


Verwandte Lernempfehlungen: Python-Tutorial
Heute ist der sechste Artikel zum Thema Pandas-Datenverarbeitung. Sprechen wir über die Sortier- und Zusammenfassungsvorgänge von DataFrame.
Im vorherigen Artikel haben wir hauptsächlich die Apply-Methode in DataFrame vorgestellt, wie Broadcast-Vorgänge für jede Zeile oder Spalte in einem DataFrame ausgeführt werden, sodass wir die gesamten Daten in kurzer Zeit verarbeiten können. Heute werden wir darüber sprechen, wie wir einen DataFrame entsprechend unseren Anforderungen sortieren und wie wir einige Zusammenfassungsoperationen verwenden.
Sortieren ist für uns eine sehr grundlegende Anforderung. Bei Pandas ist diese Anforderung weiter unterteilt in Sortieren nach Index und Sortieren nach Wert. Schauen wir uns zunächst die Sortiermethode in Serie an.
Es gibt zwei Sortiermethoden in Series. Eine davon ist sort_index. Wie der Name schon sagt, werden diese Werte nach dem Index in Series sortiert. Der andere ist sort_values, der nach den Werten in der Serie sortiert wird. Beide Methoden geben eine neue Serie zurück: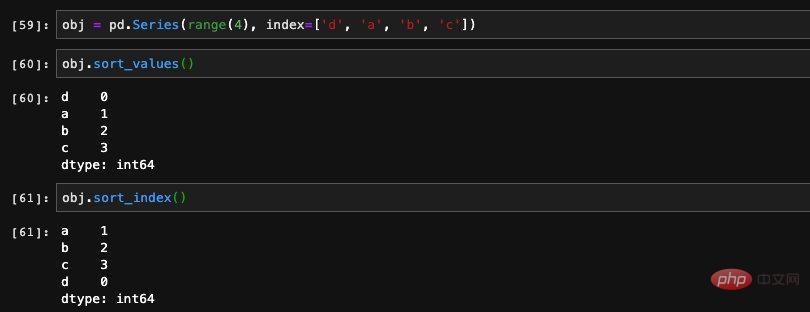
Standardmäßig sortieren wir nach dem Zeilenindex. Wenn wir die Sortierung nach dem Spaltenindex festlegen möchten, müssen wir den Parameter axis=1 übergeben. 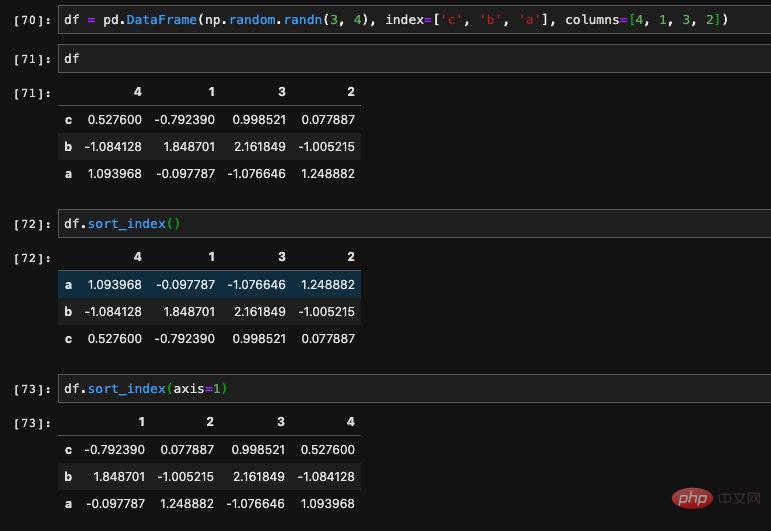
Wir können auch den aufsteigenden Parameter übergeben, um anzugeben, ob die gewünschte Sortierreihenfolge Vorwärtsreihenfolge oder Rückwärtsreihenfolge ist.
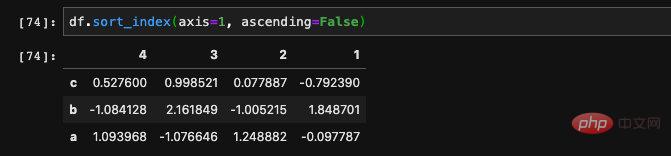
Die Wertesortierung von DataFrame ist anders, wir können keine Zeilen sortieren, nur Spalten. Wir übergeben die Spalte, nach der wir sortieren möchten, über den Parameter „by“, der eine Spalte oder mehrere Spalten sein kann.

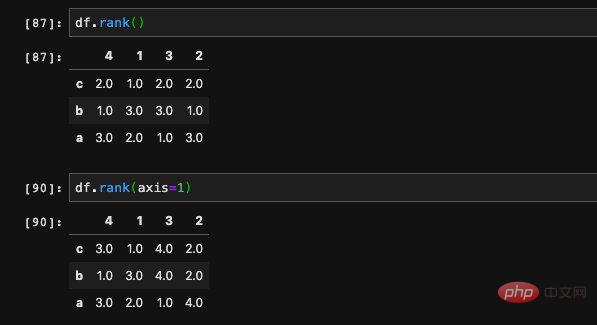
Manchmal möchten wir wissen, wo das aktuelle Element im Ganzen rangiert. Diese Funktion ist auch in Pandas verfügbar Rangmethode.
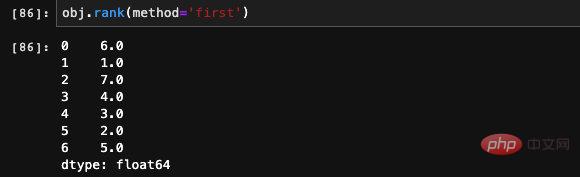
 Wir können feststellen, dass die Zahlenfolge, die wir beiläufig eingeben, zwei Siebenen enthält. 7 ist die größte Zahl in der Serie, aber warum ist ihr Rang 6,5?
Wir können feststellen, dass die Zahlenfolge, die wir beiläufig eingeben, zwei Siebenen enthält. 7 ist die größte Zahl in der Serie, aber warum ist ihr Rang 6,5? Tatsächlich ist es ganz einfach, denn 7 kommt zweimal vor, jeweils an der 6. und 7. Stelle. Die Rangfolge aller Vorkommen wird hier gemittelt, also 6,5. Wenn wir nicht möchten, dass es gemittelt wird, sondern stattdessen eine Rangfolge
basierend auf der Reihenfolge des Auftretens angeben, können wir den Methodenparameter verwenden, um den gewünschten Effekt anzugeben. Die rechtlichen Parameter der

Wenn es sich um einen DataFrame handelt, wird standardmäßig die Gesamtrangfolge der Elemente in jeder Zeile in Zeileneinheiten berechnet. Wir können die Berechnung auch in Spalteneinheiten über den Achsenparameter angeben:
Abschließend stellen wir die Zusammenfassungsoperation in DataFrame vor, die auch die Aggregationsoperation ist , wie zum Beispiel unsere gebräuchlichste Summenmethode, die einen Datenstapel aggregiert und summiert. Es gibt ähnliche Methoden in DataFrame. Schauen wir sie uns einzeln an.
Das erste ist sum. Wir können sum verwenden, um den DataFrame zu summieren. Wenn keine Parameter übergeben werden, wird standardmäßig jede Zeile summiert.

Neben der Summe wird auch häufig der Mittelwert verwendet, mit dem der Durchschnitt einer Zeile oder Spalte ermittelt werden kann.

Da es in DataFrame häufig NA-Elemente gibt, können wir den Parameter „skipna“ verwenden, um fehlende Werte auszuschließen und dann den Durchschnitt zu berechnen.
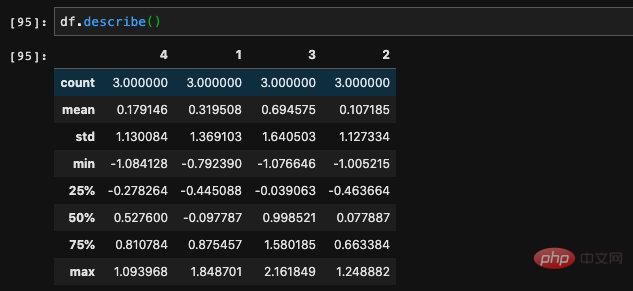
Eine weitere Methode, die ich persönlich sehr nützlich finde, ist descirbe, die die Gesamtinformationen im DataFrame zurückgeben kann. Zum Beispiel der Mittelwert, die Stichprobengröße, die Standardabweichung, der Minimalwert, der Maximalwert usw. jeder Spalte. Es handelt sich um eine häufig verwendete statistische Methode, mit der die Verteilung von Daten in DataFrame verstanden werden kann.
Zusätzlich zu den eingeführten Methoden gibt es in DataFrame viele ähnliche zusammenfassende Operationsmethoden wie idxmax, idxmin, var, std usw. Wenn Sie interessiert sind, können Sie die relevanten Dokumente überprüfen, aber meiner Erfahrung nach , verwenden Sie im Allgemeinen Kleiner als.
Wenn Sie mehr über das Programmieren erfahren möchten, achten Sie bitte auf die Rubrik „PHP-Schulung“!
Das obige ist der detaillierte Inhalt vonPandas-Fähigkeiten: Methoden zum Sortieren und Zusammenfassen in DataFrame. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



