47 Bilder, die Sie durch die Weiterentwicklung von MySQL führen
coldplay.xixi
Freigeben: 2020-10-14 17:27:20
nach vorne
2614 Leute haben es durchsucht
Die Spalte „MySQL-Tutorial“ führt Sie durch 47 Bilder, um das fortgeschrittene MySQL zu verstehen.
Im MySQL-Einführungskapitel stellen wir hauptsächlich die grundlegenden SQL-Befehle, Datentypen und Funktionen vor. Wenn Sie jedoch ein qualifizierter Entwickler werden möchten, müssen Sie die oben genannten Kenntnisse erwerben Um über einige fortgeschrittenere Fähigkeiten zu verfügen, besprechen wir, welche fortgeschrittenen Fähigkeiten für MySQL erforderlich sind. Wie und wie Daten gespeichert werden, ist also der Schlüssel zur Speicherung. Daher entspricht die Speicher-Engine der Datenspeicher-Engine und steuert die Speicherung der Daten auf Festplattenebene.
Die Architektur von MySQL kann nach dem dreistufigen Modell verstanden werden
Die Speicher-Engine ist auch eine Art Software. Die Hauptfunktionen, die sie ausführen und unterstützen kann, sind
Parallelität
Unterstützung von Transaktionen
IntegritätseinschränkungenPhysischer SpeicherUnterstützung von IndizesLeistungshilfe
MySQL unterstützt standardmäßig mehrere Speicher-Engines, um verschiedenen Datenbankanwendungen gerecht zu werden . Folgendes wird von der MySQL Storage Engine unterstützt: MyISAM, InnoDB, MEMORY, MERGE, EXAMPLE, NDB-Cluster, ARCHIVE, CSV, Blackhole
FÖDERIERT
Standardmäßig ist Wenn Sie eine Tabelle erstellen, ohne die Speicher-Engine anzugeben, wird die Standard-Speicher-Engine verwendet. Wenn Sie die Standard-Speicher-Engine ändern möchten, können Sie default-table-type in der Parameterdatei festlegen, um den aktuellen Speicher anzuzeigen engine
show variables like 'table_type';复制代码
Nach dem Login kopieren
Seltsam, warum ist es weg? Ich habe online nachgesehen und festgestellt, dass dieser Parameter in 5.5.3 gelöscht wurdeSie können die von der aktuellen Datenbank unterstützte Speicher-Engine mit den folgenden zwei Methoden abfragen
show engines \g复制代码
Nach dem Login kopieren
Beim Erstellen einer neuen Tabelle können Sie hinzufügen Das Schlüsselwort ENGINE legt die Speicher-Engine der neuen Tabelle fest.
Im obigen Bild haben wir die Speicher-Engine von MyISAM angegeben.
Was ist, wenn Sie die Speicher-Engine der Tabelle nicht kennen? Sie können es über show create table anzeigen
Wenn Sie keine Speicher-Engine angeben, ist MySQLs standardmäßig integrierte Speicher-Engine ab MySQL 5.1 bereits InnoDB. Erstellen Sie eine Tabelle und werfen Sie einen Blick darauf.
1280 " data-height="132"/>
default-table-type,能够查看当前的存储引擎
alter table cxuan003 engine = myisam;复制代码
Nach dem Login kopieren
奇怪,为什么没有了呢?网上求证一下,在 5.5.3 取消了这个参数
可以通过下面两种方法查询当前数据库支持的存储引擎
select character_set_name, default_collate_name, description, maxlen from information_schema.character_sets;复制代码
insert into product values(1, "apple","3.5"),(2,"banana","4.2"),(3,"melon","1.2");复制代码
Nach dem Login kopieren
Nach dem Login kopieren
来更换,更换完成后回显示 0 rows affected ,但其实已经操作成功
我们使用 show create tableWie im Bild oben gezeigt, haben wir keine Standardspeicher-Engine angegeben. Sehen Sie sich die Tabelle unten an
Sie können sehen, dass der Standardspeicher ist Die Engine ist InnoDB. Wenn Sie die Speicher-Engine ersetzen möchten, können Sie sie mit
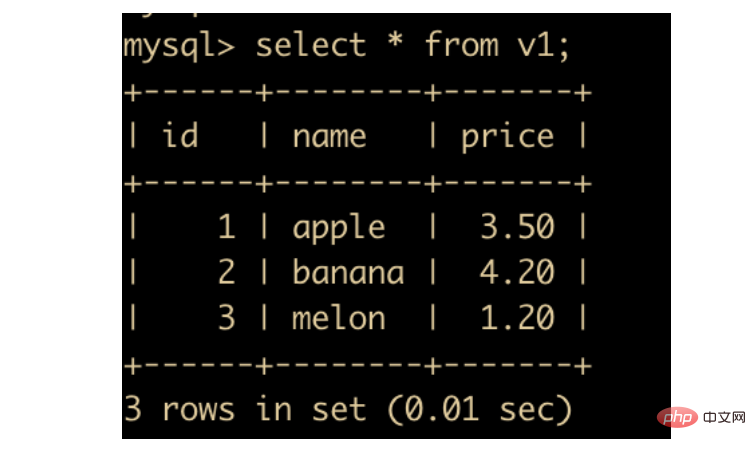
create view v1 as select * from product;复制代码
Nach dem Login kopieren
Nach dem Login kopieren
ersetzen. Nach Abschluss des Austauschs wird 🎜0 betroffene Zeilen🎜 angezeigt, der Vorgang war jedoch tatsächlich erfolgreich🎜🎜🎜🎜 🎜🎜Wir verwenden show create table. Überprüfen Sie die SQL der Tabelle und Sie werden es wissen🎜🎜🎜🎜🎜🎜🎜Eigenschaften der Speicher-Engine🎜🎜Im Folgenden werden einige häufig verwendete Speicher-Engines und ihre grundlegenden Eigenschaften vorgestellt. Diese Speicher-Engines sind **MyISAM, InnoDB, MEMORY AND MERGE**🎜
MyISAM
Vor Version 5.1 war MyISAM die Standardspeicher-Engine von MySQL und wurde in weniger Szenarien verwendet. Sein Hauptmerkmal ist, dass
keine transaction-Operationen unterstützt ACID Die Funktionen sind nicht mehr vorhanden und das Design ist auf Leistung und Effizienz ausgerichtet. 事务操作,ACID 的特性也就不存在了,这一设计是为了性能和效率考虑的。
unterstützt keine Fremdschlüssel-Operationen. Wenn Sie einen Fremdschlüssel erzwingen, meldet MySQL keinen Fehler, aber der Fremdschlüssel funktioniert nicht.
Die standardmäßige Sperrgranularität von MyISAM ist Sperre auf Tabellenebene, daher ist die Parallelitätsleistung relativ schlecht, das Sperren erfolgt schneller, es gibt weniger Sperrkonflikte und es ist weniger wahrscheinlich, dass ein Deadlock auftritt . 🎜🎜🎜MyISAM speichert drei Dateien auf der Festplatte. Die Dateinamen und Tabellennamen sind gleich und die Erweiterungen sind .frm (Speichertabellendefinition), .MYD (MYData, Store-Daten), MYI(MyIndex, Store-Index). Hier ist besonders zu beachten, dass MyISAM nur Indexdateien und keine Datendateien zwischenspeichert. 🎜🎜🎜Zu den von MyISAM unterstützten Indextypen gehören Global Index (Full-Text), B-Tree Index, R-Tree Index Code >🎜🎜Volltextindex: Er scheint das Problem der geringen Effizienz der Fuzzy-Abfrage für Text zu lösen. 🎜🎜B-Baum-Index: Alle Indexknoten werden gemäß der Datenstruktur eines ausgeglichenen Baums gespeichert, und alle Indexdatenknoten befinden sich in Blattknoten. 🎜🎜R-Baum-Index: Die Speichermethode unterscheidet sich etwas vom B-Baum-Index Es ist hauptsächlich für die Indizierung von Feldern konzipiert, die räumliche und mehrdimensionale Daten speichern. Der Vorteil von RTREE ist die Bereichssuche. 🎜🎜🎜Wenn der Host, auf dem sich die Datenbank befindet, ausfällt, werden MyISAM-Datendateien leicht beschädigt und lassen sich nur schwer wiederherstellen. 🎜🎜🎜Hinzufügen, Löschen, Ändern und Abfrageleistung: SELECT bietet eine höhere Leistung und eignet sich für Situationen mit vielen Abfragen🎜<h4 class="heading" data-id="heading-4">InnoDB🎜🎜Seit MySQL 5.1 ist die InnoDB-Speicher-Engine zur Standard-Speicher-Engine geworden. Im Vergleich zu MyISAM hat die InnoDB-Speicher-Engine große Änderungen erfahren: Sie unterstützt Transaktionsvorgänge und verfügt über Transaktions-ACID Isolation. Die Standardisolationsstufe ist <code>repetable-read, implementiert durch MVCC (Concurrent Version Control). Es kann die Probleme von Dirty Read und non-repeatable Read lösen. 🎜InnoDB unterstützt Fremdschlüsseloperationen. 🎜InnoDBs standardmäßige Sperrgranularität ist Sperre auf Zeilenebene, was eine bessere Parallelitätsleistung bietet, aber es kann zu Deadlocks kommen. 🎜Wie MyISAM verfügt auch die InnoDB-Speicher-Engine über eine .frm-Dateispeichertabellenstruktur-Definition, der Unterschied besteht jedoch darin, dass die Tabellendaten und Indexdaten von InnoDB zusammen gespeichert werden, beide in Auf dem Blatt Knoten der B+-Nummer, die Tabellendaten und Indexdaten von MyISAM werden getrennt. 🎜InnoDB verfügt über eine sichere Protokolldatei. Diese Protokolldatei wird verwendet, um Datenverluste zu beheben, die durch einen Datenbankabsturz oder andere Situationen verursacht wurden, und um die Datenkonsistenz sicherzustellen. 🎜InnoDB und MyISAM unterstützen die gleichen Indextypen, aber die spezifische Implementierung ist aufgrund unterschiedlicher Dateistrukturen sehr unterschiedlich. 🎜In Bezug auf die Leistung beim Hinzufügen, Löschen, Ändern und Abfragen wird empfohlen, die InnoDB-Speicher-Engine zu verwenden, wenn eine große Anzahl von Vorgängen zum Hinzufügen, Löschen und Ändern ausgeführt wird. Sie löscht Zeilen während Löschvorgängen und baut die Tabelle nicht neu auf.
MEMORY🎜🎜MEMORY-Speicher-Engine verwendet im Speicher gespeicherte Inhalte, um Tabellen zu erstellen. Jede MEMORY-Tabelle entspricht tatsächlich nur einer Festplattendatei und das Format ist .frm. Auf Tabellen vom Typ MEMORY wird sehr schnell zugegriffen, da ihre Daten im Speicher gespeichert sind. Standardmäßig wird HASH-Index verwendet. 🎜
MERGE🎜🎜MERGE-Speicher-Engine ist eine Kombination aus einer Reihe von MyISAM-Tabellen. Die MERGE-Tabelle selbst enthält keine Daten. Sie kann MERGE abfragen, aktualisieren und löschen Typtabellen. Die Operation wird tatsächlich für die interne MyISAM-Tabelle ausgeführt. Die MERGE-Tabelle speichert zwei Dateien auf der Festplatte, eine ist die Datei .frm, die die Tabellendefinition speichert, und die andere ist die Datei .MRG, die die Zusammensetzung der Tabelle speichert MERGE-Tabelle. 🎜🎜Wählen Sie die geeignete Speicher-Engine aus.🎜🎜Im eigentlichen Entwicklungsprozess wählen wir häufig die geeignete Speicher-Engine basierend auf den Anwendungseigenschaften aus. 🎜
MyISAM: Wenn die Anwendung normalerweise abruforientiert ist, nur wenige Einfüge-, Aktualisierungs- und Löschvorgänge aufweist und die Integrität und Parallelität der Dinge nicht sehr hoch ist, wird normalerweise empfohlen, die MyISAM-Speicher-Engine zu wählen.
InnoDB: Wenn Fremdschlüssel verwendet werden, ein hohes Maß an Parallelität erforderlich ist und die Anforderungen an die Datenkonsistenz hoch sind, wird normalerweise die InnoDB-Engine gewählt. Im Allgemeinen haben große Internetunternehmen höhere Anforderungen an Parallelität und Datenintegrität Verwenden Sie die InnoDB-Speicher-Engine.
MEMORY: Die MEMORY-Speicher-Engine speichert alle Daten im Speicher und kann einen extrem schnellen Zugriff ermöglichen, wenn ein schneller Standort erforderlich ist. MEMORY wird typischerweise für kleine Tabellen verwendet, die seltener aktualisiert werden, und für den schnellen Zugriff auf Ergebnisse.
MERGE: MERGE verwendet MyISAM-Tabellen intern. Der Vorteil der MERGE-Tabelle besteht darin, dass sie die Größenbeschränkung einer einzelnen MyISAM-Tabelle durchbrechen kann und durch die Verteilung verschiedener Tabellen auf mehrere Festplatten die Zugriffseffizienz der MERGE-Tabelle erhöht werden kann effektiv verbessert werden.
Wählen Sie den geeigneten Datentyp
Ein Problem, auf das wir beim Erstellen einer Tabelle häufig stoßen, ist die Auswahl des geeigneten Datentyps. Im Allgemeinen kann die Auswahl des geeigneten Datentyps die Leistung verbessern und unnötige Probleme reduzieren wie man den geeigneten Datentyp auswählt.
Auswahl von CHAR und VARCHAR
char und varchar sind zwei Datentypen, die wir häufig zum Speichern von Zeichenfolgen verwenden. char speichert im Allgemeinen Zeichenfolgen fester Länge, wie zum Beispiel die folgenden: Wert
char(5)
Speicherbytes
''
''
5 Bytes
'cx'
'cx '
5 Bytes
'cxuan'
'cxuan'
5 Bytes
'cxuan007'
'cxuan'
5 Bytes
Sie können das unabhängig vom Wert sehen, den Sie schreiben, sobald die Länge der Zeichen angegeben ist Wenn die Länge Ihrer Zeichenfolge nicht ausreicht, um die Länge der Zeichen anzugeben, wird sie mit Leerzeichen aufgefüllt. Wenn sie die Länge der Zeichenfolge überschreitet, werden nur die Zeichen der angegebenen Zeichenlänge gespeichert.
Hier ist Folgendes zu beachten: Wenn MySQL etwas anderes als
verwendet, wird beim Speichern der letzten Zeile in der Tabelle ein Fehler gemeldet.
Wenn der Zeichentyp Varchar verwendet wird, schauen wir uns ein Beispiel an: Byte
严格模式的话,上面表格最后一行是可以存储的。如果 MySQL 使用了 严格模式
'cx''cx '
3 Bytes
'cxuan'
'cxuan'
6 Bytes
'cxuan007'
' c xuan'
6 Bytes
Sie können sehen, dass bei Verwendung von Varchar die gespeicherten Bytes entsprechend dem tatsächlichen Wert gespeichert werden. Sie fragen sich vielleicht, warum die Länge von Varchar 5 beträgt, aber 3 Bytes oder 6 Bytes gespeichert werden müssen. Dies liegt daran, dass bei Verwendung des Varchar-Datentyps standardmäßig am Ende eine Zeichenfolge hinzugefügt wird, die 1 Wort belegt. Abschnitt (zwei Bytes werden verwendet, wenn die Spaltendeklaration länger als 255 ist). Varchar füllt keine leeren Zeichenfolgen.
Verwenden Sie im Allgemeinen char, um Zeichenfolgen fester Länge zu speichern, z. B. ID-Kartennummer, Mobiltelefonnummer, E-Mail usw.; verwenden Sie varchar, um Zeichenfolgen variabler Länge zu speichern. Da die Länge von char fest ist, ist seine Verarbeitungsgeschwindigkeit viel schneller als bei VARCHAR, der Nachteil besteht jedoch darin, dass Speicherplatz verschwendet wird. Mit der kontinuierlichen Weiterentwicklung der MySQL-Versionen verbessert sich jedoch auch die Leistung des Datentyps varchar ständig Daher wird es in vielen Anwendungen verwendet. Der Typ VARCHAR wird häufiger verwendet.
In MySQL haben verschiedene Speicher-Engines unterschiedliche Nutzungsprinzipien von CHAR und VARCHAR
MyISAM: Es wird empfohlen, Datenspalten fester Länge anstelle von Datenspalten variabler Länge zu verwenden, d. h. CHAR
MEMORY: Verwenden Sie feste Längen Bei der Verarbeitung werden CHAR und VARCHAR als CHAR behandelt.
InnoDB: Es wird empfohlen, den Typ VARCHAR zu verwenden. TEXT und BLOB. Im Allgemeinen wählen wir beim Speichern einer kleinen Textmenge CHAR und VARCHAR, beim Speichern einer großen Textmenge Bei Texten wählen wir oft TEXT und BLOB. Der Hauptunterschied zwischen TEXT und BLOB besteht darin, dass BLOB Binärdaten speichern kann, während TEXT nur Zeichendaten speichern kann ist nach unten unterteilt. Es gibt
TEXT
MEDIUMTEXT二进制数据;而 TEXT 只能保存字符数据,TEXT 往下细分有
TEXT
MEDIUMTEXT
LONGTEXT
BLOB 往下细分有
BLOB
MEDIUMBLOB
LONGBLOB
三种,它们最主要的区别就是存储文本长度不同和存储字节不同,用户应该根据实际情况选择满足需求的最小存储类型,下面主要对 BLOB 和 TEXT 存在一些问题进行介绍
TEXT 和 BLOB 在删除数据后会存在一些性能上的问题,为了提高性能,建议使用 OPTIMIZE TABLE 功能对表进行碎片整理。
🎜LONGBLOB🎜🎜🎜 dass die Textlänge unterschiedlich ist und Bytes speichern Anders gesagt, Benutzer sollten den Mindestspeichertyp auswählen, der ihren tatsächlichen Anforderungen entspricht. Im Folgenden werden hauptsächlich einige Probleme mit BLOB und TEXT vorgestellt, und BLOB wird nach dem Löschen von Daten einige Leistungsprobleme haben. Es wird empfohlen, die Funktion TABELLE OPTIMIEREN zu verwenden, um die Tabelle zu defragmentieren. 🎜🎜Synthetische Indizes können auch verwendet werden, um die Abfrageleistung für Textfelder (BLOB und TEXT) zu verbessern. Der synthetische Index besteht darin, einen Hash-Wert basierend auf dem Inhalt des großen Textfelds (BLOB und TEXT) zu erstellen und diesen Wert in der entsprechenden Spalte zu speichern, sodass die entsprechende Datenzeile basierend auf dem Hash-Wert gefunden werden kann. Im Allgemeinen werden Hashing-Algorithmen wie md5() und SHA1() verwendet. Wenn die vom Hashing-Algorithmus generierten Zeichenfolgen nachgestellte Leerzeichen enthalten, sollten Sie diese nicht in CHAR und VARCHAR speichern. Schauen wir uns zunächst diese Verwendungsmethode an Erstellen Sie eine Tabelle, die Blob-Felder und Hash-Werte aufzeichnet. width="1280" data-height="131"/>🎜🎜🎜🎜Fügen Sie Daten in cxuan005 ein, wo der Hash-Wert als Hash-Wert der Informationen verwendet wird. 🎜🎜🎜🎜🎜🎜Dann fügen Sie zwei weitere Datenelemente ein🎜🎜🎜🎜🎜🎜Fügen Sie ein Datenelement mit den Informationen cxuan005🎜🎜🎜🎜🎜🎜Wenn Sie die Daten abfragen möchten, deren Informationen sind cxuan005, Sie können es über die Hash-Spalte abfragen, um Daten abzufragen -width="1280" data-height="191"/>🎜🎜🎜🎜Dies ist ein Beispiel für einen synthetischen Index. Wenn Sie eine Fuzzy-Abfrage für BLOB durchführen möchten, müssen Sie einen Präfixindex verwenden. 🎜🎜Andere Möglichkeiten zur Optimierung von BLOB und TEXT: 🎜🎜🎜Rufen Sie BLOB- und TEXT-Indizes nicht ab, es sei denn, dies ist erforderlich. 🎜🎜Trennen Sie BLOB- oder TEXT-Spalten in separate Tabellen. 🎜🎜
Auswahl von Gleitkommazahlen und Festkommazahlen🎜🎜Gleitkommazahlen beziehen sich auf Werte, die Dezimalzahlen enthalten, nachdem Gleitkommazahlen in die angegebene Zahl eingefügt wurden Spalte und überschreiten die angegebene Genauigkeit. Gleitkommazahlen beziehen sich in MySQL auf float und double, und Festkommazahlen beziehen sich auf decimal . Festkommazahlen können genauer sein. Lassen Sie uns anhand eines Beispiels die Genauigkeit von Gleitkommazahlen erklären🎜🎜Erstellen Sie zunächst eine Tabelle cxuan006, um das Problem mit Gleitkommazahlen zu testen. Daher wählen wir hier den Datentyp float🎜🎜🎜🎜🎜🎜🎜 Fügen Sie dann zwei Datenelemente ein bzw.🎜
Führen Sie dann die Abfrage aus, und Sie können sehen, dass die beiden abgefragten Daten unterschiedlich gerundet sind ein Beispiel
Ändern Sie zunächst die beiden Felder von cxuan006 auf die gleiche Länge und die gleichen Dezimalstellen sind kleiner als Festkommazahlen. Es wird gesagt, dass Fehler auftreten
Auswahl des Datumstyps
In MySQL sind die zur Darstellung verwendeten Datumstypen
DATE, TIME, DATETIME, TIMESTAMP, in 138 Bilder werden helfen Ihnen beim Einstieg in MySQL Die Unterschiede zwischen Datumstypen wurden in diesem Artikel vorgestellt, daher werden wir hier nicht näher darauf eingehen. Im Folgenden wird hauptsächlich die Auswahl von
TIMESTAMP vorgestellt, die sich auf die Zeitzone bezieht und die aktuelle Zeit besser widerspiegeln kann. Wenn das aufgezeichnete Datum von Personen in verschiedenen Zeitzonen verwendet werden muss, ist es am besten, TIMESTAMP zu verwenden. DATE wird zur Darstellung von Jahr, Monat und Tag verwendet. Wenn der tatsächliche Anwendungswert Jahr, Monat und Tag speichern muss, können Sie DATE verwenden. TIME wird zur Darstellung von Stunden, Minuten und Sekunden verwendet. Wenn der tatsächliche Anwendungswert Stunden, Minuten und Sekunden speichern muss, können Sie TIME verwenden. YEAR wird verwendet, um das Jahr darzustellen. Es gibt zweistellige (vorzugsweise vierstellige) und vierstellige Jahresformate. Der Standardwert ist 4 Ziffern. Wenn die eigentliche Anwendung nur das Jahr speichert, ist es völlig in Ordnung, 1 Byte zum Speichern des Typs YEAR zu verwenden. Dies kann nicht nur Speicherplatz sparen, sondern auch die Effizienz der Tischbedienung verbessern.
MySQL-Zeichensatz
Lassen Sie uns den MySQL-Zeichensatz kennenlernen. Einfach ausgedrückt ist ein Zeichensatz ein Satz von Textsymbolen, Kodierungen und Vergleichsregeln. Im Jahr 1960 veröffentlichte die amerikanische Normungsorganisation ANSI den ersten Computerzeichensatz, den berühmten ASCII (American Standard Code for Information Interchange). Seit der ASCII-Kodierung hat jedes Land und jede internationale Organisation ihren eigenen Zeichensatz entwickelt, wie z. B. ISO-8859-1, GBK usw.
Aber jedes Land verwendet seinen eigenen Zeichensatz, was große Schwierigkeiten bei der Portabilität mit sich bringt. Um die Zeichenkodierung zu vereinheitlichen, hat die International Organization for Standardization (ISO) daher einen einheitlichen Zeichenstandard spezifiziert – die Unicode-Kodierung, die fast alle Zeichenkodierungen unterstützt. Hier sind einige gängige Zeichencodierungen
Zeichensätze
, um nicht zu bestimmen, dass es sich bei der langen Codierungsmethode
ASCII
ASCII(American Standard Code for Information Interchange) 。自从 ASCII 编码后,每个国家、国际组织都研究了一套自己的字符集,比如 ISO-8859-1、GBK 等。
但是每个国家都使用自己的字符集为移植性带来了很大的困难。所以,为了统一字符编码,国际标准化组织(ISO) um eine 7-stellige Einzelbyte-Codierung
Das obige ist der detaillierte Inhalt von47 Bilder, die Sie durch die Weiterentwicklung von MySQL führen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn






















 🎜🎜🎜🎜Fügen Sie ein Datenelement mit den Informationen cxuan005🎜🎜
🎜🎜🎜🎜Fügen Sie ein Datenelement mit den Informationen cxuan005🎜🎜 🎜🎜🎜🎜Wenn Sie die Daten abfragen möchten, deren Informationen sind cxuan005, Sie können es über die Hash-Spalte abfragen, um Daten abzufragen -width="1280" data-height="191"/>🎜🎜🎜🎜Dies ist ein Beispiel für einen synthetischen Index. Wenn Sie eine Fuzzy-Abfrage für BLOB durchführen möchten, müssen Sie einen Präfixindex verwenden. 🎜🎜Andere Möglichkeiten zur Optimierung von BLOB und TEXT: 🎜🎜🎜Rufen Sie BLOB- und TEXT-Indizes nicht ab, es sei denn, dies ist erforderlich. 🎜🎜Trennen Sie BLOB- oder TEXT-Spalten in separate Tabellen. 🎜🎜
🎜🎜🎜🎜Wenn Sie die Daten abfragen möchten, deren Informationen sind cxuan005, Sie können es über die Hash-Spalte abfragen, um Daten abzufragen -width="1280" data-height="191"/>🎜🎜🎜🎜Dies ist ein Beispiel für einen synthetischen Index. Wenn Sie eine Fuzzy-Abfrage für BLOB durchführen möchten, müssen Sie einen Präfixindex verwenden. 🎜🎜Andere Möglichkeiten zur Optimierung von BLOB und TEXT: 🎜🎜🎜Rufen Sie BLOB- und TEXT-Indizes nicht ab, es sei denn, dies ist erforderlich. 🎜🎜Trennen Sie BLOB- oder TEXT-Spalten in separate Tabellen. 🎜🎜 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen






































![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



