了,摘抄一短网上的解决方法Oracle数据库程序包中的变量,在本程序包中可以直接引用,但是在程序包之外,则不可以直接引用。对程序包变量的存取,可以为每个变量配套相应的存储过程<用于存储数据>和函数<用于读取数据>来实现。 3.2 实例 --定义程序包 create or replace package PKG_System_Constant is C_SystemTitle nVarChar2(100):='测试全局程序变量'; --定义常数 --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2; G_CurrentDate Date:=SysDate; --定义全局变量 --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date); End PKG_System_Constant; / create or replace package body PKG_System_Constant is --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2 Is Begin Return C_SystemTitle; End FN_GetSystemTitle; --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date Is Begin Return G_CurrentDate; End FN_GetCurrentDate; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date) Is Begin G_CurrentDate:=P_CurrentDate; End SP_SetCurrentDate; End PKG_System_Constant; / 3.3 测试 --测试读取常数 Select PKG_System_Constant.FN_GetSystemTitle From Dual; --测试设置全局变量 Declare Begin PKG_System_Constant.SP_SetCurrentDate(To_Date('2001.01.01','yyyy.mm.dd')); End; / --测试读取全局变量 Select PKG_System_Constant.FN_GetCurrentDate From Dual;
10,aa,bb表都有20个字段,且记录数量都很大,aa,bb表的X字段(非空)上有索引,
请用SQL列出aa表里面存在的X在bb表不存在的X的值,请写出认为最快的语句,并解译原因。
select aa.x from aa where not exists (select 'x' from bb where aa.x = bb.x) ;
以上语句同时使用到了aa中x的索引和的bb中x的索引
11,简述SGA主要组成结构和用途?
SGA是Oracle为一个实例分配的一组共享内存缓冲区,它包含该实例的数据和控制信息。SGA在实例启动时被自动分配,当实例关闭时被收回。数据库的所有数据操作都要通过SGA来进行。
SGA中内存根据存放信息的不同,可以分为如下几个区域:
a.Buffer Cache:存放数据库中数据库块的拷贝。它是由一组缓冲块所组成,这些缓冲块为所有与该实例相链接的用户进程所共享。缓冲块的数目由初始化参数DB_BLOCK_BUFFERS确定,缓冲块的大小由初始化参数DB_BLOCK_SIZE确定。大的数据块可提高查询速度。它由DBWR操作。
b. 日志缓冲区Redo Log Buffer:存放数据操作的更改信息。它们以日志项(redo entry)的形式存放在日志缓冲区中。当需要进行数据库恢复时,日志项用于重构或回滚对数据库所做的变更。日志缓冲区的大小由初始化参数LOG_BUFFER确定。大的日志缓冲区可减少日志文件I/O的次数。后台进程LGWR将日志缓冲区中的信息写入磁盘的日志文件中,可启动ARCH后台进程进行日志信息归档。
c. 共享池Shared Pool:包含用来处理的SQL语句信息。它包含共享SQL区和数据字典存储区。共享SQL区包含执行特定的SQL语句所用的信息。数据字典区用于存放数据字典,它为所有用户进程所共享。
12什么是分区表?简述范围分区和列表分区的区别,分区表的主要优势有哪些?
使用分区方式建立的表叫分区表
范围分区
每个分区都由一个分区键值范围指定(对于一个以日期列作为分区键的表,“2005 年 1 月”分区包含分区键值为从“2005 年 1 月 1 日”
到“2005 年 1 月 31 日”的行)。
列表分区
每个分区都由一个分区键值列表指定(对于一个地区列作为分区键的表,“北美”分区可能包含值“加拿大”“美国”和“墨西哥”)。
分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务。通过分区,数据库设计人员和管理员能够解决前沿应用程序带来的一些难题。分区是构建千兆字节数据系统或超高可用性系统的关键工具。
13. Hintergrund: Bestimmte Daten werden im Archivprotokoll ausgeführt und RMAN wurde verwendet, um eine vollständige Sicherung und Kaltsicherung der Datenbank durchzuführen.
Jetzt sind alle Steuerdateien beschädigt Alle anderen Dateien sind intakt. Was ist das Problem? Wie kann ich die Datenbank wiederherstellen? Nennen Sie mir eine oder zwei Methoden.
Antwortmethode:
1. Verwenden Sie eine Kaltsicherung, KOPIEREN Sie alle Kaltsicherungsdateien direkt in das Originalverzeichnis und starten Sie dann die Datenbank neu
2. Verwenden Sie Archivprotokolle,
Starten Sie die Datenbank NOMOUNT
Erstellen Sie eine Steuerdatei, die den Speicherort der Datendateien und Redo-Log-Dateien angibt.
Verwenden Sie den Befehl RECOVER DATABASE using backup controlfile Until cancel, um die Datenbank wiederherzustellen. Zu diesem Zeitpunkt können Sie Archivprotokolle verwenden
ALETER DATABASE OPEN RESETLOGS;
-
Sichern Sie die Datenbank und die Steuerdateien erneut
14. Verwenden Sie rman, um eine Sicherungsanweisung zu schreiben: Backup Table Space TSB, Level 2 Inkrementelle Sicherung.
15, es gibt eine Tabelle a(x Zahl(20),y Zahl(20)), die das schnellste und effizienteste SQL verwendet, um 10 Millionen aufeinanderfolgende Datensätze, beginnend bei 1, in die Tabelle einzufügen.
Verwandte Lernempfehlungen: Oracle-Datenbank-Lerntutorial
[Themenempfehlung]: Zusammenfassung der Oracle-Interviewfragen 2020 ( Neueste )
Das obige ist der detaillierte Inhalt vonOrganisieren Sie Fragen und Antworten zu Oracle-Interviews. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Wie erstelle ich Benutzer und Rollen in Oracle?
Mar 17, 2025 pm 06:41 PM
Wie erstelle ich Benutzer und Rollen in Oracle?
Mar 17, 2025 pm 06:41 PM
In dem Artikel wird erläutert, wie Benutzer und Rollen in Oracle mithilfe von SQL -Befehlen erstellt werden, und erörtert Best Practices für die Verwaltung von Benutzerberechtigungen, einschließlich der Verwendung von Rollen, nach dem Prinzip der geringsten Privilegien und regelmäßigen Audits.
 Wie konfiguriere ich die Verschlüsselung in Oracle mithilfe der transparenten Datenverschlüsselung (TDE)?
Mar 17, 2025 pm 06:43 PM
Wie konfiguriere ich die Verschlüsselung in Oracle mithilfe der transparenten Datenverschlüsselung (TDE)?
Mar 17, 2025 pm 06:43 PM
Der Artikel beschreibt Schritte zur Konfiguration der transparenten Datenverschlüsselung (TDE) in Oracle, detaillierte Brieftaschenerstellung, Ermöglichung von TDE und Datenverschlüsselung auf verschiedenen Ebenen. Es wird auch die Vorteile von TDE wie Datenschutz und Konformität und wie man veri erörtert, erörtert
 Wie führe ich Online -Backups in Oracle mit minimalen Ausfallzeiten durch?
Mar 17, 2025 pm 06:39 PM
Wie führe ich Online -Backups in Oracle mit minimalen Ausfallzeiten durch?
Mar 17, 2025 pm 06:39 PM
In dem Artikel werden Methoden zur Durchführung von Online -Backups in Oracle mit minimalen Ausfallzeiten mit RMAN, Best Practices zur Reduzierung der Ausfallzeit, der Gewährleistung der Datenkonsistenz und der Überwachung der Sicherungsträger erörtert.
 Wie verwende ich das automatische Workload Repository (AWR) und den automatischen Datenbankdiagnosemonitor (AddM) in Oracle?
Mar 17, 2025 pm 06:44 PM
Wie verwende ich das automatische Workload Repository (AWR) und den automatischen Datenbankdiagnosemonitor (AddM) in Oracle?
Mar 17, 2025 pm 06:44 PM
In dem Artikel wird erläutert, wie die AWR von Oracle und Addm für die Optimierung der Datenbankleistung verwendet werden. Es wird beschrieben, dass AWR -Berichte generiert und analysiert werden sowie AddM zur Identifizierung und Lösung von Leistung Engpässen verwenden.
 Oracle PL/SQL Deep Dive: Mastering -Verfahren, Funktionen und Pakete
Apr 03, 2025 am 12:03 AM
Oracle PL/SQL Deep Dive: Mastering -Verfahren, Funktionen und Pakete
Apr 03, 2025 am 12:03 AM
Die Prozeduren, Funktionen und Pakete in OraclePl/SQL werden verwendet, um Operationen, Rückgabeteile bzw. den Code zu organisieren. 1. Der Prozess wird verwendet, um Operationen wie die Ausgabe von Grüßen auszuführen. 2. Die Funktion wird verwendet, um einen Wert zu berechnen und zurückzugeben, z. B. die Berechnung der Summe von zwei Zahlen. 3. Pakete werden verwendet, um relevante Elemente zu organisieren und die Modularität und Wartbarkeit des Codes zu verbessern, z. B. Pakete, die das Inventar verwalten.
 Oracle Goldengate: Replikation und Integration in Echtzeitdaten
Apr 04, 2025 am 12:12 AM
Oracle Goldengate: Replikation und Integration in Echtzeitdaten
Apr 04, 2025 am 12:12 AM
OracleGoldEngate ermöglicht die Replikation und Integration von Echtzeit, indem die Transaktionsprotokolle der Quelldatenbank erfasst und Änderungen in der Zieldatenbank angewendet werden. 1) Änderungen erfassen: Lesen Sie das Transaktionsprotokoll der Quelldatenbank und konvertieren Sie sie in eine Trail -Datei. 2) Übertragungsänderungen: Übertragung auf das Zielsystem über das Netzwerk und die Übertragung wird unter Verwendung eines Datenpumpenprozesses verwaltet. 3) Anwendungsänderungen: Im Zielsystem liest der Kopiervorgang die Trail -Datei und wendet Änderungen an, um die Datenkonsistenz sicherzustellen.
 Wie führe ich Umschalt- und Failover -Operationen in Oracle Data Guard durch?
Mar 17, 2025 pm 06:37 PM
Wie führe ich Umschalt- und Failover -Operationen in Oracle Data Guard durch?
Mar 17, 2025 pm 06:37 PM
Der Artikel beschreibt Verfahren für Umschleppen und Failover in Oracle Data Guard und betont ihre Unterschiede, Planungen und Tests, um den Datenverlust zu minimieren und reibungslose Vorgänge zu gewährleisten.
 So überprüfen Sie die Tabellenraumgröße von Oracle
Apr 11, 2025 pm 08:15 PM
So überprüfen Sie die Tabellenraumgröße von Oracle
Apr 11, 2025 pm 08:15 PM
Um die Oracle -Tablespace -Größe abzufragen, führen Sie die folgenden Schritte aus: Bestimmen Sie den Namen Tablespace, indem Sie die Abfrage ausführen: Wählen Sie Tablespace_Name aus dba_tablespaces. Abfragen Sie die Tablespace -Größe durch Ausführen der Abfrage: Summe (Bytes) als Total_Size, sum (bytes_free) als verfügbare_space, sum
