
 Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der Methode zum Crawlen von 51cto-Daten in Python und zum Speichern dieser in MySQL
Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der Methode zum Crawlen von 51cto-Daten in Python und zum Speichern dieser in MySQL
Detaillierte Erläuterung der Methode zum Crawlen von 51cto-Daten in Python und zum Speichern dieser in MySQL

?? Installieren Sie die Umgebung und Module
 Bitte beachten Sie https://www.jb51.net/article/194104.htm
Bitte beachten Sie https://www.jb51.net/article/194104.htm
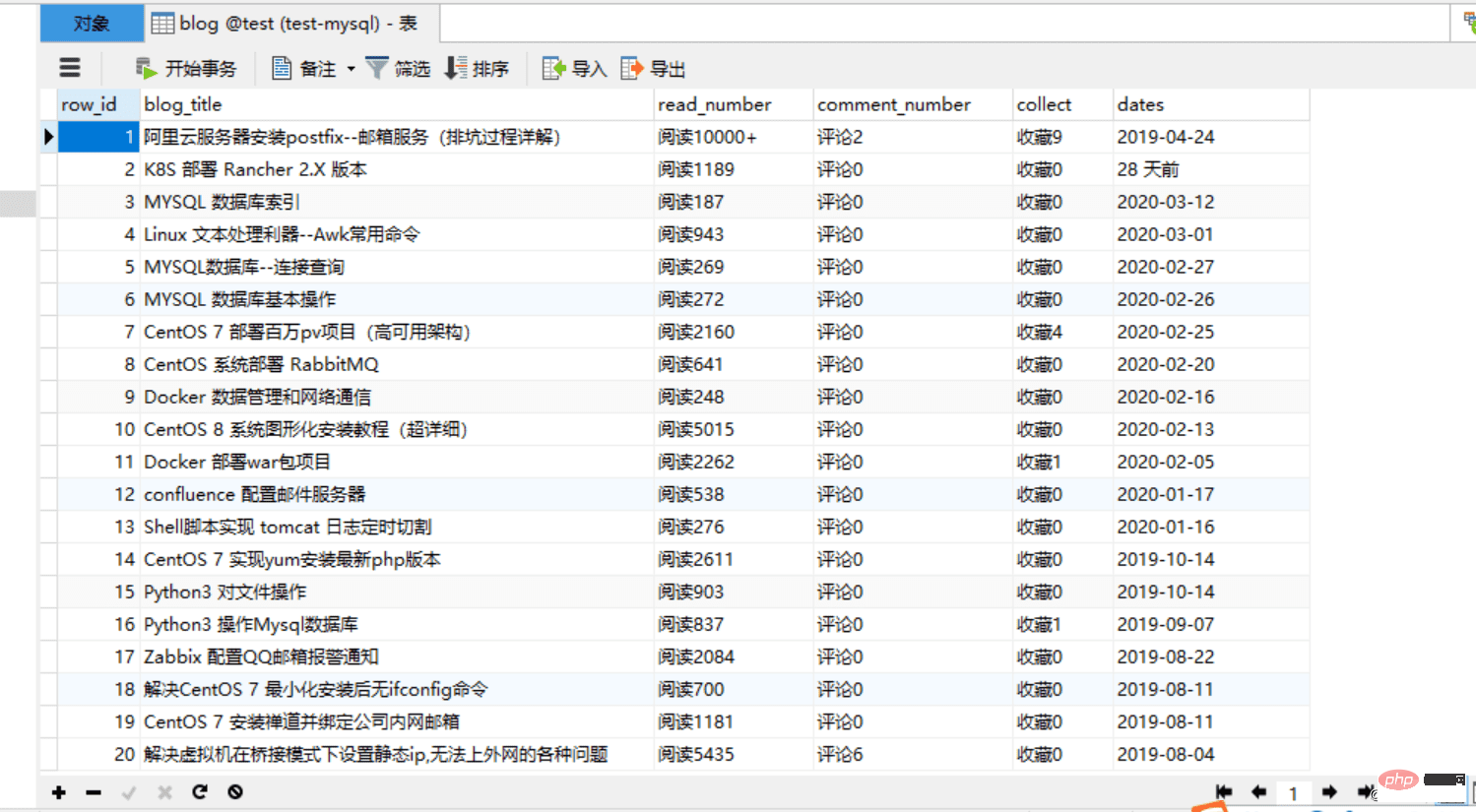
4 und sehen Sie sich den Effekt an:
Verbesserte Version:
1. Einige Felder in der Datenbank können nur Zahlen speichern
2 Standardmäßig besteht der gecrawlte Inhalt aus Zeichenfolgen, in denen einige gespeichert sind Felder der Datenbank. Es ist am besten, sie in einen Ganzzahltyp zu ändern.1 Der Code lautet wie folgt:  rrree
rrree
 Um es Anfängern zu erleichtern Mit diesem Programm können Sie dieses Projekt in eine Datei im Exe-Format packen, sodass andere den Code auf einem Computer ausführen können, was sehr praktisch ist!
Um es Anfängern zu erleichtern Mit diesem Programm können Sie dieses Projekt in eine Datei im Exe-Format packen, sodass andere den Code auf einem Computer ausführen können, was sehr praktisch ist!
1. Verbessern Sie den Code:
rrree2. Installieren Sie das Paketierungsmodul pyinstaller
5. Führen Sie das Exe-Paket aus und überprüfen Sie die Wirkung. Überprüfen Sie die Datenbank. Verwandte Lernempfehlungen:
MySQL-Tutorial
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Methode zum Crawlen von 51cto-Daten in Python und zum Speichern dieser in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
Die Hauptaufgabe von MySQL in Webanwendungen besteht darin, Daten zu speichern und zu verwalten. 1.Mysql verarbeitet effizient Benutzerinformationen, Produktkataloge, Transaktionsunterlagen und andere Daten. 2. Durch die SQL -Abfrage können Entwickler Informationen aus der Datenbank extrahieren, um dynamische Inhalte zu generieren. 3.Mysql arbeitet basierend auf dem Client-Server-Modell, um eine akzeptable Abfragegeschwindigkeit sicherzustellen.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 Wie man Python mit Notepad leitet
Apr 16, 2025 pm 07:33 PM
Wie man Python mit Notepad leitet
Apr 16, 2025 pm 07:33 PM
Das Ausführen von Python-Code in Notepad erfordert, dass das ausführbare Python-ausführbare Datum und das NPPEXEC-Plug-In installiert werden. Konfigurieren Sie nach dem Installieren von Python und dem Hinzufügen des Pfades den Befehl "Python" und den Parameter "{current_directory} {file_name}" im NPPExec-Plug-In, um Python-Code über den Shortcut-Taste "F6" in Notoza auszuführen.
 Lösen Sie das Datenbankverbindungsproblem: Ein praktischer Fall der Verwendung von Minii/DB -Bibliothek
Apr 18, 2025 am 07:09 AM
Lösen Sie das Datenbankverbindungsproblem: Ein praktischer Fall der Verwendung von Minii/DB -Bibliothek
Apr 18, 2025 am 07:09 AM
Bei der Entwicklung einer kleinen Anwendung stieß ich auf ein kniffliges Problem: die Notwendigkeit, eine leichte Datenbankbetriebsbibliothek schnell zu integrieren. Nachdem ich mehrere Bibliotheken ausprobiert hatte, stellte ich fest, dass sie entweder zu viel Funktionalität haben oder nicht sehr kompatibel sind. Schließlich fand ich Minii/DB, eine vereinfachte Version basierend auf YII2, die mein Problem perfekt löste.
 Beispiel für Laravel -Einführung
Apr 18, 2025 pm 12:45 PM
Beispiel für Laravel -Einführung
Apr 18, 2025 pm 12:45 PM
Laravel ist ein PHP -Framework zum einfachen Aufbau von Webanwendungen. Es bietet eine Reihe leistungsstarker Funktionen, darunter: Installation: Installieren Sie die Laravel CLI weltweit mit Komponisten und erstellen Sie Anwendungen im Projektverzeichnis. Routing: Definieren Sie die Beziehung zwischen der URL und dem Handler in Routen/Web.php. Ansicht: Erstellen Sie eine Ansicht in Ressourcen/Ansichten, um die Benutzeroberfläche der Anwendung zu rendern. Datenbankintegration: Bietet eine Out-of-the-Box-Integration in Datenbanken wie MySQL und verwendet Migration, um Tabellen zu erstellen und zu ändern. Modell und Controller: Das Modell repräsentiert die Datenbankentität und die Controller -Prozesse HTTP -Anforderungen.
 Golang vs. Python: Parallelität und Multithreading
Apr 17, 2025 am 12:20 AM
Golang vs. Python: Parallelität und Multithreading
Apr 17, 2025 am 12:20 AM
Golang eignet sich besser für hohe Parallelitätsaufgaben, während Python mehr Vorteile bei der Flexibilität hat. 1. Golang behandelt die Parallelität effizient über Goroutine und Kanal. 2. Python stützt sich auf Threading und Asyncio, das von GIL betroffen ist, jedoch mehrere Parallelitätsmethoden liefert. Die Wahl sollte auf bestimmten Bedürfnissen beruhen.
