

Detaillierte Erläuterung des LRU-Algorithmus von Redis

In der Spalte Redis-Tutorial wird der LRU-Algorithmus von Redis unten ausführlich erläutert. Ich hoffe, dass er Freunden in Not hilfreich sein wird!

Der LRU-Algorithmus von Redis
Die Idee hinter dem LRU-Algorithmus ist in der Informatik allgegenwärtig und dem „Lokalitätsprinzip“ des Programms sehr ähnlich. Obwohl es in einer Produktionsumgebung Redis-Speichernutzungsalarme gibt, ist es dennoch von Vorteil, die Cache-Nutzungsstrategie von Redis zu verstehen. Das Folgende ist die Redis-Nutzungsstrategie in der Produktionsumgebung: Der maximal verfügbare Speicher ist auf 4 GB begrenzt und die Löschstrategie allkeys-lru wird übernommen. Die sogenannte Löschstrategie: Wenn die Redis-Nutzung den maximalen Speicher erreicht hat, z. B. 4 GB, und zu diesem Zeitpunkt ein neuer Schlüssel zu Redis hinzugefügt wird, wählt Redis einen Schlüssel zum Löschen aus. Wie wählt man also den passenden Schlüssel zum Löschen aus?
CONFIG GET maxmemory
- "maxmemory"
- "4294967296"
CONFIG GET maxmemory-policy
- "maxmemory-policy"
- "allkeys-lru"
In der offiziellen Dokumentation Using Redis as In der Beschreibung eines LRU-Caches werden mehrere Löschstrategien bereitgestellt, wie z. B. allkeys-lru, volatile-lru usw. Meiner Meinung nach sollten bei der Auswahl drei Faktoren berücksichtigt werden: Zufälligkeit, die Zeit, zu der kürzlich auf den Schlüssel zugegriffen wurde, und die Ablaufzeit (TTL) des Schlüssels " Schlüssel, entfernen Sie den „ältesten“ Schlüssel. Hinweis: Ich habe hier Anführungszeichen hinzugefügt. Tatsächlich ist es in der spezifischen Implementierung von Redis sehr kostspielig, die aktuelle Zugriffszeit aller Schlüssel zu zählen. Denken Sie darüber nach, wie geht das?
Entfernen Sie Schlüssel, indem Sie zuerst versuchen, die weniger kürzlich verwendeten (LRU) Schlüssel zu entfernen, um Platz für die neu hinzugefügten Daten zu schaffen.
Ein weiteres Beispiel: allkeys-random, bei dem ein Schlüssel zufällig ausgewählt und entfernt wird .Schlüssel nach dem Zufallsprinzip entfernen, um Platz für die neu hinzugefügten Daten zu schaffen.
Ein weiteres Beispiel: volatile-lru, das nur diejenigen Schlüssel entfernt, deren Ablaufzeit mit dem Befehl „expire“ festgelegt wurde, und diese gemäß dem LRU-Algorithmus entfernt.Entfernen Sie Schlüssel, indem Sie zuerst versuchen, die weniger kürzlich verwendeten (LRU) Schlüssel zu entfernen, aber nur unter den Schlüsseln, die über einen
Ablaufsatz
verfügen, um Platz für die neu hinzugefügten Daten zu schaffen.Entfernen Sie Schlüssel mit einemEin weiteres Beispiel: volatile- ttl, es werden nur die Schlüssel entfernt, deren Ablaufzeit mit dem Befehl „expire“ festgelegt wurde. Der Schlüssel hat eine kürzere Überlebenszeit (je kleiner der TTL-SCHLÜSSEL), der zuerst entfernt wird.
Ablaufsatz
und versuchen Sie zuerst, Schlüssel mit einer kürzeren Lebensdauer (TTL) zu entfernen, um Platz für die neu hinzugefügten Daten zu schaffen.Welche sollte ich anwenden, da es so viele Strategien gibt? Dies betrifft das Zugriffsmuster (Zugriffsmuster) des Schlüssels in Redis. Das Zugriffsmuster hängt beispielsweise mit der Geschäftslogik des Codes zusammen. Auf Schlüssel, die bestimmte Merkmale erfüllen, wird häufig zugegriffen, während andere Schlüssel selten verwendet werden. Wenn unsere Anwendung auf alle Schlüssel gleich zugreifen kann, folgt ihr Zugriffsmuster einer gleichmäßigen Verteilung, und in den meisten Fällen folgt das Zugriffsmuster der Potenzgesetzverteilung (Potenzgesetzverteilung). Schlüsselmuster können sich auch im Laufe der Zeit ändern, daher ist eine geeignete Löschstrategie erforderlich, um verschiedene Situationen zu erfassen (zu erfassen). Unter der Stromverteilung ist LRU eine gute Strategie:flüchtige Strategie (Eviction-Methoden) Schlüssel sind diejenigen, für die eine Ablaufzeit festgelegt ist. In der redisDb-Struktur wird ein Wörterbuch (dict) mit dem Namen „expires“ definiert, um alle Schlüssel zu speichern, deren Ablaufzeit mit dem Befehl „expire“ festgelegt wird. Die Schlüssel des „expires“-Wörterbuchs verweisen auf den Schlüsselraum der Redis-Datenbank (redisServer--->redisDb --->redisObject) und der Wert des Expires-Wörterbuchs ist die Ablaufzeit dieses Schlüssels (lange Ganzzahl). Eine zusätzliche Erwähnung: Der Schlüsselraum der Redis-Datenbank bezieht sich auf: einen Zeiger mit dem Namen „dict“, der in der Struktur redisDb definiert ist und vom Typ Hash-Wörterbuch ist und zum Speichern jedes Schlüsselobjekts in der Redis-Datenbank und des entsprechenden Wertobjekts verwendet wird.
Obwohl Caches die Zukunft nicht vorhersagen können, können sie auf folgende Weise argumentieren:
Schlüssel, die wahrscheinlich erneut angefordert werden, sind Schlüssel, die kürzlich häufig angefordert wurden
Zweite Methode: Aus einer anderen Perspektive zeichnen Sie nicht den spezifischen Zugriffszeitpunkt (Unix-Zeitstempel) auf, sondern die Leerlaufzeit: Je kleiner die Leerlaufzeit, desto kleiner ist die Leerlaufzeit, was bedeutet, dass kürzlich darauf zugegriffen wurde.
Verwenden Sie hier a doppelt Verknüpfte Liste zum Verknüpfen aller Schlüssel. Wenn auf einen Schlüssel zugegriffen wird, verschieben Sie ihn an den Anfang der verknüpften Liste. Wenn Sie einen Schlüssel entfernen möchten, entfernen Sie ihn direkt vom Ende der Liste.Der LRU-Algorithmus entfernt den zuletzt verwendeten Schlüssel, d Der Zugriff erfolgt alle 2 Sekunden. Auf C und D wird alle 10 Sekunden zugegriffen. (Eine Tilde stellt 1 s dar), wie aus dem obigen Bild ersichtlich ist: Die Leerlaufzeit von A beträgt 2 s, die Leerlaufzeit von B beträgt 1 s, die Leerlaufzeit von C beträgt 5 s, D ist gerade besucht, daher beträgt die Leerlaufzeit 0 s
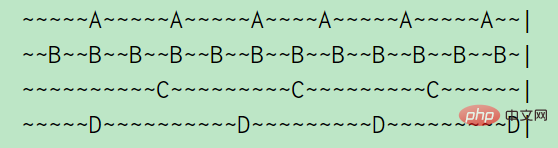
Aber in Redis ist es nicht auf diese Weise implementiert. Es wird angenommen, dass LinkedList zu viel Platz einnimmt. Redis implementiert die KV-Datenbank nicht direkt basierend auf Datenstrukturen wie Zeichenfolgen, verknüpften Listen und Wörterbüchern. Stattdessen erstellt es ein Objektsystem Redis-Objekt basierend auf diesen Datenstrukturen. In der redisObject-Struktur ist ein 24-Bit-Feld vom Typ ohne Vorzeichen definiert, um den Zeitpunkt zu speichern, zu dem das Befehlsprogramm zuletzt auf das Objekt zugegriffen hat:
Durch eine kleine Änderung der Redis-Objektstruktur konnte ich dort 24 Bit Platz schaffen Es gab keinen Platz für die Verknüpfung der Objekte in einer verknüpften Liste (fette Zeiger!)
Schließlich ist kein vollständig genauer LRU-Algorithmus erforderlich. Selbst wenn ein kürzlich aufgerufener Schlüssel entfernt wird, sind die Auswirkungen nicht erheblich.
Das Hinzufügen einer weiteren Datenstruktur zur Aufnahme dieser Metadaten war keine Option. Da LRU jedoch selbst eine Annäherung an das ist, was wir erreichen möchten, wie wäre es dann mit der Annäherung an LRU selbst?
Ursprünglich wurde Redis folgendermaßen implementiert:
Zufällig Wählen Sie drei Schlüssel aus und entfernen Sie den Schlüssel mit der längsten Leerlaufzeit. Später wurde 3 in einen konfigurierbaren Parameter geändert und der Standardwert war N=5:
Wenn ein Schlüssel entfernt werden soll, wählen Sie 3 zufällige Schlüssel aus und entfernen Sie den Schlüssel mit der höchsten Leerlaufzeit
maxmemory-samples 5So einfach ist das , es ist unglaublich einfach und sehr effektiv. Es weist jedoch immer noch Mängel auf: Bei jeder zufälligen Auswahl werden „historische Informationen“ nicht verwendet. Wenn Sie in jeder Runde einen Schlüssel entfernen (vertreiben), wählen Sie zufällig einen Schlüssel aus N aus und entfernen Sie in der nächsten Runde zufällig einen Schlüssel aus N ... Haben Sie darüber nachgedacht? Beim Entfernen von Schlüsseln in der letzten Runde kannten wir tatsächlich die Leerlaufzeit von N Schlüsseln. Kann ich einige der Informationen, die ich in der vorherigen Runde gelernt habe, beim Entfernen von Schlüsseln in der nächsten Runde sinnvoll nutzen?
Wenn Sie jedoch über die Ausführungen dieses Algorithmus nachdenken, können Sie sehen, wie wir viele interessante Daten vernichten. Vielleicht stoßen wir beim Abtasten der N-Schlüssel auf viele gute Kandidaten, die wir dann aber einfach entfernen Am besten, und fangen Sie im nächsten Zyklus wieder von vorne an.
Von vorne anfangen ist so albern. Deshalb hat Redis eine weitere Verbesserung vorgenommen: Verwenden von Pufferpooling (Pooling)Wenn der Schlüssel in jeder Runde entfernt wird, wird die Leerlaufzeit dieser N Schlüssel ermittelt, wenn seine Leerlaufzeit größer als die Leerlaufzeit des Schlüssels im Pool ist es ist groß, fügen Sie es dem Pool hinzu. Auf diese Weise ist der jedes Mal entfernte Schlüssel nicht nur der größte unter den N zufällig ausgewählten Schlüsseln, sondern auch die längste Leerlaufzeit im Pool, und: Der Schlüssel im Pool wurde durch mehrere Vergleichsrunden überprüft und ist im Leerlauf Zeit Die Zeit ist wahrscheinlich größer als die Leerlaufzeit eines zufällig erhaltenen Schlüssels. Dies kann wie folgt verstanden werden: Der Schlüssel im Pool behält „historische Erfahrungsinformationen“.
Grundsätzlich wurde die N-Schlüssel-Probenahme dazu verwendet, einen größeren Schlüsselpool zu füllen (standardmäßig nur 16 Schlüssel). In diesem Pool sind die Schlüssel nach Leerlaufzeit sortiert, sodass neue Schlüssel nur dann in den Pool gelangen, wenn sie vorhanden sind eine Leerlaufzeit von mehr als einem Schlüssel im Pool oder wenn im Pool leerer Platz vorhanden ist.
Mit „pool“ wird ein globales Sortierproblem in ein lokales Vergleichsproblem umgewandelt. (Obwohl das Sortieren im Wesentlichen ein Vergleich ist, 囧). Um den Schlüssel mit der längsten Leerlaufzeit zu ermitteln, muss eine genaue LRU die Leerlaufzeit der globalen Schlüssel sortieren und dann den Schlüssel mit der längsten Leerlaufzeit finden. Es kann jedoch eine ungefähre Idee übernommen werden, nämlich das zufällige Abtasten mehrerer Schlüssel, die globale Schlüssel darstellen, das Einfügen der durch Abtasten erhaltenen Schlüssel in den Pool und das Aktualisieren des Pools nach jeder Abtastung, sodass die Schlüssel im Pool vorhanden sind mit der größten Leerlaufzeit unter den zufällig ausgewählten Schlüsseln werden immer gespeichert. Wenn ein Räumungsschlüssel benötigt wird, nehmen Sie den Schlüssel mit der längsten Leerlaufzeit direkt aus dem Pool und entfernen Sie ihn. Es lohnt sich, von dieser Idee zu lernen.
An diesem Punkt ist die Analyse der LRU-basierten Entfernungsstrategie abgeschlossen. Es gibt auch eine Entfernungsstrategie basierend auf LFU (Zugriffsfrequenz) in Redis, auf die ich später noch eingehen werde.
LRU-Implementierung in JAVA
LinkedHashMap in JDK implementiert den LRU-Algorithmus unter Verwendung der folgenden Konstruktionsmethode: accessOrder stellt das Maß „zuletzt verwendet“ dar. Wenn beispielsweise accessOrder=true das Element java.util.LinkedHashMap#get ausführt, bedeutet dies, dass kürzlich auf dieses Element zugegriffen wurde.
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}Umschreiben: java.util.LinkedHashMap#removeEldestEntry-Methode.
Die Methode {@link #removeEldestEntry(Map.Entry)} kann überschrieben werden, um eine Richtlinie zum automatischen Entfernen veralteter Zuordnungen festzulegen, wenn der Karte neue Zuordnungen hinzugefügt werden.
Um die Thread-Sicherheit zu gewährleisten, verwenden Sie Sammlungen. synchronisiertMap LinkedHashMap-Objektumbrüche:
Beachten Sie, dass diese Implementierung nicht synchronisiert ist. Wenn mehrere Threads gleichzeitig auf eine verknüpfte Hash-Map zugreifen und mindestens einer der Threads die Map strukturell ändert, muss dies normalerweise durch Synchronisierung erfolgen auf einem Objekt, das die Karte auf natürliche Weise kapselt.
Die Implementierung ist wie folgt: (org.elasticsearch.transport.TransportService)
final Map<Long, TimeoutInfoHolder> timeoutInfoHandlers =
Collections.synchronizedMap(new LinkedHashMap<Long, TimeoutInfoHolder>(100, .75F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 100;
}
});Wenn die Kapazität 100 überschreitet, beginnen Sie mit der Ausführung der LRU-Richtlinie: Entfernen Sie das am längsten nicht verwendete TimeoutInfoHolder-Objekt.
Referenzlink:
- Zufällige Hinweise zur Verbesserung des Redis-LRU-Algorithmus
- Verwendung von Redis als LRU-Cache
Lassen Sie uns abschließend über etwas sprechen, das nichts mit diesem Artikel zu tun hat: einige Gedanken zur Datenverarbeitung:
5G ist fähig Wenn alle Wenn verschiedene Knoten mit dem Netzwerk verbunden sind, werden große Datenmengen generiert und die verborgenen Muster hinter den Daten ermittelt (maschinelles Lernen, tiefes Lernen), da diese Daten tatsächlich vorhanden sind eine objektive Widerspiegelung menschlichen Verhaltens. Mit der Schrittzählfunktion von WeChat Sports können Sie beispielsweise Folgendes herausfinden: Hey, es stellt sich heraus, dass mein Aktivitätsniveau jeden Tag etwa 10.000 Schritte beträgt. Um noch einen Schritt weiter zu gehen: In Zukunft werden verschiedene Industrieanlagen und Haushaltsgeräte eine Vielzahl von Daten generieren. Diese Daten sind die Verkörperung sozialer Geschäftsaktivitäten und menschlicher Aktivitäten. Wie können diese Daten sinnvoll genutzt werden? Kann das vorhandene Speichersystem die Speicherung dieser Daten unterstützen? Gibt es ein effizientes Computersystem (Spark oder Tensorflow ...), um den in den Daten verborgenen Wert zu analysieren? Wird das auf der Grundlage dieser Daten trainierte Algorithmusmodell außerdem nach der Anwendung zu Verzerrungen führen? Liegt ein Datenmissbrauch vor? Algorithmen empfehlen Ihnen Dinge, wenn Sie Dinge online kaufen. Moments bewertet auch, wie viel Geld Sie ausleihen müssen und wie viel Sie ausleihen möchten, wenn Sie Nachrichten lesen und Unterhaltungsklatsch. Viele der Dinge, die Sie jeden Tag sehen und mit denen Sie in Berührung kommen, sind Entscheidungen, die von diesen „Datensystemen“ getroffen werden. Sind sie wirklich fair? Wenn Sie in Wirklichkeit einen Fehler machen und Lehrer, Freunde und Familienmitglieder Ihnen Feedback und Korrekturen geben und Sie ihn ändern, können Sie bei Null anfangen. Aber wie sieht es unter diesen Datensystemen aus? Gibt es einen Feedback-Mechanismus zur Fehlerkorrektur? Wird es die Menschen dazu anregen, immer tiefer zu sinken? Selbst wenn Sie aufrichtig sind und über eine gute Bonität verfügen, weist das Algorithmusmodell möglicherweise immer noch eine Wahrscheinlichkeitsverzerrung auf. Beeinträchtigt dies die Möglichkeit eines „fairen Wettbewerbs“ für Menschen? Das sind Fragen, über die sich Datenentwickler Gedanken machen sollten.
Originaltext: https://www.cnblogs.com/hapjin/p/10933405.html
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des LRU-Algorithmus von Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
