
 Datenbank
Redis
Eine einfache und leicht verständliche Einführung in die Caching-Prinzipien von Redis
Datenbank
Redis
Eine einfache und leicht verständliche Einführung in die Caching-Prinzipien von Redis
Eine einfache und leicht verständliche Einführung in die Caching-Prinzipien von Redis

Die Kolumne „Redis-Tutorial“ führt Sie in das Caching-Prinzip von „Redis“ ein. Ich hoffe, dass es Freunden, die es benötigen, hilfreich sein wird! 1. Was ist Redis? Redis wird im Schlüsselwertformat gespeichert, das sich von herkömmlichen relationalen Datenbanken unterscheidet. Es folgt nicht unbedingt einigen grundlegenden Anforderungen herkömmlicher Datenbanken, beispielsweise nicht den SQL-Standards, Transaktionen, Tabellenstrukturen usw. Nicht-relationale Datenbanken sind streng genommen keine Datenbank, sondern eine Sammlung strukturierter Datenspeichermethoden. Datenstrukturen in Java: String, Array, Liste, Set Map ... Redis bietet viele Methoden, mit denen auf Daten in verschiedenen Datenstrukturen zugegriffen werden kann. 2. Funktionen (Vorteile) ), set (Satz), zset (sortierter Satz – geordneter Satz) und Hash (Hash-Typ). 3. Das Aufkommen von Redis hat die Mängel der Schlüssel-/Wertspeicherung wie Memcached weitgehend ausgeglichen. In einigen Fällen kann es eine sehr gute Ergänzungsrolle zu relationalen Datenbanken (wie MySQL) spielen. 4. Es bietet Java, C/C++, C#, PHP, JavaScript und andere Clients, was sehr bequem zu verwenden ist. 5.Redis unterstützt Clustering (Master-Slave-Synchronisation, Lastausgleich). Daten können vom Master-Server mit einer beliebigen Anzahl von Slave-Servern synchronisiert werden, und der Slave-Server kann der Master-Server sein, der mit anderen Slave-Servern verbunden ist. 6. Unterstützt Persistenz, Daten können in Dateien auf der Festplatte gespeichert werden. 7. Unterstützt die Abonnement-/Veröffentlichungsfunktion der QQ-Gruppe. 1. Datenspeicherung: wird im Speicher gespeichert und kann von Zeit zu Zeit auf der Festplatte gespeichert werden. Die Zugriffsgeschwindigkeit ist hoch, die Parallelitätsfähigkeit ist stark und die Daten gehen nach einem Stromausfall nicht verloren.
2. Unterstützt mehr Werttypen. 3. Mehrere Clients (Sprache Java PHP C# JS)  4. Unterstützungscluster zur Erweiterung des Speicherplatzes 8G+8G+16G
4. Unterstützungscluster zur Erweiterung des Speicherplatzes 8G+8G+16G
The Die offizielle Download-Site von Redis ist http://redis.io/download. Sie können das neueste Installationsprogramm von dort herunterladen.
3.1. Installation und Verwendung unter Windows. 1. Laden Sie die Redis-Programmsoftware herunter. Verwenden Sie redisbin32 oder redisbin64. 2. Grün Software, keine Installation erforderlich, direkt verwenden3. Starten Sie den Redis-Dienst (beginnen Sie mit der Konfigurationsdatei und starten Sie ohne Konfigurationsdatei)
4. Stellen Sie für den Betrieb eine Verbindung zu Redis hercmd>{%redis%}/redis -cli -h IP-Adresse -p Portnummer IP ist standardmäßig lokal -p ist standardmäßig 6379 redis-cli -h 172.16.6.248 -p 6379
cmd>{%redis%}/redis-cli
Grundlegende Verwendung
2. Redis-Persistenzkonfiguration wird beibehalten und gespeichert, und die Daten, die noch nicht gespeichert wurden, werden in Form eines AOF-Protokolls gespeichert.
Wenn Redis startet, analysiert es zunächst die Protokolldatei (eine Reihe von Befehlen) und stellt die Daten wieder her. Laden Sie dann auch die RDB-Datei (nehmen Sie die Union).
4.RDB-Modus
RDB-Persistenz kann Point-in-Time-Snapshots des Datensatzes innerhalb eines bestimmten Zeitintervalls generieren.
Speichern Sie „“ save 900 1 //Mindestens Es gibt mindestens eine Änderung an der Speichersynchronisierung innerhalb eines Zeitraums von 900 Sekunden save xxx save 60 10000
5
AOF zeichnet dauerhaft alle vom Server ausgeführten Schreiboperationsbefehle auf und stellt den Datensatz wieder her, indem diese Befehle beim Serverstart erneut ausgeführt werden. Dieser Modus ist standardmäßig deaktiviert.
So aktivieren Sie den AOF-Modus:
appendonly yes //Yes ist aktiviert, No ist deaktiviert
#appendfsync Always //Führen Sie fsync jedes Mal aus, wenn ein neuer Befehl vorliegt, und fügen Sie die Pufferdaten in die AOF-Datei ein
#Hier aktivieren wir everysec
appendfsync everysec //fsync einmal pro Sekunde
#appendfsync no //Nie fsync (überlassen Sie die Handhabung dem Betriebssystem, die Ausführung von fsync kann lange dauern)
Weitere Parameter finden Sie in der Konfigurationsdatei redis.conf für eine ausführliche Erklärung
6.Redis Klassisches praktisches Szenario – Cache
-
6.1 Warum Cache verwenden
Speichern Sie häufig abgefragte Daten und selten geänderte Daten im Cache, um den Zugriff auf die Datenbank zu reduzieren und den Datenbankdruck zu verringern im Allgemeinen im Speicher und die Zugriffsgeschwindigkeit ist relativ hoch.
-
6.2 Welche Daten eignen sich für die Speicherung im Cache?
Häufig abfragen: Beim Caching soll ein effizienter Zugriff auf Datenabfragen gewährleistet werden.
Selten geändert: Beim Ändern müssen Cache und Datenbank gleichzeitig geändert werden.
Zum Beispiel: Regionaldaten, Produktklassifizierung, Datenwörterbuchmenü (unabhängig von den Berechtigungen) -
6.3 Wählen Sie den entsprechenden Cache.
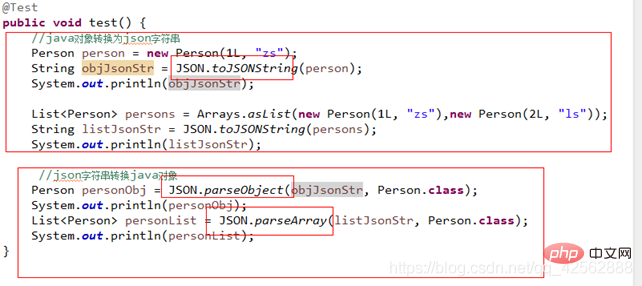
Cache der zweiten Ebene im Ruhezustand. Mybatis-Cache der zweiten Ebene, zentraler Redis-Cache. Ruhezustand des Caches der zweiten Ebene. Der Cache der zweiten Ebene von Mybatis unterstützt standardmäßig keinen Cluster-Cache soll in einem JSON-Typ-String gespeichert werden
Java-Objekt----------->json-String
Beim Speichern des Caches: Abrufen des Caches: - JSON-String--------> Java Object-
Json-Framework: jdk-json-lib jackson gson fastjson
2) Binärer Speicher: Serialisieren Sie die zu speichernden Daten in einem binären Serialisierungs-Framework, um sie zu implementieren
7. Menü-Caching implementieren
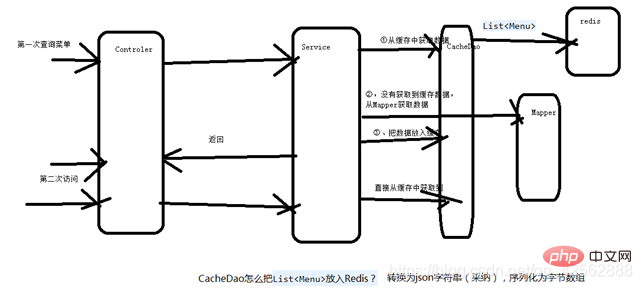
Das obige ist der detaillierte Inhalt vonEine einfache und leicht verständliche Einführung in die Caching-Prinzipien von Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1385
1385
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
Redis unterstützt als Messing Middleware Modelle für Produktionsverbrauch, kann Nachrichten bestehen und eine zuverlässige Lieferung sicherstellen. Die Verwendung von Redis als Message Middleware ermöglicht eine geringe Latenz, zuverlässige und skalierbare Nachrichten.
