
 Backend-Entwicklung
Python-Tutorial
Pandas-Tipps zum effizienten Abrufen von Daten durch Indizierung in DataFrame
Backend-Entwicklung
Python-Tutorial
Pandas-Tipps zum effizienten Abrufen von Daten durch Indizierung in DataFrame
Pandas-Tipps zum effizienten Abrufen von Daten durch Indizierung in DataFrame


Verwandte Lernempfehlungen: Python-Tutorial
Im vorherigen Artikel haben wir die Verwendung einiger häufig verwendeter Indizes in der DataFrame-Datenstruktur vorgestellt, z. B. iloc, loc, logische Indizes usw. Werfen wir im heutigen Artikel einen Blick auf einige „grundlegende Vorgänge“ von DataFrame.
Wir können die Summe zweier DataFrames berechnen.
pandas richtet die beiden DataFrames automatisch aus. Wenn die Daten nicht übereinstimmen, werden sie auf Nan (keine Zahl) gesetzt. Zuerst erstellen wir zwei DataFrames:
import numpy as npimport pandas as pddf1 = pd.DataFrame(np.arange(9).reshape((3, 3)), columns=list('abc'), index=['1', '2', '3'])df2 = pd.DataFrame(np.arange(12).reshape((4, 3)), columns=list('abd'), index=['2', '3', '4', '5'])复制代码Das Ergebnis stimmt mit dem überein, was wir uns vorgestellt haben. Tatsächlich müssen wir lediglich
den DataFrame über das Numpy-Array erstellen und dann den Index und die Spalten angeben grundlegende Verwendung.
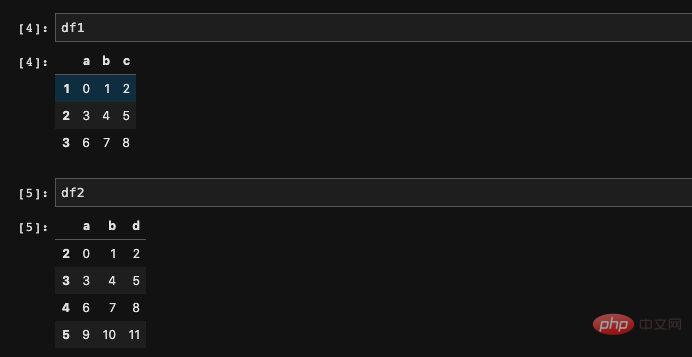
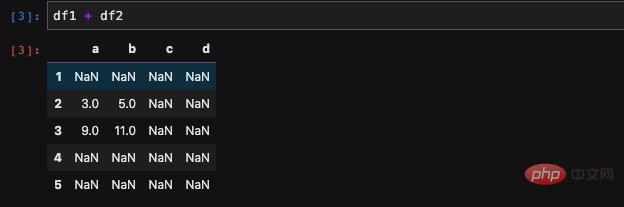 Jede Position, die nicht in beiden DataFrames erscheint, auf Nan gesetzt wird
Jede Position, die nicht in beiden DataFrames erscheint, auf Nan gesetzt wirdfill_value
Wenn wir mit zwei DataFrames arbeiten, dann wollen wir natürlich keine Nullwerte. Zu diesem Zeitpunkt müssen wir die Nullwerte eingeben, um Operationen direkt auszuführen. Zu diesem Zeitpunkt müssen wir die für uns bereitgestellte arithmetische Methode verwenden.
Es gibt mehrere häufig verwendete Operatoren in DataFrame: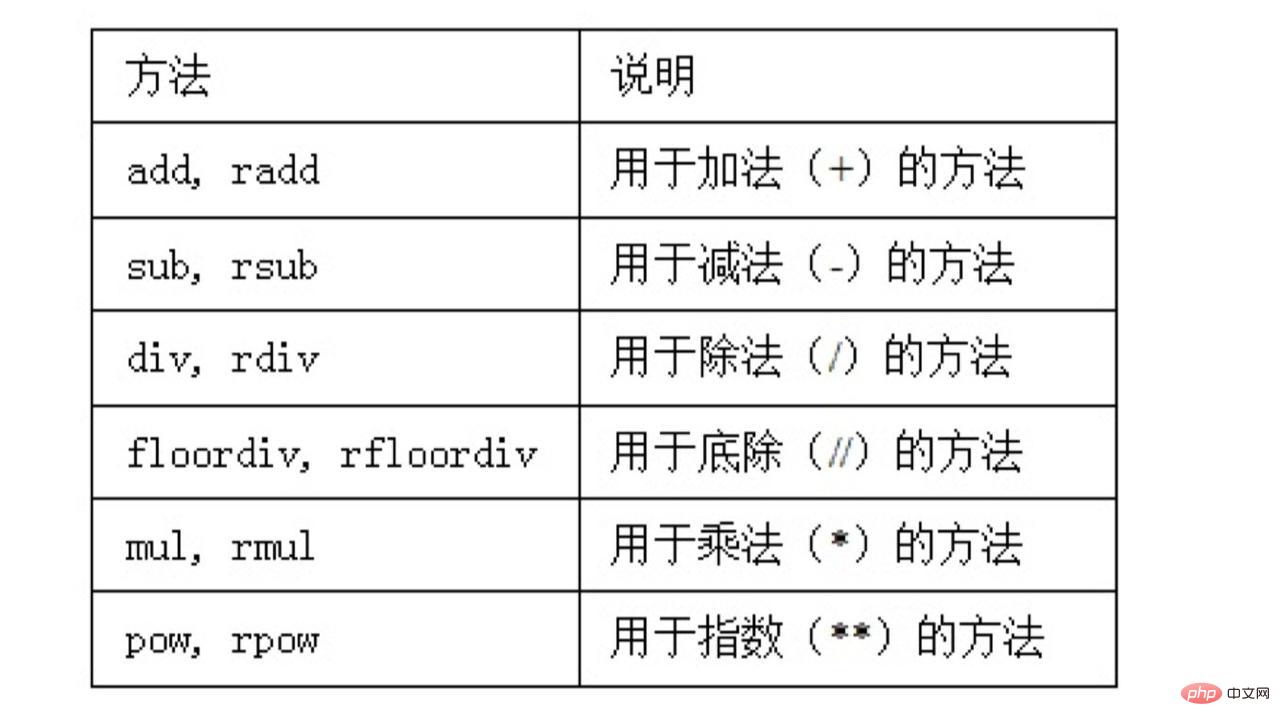
Wir alle verstehen add, sub und p sehr gut. Was bedeuten die Methoden radd und rsub hier? Warum steht ein r davor?
Es scheint verwirrend, aber um es ganz klar auszudrücken: Radd ist es gewohnt, Parameter umzudrehen. Wenn wir beispielsweise den Kehrwert aller Elemente im DataFrame erhalten möchten, können wir ihn als 1/df schreiben. Da 1 selbst kein DataFrame ist, können wir 1 nicht zum Aufrufen von Methoden im DataFrame verwenden und keine Parameter übergeben. Um diese Situation zu lösen, können wir 1/df als df.rp(1) schreiben, sodass wir Sie können darin Parameter übergeben.
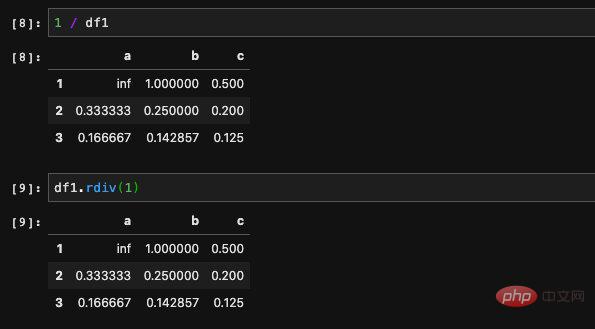
. Das heißt, die Position, die nur in einem DataFrame fehlt, wird durch den von uns angegebenen Wert ersetzt. Wenn sie in beiden DataFrames fehlt, ist sie immer noch Nan.
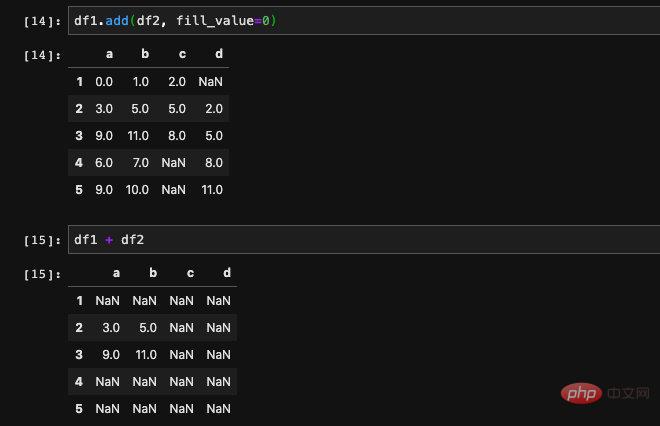
fill_value Dieser Parameter erscheint in vielen APIs
, z. B. bei der Neuindizierung usw. Die Verwendung ist dieselbe. Wir können darauf achten, wenn wir die API-Dokumentation überprüfen.Was machen wir also mit solch einem leeren Wert, der nach dem Ausfüllen immer noch erscheint? Kann ich diese Standorte nur manuell finden und ausfüllen? Natürlich ist es unrealistisch, dass Pandas uns auch eine API zur Verfügung stellt, die speziell Nullwerte löst.
Nullwert-APIBevor wir den Nullwert füllen, müssen wir als Erstes den Nullwert finden
. Um dieses Problem zu lösen, haben wir die isna-API, die einen boolschen DataFrame zurückgibt. Jede Position im DataFrame gibt an, ob die Position, die dem ursprünglichen DataFrame entspricht, ein Nullwert ist.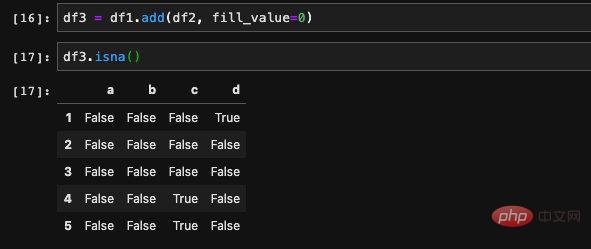
dropna
Natürlich reicht es nicht aus, nur herauszufinden, ob ein Nullwert angezeigt wird. Zu diesem Zeitpunkt können wir uns dafür entscheiden, ihn zu löschen der Nullwert. Für diese Situation können wir die Dropna-Methode in DataFrame verwenden.
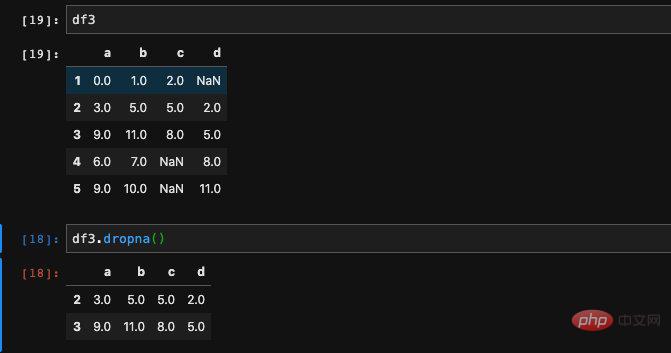
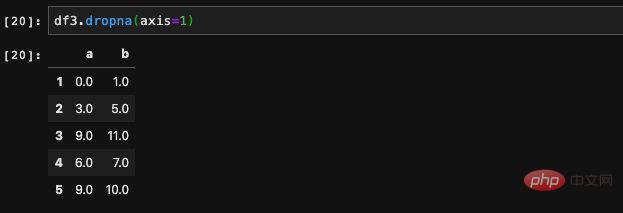
Zeilen mit Nullwerten verworfen wurden. Nur Zeilen ohne Nullwerte werden beibehalten. Manchmal möchten wir die Spalten anstelle von Zeilen verwerfen. Dies können wir durch die Übergabe des Achsenparameters steuern.
fillnaFüllen von Nullwerten verwendet werden
. Tatsächlich ist dies auch die am häufigsten verwendete Methode.Wir können einfach einen bestimmten Wert zum Füllen übergeben:
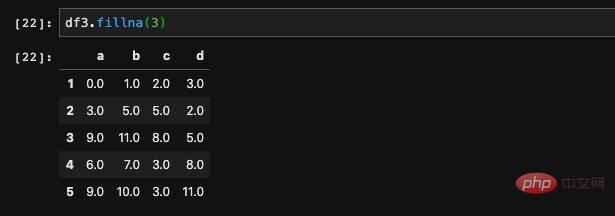 gibt einen neuen DataFrame zurück
gibt einen neuen DataFrame zurückdf3.fillna(3, inplace=True)复制代码
除了填充具体的值以外,我们也可以和一些计算结合起来算出来应该填充的值。比如说我们可以计算出某一列的均值、最大值、最小值等各种计算来填充。fillna这个函数不仅可以使用在DataFrame上,也可以使用在Series上,所以我们可以针对DataFrame中的某一列或者是某些列进行填充:
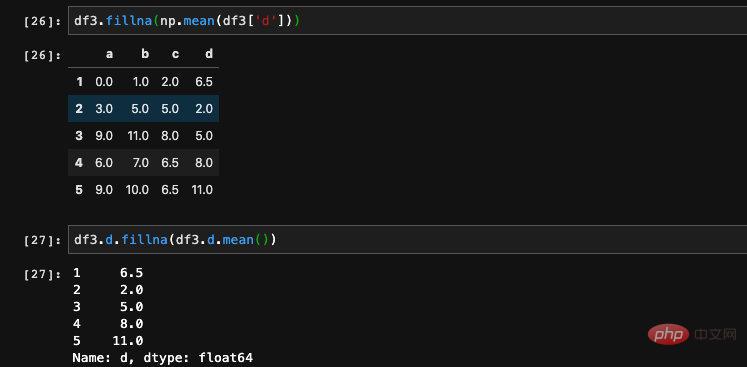
除了可以计算出均值、最大最小值等各种值来进行填充之外,还可以指定使用缺失值的前一行或者是后一行的值来填充。实现这个功能需要用到method这个参数,它有两个接收值,ffill表示用前一行的值来进行填充,bfill表示使用后一行的值填充。
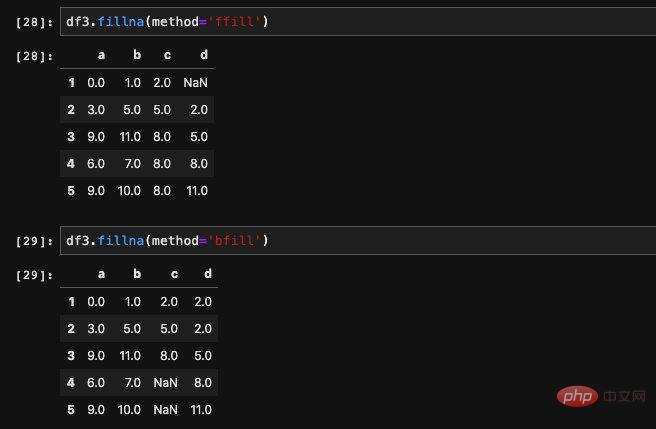
我们可以看到,当我们使用ffill填充的时候,对于第一行的数据来说由于它没有前一行了,所以它的Nan会被保留。同样当我们使用bfill的时候,最后一行也无法填充。
总结
今天的文章当中我们主要介绍了DataFrame的一些基本运算,比如最基础的四则运算。在进行四则运算的时候由于DataFrame之间可能存在行列索引不能对齐的情况,这样计算得到的结果会出现空值,所以我们需要对空值进行处理。我们可以在进行计算的时候通过传入fill_value进行填充,也可以在计算之后对结果进行fillna填充。
在实际的运用当中,我们一般很少会直接对两个DataFrame进行加减运算,但是DataFrame中出现空置是家常便饭的事情。因此对于空值的填充和处理非常重要,可以说是学习中的重点,大家千万注意。
想了解更多编程学习,敬请关注php培训栏目!
Das obige ist der detaillierte Inhalt vonPandas-Tipps zum effizienten Abrufen von Daten durch Indizierung in DataFrame. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
MySQL Workbench kann eine Verbindung zu MariADB herstellen, vorausgesetzt, die Konfiguration ist korrekt. Wählen Sie zuerst "Mariadb" als Anschlusstyp. Stellen Sie in der Verbindungskonfiguration Host, Port, Benutzer, Kennwort und Datenbank korrekt ein. Überprüfen Sie beim Testen der Verbindung, ob der Mariadb -Dienst gestartet wird, ob der Benutzername und das Passwort korrekt sind, ob die Portnummer korrekt ist, ob die Firewall Verbindungen zulässt und ob die Datenbank vorhanden ist. Verwenden Sie in fortschrittlicher Verwendung die Verbindungspooling -Technologie, um die Leistung zu optimieren. Zu den häufigen Fehlern gehören unzureichende Berechtigungen, Probleme mit Netzwerkverbindung usw. Bei Debugging -Fehlern, sorgfältige Analyse von Fehlerinformationen und verwenden Sie Debugging -Tools. Optimierung der Netzwerkkonfiguration kann die Leistung verbessern
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
Die MySQL -Verbindung kann auf die folgenden Gründe liegen: MySQL -Dienst wird nicht gestartet, die Firewall fängt die Verbindung ab, die Portnummer ist falsch, der Benutzername oder das Kennwort ist falsch, die Höradresse in my.cnf ist nicht ordnungsgemäß konfiguriert usw. Die Schritte zur Fehlerbehebung umfassen: 1. Überprüfen Sie, ob der MySQL -Dienst ausgeführt wird. 2. Passen Sie die Firewall -Einstellungen an, damit MySQL Port 3306 anhören kann. 3. Bestätigen Sie, dass die Portnummer mit der tatsächlichen Portnummer übereinstimmt. 4. Überprüfen Sie, ob der Benutzername und das Passwort korrekt sind. 5. Stellen Sie sicher, dass die Einstellungen für die Bindungsadresse in my.cnf korrekt sind.
 Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Als Datenprofi müssen Sie große Datenmengen aus verschiedenen Quellen verarbeiten. Dies kann Herausforderungen für das Datenmanagement und die Analyse darstellen. Glücklicherweise können zwei AWS -Dienste helfen: AWS -Kleber und Amazon Athena.
