

Verwenden Sie Node.js+Chrome+Puppeteer, um die Website zu crawlen


Video-Tutorial-Empfehlung: nodejs-Tutorial
Was werden wir lernen?
In diesem Tutorial erfahren Sie, wie Sie das Web mithilfe von JavaScript automatisieren und bereinigen. Dazu verwenden wir Puppeteer. Puppeteer ist eine Node-Bibliotheks-API, mit der wir Headless Chrome steuern können. Headless Chrome ist eine Möglichkeit, den Chrome-Browser auszuführen, ohne Chrome tatsächlich auszuführen.
Wenn das alles keinen Sinn ergibt, müssen Sie nur wissen, dass wir JavaScript-Code schreiben werden, um Google Chrome zu automatisieren.
Bevor Sie beginnen
Bevor Sie beginnen, muss Node 8+ auf Ihrem Computer installiert sein. Sie können es hier installieren. Achten Sie darauf, die „aktuelle“ Version 8+ auszuwählen.
Wenn Sie Node noch nie verwendet haben und lernen möchten, schauen Sie sich Folgendes an: Lernen Sie Node JS – die 3 besten Online-Node-JS-Kurse.
Erstellen Sie nach der Installation von Node einen neuen Projektordner und installieren Sie Puppeteer. Puppeteer wird mit der neuesten Version von Chromium geliefert, die mit der API verwendet werden kann:
npm install --save puppeteer
Beispiel #1 – Screenshot
Nach der Installation von Puppeteer beginnen wir mit einem einfachen Beispiel. Dieses Beispiel stammt aus der Puppeteer-Dokumentation (mit geringfügigen Änderungen). Wir erklären Ihnen Schritt für Schritt, wie Sie einen Screenshot der von Ihnen besuchten Website erstellen.
Erstellen Sie zunächst eine Datei mit dem Namen test.js und kopieren Sie den folgenden Code: test.js的文件,然后复制以下代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();让我们逐行浏览这个例子。
- 第1行: 我们需要我们先前安装的 Puppeteer 依赖项
-
第3-10行:这是我们的主函数
getPic()。该函数将保存我们所有的自动化代码。 -
第12行:在第12行上,我们调用
getPic()函数。
需要注意的是,getPic()函数是一个异步函数,并利用了新的ES 2017async/await功能。由于这个函数是异步的,所以当调用时它返回一个Promise。当Async函数最终返回值时,Promise将被解析(如果存在错误,则Reject)。
由于我们使用的是async函数,因此我们可以使用await表达式,该表达式将暂停函数执行并等待Promise解析后再继续。 如果现在所有这些都没有意义,那也没关系。随着我们继续学习教程,它将变得更加清晰。
现在,我们概述了主函数,让我们深入了解其内部功能:
- 第4行:
const browser = await puppeteer.launch();
这是我们实际启动 puppeteer 的地方。实际上,我们正在启动 Chrome 实例,并将其设置为等于我们新创建的browser变量。由于我们使用了await关键字,因此该函数将在此处暂停,直到Promise解析(直到我们成功创建 Chrome 实例或出错)为止。
- 第5行:
const page = await browser.newPage();
在这里,我们在自动浏览器中创建一个新页面。我们等待新页面打开并将其保存到我们的page变量中。
- 第6行:
await page.goto('https://google.com');使用我们在代码的最后一行中创建的page,现在可以告诉page导航到URL。在此示例中,导航到 google。我们的代码将暂停,直到页面加载完毕。
- 第7行:
await page.screenshot({path: 'google.png'});现在,我们告诉 Puppeteer 截取当前页面的屏幕。screenshot()方法将自定义的.png屏幕截图的保存位置的对象作为参数。同样,我们使用了await关键字,因此在执行操作时我们的代码会暂停。
- 第9行:
await browser.close();
最后,我们到了getPic()函数的结尾,并且关闭了browser。
运行示例
您可以使用 Node 运行上面的示例代码:
node test.js
这是生成的屏幕截图:
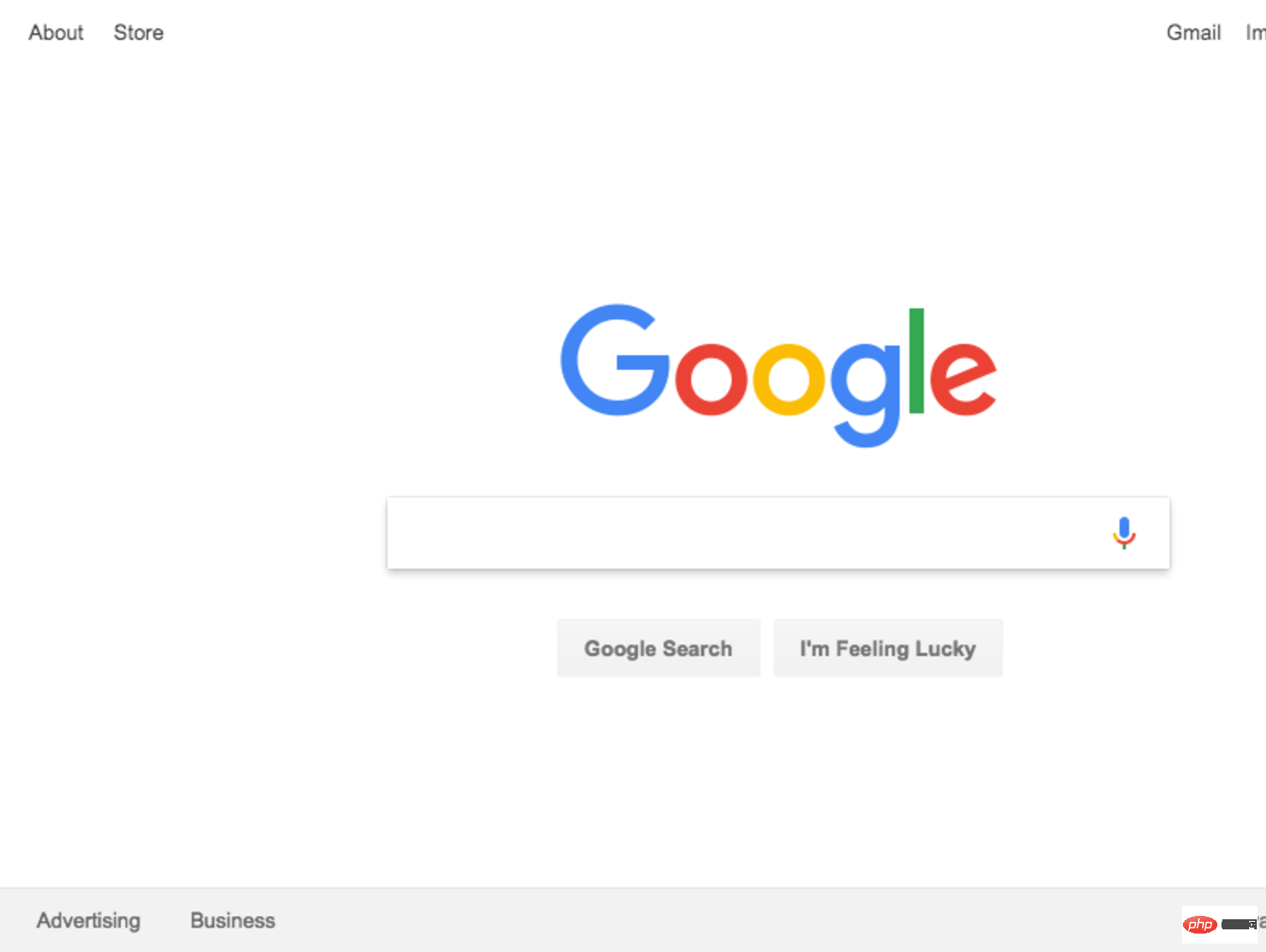
太棒了!为了增加乐趣(并简化调试),我们可以不以无头方式运行代码。
这到底是什么意思?自己尝试一下,看看吧。更改代码的第4行从:
const browser = await puppeteer.launch();
改为:
const browser = await puppeteer.launch({headless: false});然后使用 Node 再次运行:
node test.js
太酷了吧?当我们使用{headless:false}
await page.setViewport({width: 1000, height: 500})- 🎜Zeile 1: 🎜 Wir benötigen die Puppeteer-Abhängigkeiten, die wir zuvor installiert haben
- 🎜Zeilen 3-10: 🎜Dies ist unsere Hauptfunktion
getPic(). Diese Funktion enthält unseren gesamten Automatisierungscode. - 🎜Zeile 12: 🎜In Zeile 12 rufen wir die Funktion
getPic()auf.
getPic() eine asynchrone-Funktion ist und die Vorteile des neuen ES 2017 async/ nutzt. waitFunktion. Da diese Funktion asynchron ist, gibt sie beim Aufruf ein Promise zurück. Wenn die Funktion Async schließlich einen Wert zurückgibt, wird das Promise aufgelöst (oder Reject, wenn ein Fehler vorliegt). 🎜🎜Da wir die Funktion async verwenden, können wir den Ausdruck await verwenden, der die Funktionsausführung anhält und auf das Promise wartet lösen und dann fortfahren. 🎜Wenn das alles jetzt keinen Sinn ergibt, ist das in Ordnung🎜. Im weiteren Verlauf des Tutorials wird es klarer. 🎜🎜Da wir nun einen Überblick über die Hauptfunktion haben, tauchen wir in ihre interne Funktionalität ein: 🎜- 🎜Zeile 4: 🎜
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();browser. Da wir das Schlüsselwort await verwendet haben, wird die Funktion hier angehalten, bis das Promise aufgelöst wird (bis wir die Chrome-Instanz erfolgreich erstellen oder ein Fehler auftritt). 🎜- 🎜Zeile 5: 🎜
const puppeteer = require('puppeteer');
let scrape = async () => {
// 实际的抓取从这里开始...
// 返回值
};
scrape().then((value) => {
console.log(value); // 成功!
});page-Variable. 🎜- 🎜Zeile 6: 🎜
let scrape = async () => {
return 'test';
};page, die wir in der letzten Codezeile erstellt haben, können wir nun page Navigieren Sie zur URL. Navigieren Sie in diesem Beispiel zu Google. Unser Code wird angehalten, bis die Seite geladen ist. 🎜<ul><li>🎜Zeile 7: 🎜</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000); // Scrape browser.close();
return result;};</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜Jetzt weisen wir Puppeteer an, einen Screenshot der aktuellen <code>Seite zu machen. Die Methode screenshot() verwendet das benutzerdefinierte .png-Objekt, in dem der Screenshot als Parameter gespeichert wird. Auch hier haben wir das Schlüsselwort await verwendet, damit unser Code anhält, während der Vorgang ausgeführt wird. 🎜- 🎜Zeile 9: 🎜
const browser = await puppeteer.launch({headless: false});getPic() und schließen den Browser Code>. 🎜🎜🎜Führen Sie das Beispiel aus🎜🎜🎜Sie können den obigen Beispielcode mit Knoten ausführen: 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">const page = await browser.newPage();</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜Dies ist der generierte Screenshot: 🎜🎜<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/2d6f574ea6b652f9047628a160ebac6c-2.png" class="lazy" alt=""><br>Fantastisch! Für mehr Spaß (und einfacheres Debuggen) können wir den Code ausführen, ohne ihn kopflos auszuführen. 🎜🎜Was genau bedeutet das? Probieren Sie es selbst aus und sehen Sie. Ändern Sie Zeile 4 des Codes von: 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">await page.goto('http://books.toscrape.com/');</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜 in: 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">await page.waitFor(1000);</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜 Führen Sie ihn dann erneut mit Node aus: 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">browser.close();
return result;</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜 Cool, oder? Sie können tatsächlich sehen, wie Google Chrome gemäß Ihrem Code funktioniert, wenn wir es mit <code>{headless: false ausführen. 🎜在继续之前,我们将对这段代码做最后一件事。还记得我们的屏幕截图有点偏离中心吗?那是因为我们的页面有点小。我们可以通过添加以下代码行来更改页面的大小:
await page.setViewport({width: 1000, height: 500})这个屏幕截图更好看点:
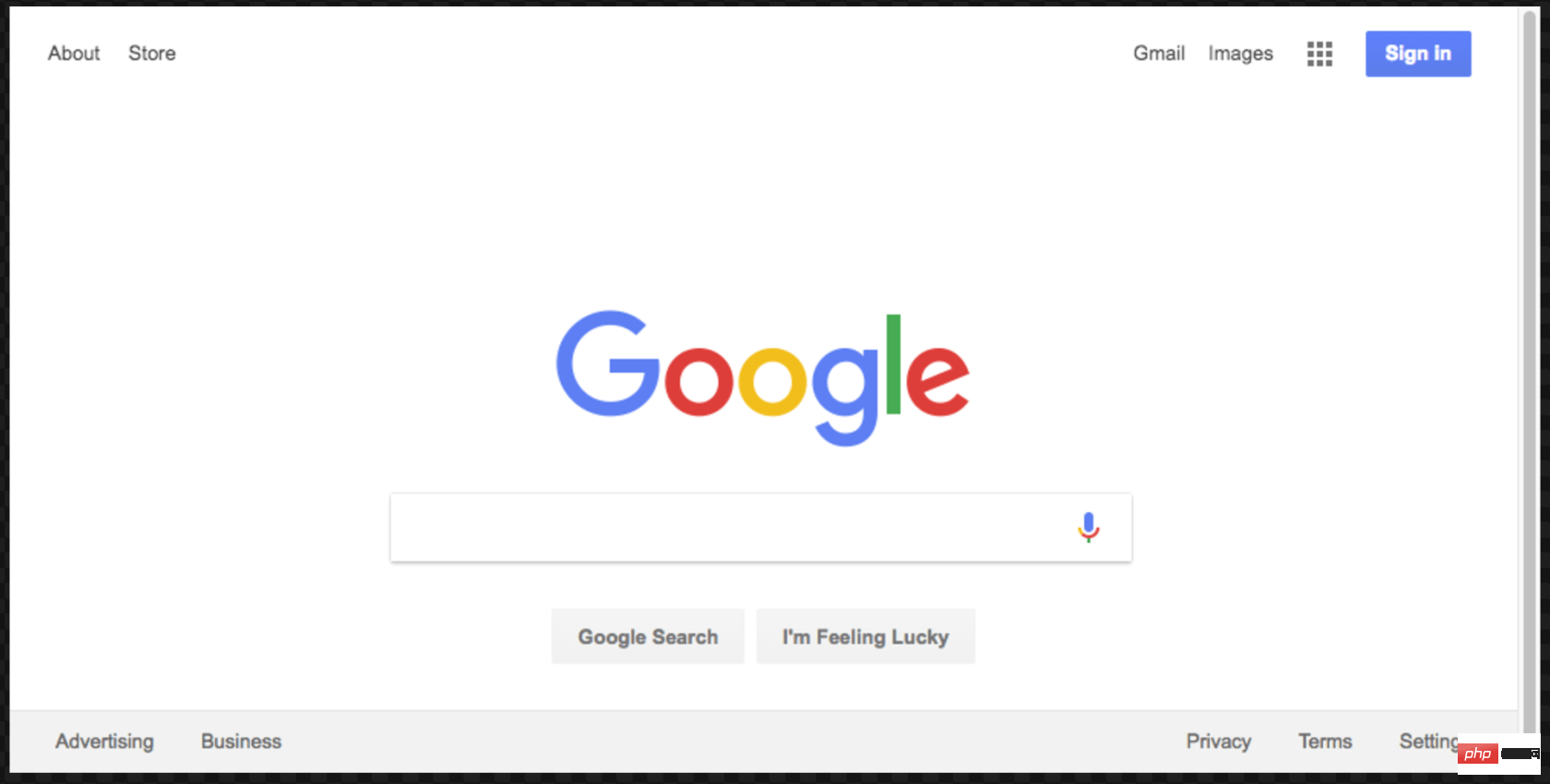
这是本示例的最终代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();示例 #2-让我们抓取一些数据
既然您已经了解了 Headless Chrome 和 Puppeteer 的工作原理,那么让我们看一个更复杂的示例,在该示例中我们事实上可以抓取一些数据。
首先, 在此处查看 Puppeteer 的 API 文档。 如您所见,我们有很多方法可以使用, 不仅可以点击网站,还可以填写表格,输入内容和读取数据。
在本教程中,我们将抓取 Books To Scrape ,这是一家专门设置的假书店,旨在帮助人们练习抓取。
在同一目录中,创建一个名为scrape.js的文件,并插入以下样板代码:
const puppeteer = require('puppeteer');
let scrape = async () => {
// 实际的抓取从这里开始...
// 返回值
};
scrape().then((value) => {
console.log(value); // 成功!
});理想情况下,在看完第一个示例之后,上面的代码对您有意义。如果没有,那没关系!
我们上面所做的需要以前安装的puppeteer依赖关系。然后我们有scraping()函数,我们将在其中填入抓取代码。此函数将返回值。最后,我们调用scraping函数并处理返回值(将其记录到控制台)。
我们可以通过在scrape函数中添加一行代码来测试以上代码。试试看:
let scrape = async () => {
return 'test';
};现在,在控制台中运行node scrape.js。您应该返回test!完美,我们返回的值正在记录到控制台。现在我们可以开始补充我们的scrape函数。
步骤1:设置
我们需要做的第一件事是创建浏览器实例,打开一个新页面,然后导航到URL。我们的操作方法如下:
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000); // Scrape browser.close();
return result;};太棒了!让我们逐行学习它:
首先,我们创建浏览器,并将headless模式设置为false。这使我们可以准确地观察发生了什么:
const browser = await puppeteer.launch({headless: false});然后,我们在浏览器中创建一个新页面:
const page = await browser.newPage();
接下来,我们转到books.toscrape.com URL:
await page.goto('http://books.toscrape.com/');我选择性地添加了1000毫秒的延迟。尽管通常没有必要,但这将确保页面上的所有内容都加载:
await page.waitFor(1000);
最后,完成所有操作后,我们将关闭浏览器并返回结果。
browser.close(); return result;
步骤2:抓取
正如您现在可能已经确定的那样,Books to Scrape 拥有大量的真实书籍和这些书籍的伪造数据。我们要做的是选择页面上的第一本书,然后返回该书的标题和价格。这是要抓取的图书的主页。我有兴趣点第一本书(下面红色标记)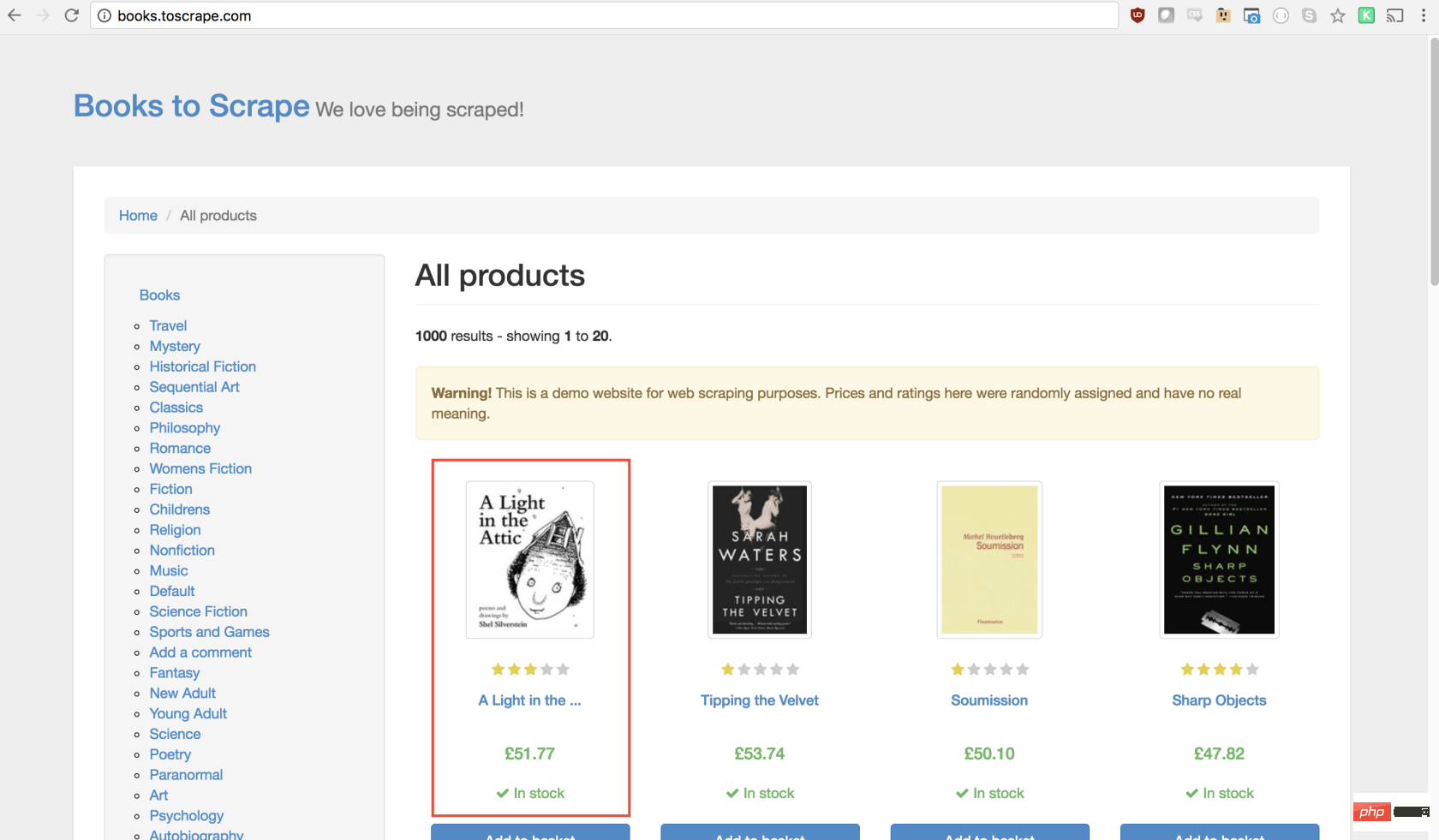
查看 Puppeteer API,我们可以找到单击页面的方法:
page.click(selector[, options])
-
selector用于选择要单击的元素的选择器,如果有多个满足选择器的元素,则将单击第一个。
幸运的是,使用 Google Chrome 开发者工具可以非常轻松地确定特定元素的选择器。只需右键单击图像并选择检查: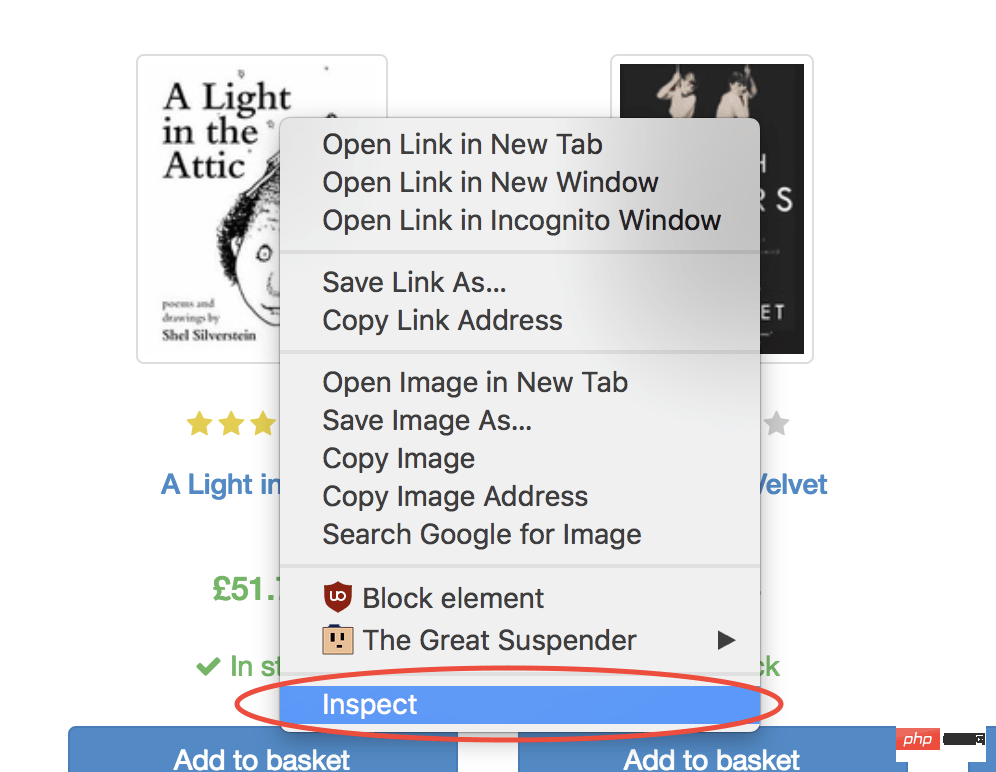
这将打开元素面板,突出显示该元素。现在,您可以单击左侧的三个点,选择复制,然后选择复制选择器:
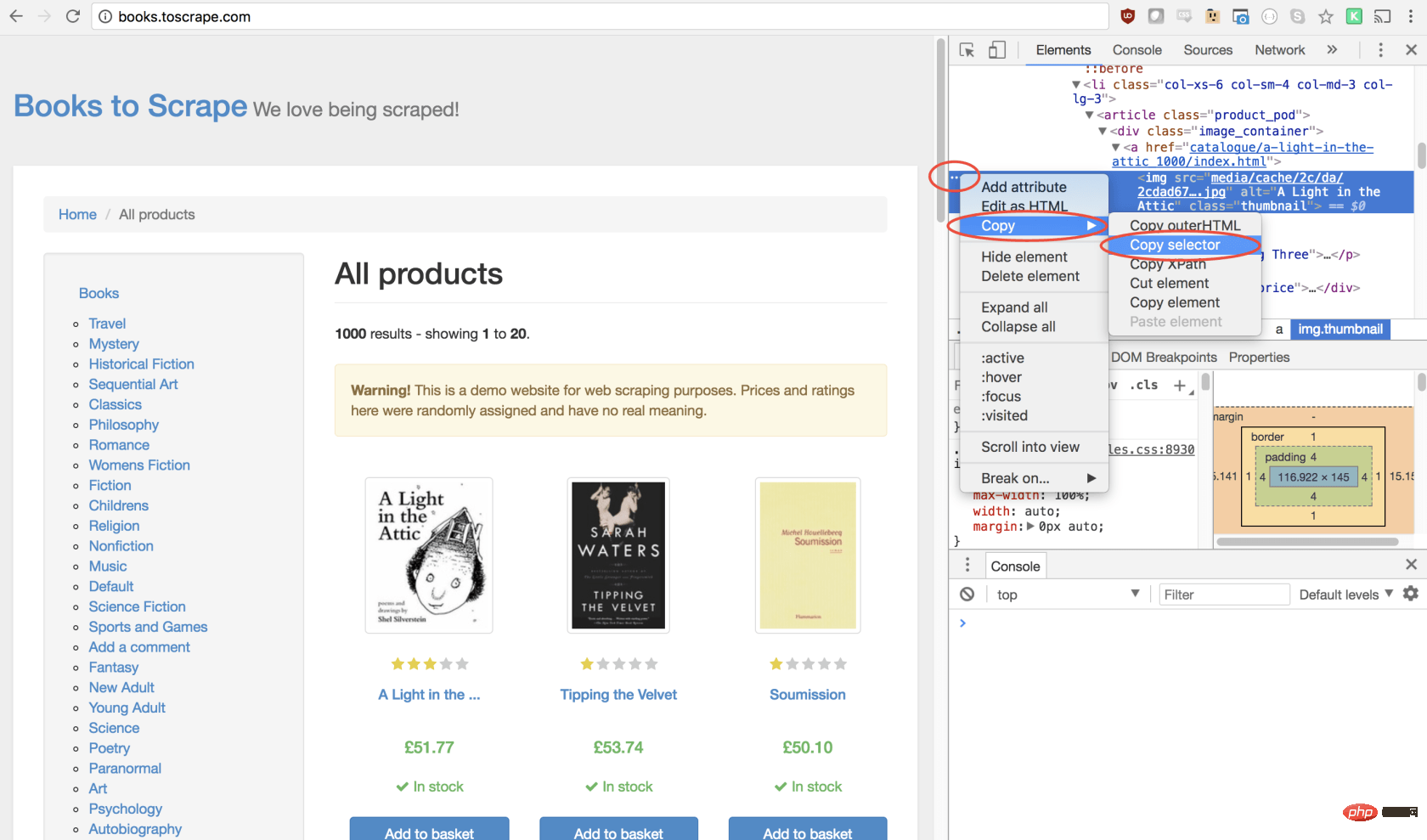
太棒了!现在,我们复制了选择器,并且可以将click方法插入程序。像这样:
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');我们的窗口将单击第一个产品图像并导航到该产品页面!
在新页面上,我们对商品名称和商品价格均感兴趣(以下以红色概述)
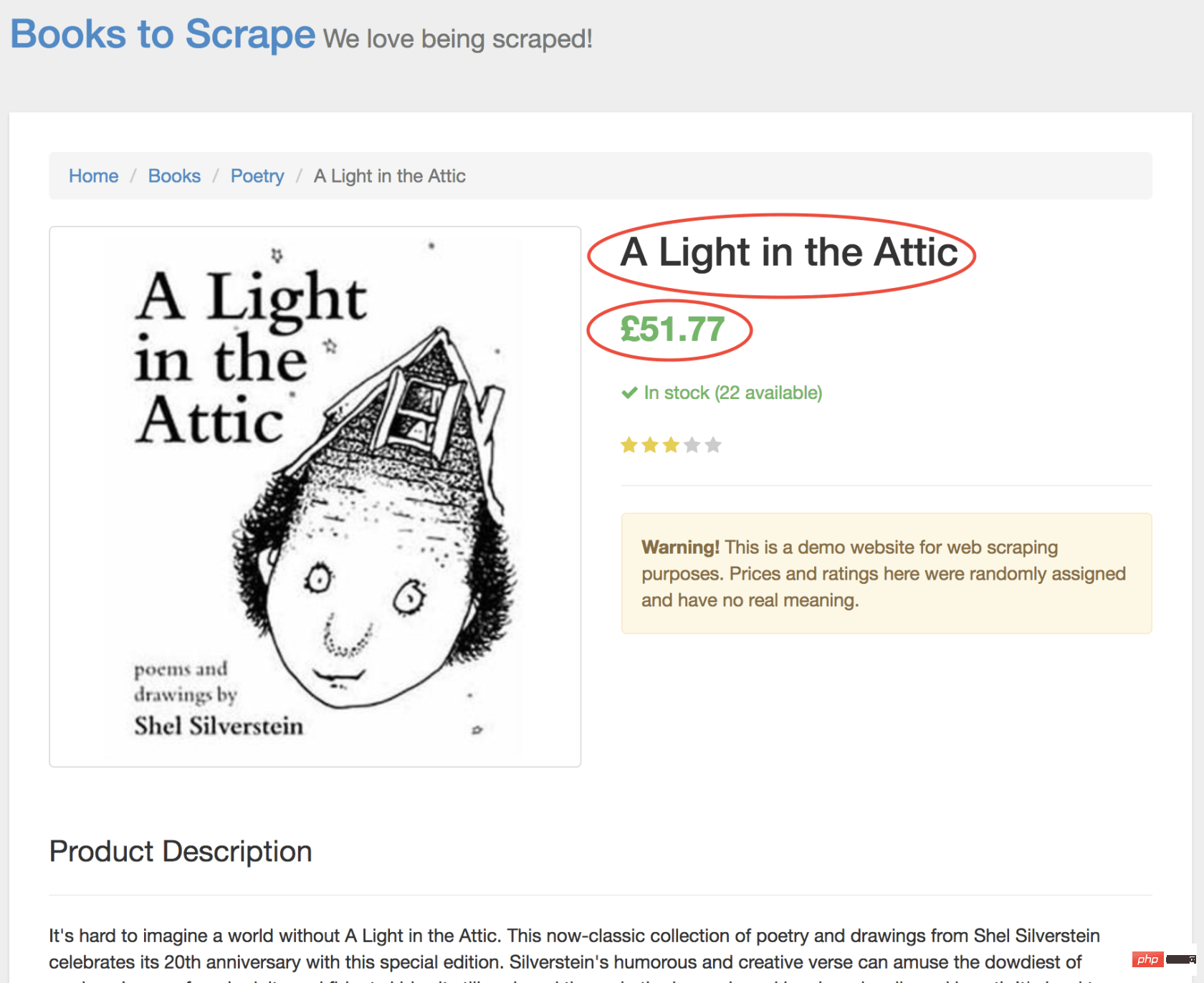
为了检索这些值,我们将使用page.evaluate()方法。此方法使我们可以使用内置的 DOM 选择器,例如querySelector()。
我们要做的第一件事是创建page.evaluate()函数,并将返回值保存到变量result中:
const result = await page.evaluate(() => {// return something});在函数里,我们可以选择所需的元素。我们将使用 Google Developers 工具再次解决这一问题。右键单击标题,然后选择检查:
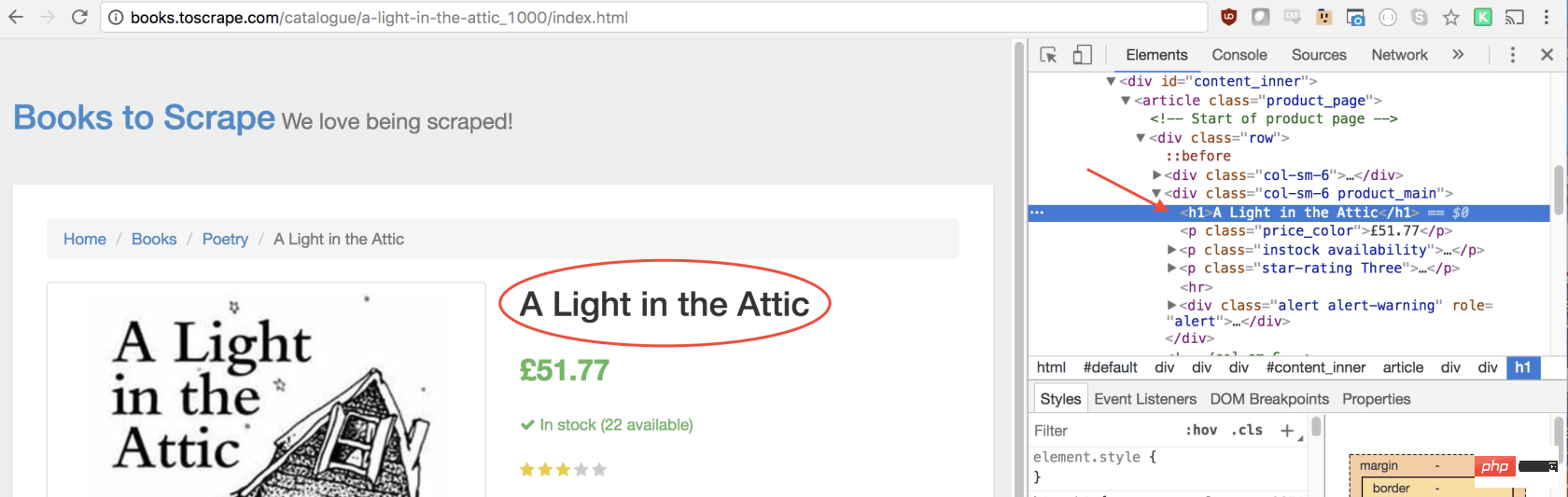
正如您将在 elements 面板中看到的那样,标题只是一个h1元素。我们可以使用以下代码选择此元素:
let title = document.querySelector('h1');由于我们希望文本包含在此元素中,因此我们需要添加.innerText-最终代码如下所示:
let title = document.querySelector('h1').innerText;同样,我们可以通过单击右键检查元素来选择价格:
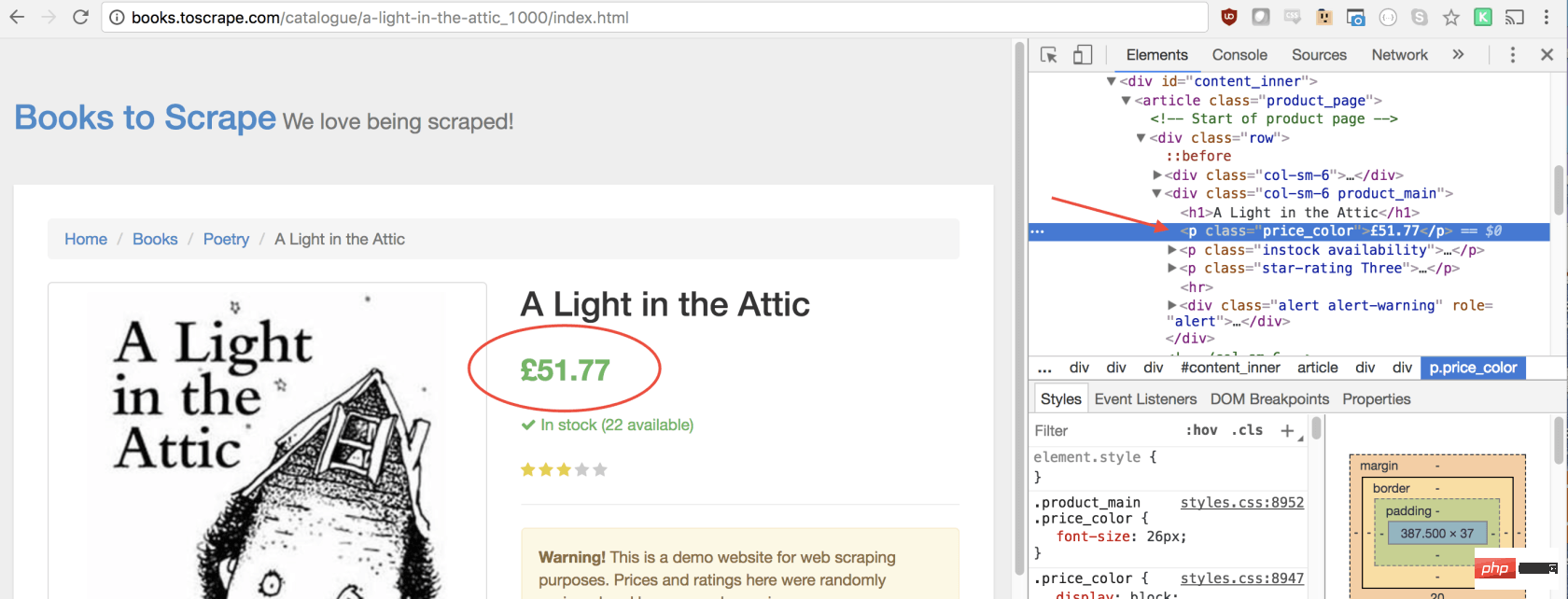
如您所见,我们的价格有price_color类,我们可以使用此类选择元素及其内部文本。这是代码:
let price = document.querySelector('.price_color').innerText;现在我们有了所需的文本,可以将其返回到一个对象中:
return {
title,
price
}太棒了!我们选择标题和价格,将其保存到一个对象中,然后将该对象的值返回给result变量。放在一起是这样的:
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}});剩下要做的唯一一件事就是返回result,以便可以将其记录到控制台:
return result;
您的最终代码应如下所示:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // 成功!
});您可以通过在控制台中键入以下内容来运行 Node 文件:
node scrape.js // { 书名: 'A Light in the Attic', 价格: '£51.77' }您应该看到所选图书的标题和价格返回到屏幕上!您刚刚抓取了网页!
示例 #3 ——完善它
现在您可能会问自己,当标题和价格都显示在主页上时,为什么我们要点击书?为什么不从那里抓取呢?而在我们尝试时,为什么不抓紧所有书籍的标题和价格呢?
因为有很多方法可以抓取网站! (此外,如果我们留在首页上,我们的标题将被删掉)。但是,这为您提供了练习新的抓取技能的绝好机会!
挑战
目标 ——从首页抓取所有书名和价格,并以数组形式返回。这是我最终的输出结果:

开始!看看您是否可以自己完成此任务。与我们刚创建的上述程序非常相似,如果卡住,请向下滚动…
GO! See if you can accomplish this on your own. It’s very similar to the above program we just created. Scroll down if you get stuck…
提示:
此挑战与上一个示例之间的主要区别是需要遍历大量结果。您可以按照以下方法设置代码来做到这一点:
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组
let elements = document.querySelectorAll('xxx'); // 选择全部
// 遍历每一个产品
// 选择标题
// 选择价格
data.push({title, price}); // 将数据放到数组里, 返回数据;
// 返回数据数组
});如果您不明白,没事!这是一个棘手的问题…… 这是一种可能的解决方案。在以后的文章中,我将深入研究此代码及其工作方式,我们还将介绍更高级的抓取技术。如果您想收到通知,请务必 在此处输入您的电子邮件 。
方案:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组, 用来存储数据
let elements = document.querySelectorAll('.product_pod'); // 选择所有产品
for (var element of elements){ // 遍历每个产品
let title = element.childNodes[5].innerText; // 选择标题
let price = element.childNodes[7].children[0].innerText; // 选择价格
data.push({title, price}); // 将对象放进数组 data
}
return data; // 返回数组 data
});
browser.close();
return result; // 返回数据
};
scrape().then((value) => {
console.log(value); // 成功!
});结束语:
感谢您的阅读!
英文原文地址:https://codeburst.io/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js-b18efb9e9921
更多编程相关知识,请访问:编程入门!!
Das obige ist der detaillierte Inhalt vonVerwenden Sie Node.js+Chrome+Puppeteer, um die Website zu crawlen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Was ist Updater.exe in Windows 11/10? Ist das der Chrome-Prozess?
Mar 21, 2024 pm 05:36 PM
Was ist Updater.exe in Windows 11/10? Ist das der Chrome-Prozess?
Mar 21, 2024 pm 05:36 PM
Jede Anwendung, die Sie unter Windows ausführen, verfügt über ein Komponentenprogramm, um sie zu aktualisieren. Wenn Sie also Google Chrome oder Google Earth verwenden, wird die Anwendung „GoogleUpdate.exe“ ausgeführt, geprüft, ob ein Update verfügbar ist, und es dann basierend auf den Einstellungen aktualisiert. Wenn Sie es jedoch nicht mehr sehen und stattdessen einen Prozess updater.exe im Task-Manager von Windows 11/10 sehen, gibt es dafür einen Grund. Was ist Updater.exe in Windows 11/10? Google hat Updates für alle seine Apps wie Google Earth, Google Drive, Chrome usw. bereitgestellt. Dieses Update bringt
 Welche Datei ist crdownload?
Mar 08, 2023 am 11:38 AM
Welche Datei ist crdownload?
Mar 08, 2023 am 11:38 AM
crdownload ist eine Chrome-Browser-Download-Cache-Datei, bei der es sich um eine Datei handelt, die nicht heruntergeladen wurde. Bei der crdownload-Datei handelt es sich um ein temporäres Dateiformat, das zum Speichern von Dateien verwendet wird, die von der Festplatte heruntergeladen wurden. Es kann Benutzern helfen, die Dateiintegrität beim Herunterladen von Dateien zu schützen und Schäden zu vermeiden . Unerwartete Unterbrechung oder Unterbrechung. CRDownload-Dateien können auch zum Sichern von Dateien verwendet werden, sodass Benutzer temporäre Kopien von Dateien speichern können. Wenn beim Herunterladen ein unerwarteter Fehler auftritt, können CRDownload-Dateien zum Wiederherstellen heruntergeladener Dateien verwendet werden.
 Was tun, wenn Chrome keine Plugins laden kann?
Nov 06, 2023 pm 02:22 PM
Was tun, wenn Chrome keine Plugins laden kann?
Nov 06, 2023 pm 02:22 PM
Die Unfähigkeit von Chrome, Plug-Ins zu laden, kann behoben werden, indem überprüft wird, ob das Plug-In korrekt installiert ist, das Plug-In deaktiviert und aktiviert, der Plug-In-Cache geleert, der Browser und die Plug-Ins aktualisiert, die Netzwerkverbindung überprüft werden usw Ich versuche, das Plug-in im Inkognito-Modus zu laden. Die Lösung lautet wie folgt: 1. Überprüfen Sie, ob das Plug-in korrekt installiert wurde, und installieren Sie es erneut. 2. Deaktivieren und aktivieren Sie das Plug-in, klicken Sie auf die Schaltfläche „Deaktivieren“ und dann erneut auf die Schaltfläche „Aktivieren“. - Wählen Sie im Cache „Erweiterte Optionen“ > „Browserdaten löschen“, überprüfen Sie die Bilder und Dateien im Cache, löschen Sie alle Cookies und klicken Sie auf „Daten löschen“.
 So lösen Sie das Problem, dass Google Chrome keine Webseiten öffnen kann
Jan 04, 2024 pm 10:18 PM
So lösen Sie das Problem, dass Google Chrome keine Webseiten öffnen kann
Jan 04, 2024 pm 10:18 PM
Was soll ich tun, wenn die Google Chrome-Webseite nicht geöffnet werden kann? Viele Freunde verwenden gerne Google Chrome. Einige Freunde stellen jedoch fest, dass sie Webseiten nicht normal öffnen können oder dass sich die Webseiten während der Nutzung nur sehr langsam öffnen. Werfen wir einen Blick auf die Lösung des Problems, dass Google Chrome-Webseiten nicht mit dem Editor geöffnet werden können. Lösung für das Problem, dass die Google Chrome-Webseite nicht geöffnet werden kann. Methode 1. Um Spielern zu helfen, die das Level noch nicht bestanden haben, erfahren Sie mehr über die spezifischen Methoden zum Lösen des Rätsels. Klicken Sie zunächst mit der rechten Maustaste auf das Netzwerksymbol in der unteren rechten Ecke und wählen Sie „Netzwerk- und Interneteinstellungen“. 2. Klicken Sie auf „Ethernet“ und dann auf „Adapteroptionen ändern“. 3. Klicken Sie auf die Schaltfläche „Eigenschaften“. 4. Doppelklicken Sie, um i zu öffnen
 Was ist das Installationsverzeichnis der Chrome-Plug-in-Erweiterung?
Mar 08, 2024 am 08:55 AM
Was ist das Installationsverzeichnis der Chrome-Plug-in-Erweiterung?
Mar 08, 2024 am 08:55 AM
Was ist das Installationsverzeichnis der Chrome-Plug-in-Erweiterung? Unter normalen Umständen lautet das Standardinstallationsverzeichnis von Chrome-Plug-In-Erweiterungen wie folgt: 1. Der Standard-Installationsverzeichnis-Speicherort von Chrome-Plug-Ins in Windows XP: C:\DocumentsandSettings\Benutzername\LocalSettings\ApplicationData\Google\Chrome\UserData\ Default\Extensions2. Chrome in Windows7 Der Standardinstallationsverzeichnisspeicherort des Plug-Ins: C:\Benutzer\Benutzername\AppData\Local\Google\Chrome\User
 So löschen Sie einen Knoten in NVM
Dec 29, 2022 am 10:07 AM
So löschen Sie einen Knoten in NVM
Dec 29, 2022 am 10:07 AM
So löschen Sie einen Knoten mit nvm: 1. Laden Sie „nvm-setup.zip“ herunter und installieren Sie es auf dem Laufwerk C. 2. Konfigurieren Sie Umgebungsvariablen und überprüfen Sie die Versionsnummer mit dem Befehl „nvm -v“. install“-Befehl Knoten installieren; 4. Löschen Sie den installierten Knoten über den Befehl „nvm uninstall“.
 So verwenden Sie Express für den Datei-Upload im Knotenprojekt
Mar 28, 2023 pm 07:28 PM
So verwenden Sie Express für den Datei-Upload im Knotenprojekt
Mar 28, 2023 pm 07:28 PM
Wie gehe ich mit dem Datei-Upload um? Der folgende Artikel stellt Ihnen vor, wie Sie Express zum Hochladen von Dateien im Knotenprojekt verwenden. Ich hoffe, er ist hilfreich für Sie!
 was bedeutet Chrom
Aug 07, 2023 pm 01:18 PM
was bedeutet Chrom
Aug 07, 2023 pm 01:18 PM
Chrome bedeutet Browser, ein von Google entwickelter Webbrowser. Er wurde erstmals im Jahr 2008 veröffentlicht und entwickelte sich aufgrund seiner ikonischen Funktion schnell zu einem der beliebtesten Browser oben im Fenster, und das Erscheinungsbild dieser Registerkartenleiste ähnelt stark dem verchromten Metall.
