

DataFrame nutzt Pandas für die Datenverarbeitung


Verwandte Lernempfehlungen: Python-Tutorial
Dies ist der zweite Artikel zum Thema Pandas-Datenverarbeitung. Sprechen wir über die wichtigste Datenstruktur in Pandas – DataFrame.
Im vorherigen Artikel haben wir die Verwendung von Series vorgestellt und auch erwähnt, dass Series einem eindimensionalen Array entspricht, Pandas jedoch viele praktische und benutzerfreundliche APIs für uns kapselt. Der DataFrame kann einfach als ein Diktat verstanden werden, das aus Series besteht und so die Daten in eine zweidimensionale Tabelle zusammenfügt. Es bietet uns außerdem viele Schnittstellen für die Datenverarbeitung auf Tabellenebene und die Stapeldatenverarbeitung, wodurch die Schwierigkeit der Datenverarbeitung erheblich verringert wird.
DataFrame erstellen
DataFrame ist eine tabellarische Datenstruktur, nämlichZeilenindex und Spaltenindex, mit denen wir die entsprechenden Zeilen und Spalten einfach abrufen können. Dadurch wird die Schwierigkeit, Daten für die Datenverarbeitung zu finden, erheblich reduziert.
Beginnen wir zunächst mit der einfachsten Frage, wie man einen DataFrame erstellt.Erstellt aus einem Wörterbuch
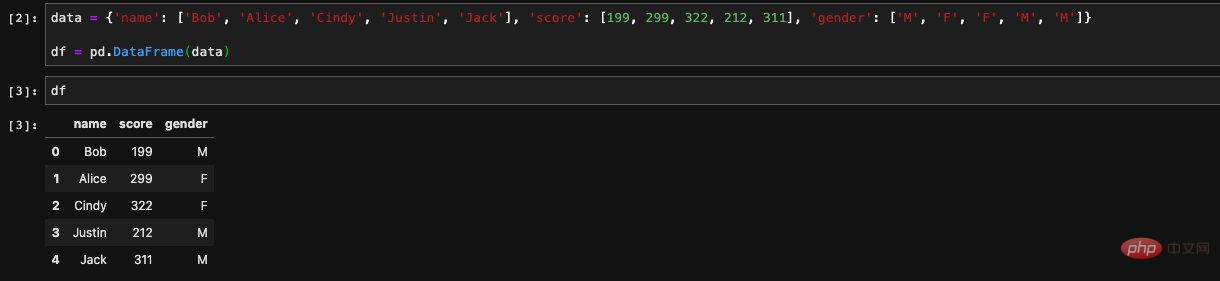
Verwenden Sie den Schlüssel als Spaltennamen und den Wert als entsprechenden Wert, um einen DataFrame für uns zu erstellen.
Wenn wir in Jupyter ausgeben, wird uns der Inhalt des DataFrame automatisch in Tabellenform angezeigt.Aus Numpy-Daten erstellen
Wir können auch einen DataFrame aus einem zweidimensionalen Numpy-Array erstellen, ohne den Spaltennamen anzugeben, dann dienen Pandasals Zahlen als Indizes, um Spalten für uns zu erstellen:
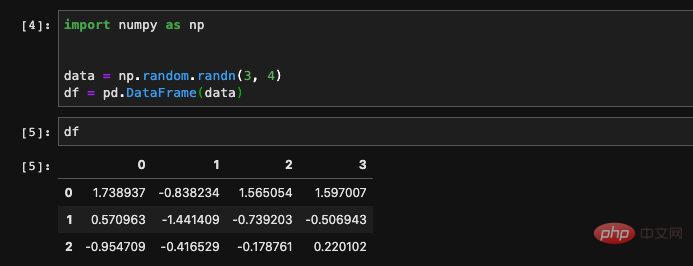
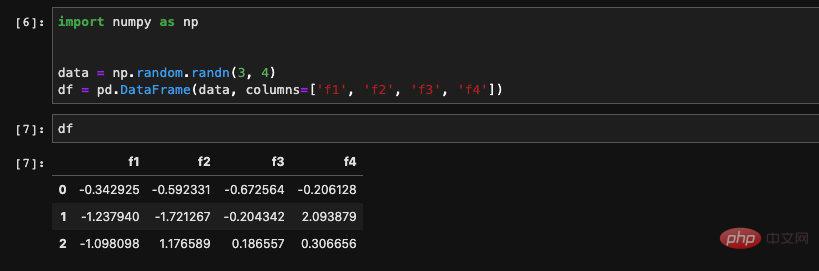
Lesen aus Dateien
Eine weitere sehr leistungsstarke Funktion von Pandas besteht darin, dass es Daten aus Dateien in verschiedenen Formaten lesen kann, um DataFrame zu erstellen, wie z. B. häufig verwendetes Excel, CSV und sogar. Es kann auch eine Datenbank sein.
Für strukturierte Daten wie Excel, CSV, JSON usw. bietet Pandas eine spezielle API. Wir können die entsprechende API finden und verwenden:
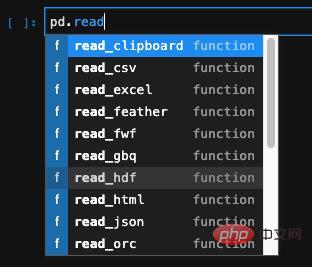
Wenn sie in einem speziellen Format vorliegen, spielt es keine Rolle . Wir verwenden read_table, das Daten aus verschiedenen Textdateien lesen und die Erstellung durch Übergabe von Parametern wie Trennzeichen abschließen kann. Im vorherigen Artikel, der den Dimensionsreduktionseffekt von PCA überprüft, haben wir beispielsweise Daten aus einer Datei im .data-Format gelesen. Das Trennzeichen zwischen den Spalten in dieser Datei ist ein Leerzeichen, nicht das Komma oder Tabellenzeichen von csv. Wir übergeben den Parameter sep und geben das Trennzeichen an, um das Lesen der Daten abzuschließen.
 Dieser Header-Parameter gibt an, welche Zeilen der Datei als Spaltennamen der Daten verwendet werden.
Dieser Header-Parameter gibt an, welche Zeilen der Datei als Spaltennamen der Daten verwendet werden. bedeutet, dass die erste Zeile als Spaltenname verwendet wird. Wenn der Spaltenname nicht in den Daten vorhanden ist, muss header=None angegeben werden, andernfalls treten Probleme auf. Wir müssen selten Spaltennamen mit mehreren Ebenen verwenden. Daher besteht die am häufigsten verwendete Methode darin, den Standardwert zu übernehmen oder ihn auf „Keine“ zu setzen. Unter all diesen
Methoden zum Erstellen eines DataFrames wird am häufigsten die letzte verwendet: das Lesen aus einer Datei. Denn wenn wir maschinelles Lernen betreiben oder an einigen Wettbewerben in Kaggle teilnehmen, werden uns die Daten oft vorgefertigt und in Form von Dateien zur Verfügung gestellt. Es gibt nur sehr wenige Fälle, in denen wir Daten selbst erstellen müssen. Wenn es sich um ein tatsächliches Arbeitsszenario handelt, werden die Daten zwar nicht in Dateien gespeichert, es gibt jedoch eine Quelle, die normalerweise auf einigen Big-Data-Plattformen gespeichert ist, und das Modell erhält Trainingsdaten von diesen Plattformen.Im Allgemeinen verwenden wir selten andere Methoden zum Erstellen von DataFrame. Wir haben ein gewisses Verständnis und konzentrieren uns darauf, die Methode zum Lesen aus Dateien zu beherrschen.
Allgemeine Operationen
Im Folgenden werden einige gängige Operationen von Pandas vorgestellt, die ich bereits kannte, bevor ich lernte, Pandas systematisch zu verwenden. Der Grund, sie zu verstehen, ist ebenfalls sehr einfach, da sie so häufig verwendet werden, dass man sagen kann, dass es sich um „Inhalte des gesunden Menschenverstandes handelt, die bekannt und verstanden werden müssen“.
Wenn wir die DataFrame-Instanz in Jupyter ausführen, werden alle Daten im DataFrame für uns gedruckt. Wenn zu viele Datenzeilen vorhanden sind, wird der mittlere Teil weggelassen Form von Ellipsen. Bei einem DataFrame mit einer großen Datenmenge geben wir ihn im Allgemeinen nicht direkt auf diese Weise aus, sondern zeigen die ersten oder letzten Datenelemente an. Hier werden zwei APIs benötigt.
Die Methode zum Anzeigen der ersten Datenelemente heißt headSie akzeptiert einen Parameter und ermöglicht es uns, ihn anzugeben, um die Anzahl der Daten anzuzeigen, die wir von Anfang an angeben.
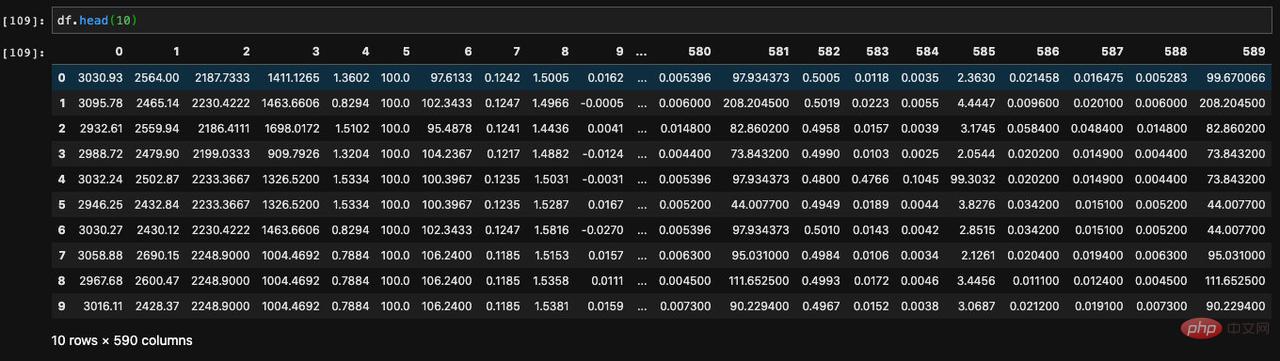 Da es eine API zum Anzeigen der ersten paar Elemente gibt, gibt es auch eine API zum Anzeigen der letzten paar Elemente. Eine solche API heißt
Da es eine API zum Anzeigen der ersten paar Elemente gibt, gibt es auch eine API zum Anzeigen der letzten paar Elemente. Eine solche API heißt . Dadurch können wir die zuletzt angegebene Anzahl von Daten im DataFrame anzeigen:

Wir haben bereits erwähnt, dass dies für DataFrame tatsächlich der Fall ist entspricht der Kombination von Series dict. Da es sich um ein Diktat handelt, können wir die angegebene Serie natürlich basierend auf dem Schlüsselwert erhalten.
Es gibt zwei Methoden, um die angegebenen Spalten in DataFrame abzurufen. Wir können
Spaltennamen hinzufügenoder wir können Elemente durch Diktieren finden zur Abfrage:
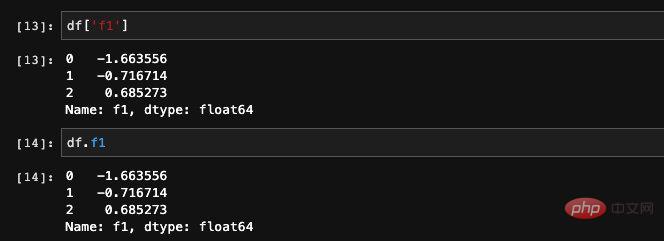 Wir können auch
Wir können auch Wenn mehrere Spalten vorhanden sind, wird nur eine Methode unterstützt, nämlich das Abfragen von Elementen über dict. Es ermöglicht den Empfang einer eingehenden Liste und das Auffinden der Daten, die den Spalten in der Liste entsprechen. Das zurückgegebene Ergebnis ist ein neuer DataFrame, der aus diesen neuen Spalten besteht. Wir können del verwenden, um eine Spalte zu löschen, die wir nicht benötigen: Es ist auch sehr einfach, dem DataFrame direkt einen Wert zuzuweisen, wie bei der Diktatzuweisung: :
Einige Berufsorganisationen haben Statistiken erstellt. Für einen Algorithmus-Ingenieur werden etwa 70 % der Zeit in die Datenverarbeitung investiert. Der tatsächliche Zeitaufwand für das Schreiben des Modells und das Anpassen der Parameter kann weniger als 20 % betragen. Daraus können wir die Notwendigkeit und Bedeutung der Datenverarbeitung erkennen. Im Bereich Python ist Pandas das beste Skalpell und die beste Toolbox für die Datenverarbeitung. Ich hoffe, dass jeder es beherrschen kann. 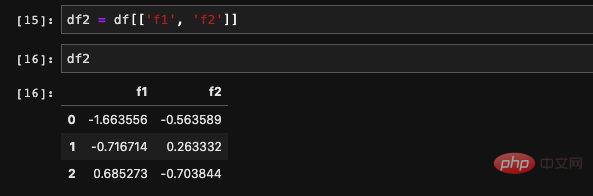
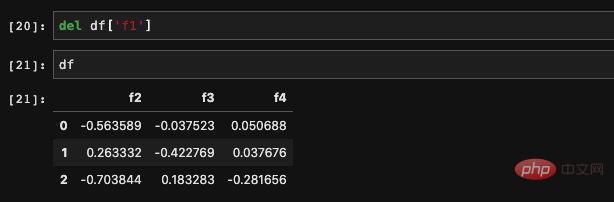
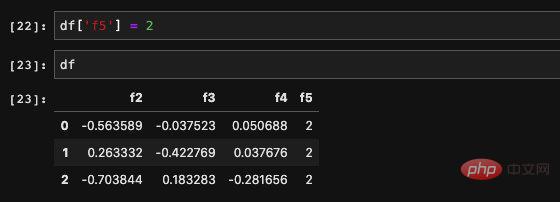 Das Zuweisungsobjekt ist nicht nur eine reelle Zahl,
Das Zuweisungsobjekt ist nicht nur eine reelle Zahl, 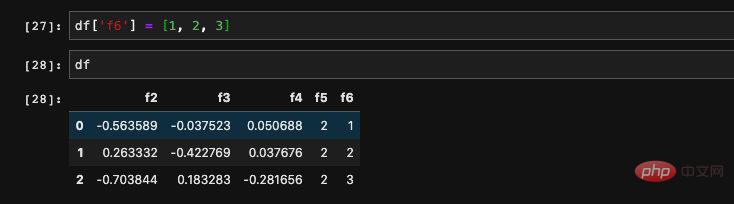 Es ist für uns sehr einfach, eine bestimmte Spalte zu ändern, und wir können die Originaldaten dadurch überschreiben gleiche Zuordnungsmethode.
Es ist für uns sehr einfach, eine bestimmte Spalte zu ändern, und wir können die Originaldaten dadurch überschreiben gleiche Zuordnungsmethode.
Manchmal ist es für uns unpraktisch, Pandas zu verwenden. Wenn wir die entsprechenden Originaldaten erhalten möchten, können wir .values direkt verwenden, um das Numpy-Array abzurufen entsprechend
DataFrame:  jede Spalte im DataFrame einen separaten Typ hat
jede Spalte im DataFrame einen separaten Typ hatZusammenfassungIm heutigen Artikel haben wir etwas über die Beziehung zwischen DataFrame und Series gelernt und außerdem einige Grundlagen und die allgemeine Verwendung von DataFrame kennengelernt. Obwohl DataFrame ungefähr als ein aus Reihen bestehendes Diktat betrachtet werden kann, ist es tatsächlich eine separate Datenstruktur, verfügt aber auch über viele eigene APIs, unterstützt viele ausgefallene Operationen und ist für uns ein leistungsstarkes Werkzeug zur Datenverarbeitung.
Wenn Sie mehr über das Programmieren erfahren möchten, achten Sie bitte auf die Rubrik „PHP-Schulung“!
Das obige ist der detaillierte Inhalt vonDataFrame nutzt Pandas für die Datenverarbeitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
