
In der Kolumne
Java-Grundlagen wird heute das Caching-Kapitel des Java-Systemdesigns mit hoher Parallelität vorgestellt.

Die Latenz gängiger Hardwarekomponenten ist wie folgt: 
Aus diesen Daten können Sie ersehen, dass es etwa 100 ns dauert, eine Speicheradresse durchzuführen, und 10 ms, um eine Festplattensuche durchzuführen. Es ist ersichtlich, dass die Leistung im Vergleich zu einer Datenbank, die die Festplatte als Hauptspeichermedium verwendet, um viele Größenordnungen verbessert wird, wenn wir Speicher als Cache-Speichermedium verwenden. Daher ist der Speicher das am häufigsten verwendete Medium zum Zwischenspeichern von Daten.
2. Die Kurzvideos auf der Douyin-Plattform werden tatsächlich mit dem integrierten Netzwerkplayer erstellt. Der Netzwerkplayer empfängt den Datenstrom, lädt die Daten herunter, trennt die Audio- und Videoströme, dekodiert und verarbeitet andere Prozesse und gibt sie dann zur Wiedergabe an das Peripheriegerät aus. Einige Caching-Komponenten sind im Player normalerweise so konzipiert, dass sie einen Teil der Videodaten zwischenspeichern, wenn wir beispielsweise Douyin öffnen. Wenn wir das erste Video abspielen, gibt der Server möglicherweise drei Videoinformationen zurück Wir haben einen Teil der Daten des zweiten und dritten Videos für uns zwischengespeichert, um den Nutzern beim Ansehen des zweiten Videos das Gefühl zu geben, „in Sekunden zu starten“.
Wenn wir zum ersten Mal eine statische Ressource, z. B. ein Bild, anfordern, verfügt der Server zusätzlich zur Rückgabe der Bildinformationen über ein „Etag“-Feld im Antwortheader. Der Browser speichert die Bildinformationen und den Wert dieses Felds zwischen. Wenn das Bild das nächste Mal angefordert wird, gibt es im vom Browser initiierten Anforderungsheader ein Feld „If-None-Match“, in das der zwischengespeicherte „Etag“-Wert geschrieben und an den Server gesendet wird. Der Server prüft, ob sich die Bildinformationen geändert haben. Andernfalls wird ein 304-Statuscode an den Browser zurückgegeben und der Browser verwendet weiterhin die zwischengespeicherten Bildinformationen. Durch diese Cache-Aushandlungsmethode kann die über das Netzwerk übertragene Datengröße reduziert und dadurch die Leistung der Seitenanzeige verbessert werden.
2. Cache-Klassifizierung Statischer Cache ist in der Web 1.0-Ära sehr beliebt. Durch die Bereitstellung statischer Caches auf Nginx kann der Bedarf reduziert werden Druck auf den Backend-Anwendungsserver
Statischer Cache ist in der Web 1.0-Ära sehr beliebt. Durch die Bereitstellung statischer Caches auf Nginx kann der Bedarf reduziert werden Druck auf den Backend-Anwendungsserver
3. Lokaler Cache oder Ehcache usw. Sie werden im selben Prozess wie die Anwendung bereitgestellt Es ist im gesamten Netzwerk geplant und die Geschwindigkeit ist extrem hoch, so dass damit Hot-Anfragen in kurzer Zeit blockiert werden können.
aktualisiert den Cache nicht, wenn Daten aktualisiert werden, sondern löscht die Daten im Cache Cache und dann Daten aus der Datenbank lesen und im Cache aktualisieren.
Diese Strategie ist die am häufigsten verwendete Strategie für das Caching, die Cache-Aside-Strategie (auch Bypass-Cache-Strategie genannt). Diese Strategiedaten basieren auf den Daten in der Datenbank und die Daten im Cache werden bei Bedarf geladen . Die Cache-Aside-Strategie ist die am häufigsten verwendete Caching-Strategie in unserer täglichen Entwicklung. Wir müssen jedoch auch lernen, sie je nach Situation zu ändern. Sie ist nicht statisch. Das größte Problem bei Cache Aside besteht darin, dass bei häufigen Schreibvorgängen die Daten im Cache häufig gelöscht werden, was einen gewissen Einfluss auf die Cache-Trefferquote hat. Wenn Ihr Unternehmen strenge Anforderungen an die Cache-Trefferquote stellt, können Sie zwei Lösungen in Betracht ziehen:Eine Möglichkeit besteht darin, den Cache beim Aktualisieren der Daten zu aktualisieren, aber vor dem Aktualisieren des Caches eine verteilte Sperre hinzuzufügen, da auf diese Weise nur ein Thread gleichzeitig den Cache aktualisieren darf und keine Parallelitätsprobleme auftreten. Dies hat natürlich einige Auswirkungen auf die Schreibleistung (empfohlen);
Ein anderer Ansatz besteht darin, den Cache beim Aktualisieren von Daten zu aktualisieren, aber dem Cache einfach eine kürzere Ablaufzeit hinzuzufügen, damit der Cache auch dann im Cache gespeichert wird, wenn eine Inkonsistenz auftritt Daten verfallen zudem schnell und die Auswirkungen auf das Geschäft sind akzeptabel.
Das Kernprinzip dieser Strategie besteht darin, dass Benutzer sich nur mit dem Cache befassen und der Cache mit der Datenbank kommuniziert, um Daten zu schreiben oder zu lesen. Die Strategie von 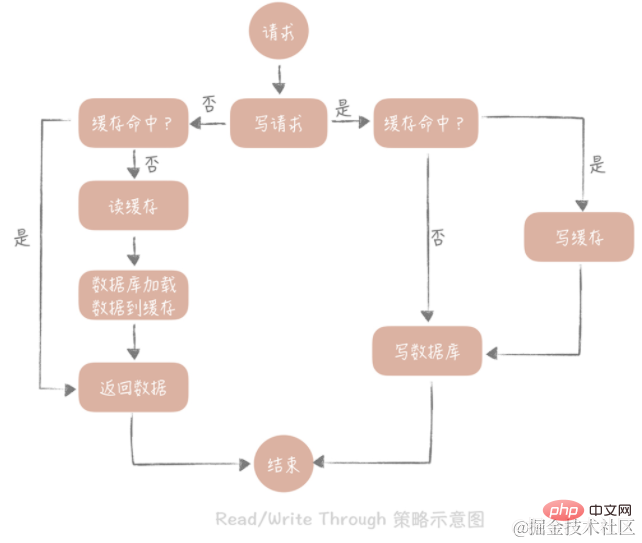
Write Through
lautet wie folgt: Fragen Sie zunächst ab, ob die zu schreibenden Daten bereits im Cache vorhanden sind. Wenn sie bereits vorhanden sind, aktualisieren Sie die Daten im Cache und synchronisieren Sie sie mit der Datenbank Wenn die Daten nicht im Cache vorhanden sind, nennen wir diese Situation „Write Miss“. Im Allgemeinen können wir zwei „Write Miss“-Methoden wählen: Eine ist „Write Allocate (Distribute by Write)“, bei der der entsprechende Speicherort in den Cache geschrieben wird und die Cache-Komponente ihn dann synchron in der Datenbank aktualisiert ist „No -write allocate (nicht beim Schreiben zuweisen)“, die Methode besteht nicht darin, in den Cache zu schreiben, sondern direkt in die Datenbank zu aktualisieren. Wir sehen, dass das Schreiben in die Datenbank bei der Write-Through-Strategie synchron erfolgt, was einen größeren Einfluss auf die Leistung hat, da die Latenz beim synchronen Schreiben in die Datenbank im Vergleich zum Schreiben in den Cache viel höher ist. Aktualisieren Sie die Datenbank asynchron über die Write-Back-Strategie.
Durchlesen
Die Strategie ist einfacher: Fragen Sie zunächst ab, ob die Daten im Cache vorhanden sind, und geben Sie sie direkt zurück, wenn sie nicht vorhanden sind Laden der Daten synchron aus der Datenbank.
Die Kernidee dieser Strategie besteht darin, beim Schreiben von Daten nur in den Cache zu schreiben und die Cache-Blöcke als „schmutzig“ zu markieren. Die Daten in Dirty-Blöcken werden erst bei erneuter Verwendung in den Back-End-Speicher geschrieben.
Im Fall von „Write Miss“ verwenden wir die Methode „Write Allocate“, was bedeutet, dass in den Cache geschrieben wird, während in den Backend-Speicher geschrieben wird, sodass wir bei nachfolgenden Schreibanfragen nur den Cache aktualisieren müssen, ohne das Backend zu aktualisieren Lagerung. Beachten Sie den Unterschied zur oben beschriebenen Write-Through-Strategie. 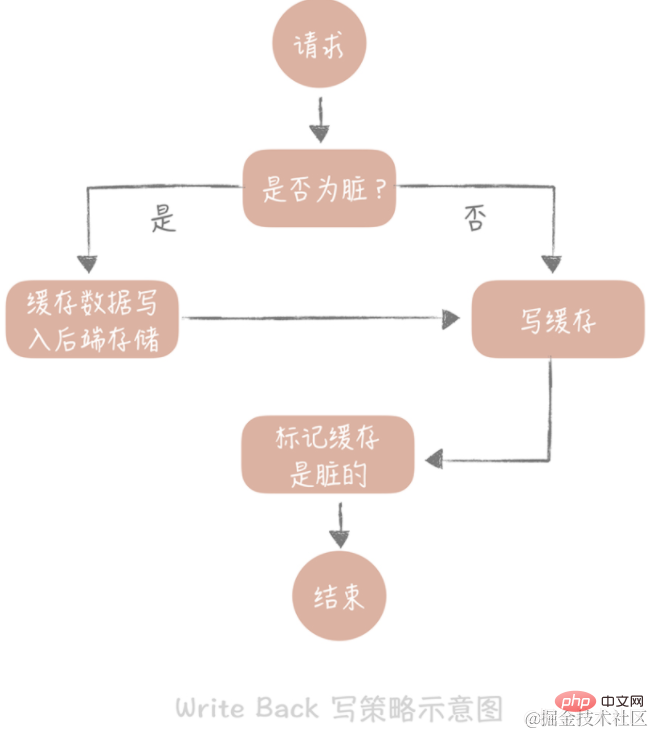
Wenn wir beim Lesen des Caches einen Cache-Treffer finden, geben wir die Cache-Daten direkt zurück. Wenn der Cache fehlschlägt, sucht er nach einem verfügbaren Cache-Block. Wenn der Cache-Block „verschmutzt“ ist, werden die vorherigen Daten im Cache-Block in den Back-End-Speicher geschrieben und die Daten werden aus dem Back-End-Speicher geladen Wenn der Block nicht verschmutzt ist, lädt die Cache-Komponente die Daten im Back-End-Speicher in den Cache. Schließlich stellen wir den Cache so ein, dass er nicht verschmutzt ist, und geben die Daten zurück. 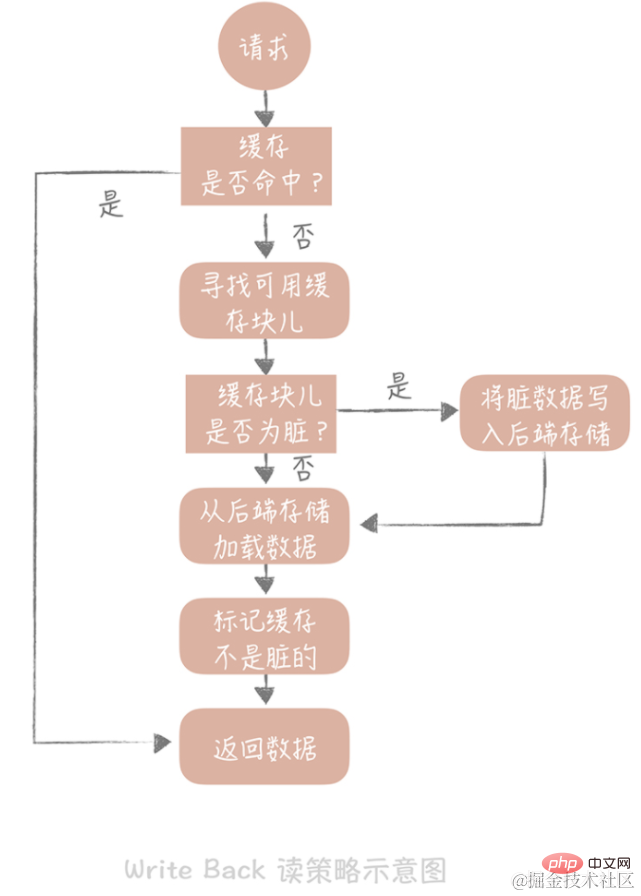
Die Write-Back-Strategie wird hauptsächlich zum Schreiben von Daten auf die Festplatte verwendet. Zum Beispiel: Seitencache auf Betriebssystemebene, asynchrones Leeren von Protokollen, asynchrones Schreiben von Nachrichten in der Nachrichtenwarteschlange auf die Festplatte usw. Da der Leistungsvorteil dieser Strategie unbestritten ist, vermeidet sie das Problem des zufälligen Schreibens, das durch das direkte Schreiben auf die Festplatte verursacht wird. Schließlich unterscheidet sich die Latenz zufälliger E/A beim Schreiben in den Speicher und beim Schreiben auf die Festplatte um mehrere Größenordnungen.
Die Cache-Trefferrate ist ein Datenindikator, der vom Cache überwacht werden muss. Die hohe Verfügbarkeit des Caches kann die Wahrscheinlichkeit einer Cache-Penetration bis zu einem gewissen Grad verringern und die Stabilität des Systems verbessern . Hochverfügbarkeitslösungen für das Caching umfassen hauptsächlich drei Kategorien: clientseitige Lösungen, Zwischen-Proxy-Layer-Lösungen und serverseitige Lösungen:
Bei der clientseitigen Lösung müssen Sie darauf achten die Schreib- und Leseaspekte des Caches: Beim Schreiben von Daten müssen die in den Cache geschriebenen Daten auf mehrere Knoten verteilt werden, dh es wird ein Daten-Sharding durchgeführt. Beim Lesen von Daten können zur Fehlertoleranz mehrere Cache-Sätze verwendet werden, um die Verfügbarkeit des Cache-Systems zu verbessern. Bezüglich des Lesens von Daten können hier zwei Strategien verwendet werden: Master-Slave und Multi-Copy. Die beiden Strategien werden zur Lösung unterschiedlicher Probleme vorgeschlagen. Zu den spezifischen Implementierungsdetails gehören: Daten-Sharding, Master-Slave, mehrere Kopien
Daten-Sharding
Konsistenter Hash-Algorithmus. Bei diesem Algorithmus organisieren wir den gesamten Hash-Wertraum in einem virtuellen Ring, hashen dann die IP-Adresse oder den Hostnamen des Cache-Knotens und platzieren ihn im Ring. Wenn wir bestimmen müssen, auf welchen Knoten ein bestimmter Schlüssel zugreifen muss, ermitteln wir zunächst den gleichen Hash-Wert für den Schlüssel, bestimmen seine Position auf dem Ring und „laufen“ dann im Uhrzeigersinn auf dem Ring Der erste Cache-Knoten ist der Knoten, auf den zugegriffen werden soll. 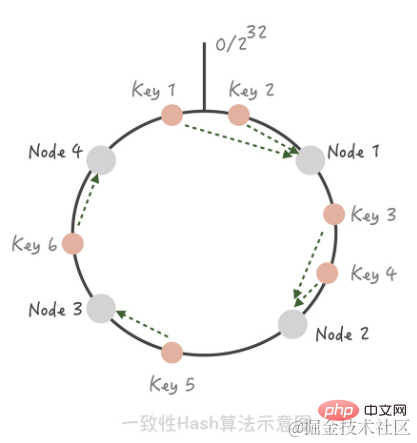
Wenn Sie zu diesem Zeitpunkt einen Knoten 5 zwischen Knoten 1 und Knoten 2 hinzufügen, können Sie sehen, dass Schlüssel 3, der ursprünglich Knoten 2 traf, jetzt Knoten 5 trifft, während sich die anderen Schlüssel nicht auf die gleiche Weise geändert haben Das Entfernen von Knoten 3 aus dem Cluster wirkt sich nur auf Schlüssel 5 aus. Sie sehen also, dass beim Hinzufügen und Löschen von Knoten nur eine kleine Anzahl von Schlüsseln auf andere Knoten „driftet“, während die von den meisten Schlüsseln getroffenen Knoten unverändert bleiben, wodurch sichergestellt wird, dass die Trefferquote nicht wesentlich sinkt. [Tipp] Verwenden Sie virtuelle Knoten, um das Cache-Lawine-Phänomen zu lösen, das bei konsistentem Hashing auftritt. Der Unterschied zwischen konsistentem Hash-Sharding und Hash-Sharding ist das Problem der Cache-Trefferrate. Wenn Hash-Sharding hinzugefügt oder reduziert wird, wird der Cache ungültig und die Cache-Trefferrate sinkt.
Master-Slave
Redis selbst unterstützt die Master-Slave-Bereitstellungsmethode, Memcached unterstützt sie jedoch nicht. Wie wird der Master-Slave-Mechanismus von Memcached auf dem Client implementiert? Konfigurieren Sie für jede Mastergruppe einen Satz Slaves. Beim Aktualisieren von Daten werden die Master und Slaves gleichzeitig aktualisiert. Beim Lesen werden die Daten zuerst vom Slave gelesen. Wenn die Daten nicht gelesen werden können, werden sie über den Master gelesen und die Daten werden an den Slave zurückgesendet, um die Slave-Daten auf dem neuesten Stand zu halten. Der größte Vorteil des Master-Slave-Mechanismus besteht darin, dass beim Ausfall eines bestimmten Slaves der Master als Backup fungiert und nicht viele Anforderungen in die Datenbank eindringen, was die hohe Verfügbarkeit des Cache-Systems verbessert.
Mehrere Kopien
Die Master-Slave-Methode kann die Probleme in den meisten Szenarien lösen. In extremen Verkehrsszenarien kann eine Gruppe von Slaves jedoch normalerweise nicht den gesamten Datenverkehr bewältigen, und die Bandbreite der Slave-Netzwerkkarte kann beeinträchtigt werden ein Engpass. Um dieses Problem zu lösen, erwägen wir das Hinzufügen einer Kopierebene vor Master/Slave. Die Gesamtarchitektur sieht wie folgt aus: 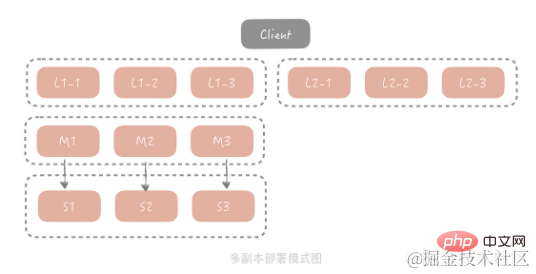
Wenn der Client bei dieser Lösung eine Abfrageanforderung initiiert, wird die Anforderung zunächst aus mehreren Kopiergruppen ausgewählt Eine Kopiengruppe initiiert eine Abfrage. Wenn die Abfrage fehlschlägt, fragt sie weiterhin den Master/Slave ab und die Abfrageergebnisse werden an alle Kopiengruppen zurückgesendet, um das Vorhandensein fehlerhafter Daten in der Kopiengruppe zu vermeiden. Aus Kostengründen ist die Kapazität jeder Kopiergruppe kleiner als die von Master und Slave, sodass nur heißere Daten gespeichert werden. In dieser Architektur wird das Anforderungsvolumen von Master und Slave erheblich reduziert. Um die Wärme der von ihnen gespeicherten Daten sicherzustellen, werden wir in der Praxis Master und Slave als Kopiergruppe verwenden.
Es gibt auch viele Zwischen-Proxy-Schicht-Lösungen in der Branche, wie zum Beispiel Facebooks Mcrouter, Twitters Twemproxy und Wandoujias Codis. Ihre Prinzipien lassen sich im Wesentlichen durch ein Bild zusammenfassen: 
Redis hat in Version 2.4 den Redis Sentinel-Modus vorgeschlagen, um das Hochverfügbarkeitsproblem während der Master-Slave-Redis-Bereitstellung zu lösen Knoten Nach dem Ausfall wird der Slave-Knoten automatisch zum Master-Knoten hochgestuft, um die Verfügbarkeit des gesamten Clusters sicherzustellen. Die Gesamtarchitektur ist wie in der folgenden Abbildung dargestellt: 
redis Sentinel wird auch im Cluster bereitgestellt, was möglich ist Vermeiden Sie das Problem der automatischen Fehlerwiederherstellung, die durch den Ausfall des Sentinel-Knotens verursacht wird. Jeder Sentinel-Knoten ist zustandslos. Die Adresse des Masters wird in Sentinel konfiguriert. Wenn festgestellt wird, dass der Master nicht innerhalb des konfigurierten Zeitintervalls antwortet, wird davon ausgegangen, dass der Master ausgefallen ist wählt einen der Slave-Knoten aus und befördert ihn zum Master-Knoten. Alle anderen Slave-Knoten werden als Slave-Knoten für den neuen Master behandelt. Während der Schlichtung innerhalb des Sentinel-Clusters wird anhand des konfigurierten Werts festgestellt, dass mehrere Sentinel-Knoten einen Master-Slave-Umschaltvorgang durchführen können. Das heißt, der Cluster muss einen Konsens erzielen der Status des Cache-Knotens.
[Tipp] Die Verbindungslinie vom oben genannten Client zum Sentinel-Cluster ist eine gepunktete Linie, da Schreib- und Leseanforderungen für den Cache nicht über den Sentinel-Knoten geleitet werden.
Das Datenzugriffsmodell von Internetsystemen folgt im Allgemeinen dem „80/20-Prinzip“. Das „80/20-Prinzip“, auch Pareto-Prinzip genannt, ist eine Wirtschaftstheorie des italienischen Ökonomen Pareto. Einfach ausgedrückt bedeutet dies, dass bei einer Reihe von Dingen der wichtigste Teil normalerweise nur 20 % ausmacht, während die anderen 80 % nicht so wichtig sind. Wenn wir dies auf den Bereich des Datenzugriffs anwenden, greifen wir häufig auf 20 % der heißen Daten zu, während auf die anderen 80 % der Daten nicht häufig zugegriffen wird. Da die Cache-Kapazität begrenzt ist und die meisten Zugriffe nur 20 % der Hotspot-Daten anfordern, müssen wir theoretisch nur 20 % der Hotspot-Daten im begrenzten Cache-Speicherplatz speichern, um das fragile Back-End-System effektiv zu schützen kann auf das Zwischenspeichern der anderen 80 % der nicht heißen Daten verzichten. Diese geringe Cache-Penetration ist also unvermeidlich, schadet dem System jedoch nicht.
Wenn wir einen Nullwert aus der Datenbank abfragen oder eine Ausnahme auftritt, können wir einen Nullwert an den Cache zurückgeben. Da der Nullwert jedoch keine genauen Geschäftsdaten darstellt und Cache-Speicherplatz belegt, fügen wir dem Nullwert eine relativ kurze Ablaufzeit hinzu, damit der Nullwert schnell ablaufen und in kurzer Zeit gelöscht werden kann. Obwohl die Rückgabe von Nullwerten eine große Anzahl eindringender Anforderungen blockieren kann, wird auch der Cache-Speicherplatz verschwendet, wenn eine große Anzahl von Nullwerten zwischengespeichert wird. Wenn der Cache-Speicherplatz voll ist, werden einige Benutzerinformationen gelöscht Der Cache wird ebenfalls entfernt, im Gegenteil, die Cache-Trefferquote sinkt. Daher empfehle ich Ihnen zu prüfen, ob die Cache-Kapazität diese Lösung bei der Verwendung unterstützen kann. Wenn zur Unterstützung eine große Anzahl von Cache-Knoten erforderlich ist, kann das Problem nicht durch Setzen von Nullwerten gelöst werden. In diesem Fall können Sie die Verwendung eines Bloom-Filters in Betracht ziehen.
1970 schlug Bloom einen Bloom-Filteralgorithmus vor, um zu bestimmen, ob ein Element in einer Menge enthalten ist. Dieser Algorithmus besteht aus einem binären Array und einem Hash-Algorithmus. Seine Grundidee ist wie folgt: Wir berechnen den entsprechenden Hash-Wert für jeden Wert im Satz gemäß dem bereitgestellten Hash-Algorithmus und modulieren dann den Hash-Wert auf die Array-Länge, um den Indexwert zu erhalten, der in das Array aufgenommen werden muss Fügen Sie den Indexwert an dieser Position des Arrays hinzu. Der Wert wurde von 0 auf 1 geändert. Bei der Beurteilung, ob ein Element in dieser Menge vorhanden ist, müssen Sie nur den Indexwert des Elements nach demselben Algorithmus berechnen. Wenn der Wert dieser Position 1 ist, wird davon ausgegangen, dass sich das Element in der Menge befindet, andernfalls ist dies der Fall gelten als nicht im Set enthalten. 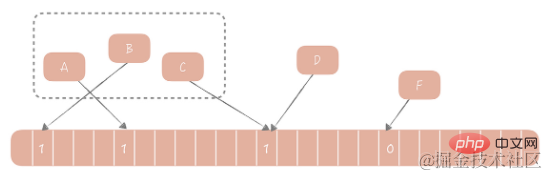
Wie verwende ich den Bloom-Filter, um die Cache-Penetration zu lösen?
Nehmen Sie zur Erläuterung die Tabelle, in der Benutzerinformationen gespeichert sind, als Beispiel. Zuerst initialisieren wir ein großes Array, beispielsweise ein Array mit einer Länge von 2 Milliarden, wählen dann einen Hash-Algorithmus aus, berechnen dann den Hash-Wert aller vorhandenen Benutzer-IDs und ordnen sie diesem großen Array zu, wobei wir den Positionswert abbilden wird auf 1 gesetzt und andere Werte werden auf 0 gesetzt. Zusätzlich zum Schreiben in die Datenbank muss der neu registrierte Benutzer auch den Wert der entsprechenden Position im Bloom-Filter-Array nach demselben Algorithmus aktualisieren. Wenn wir dann die Informationen eines bestimmten Benutzers abfragen müssen, fragen wir zunächst ab, ob die ID im Bloom-Filter vorhanden ist. Wenn sie nicht vorhanden ist, geben wir direkt einen Nullwert zurück, ohne die Datenbank und den Cache weiter abzufragen, was zu einer erheblichen Reduzierung führen kann Ausnahmen. Cache-Penetration durch Abfragen. 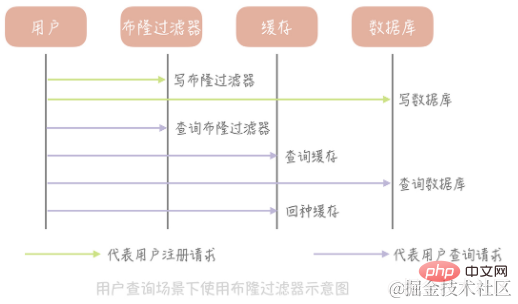
Vorteile des Bloom-Filters:
(1) Hohe Leistung. Unabhängig davon, ob es sich um einen Schreibvorgang oder einen Lesevorgang handelt, beträgt die Zeitkomplexität O(1), was aus Platzgründen ein konstanter Wert ist
(2). Beispielsweise erfordert ein Array von 2 Milliarden 2000000000/8/1024/1024 = 238 MB Speicherplatz. Wenn ein Array zum Speichern verwendet wird und jede Benutzer-ID 4 Byte Speicherplatz belegt, sind zum Speichern von 2 Milliarden Benutzern 2000000000 * 4 / 1024 erforderlich / 1024 = 7600 MB Speicherplatz, 32-mal so viel wie der Bloom-Filter.
Nachteile des Bloom-Filters:
(1) Es besteht eine gewisse Fehlerwahrscheinlichkeit bei der Beurteilung, ob ein Element in der Menge enthalten ist. Beispielsweise wird ein Element, das nicht in der Menge enthalten ist, als in der Menge enthalten eingestuft .
Ursache: Fehler im Hash-Algorithmus selbst.
Lösung: Verwenden Sie mehrere Hash-Algorithmen, um mehrere Hash-Werte für das Element zu berechnen. Nur wenn die Werte im Array, die allen Hash-Werten entsprechen, 1 sind, wird das Element als Teil der Menge betrachtet.
(2) unterstützt das Löschen von Elementen nicht. Der Fehler, dass Bloom-Filter das Löschen von Elementen nicht unterstützen, hängt auch mit der Hash-Kollision zusammen. Wenn beispielsweise zwei Elemente A und B beide Elemente in der Sammlung sind und denselben Hash-Wert haben, werden sie derselben Position im Array zugeordnet. Zu diesem Zeitpunkt löschen wir A und der Wert der entsprechenden Position im Array ändert sich ebenfalls von 1 auf 0. Wenn wir dann B beurteilen und feststellen, dass der Wert 0 ist, werden wir auch beurteilen, dass B ein Element ist, das nicht 0 ist im Satz, und wir werden zu einer falschen Schlussfolgerung kommen.
Lösung: Anstatt nur 0- und 1-Werte im Array zu haben, würde ich eine Zählung speichern. Treffen beispielsweise A und B gleichzeitig auf den Index eines Arrays, dann ist der Wert dieser Position 2. Wird A gelöscht, ändert sich der Wert von 2 auf 1. Das Array in dieser Lösung speichert keine Bits mehr, sondern Werte, was den Speicherplatzverbrauch erhöht.
(1) Steuerung im Code, um nach Ablauf eines bestimmten Hot-Cache-Elements einen Hintergrundthread zu starten und in die Datenbank einzudringen. und Die Daten werden in den Cache geladen, bevor alle Anforderungen für den Zugriff auf diesen Cache eindringen und direkt zurückkehren.
(2) Durch das Festlegen einer verteilten Sperre in Memcached oder Redis kann nur die Anforderung zum Erhalten der Sperre in die Datenbank eindringen
6. CDN
2. CDN
CDN (Content Delivery Network/Content Distribution Network, Inhaltsverteilungsnetzwerk). Einfach ausgedrückt verteilt CDN statische Ressourcen an Server, die sich in Computerräumen an mehreren geografischen Standorten befinden, sodass das Problem des Datenzugriffs in der Nähe gut gelöst und der Zugriff auf statische Ressourcen beschleunigt werden kann.
3. Erstellen Sie ein CDN-System
Sie denken vielleicht, dass das sehr einfach ist, sagen Sie es einfach Geben Sie einfach die IP-Adresse des CDN-Knotens des Benutzers ein und fordern Sie dann den auf dieser IP-Adresse bereitgestellten CDN-Dienst an. Dies ist jedoch nicht der Fall. Sie müssen die IP durch den entsprechenden Domainnamen ersetzen. Wie geht das? Dies erfordert, dass wir uns auf DNS verlassen, um das Problem der Domänennamenzuordnung zu lösen. DNS (Domain Name System) ist eigentlich eine verteilte Datenbank, die die Korrespondenz zwischen Domänennamen und IP-Adressen speichert. Im Allgemeinen gibt es zwei Arten von Ergebnissen zur Auflösung von Domänennamen: Eine wird als „A-Eintrag“ bezeichnet und gibt die dem Domänennamen entsprechende IP-Adresse zurück. Die andere ist „CNAME-Eintrag“ und gibt einen anderen Domänennamen zurück Auflösung des aktuellen Domainnamens. Um zur Auflösung eines anderen Domainnamens zu springen.
Zum Beispiel: Wenn der Domänenname der ersten Ebene Ihres Unternehmens beispielsweise example.com heißt, können Sie den Domänennamen Ihres Bilddienstes als „img.example.com“ definieren und dann den CNAME der Auflösung konfigurieren Ergebnis dieses Domänennamens: Für den vom CDN bereitgestellten Domänennamen kann ucloud beispielsweise den Domänennamen „80f21f91.cdn.ucloud.com.cn“ bereitstellen. Auf diese Weise kann die von Ihrem E-Commerce-System verwendete Bildadresse „img.example.com/1.jpg“ lauten.
Wenn der Benutzer diese Adresse anfordert, löst der DNS-Server den Domänennamen in den Domänennamen 80f21f91.cdn.ucloud.com.cn und dann den Domänennamen in die Knoten-IP des CDN auf, sodass die Ressourcendaten vorliegen auf dem CDN erhältlich.
Optimierung der Auflösung auf DomänennamenebeneDa der Domänennamenauflösungsprozess hierarchisch ist und jede Ebene über einen dedizierten Domänennamenserver verfügt, der für die Auflösung verantwortlich ist, erfordert der Domänennamenauflösungsprozess möglicherweise mehrere DNS-Abfragen im gesamten öffentlichen Netzwerk In Bezug auf die Leistung ist es relativ schlecht. Eine Lösung besteht darin, den Domänennamen, der beim Start der APP analysiert werden muss, vorab zu analysieren und die analysierten Ergebnisse dann in einem lokalen LRU-Cache zwischenzuspeichern. Wenn wir diesen Domänennamen verwenden möchten, müssen wir auf diese Weise nur die erforderliche IP-Adresse direkt aus dem Cache abrufen. Wenn sie nicht im Cache vorhanden ist, durchlaufen wir den gesamten DNS-Abfrageprozess. Um zu verhindern, dass Daten im Cache aufgrund von Änderungen in den DNS-Auflösungsergebnissen ungültig werden, können wir gleichzeitig einen Timer starten, um die Daten im Cache regelmäßig zu aktualisieren.
(2) So wählen Sie einen nahegelegenen Knoten basierend auf den geografischen Standortinformationen des Benutzers aus.
GSLB (Global Server Load Balance) bedeutet Lastausgleich zwischen Servern, die in verschiedenen Regionen bereitgestellt werden. Viele lokale Lastausgleichskomponenten können unten verwaltet werden. Er hat zwei Funktionen: Einerseits ist er ein Lastausgleichsserver. Wie der Name schon sagt, bezieht er sich auf die gleichmäßige Verteilung des Datenverkehrs, sodass die Last der unten verwalteten Server gleichmäßiger ist. Es muss außerdem sichergestellt werden, dass der Datenverkehr durch den Server relativ nahe an der Datenverkehrsquelle liegt.
GSLB kann verschiedene Strategien verwenden, um sicherzustellen, dass sich die zurückgegebenen CDN-Knoten und Benutzer so weit wie möglich im selben geografischen Bereich befinden. Beispielsweise kann die IP-Adresse des Benutzers entsprechend dem geografischen Standort in mehrere Bereiche unterteilt werden CDN-Knoten können einem Bereich zugeordnet werden, je nachdem, in welchem Bereich sich der Benutzer befindet. Sie können auch entscheiden, welcher Knoten zurückgegeben werden soll, indem Sie Datenpakete senden, um die RTT zu messen.
Zusammenfassung: Die DNS-Technologie ist die Kerntechnologie, die bei der CDN-Implementierung verwendet wird. Sie kann Benutzeranfragen CDN-Knoten zuordnen. DNS-Auflösungsergebnisse müssen lokal zwischengespeichert werden, um die Antwortzeit des DNS-Auflösungsprozesses zu verkürzen Benutzer Seine näheren Knoten beschleunigen den Zugriff auf statische Ressourcen.
(1) Baidu-Domänennamenauflösungsprozess
Zu Beginn überprüft die Domänennamenauflösungsanforderung zunächst die lokale Hosts-Datei, um festzustellen, ob eine IP vorhanden ist, die www.baidu.com entspricht , fordern Sie an, ob das lokale DNS über einen Cache mit Ergebnissen zur Domänennamenauflösung verfügt. Wenn dies der Fall ist, wird das Ergebnis zurückgegeben, das angibt, dass es von einem nicht autorisierenden DNS zurückgegeben wird. Andernfalls wird eine iterative DNS-Abfrage gestartet. Fordern Sie zuerst den Root-DNS an, der die Adresse des Top-Level-DNS (.com) zurückgibt. Fordern Sie dann den .com-Top-Level-DNS an, um die Domain-Name-Server-Adresse von baidu.com abzurufen www.baidu.com vom Domain-Name-Server der IP-Adresse von baidu.com, während Sie diese IP-Adresse zurückgeben, markieren Sie das Ergebnis als vom autorisierenden DNS stammend und schreiben Sie es in den lokalen DNS-Analyseergebnis-Cache, damit es beim nächsten Mal angezeigt wird Wenn Sie denselben Domänennamen analysieren, müssen Sie keine iterative DNS-Abfrage durchführen.
(2) CDN-Verzögerung
Im Allgemeinen schreiben wir statische Ressourcen über die Schnittstelle des CDN-Herstellers auf einen bestimmten CDN-Knoten, und dann verteilt und synchronisiert der interne Synchronisationsmechanismus des CDN die Ressourcen auf jeden CDN-Knoten Wenn das interne CDN-Netzwerk optimiert ist, kommt es zu einer Verzögerung bei diesem Synchronisierungsprozess. Sobald wir keine Daten vom ausgewählten CDN-Knoten erhalten können, müssen wir Daten vom Ursprungsstandort und das Netzwerk vom Benutzernetzwerk zum Ursprungsstandort abrufen kann sich über mehrere Backbone-Netzwerke erstrecken, was nicht nur zu Leistungsverlusten führt, sondern auch die Bandbreite des Ursprungsstandorts verbraucht, was zu höheren Forschungs- und Entwicklungskosten führt. Daher müssen wir bei der Verwendung eines CDN auf die Trefferquote des CDN und die Bandbreite der Ursprungsseite achten.
Verwandte Lernempfehlungen: Java-Grundlagen
Das obige ist der detaillierte Inhalt vonJava-Systemdesign mit hoher Parallelität – Cache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verbinden Sie Breitband mit einem Server
So verbinden Sie Breitband mit einem Server
 HTTP 503-Fehlerlösung
HTTP 503-Fehlerlösung
 So überspringen Sie die Verbindung zum Internet nach dem Hochfahren von Windows 11
So überspringen Sie die Verbindung zum Internet nach dem Hochfahren von Windows 11
 So aktivieren Sie den abgesicherten Word-Modus
So aktivieren Sie den abgesicherten Word-Modus
 Die Rolle des HTML-Titel-Tags
Die Rolle des HTML-Titel-Tags
 jquery animieren
jquery animieren
 kb4012212 Was tun, wenn das Update fehlschlägt?
kb4012212 Was tun, wenn das Update fehlschlägt?
 Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
 So exportieren Sie Word aus Powerdesigner
So exportieren Sie Word aus Powerdesigner











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



