
 Datenbank
MySQL-Tutorial
Was ist der Grund, warum der MySQL-Index die Abfrageeffizienz so stark verbessern kann?
Datenbank
MySQL-Tutorial
Was ist der Grund, warum der MySQL-Index die Abfrageeffizienz so stark verbessern kann?
Was ist der Grund, warum der MySQL-Index die Abfrageeffizienz so stark verbessern kann?


Hintergrund
Ich glaube, dass jeder über Indizes sprechen wird, wenn es um die Optimierung von Datenbanken geht, und ich bin keine Ausnahme. Jeder kann im Grunde eins, zwei, drei zur Optimierung von Datenstrukturen sowie zum Seiten-Caching und dergleichen beantworten Ein paar Sätze weiter oben, aber einmal wurde ich in einem Interview mit Alibaba P9 gefragt: Können Sie über den Prozess des Ladens von Indexdaten auf Computerebene sprechen? (Ich wollte nur, dass ich über IO spreche)
Ich bin auf der Stelle gestorben.... Denn das Grundwissen über Computernetzwerke und Betriebssysteme ist wirklich mein blinder Fleck, aber das habe ich später ohne weitere Umschweife nachgeholt Beginnen wir mit: Lassen Sie uns über das Laden von Daten durch den Computer sprechen. Lassen Sie uns über die Indizierung aus einem anderen Blickwinkel sprechen.
Text
Der Index von MySQL ist im Wesentlichen eine Datenstruktur
Lassen Sie uns zunächst das Laden der Daten auf den Computer verstehen.
Festplatten-IO und Vorlesen:

Das Lesen von Daten von der Festplatte erfordert jedes Mal drei Schritte: Suchen, Punktsuchen und Kopieren in den Speicher arbeiten.
Suchzeit ist die Zeit, die der Magnetarm benötigt, um sich zur angegebenen Spur zu bewegen, im Allgemeinen weniger als 5 ms; Eine halbe Umdrehungszeit, wenn Bei einer Festplatte mit 7200 U/min beträgt die durchschnittliche Punktsuchzeit 600000/7200/2=4,17 ms; Mal, also ein IO. Die durchschnittliche Zeit beträgt etwa 9 ms. Das hört sich schnell an, aber es dauert 9000 Sekunden, Millionen von Daten in der Datenbank zu durchsuchen, was offensichtlich eine Katastrophe ist.
Angesichts der Tatsache, dass Festplatten-IO ein sehr teurer Vorgang ist, hat das Computer-Betriebssystem das Vorlesen optimiert, nicht nur die Daten an der aktuellen Festplattenadresse, sondern auch die angrenzenden Die Daten werden auch in den Speicherpuffer eingelesen, denn wenn der Computer auf die Daten an einer Adresse zugreift, wird auch schnell auf die angrenzenden Daten zugegriffen.
Wir rufen die von IO jedes Mal gelesenen Daten auf. Die spezifische Größe der Daten auf einer Seite hängt normalerweise vom Betriebssystem ab. Das heißt, wenn wir die Daten auf einer Seite lesen Es ist ein IO aufgetreten. (Plötzlich fiel mir eine Frage ein, die mir kurz nach dem Abschluss gestellt wurde. Wie viele Bytes belegt der Typ int in Java in einem 64-Bit-Betriebssystem? Was ist das Maximum? Warum?)
(Plötzlich fiel mir eine Frage ein, die mir kurz nach dem Abschluss gestellt wurde. Wie viele Bytes belegt der Typ int in Java in einem 64-Bit-Betriebssystem? Was ist das Maximum? Warum?) 
MySQLs offizielle Definition von Index lautet: Index (Index) ist eine Datenstruktur, die MySQL dabei hilft, Daten effizient zu erhalten.
MySQL sind physisch in zwei Kategorien unterteilt: B-Tree-Indizes und Hash-Indizes. Dieses Mal sprechen wir hauptsächlich über den BTree-Index.
BTree-Index
BTree wird auch als mehrwegiger ausgeglichener Suchbaum bezeichnet. Die Eigenschaften eines M-Fork-BTree sind wie folgt:
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
MySQL 中常用的索引在物理上分两类,B-树索引和哈希索引。
本次主要讲BTree索引。
BTree索引
BTreeWenn der Wurzelknoten kein Blattknoten ist, muss er mindestens zwei untergeordnete Knoten haben.
- Alle Blattknoten befinden sich auf derselben Ebene.
- Jeder Nicht-Blattknoten besteht aus n Schlüsseln und n+1 Zeigern, wobei [ceil(m/2)-1] <= n <= m-1.
- Dies ist ein BTree-Strukturdiagramm mit 3 Zweigen (nur ein Beispiel, in der Realität wird es viele Zweige geben, die als Festplattenblock oder Block bezeichnet werden). Beim Lesen von Inhalten aus dem Speicher entspricht ein Block vier Sektoren. Lila stellt den Datenschlüssel im Plattenblock dar, Gelb stellt die Daten dar und Blau stellt den Zeiger p dar, der auf die Position des nächsten Plattenblocks zeigt.
- Lassen Sie uns den Prozess der Datensuche mit Schlüssel 29 simulieren:
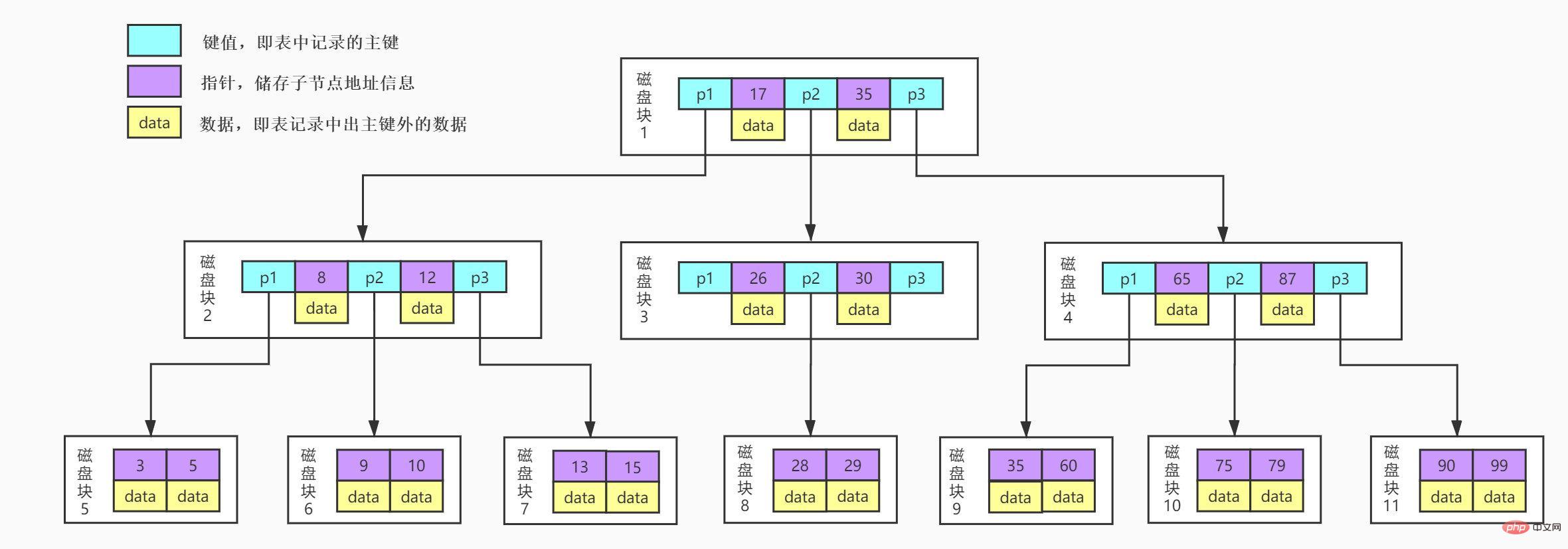 1 Mal
1 Mal2-mal]
4. Festplattenblock 3 speichert 26, 30 und drei Zeigerdaten. Wir finden 26<29<30, also finden wir den Zeiger p2.5. Gemäß dem p2-Zeiger lokalisieren und lesen wir den Plattenblock 8. [Festplatten-E/A-Vorgänge 3 Mal]
6, Festplattenblock 8 speichert 28, 29. Wir finden 29 und erhalten die Daten, die 29 entsprechen.
Es ist ersichtlich, dass der BTree-Index dafür sorgt, dass die Daten, die bei jeder Festplatten-E/A in den Speicher abgerufen werden, eine Rolle spielen, wodurch die Abfrageeffizienz verbessert wird.
Aber gibt es etwas, das optimiert werden kann?
Auf dem Bild können wir sehen, dass jeder Knoten nicht nur den Schlüsselwert der Daten, sondern auch den Datenwert enthält. Der Speicherplatz jeder Seite ist begrenzt. Wenn die Datenmenge groß ist, ist die Anzahl der Schlüssel, die in jedem Knoten gespeichert werden können (d. h. eine Seite), sehr gering zu B- Die Tiefe des Baums ist größer, was die Anzahl der Festplatten-E/As während der Abfrage erhöht und sich dadurch auf die Abfrageeffizienz auswirkt. Eine auf dem
B+Tree-Index
B+Tree是在B-Tree basierende Optimierung, die ihn besser für die Implementierung externer Speicherindexstrukturen geeignet macht. In B+Tree werden alle Datensatzknoten in der Reihenfolge ihres Schlüsselwerts auf Blattknoten gespeichert. Auf Nicht-Blattknoten werden nur Schlüsselwertinformationen gespeichert Knoten. Reduzieren Sie die Höhe von B+Baum.
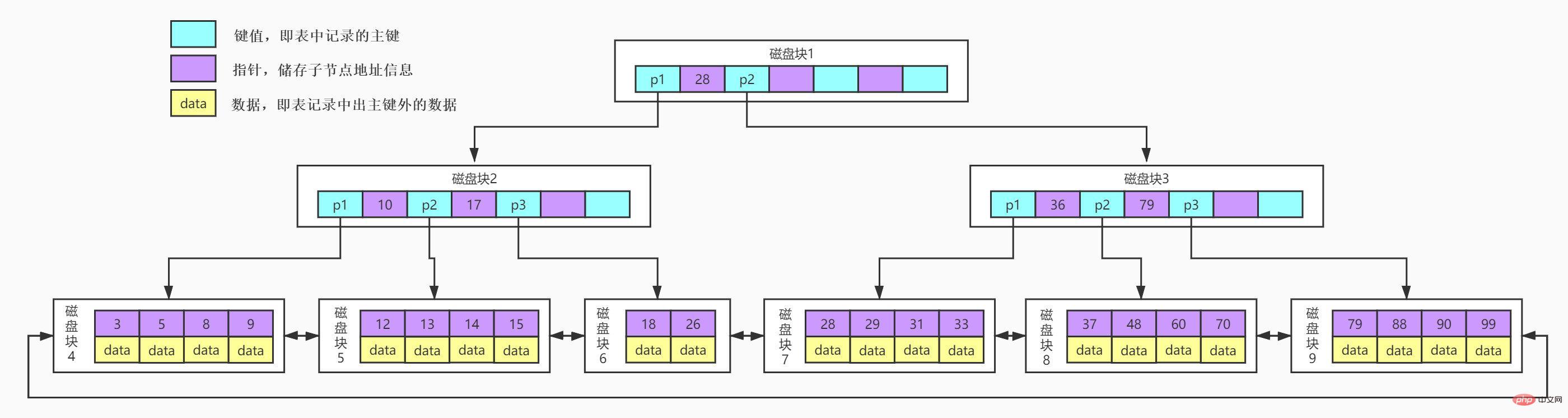
B+Tree weist im Vergleich zu B-Tree mehrere Unterschiede auf:
Nicht-Blattknoten speichern nur Schlüsselwertinformationen, und Datensätze werden in Blattknoten gespeichert. Optimieren Sie den B-Baum im vorherigen Abschnitt. Da die Nicht-Blattknoten von B+Tree nur Schlüsselwertinformationen speichern, kann die Höhe von B+Tree auf ein besonders niedriges Niveau komprimiert werden.
Die spezifischen Daten lauten wie folgt:
Die Seitengröße in der InnoDB-Speicher-Engine beträgt 16 KB. Der Primärschlüsseltyp der allgemeinen Tabelle ist INT (belegt 4 Bytes) oder BIGINT (belegt 8 Bytes). auch im Allgemeinen 4 Oder 8 Bytes, was bedeutet, dass eine Seite (ein Knoten in B + Baum) ungefähr 16 KB / (8B + 8B) = 1K Schlüsselwerte speichert (da es sich um eine Schätzung handelt und der Einfachheit halber die Berechnung erforderlich ist). Der Wert von K beträgt hier〖10〗^3).
Das heißt, ein B+Tree-Index mit einer Tiefe von 3 kann 10^3 10^3 10^3 = 1 Milliarde Datensätze verwalten. (Diese Berechnungsmethode weist Fehler auf und die Blattknoten werden nicht berechnet. Wenn die Blattknoten berechnet werden, beträgt die Tiefe tatsächlich 4)
Wir müssen nur drei E / A-Vorgänge ausführen, um die gewünschten Daten aus 1 Milliarde zu finden Datenstücke, im Vergleich zu den ursprünglichen Millionen Daten von 9000 Sekunden, ich weiß nicht, wie viele Wallaces besser sind.
Und in B+Tree gibt es normalerweise zwei Kopfzeiger, einer zeigt auf den Wurzelknoten und der andere zeigt auf den Blattknoten mit dem kleinsten Schlüsselwort, und zwischen allen Blattknoten (d. h. Datenknoten) besteht eine Kettenringstruktur. Daher können wir zusätzlich zur Primärschlüsselbereichssuche und Paging-Suche im B+Tree auch Zufallssuchen ausgehend vom Wurzelknoten durchführen.
Der B+Tree-Index in der Datenbank kann in Clustered-Index und Sekundärindex unterteilt werden.
Die Implementierung des B+Tree-Beispieldiagramms in der Datenbank ist ein Clustered-Index. Die Blattknoten im B+Tree des Clustered-Index speichern die Zeilendatensatzdaten der gesamten Tabelle Der Clustered-Index ist der Hilfsindex. Der Blattknoten enthält nicht alle Daten des Zeilendatensatzes, sondern den Clustered-Index-Schlüssel, der die entsprechenden Zeilendaten speichert, also den Primärschlüssel.
Beim Abfragen von Daten über den Hilfsindex durchläuft die InnoDB-Speicher-Engine den Hilfsindex, um den Primärschlüssel zu finden, und findet dann über den Primärschlüssel die vollständigen Zeilendatensatzdaten im Clustered-Index.
Obwohl Indizes Abfragen beschleunigen und die Verarbeitungsleistung von MySQL verbessern können, führt eine übermäßige Verwendung von Indizes auch zu den folgenden Nachteilen:
- Das Erstellen und Verwalten von Indizes nimmt Zeit in Anspruch, und dieser Zeitaufwand nimmt mit der Zeit zu mit der Datenmenge.
- Zusätzlich zum von der Datentabelle belegten Datenraum belegt jeder Index auch eine bestimmte Menge an physischem Platz. Wenn Sie einen Clustered-Index erstellen möchten, ist der erforderliche Speicherplatz größer.
- Beim Hinzufügen, Löschen und Ändern von Daten in der Tabelle muss der Index dynamisch verwaltet werden, was die Geschwindigkeit der Datenpflege verringert.
Hinweis: Indizes können in einigen Fällen Abfragen beschleunigen, in einigen Fällen jedoch die Effizienz verringern.
Der Index ist nur ein Faktor zur Verbesserung der Effizienz. Daher sollten beim Erstellen eines Index die folgenden Grundsätze befolgt werden:
- Das Erstellen von Indizes für häufig durchsuchte Spalten kann die Suche beschleunigen.
- Erstellen Sie einen Index für die Spalte als Primärschlüssel, erzwingen Sie die Eindeutigkeit der Spalte und organisieren Sie die Anordnungsstruktur der Daten in der Tabelle.
- Erstellen Sie Indizes für Spalten, die häufig für Tabellenverknüpfungen verwendet werden. Bei diesen Spalten handelt es sich hauptsächlich um Fremdschlüssel, die Tabellenverknüpfungen beschleunigen können.
- Erstellen Sie Indizes für Spalten, die häufig anhand von Bereichen durchsucht werden müssen, da der Index bereits sortiert ist und der angegebene Bereich daher zusammenhängend ist.
- Erstellen Sie Indizes für Spalten, die häufig sortiert werden müssen. Da der Index bereits sortiert ist, können Sie die Sortierung des Index beim Abfragen verwenden, um das Sortieren von Abfragen zu beschleunigen.
- Erstellen Sie Indizes für Spalten, die häufig WHERE-Klauseln verwenden, um die Beurteilung von Bedingungen zu beschleunigen.
Jetzt weiß jeder, warum der Index so schnell sein kann. Tatsächlich kann die Indexstruktur die Anzahl der E/A-Zeiten in der Datenbank minimieren. . .
Zusammenfassung
Was Interviews betrifft, können wir uns tatsächlich eine Menge Wissen leicht aneignen, aber zum Zweck des Lernens werden Sie viele Dinge finden, die wir tief in die Grundlagen von Computern eintauchen müssen, um sie zu entdecken Viele Leute fragen mich, wie man sich erinnert. Bei so vielen Dingen, in denen man leben kann, ist das Lernen selbst eine sehr hilflose Sache. Da wir es lernen müssen, warum nicht hart lernen? Lernen, es zu genießen? Vor kurzem habe ich mich auch mit den Grundlagen befasst und werde später damit beginnen, meine Computergrundlagen und Netzwerkkenntnisse zu aktualisieren.
Ich bin Ao Bing. Je mehr du weißt, desto mehr weißt du nicht. Bis zum nächsten Mal!
Talentss 【三连】 ist die größte Motivation für die Kreation von Ao Bing. Wenn es Fehler oder Vorschläge in diesem Blog gibt, können Talente gerne eine Nachricht hinterlassen!
Weitere verwandte kostenlose Lernempfehlungen: MySQL-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonWas ist der Grund, warum der MySQL-Index die Abfrageeffizienz so stark verbessern kann?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1385
1385
 52
52

 Mehrere Situationen, in denen ein MySQL-Index fehlschlägt
Feb 21, 2024 pm 04:23 PM
Mehrere Situationen, in denen ein MySQL-Index fehlschlägt
Feb 21, 2024 pm 04:23 PM
Häufige Situationen: 1. Verwenden Sie Funktionen oder Operationen; 3. Verwenden Sie ungleich (!= oder <>); Wert; 7. Niedrige Indexselektivität; 8. Prinzip des zusammengesetzten Indexes; 9. Optimierer-Entscheidung;
 Unter welchen Umständen schlägt der MySQL-Index fehl?
Aug 09, 2023 pm 03:38 PM
Unter welchen Umständen schlägt der MySQL-Index fehl?
Aug 09, 2023 pm 03:38 PM
MySQL-Indizes schlagen fehl, wenn Abfragen ohne Verwendung von Indexspalten, nicht übereinstimmenden Datentypen, falscher Verwendung von Präfixindizes, Verwendung von Funktionen oder Ausdrücken für Abfragen, falscher Reihenfolge von Indexspalten, häufigen Datenaktualisierungen und zu vielen oder zu wenigen Indizes erfolgen. 1. Verwenden Sie keine Indexspalten für Abfragen. 2. Bei der Gestaltung der Tabellenstruktur sollten Sie darauf achten, dass die Indexspalten übereinstimmen 3. Bei unsachgemäßer Verwendung des Präfixindex können Sie den Präfixindex verwenden.
 Wann könnte ein vollständiger Tabellen -Scan schneller sein als einen Index in MySQL?
Apr 09, 2025 am 12:05 AM
Wann könnte ein vollständiger Tabellen -Scan schneller sein als einen Index in MySQL?
Apr 09, 2025 am 12:05 AM
Die volle Tabellenscannung kann in MySQL schneller sein als die Verwendung von Indizes. Zu den spezifischen Fällen gehören: 1) das Datenvolumen ist gering; 2) Wenn die Abfrage eine große Datenmenge zurückgibt; 3) wenn die Indexspalte nicht sehr selektiv ist; 4) Wenn die komplexe Abfrage. Durch Analyse von Abfrageplänen, Optimierung von Indizes, Vermeidung von Überindex und regelmäßiger Wartung von Tabellen können Sie in praktischen Anwendungen die besten Auswahlmöglichkeiten treffen.
 Was sind die Klassifizierungen von MySQL-Indizes?
Apr 22, 2024 pm 07:12 PM
Was sind die Klassifizierungen von MySQL-Indizes?
Apr 22, 2024 pm 07:12 PM
MySQL-Indizes werden in die folgenden Typen unterteilt: 1. Gewöhnlicher Index: Übereinstimmung mit Wert, Bereich oder Präfix; 2. Eindeutiger Index: Stellt sicher, dass der Wert eindeutig ist. 3. Primärschlüsselindex: Eindeutiger Index der Primärschlüsselspalte Schlüsselindex: zeigt auf den Primärschlüssel einer anderen Tabelle; 5. Volltextindex: Suche nach gleicher Übereinstimmung; 8. Zusammengesetzter Index: Suche basierend auf mehreren Säulen.
 MySQL-Index-Linkspräfix-Matching-Regeln
Feb 24, 2024 am 10:42 AM
MySQL-Index-Linkspräfix-Matching-Regeln
Feb 24, 2024 am 10:42 AM
Prinzip des MySQL-Index ganz links: Prinzip und Codebeispiele In MySQL ist die Indizierung eines der wichtigsten Mittel zur Verbesserung der Abfrageeffizienz. Unter diesen ist das Indexprinzip ganz links ein wichtiges Prinzip, das wir befolgen müssen, wenn wir Indizes zur Optimierung von Abfragen verwenden. In diesem Artikel wird das Prinzip des MySQL-Index ganz links vorgestellt und einige spezifische Codebeispiele gegeben. 1. Das Prinzip des Index-Prinzips ganz links Das Prinzip des Index ganz links bedeutet, dass in einem Index, wenn die Abfragebedingung aus mehreren Spalten besteht, nur die Spalte ganz links im Index abgefragt werden kann, um die Abfragebedingungen vollständig zu erfüllen.
 Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
MySQL unterstützt vier Indextypen: B-Tree, Hash, Volltext und räumlich. 1.B-Tree-Index ist für die gleichwertige Suche, eine Bereichsabfrage und die Sortierung geeignet. 2. Hash -Index ist für gleichwertige Suche geeignet, unterstützt jedoch keine Abfrage und Sortierung von Bereichs. 3. Die Volltextindex wird für die Volltext-Suche verwendet und ist für die Verarbeitung großer Mengen an Textdaten geeignet. 4. Der räumliche Index wird für die Abfrage für Geospatial -Daten verwendet und ist für GIS -Anwendungen geeignet.
 Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen!
Sep 10, 2023 pm 03:16 PM
Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen!
Sep 10, 2023 pm 03:16 PM
Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen! Einleitung: Im heutigen Internetzeitalter wächst die Datenmenge weiter und die Optimierung der Datenbankleistung ist zu einem sehr wichtigen Thema geworden. Als eine der beliebtesten relationalen Datenbanken ist die rationelle Nutzung von Indizes durch MySQL von entscheidender Bedeutung für die Verbesserung der Datenbankleistung. In diesem Artikel erfahren Sie, wie Sie MySQL-Indizes rational nutzen, die Datenbankleistung optimieren und einige Designregeln für Technikstudenten bereitstellen. 1. Warum Indizes verwenden? Ein Index ist eine Datenstruktur, die verwendet
 Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung
Oct 15, 2023 pm 12:15 PM
Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung
Oct 15, 2023 pm 12:15 PM
Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung. Zusammenfassung: In der Entwicklung von PHP und MySQL sind Indizes ein wichtiges Werkzeug zur Optimierung der Datenbankabfrageleistung. In diesem Artikel werden die Grundprinzipien und die Verwendung von Indizes vorgestellt und die Auswirkungen von Indizes auf die Leistung bei der Datenaktualisierung und -wartung untersucht. Gleichzeitig bietet dieser Artikel auch einige Strategien zur Leistungsoptimierung und spezifische Codebeispiele, um Entwicklern zu helfen, Indizes besser zu verstehen und anzuwenden. Grundprinzipien und Verwendung von Indizes In MySQL ist ein Index eine spezielle Zahl
