

HeuteMySQL-Tutorial Die Kolumne wird Ihnen die grundlegende Architektur vorstellen, die ich verstehe.

Als seriöser CRUD-Ingenieur spielt die Interaktion mit der Datenbank eine große Rolle in der täglichen Arbeit, wie z. B. tägliche Iterationen von Hinzufügungen, Löschungen, Änderungen und Abfragen, die Verarbeitung historischer Daten, die Optimierung der SQL-Leistung usw. Mit zunehmender Menge an Projektdaten offenbaren die tiefen Gruben, die ich vergraben habe, um mit dem Projektfortschritt Schritt zu halten, langsam ihre Macht. Dies zwingt mich auch dazu, MySQL umfassend und gründlich zu erlernen, anstatt nur beim grundlegenden CRUD zu bleiben. .
Der erste Artikel der MySQL-Reihe stellt hauptsächlich die Infrastruktur von MySQL und die Funktionen jeder Komponente vor, einschließlich des Bin-Protokolls der Serverschicht und des für InnoDB einzigartigen Redo-Protokolls.
Laut der Rangliste der beliebtesten Datenbankverwaltungssysteme von DB-Engines liegt MySQL fest auf dem zweiten Platz.
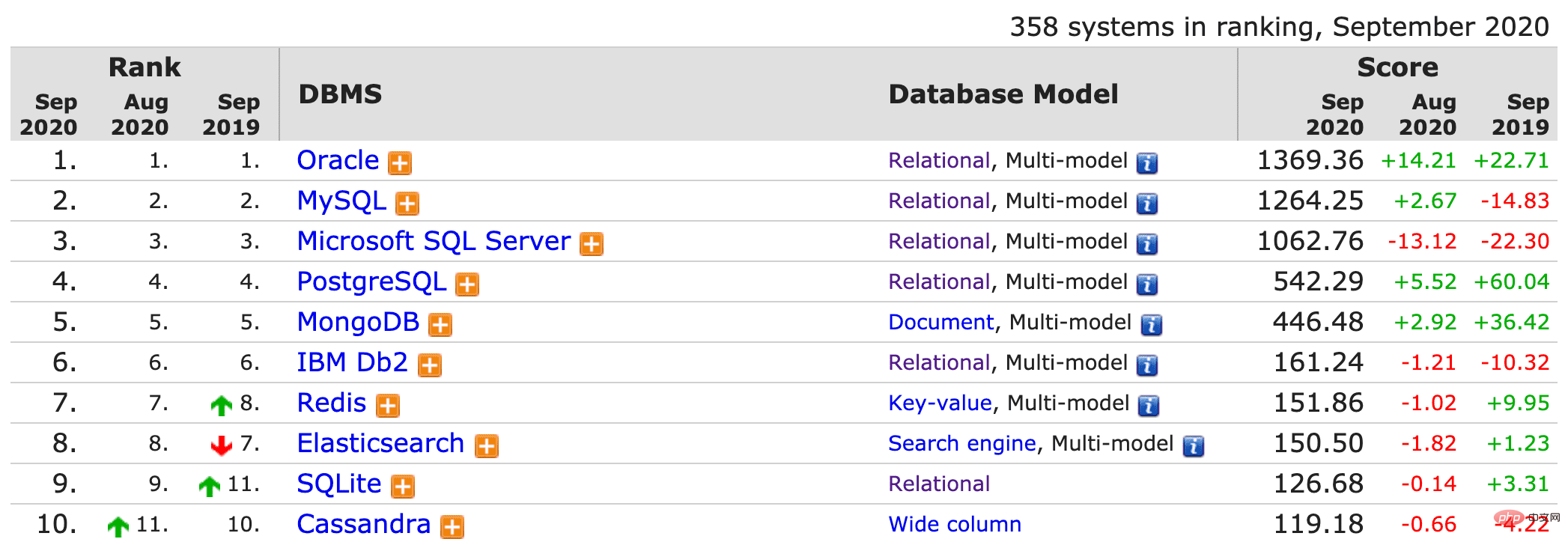
Als eines der beliebtesten relationalen Datenbankverwaltungssysteme verwendet MySQL eine C/S-Architektur, also eine Client- und Server-Architektur. Wenn ein Entwickler beispielsweise Navicat verwendet, um eine Verbindung zu MySQL herzustellen, ist ersterer der Client und letzterer der Server.
Gleichzeitig ist MySQL auch eine Einzelprozess-Multithread-Datenbank. Dies ist leicht zu verstehen. Die laufende MySQL-Instanz ist der „einzelne Prozess“, und in diesem Prozess gibt es viele Threads, wie z. B. den Hauptthread Master Thread, IO Thread Usw., diese Threads werden zur Abwicklung verschiedener Aufgaben verwendet. Master Thread,IO Thread 等,这些线程被用于处理不同的任务。
前面说到 MySQL 采用的是C/S架构,用户通过客户端连接到 MySQL 服务器,然后提交 SQL 语句到服务器,然后服务器就会把执行结果返回给客服端。
在这一小节的内容中,我们主要关注 MySQL 服务端的逻辑组成,先来看一张图。
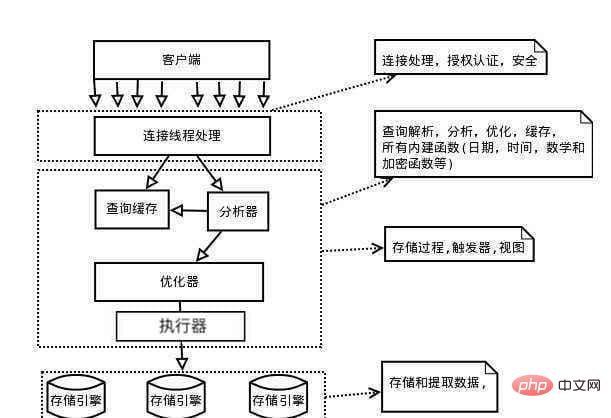
从上图可以看到,与客户端的交互中,MySQL 的服务端分别经过了连接器、查询缓存、分析器、优化器、执行器和存储引擎这几部分。
下面就以一条简单的查询语句来描述 MySQL 服务端的各组成部分及它们所起的作用。
在客户端提交查询语句之前,需要与服务端建立连接。所以最先来到的是连接器,连接器的作用就是负责与客户端建立、管理连接,同时查询用户的权限。
需要注意的是:
在经过连接器的建立连接、获取用户权限之后,接下来用户可以提交查询语句了。
最先经过的是查询缓存部分,由它的名字也能够猜到,查询缓存的作用就是查询 MySQL 是否执行过客户端提交的查询语句,如果这条 SQL 之前执行过,并且用户对该表有执行该语句的权限,就会直接返回之前执行的结果。
所以在某些时候,多次执行一句 SQL 并不能得到它的平均执行时间,因为查询缓存的关系,后面的执行时间往往比第一次执行要短。
如果你不想使用缓存,可以在每次查询后都用 update 语句更新表,当然这是非常麻烦并且憨的方法。MySQL也提供了相应的配置项—— query_cache_type,你可以在 my.cnf 文件中将 query_cache_type 设置为0以关闭查询缓存。
需要注意的是:
key-value 形式进行存储的,key 为查询语句,value 是查询结果。MySQL 8.0🎜🎜Wie Sie der obigen Abbildung entnehmen können, durchläuft der MySQL-Server bei der Interaktion mit dem Client jeweils den Connector, den Abfrage-Cache, den Analysator, den Optimierer, den Executor und den Speicher. Diese Teile des Motors. 🎜🎜Das Folgende ist eine einfache Abfrageanweisung zur Beschreibung der verschiedenen Komponenten des MySQL-Servers und ihrer Funktionen. 🎜query_cache_type. Sie können query_cache_type in der Datei my.cnf auf 0 setzen, um den Abfragecache zu deaktivieren. . 🎜🎜Es ist zu beachten, dass: 🎜Schlüsselwert gespeichert, wobei Schlüssel die Abfrageanweisung und Wert das Abfrageergebnis ist. 🎜MySQL 8.0 wurde die Abfrage-Cache-Funktion entfernt. 🎜🎜🎜2.3-Analysator🎜🎜Die von mir verwendete MySQL-Version ist 5.7.21, daher wird die vom Client übermittelte Abfrageanweisung in den Abfrage-Cache verschoben. Wenn es keinen Treffer gibt, wird sie weiterhin an den Analysator weitergeleitet. 🎜Der Analysator führt eine lexikalische Analyse (Analyse der Anweisung) und eine Syntaxanalyse (Bestimmung, ob die Anweisung den grammatikalischen Regeln von MySQL entspricht) für die übermittelte Anweisung durch. Die Aufgabe des Analysators besteht also darin, die SQL-Anweisung zu analysieren und ihre Rechtmäßigkeit zu überprüfen.
Es ist zu beachten, dass:
Zum Beispiel:
select * form user_info limit 1;复制代码
Es gibt zwei Fehler im obigen SQL-Satz. Der erste ist eine falsche Schreibweise von „from“ und der zweite ist, dass die Tabelle „user_info“ nicht vorhanden ist. Nach der Ausführung meldet MySQL nur einen Fehler Nachfolgend werden die Ergebnisinformationen der dreimaligen Ausführung von SQL angezeigt.
第一次的执行信息: 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'form user_info limit 1' at line 1, Time: 0.000000s 修改为from后第二次的执行信息:1146 - Table 'windfall.user_info' doesn't exist, Time: 0.000000s 修改为 user 表后第三次的执行信息: OK, Time: 0.000000s复制代码
Nach der Überprüfung der Rechtmäßigkeit der SQL-Anweisung weiß MySQL bereits, wozu die vom Benutzer übermittelte Anweisung dient. Bevor sie jedoch tatsächlich ausgeführt wird, muss sie noch einen sehr „metaphysischen“ Optimierer durchlaufen.

Die Funktion des Optimierers besteht darin, den optimalen Ausführungsplan für SQL-Anweisungen zu generieren.
Der Grund, warum der Optimierer als „metaphysisch“ bezeichnet wird, liegt darin, dass er bei der Optimierung von SQL-Anweisungen Ausführungspläne generieren kann, die für den Benutzer unerwartet sind (Indexauswahl, Verbindungssequenz für mehrere Tabellenzuordnungen, implizite Funktionskonvertierung, usw.) . Natürlich wählt der Optimierer manchmal „den falschen“ Index aus, was mit Faktoren wie Datenvolumen und Indexstatistiken zusammenhängt.
Es ist Folgendes zu beachten:
Über den Workflow des MySQL-Optimierers können Sie diesen Blog lesen: So funktioniert der MySQL-Optimierer ursprünglich
Der MySQL-Ausführungsplan ist auch eine Fähigkeit, die man beherrschen muss. Dieser Blog ist sehr detailliert und es lohnt sich, ihn zuerst zu lesen: Ich kann den Ausführungsplan nicht lesen. Ich rate Ihnen, nicht in Ihren Lebenslauf zu schreiben, dass Sie mit der SQL-Optimierung vertraut sind
Nachdem der Optimierer den Ausführungsplan generiert hat, den MySQL für optimal hält, kommt er an den Ausführenden. Die Rolle des Ausführenden besteht natürlich darin, einfach die SQL-Anweisung auszuführen. Aber vor der Ausführung muss zunächst eine Berechtigungsüberprüfung durchgeführt werden, um zu überprüfen, ob der Benutzer über Abfrageberechtigungen für die Tabelle verfügt. Verwenden Sie dann entsprechend dem durch die Tabelle definierten Engine-Typ die von der entsprechenden Engine bereitgestellte Schnittstelle, um eine bedingte Abfrage für die Tabelle durchzuführen, und geben Sie schließlich alle Datenzeilen der Tabelle, die die Bedingungen erfüllen, als Ergebnismenge an den Client zurück dass die Ausführung des gesamten SQL beendet ist.
Es ist zu beachten, dass
überprüft wird, bevor der Executor die SQL-Anweisung ausführt: um festzustellen, ob der Benutzer über Betriebsberechtigungen für die Tabelle verfügt.2.6.1 InnoDB
InnoDB unterstützt Transaktionen, MVCC (Multiple Version Concurrency Control), Fremdschlüssel, Sperren auf Zeilenebene und automatisch inkrementierende Spalten. Allerdings unterstützt InnoDB keine Volltextindizierung und beansprucht mehr Datenraum.
2.6.2 MyISAM
Die Daten von MyISAM werden in einem kompakten Format gespeichert, sodass sie weniger Platz beanspruchen. Die Einfügungs- und Abfragegeschwindigkeiten sind hoch, MyISAM unterstützt jedoch keine Transaktionen und kann nach einem Absturz nicht sicher wiederhergestellt werden.
2.6.3 Speicher
Speicher unterstützt den Hash-Index, aber da er Sperren auf Tabellenebene verwendet, ist die Leistung gleichzeitiger Schreibvorgänge relativ gering.
Es ist erwähnenswert, dass temporäre Tabellen in MySQL im Allgemeinen in Speichertabellen gespeichert werden. Wenn die Datenmenge in der Zwischentabelle zu groß ist oder Felder vom Typ BLOB oder TEXT enthält, werden MyISAM-Tabellen verwendet.
Was die Speicher-Engine betrifft, werde ich sie nach der Lektüre von „MySQL Technology Insider: InnoDB Storage Engine“ nur kurz erwähnen, da ich relativ wenig Kontakt damit habe.3. Protokollmodul
Die logische Abfrageanweisung und die Aktualisierungsanweisung vom Client an den Executor sind identisch, mit der Ausnahme, dass die Update-Anweisung beim Erreichen der Executor-Ebene mit dem MySQL-Protokollmodul interagiert. Dies sind die Abfrageanweisung und die Update-Anweisung anders.
对于 InnoDB 存储引擎来说,它有一个特有的日志模块——物理日志(重做日志)redo log,它是 InnoDB 存储引擎的日志,它所记录的是数据页的物理修改。
举个例子,现在有一张 user 表,有一条主键 id=1,age=18 的数据,然后用户提交了下面这条 SQL,执行器准备执行。
update user set age=age+1 where id=1;复制代码
对于这条 SQL,在 redo log 中记录的内容大致是:将 user 表中主键 id=1 行的 age 字段值修改为19。
MySQL 的更新持久化逻辑运用到了 WAL(Write-Ahead Logging,写前日志记录) 的思想:先写日志,再写磁盘。
需要注意的是这里的写日志也是写到磁盘中,但由于日志是顺序写入的,所以速度很快。而如果没有 redo log,直接更新磁盘中的数据,那么首先需要找到那条记录,然后再把新的值更新进入,由于查询和读写I/O,就相对会慢一些。
最后,当 InnoDB 引擎空闲的时候,它会去执行 redo log 中的逻辑,将数据持久化到磁盘中。
redo log 日志文件大小是固定的,我把它理解为一个Eines meiner Verständnisse von MySQL: Infrastruktur,链表的每个节点都可以存放日志,在这个链表中有两个指针:write(黑) 和 read(白)。
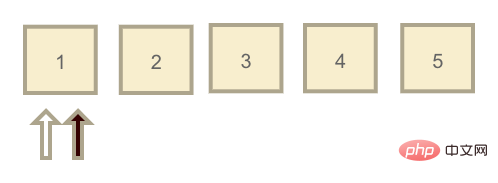
最开始这两个指针都指向同一个节点,且节点日志元素都为空,表示此时 redo log 为空。当用户开始提交更新语句,write 节点开始往前移动,假设移动到3的位置。而此时的情况就是 redo log 中有1-3这三个日志元素需要被持久化到磁盘中,当 InnoDB 空闲时,read 指针往前移动,就代表着将 redo log 持久化到磁盘。
但这里有一种特殊情况,就是 InnoDB 一直没有空闲,write 指针一直在写入日志,直到它写到5的位置,再往前写又回到了最开始1的位置(也就是上图的位置,但不同的是链表节点中都存在日志数据)。
此时发现1的位置已经有日志数据了,同时 read 指针也在。那么这时候 write 指针就会暂停写入,InnoDB 引擎开始催动 read 指针移动,把 redo log 清空掉一部分之后再让 write 指针写入日志文件。
我们已经知道,redo log 中记录的是数据页的物理修改,所以 redo log 能够保证在数据库发生异常重启时,记录尚未写入磁盘,但是在重启后可以通过 redo log 来“redo”,从而不会发生记录丢失的情况,保证了事务的持久性。
这一能力也被称作 crash-safe。
前面说到 redo log 是 InnoDB 特有的日志,而 bin log 则是属于 MySQL Server 层的日志,在默认的 Statement Level 下它记录的是更新语句的原始逻辑,即 SQL 本身。
另外需要注意的是:
与 redo log 不同的是,bin log 常用于恢复数据,比如说主从复制,从节点根据父节点的 bin log 来进行数据同步,实现主从同步。
为了让 redo log 和 bin log 的状态保持一致,MySQL 使用两阶段提交的方式来写入 redo log 日志。
在执行器调用 InnoDB 引擎的接口将写入更新数据时,InnoDB 引擎会将本次更新记录到 redo log 中,同时将 redo log 的状态标记为 prepare,表示可以提交事务。
随后执行器生成本次操作的 bin log 数据,并写入 bin log 的日志文件中。
最后执行器调用 InnoDB 的提交事务接口,存储引擎把刚写入的 redo log 记录状态修改为 commit,本次更新结束。
在这个过程中有三个步骤 add redo log and mark as prepare -> add bin log -> commit,即:
Wenn das System im zweiten Schritt, also vor dem Schreiben des Bin-Protokolls, abstürzt oder neu startet, sind keine Daten vorhanden Im Bin-Protokoll nach dem Start des Datensatzes werden die Datensätze im Redo-Protokoll vor dem Ausführen dieser Aktualisierungsanweisung zurückgesetzt.
Wenn das System vor dem dritten Schritt, also vor der Übermittlung, abstürzt oder neu startet, wird es automatisch festgeschrieben, auch wenn kein Commit erfolgt, es aber im Redo-Log als „Vorbereitung“ aufgezeichnet wird und ein vollständiger Datensatz im Bin-Log vorhanden ist nach dem Neustart und kommt nicht zurück.
In diesem Artikel werden hauptsächlich die Infrastruktur von MySQL und die Funktionen der einzelnen Komponenten vorgestellt. Schließlich werden das für InnoDB einzigartige Bin-Protokoll der MySQL-Serverschicht vorgestellt.
Die folgenden Fragen dienen dazu, Fragen zu den in diesem Artikel beschriebenen Inhalten zu stellen und das Wissen zu festigen: „Das Vergangene Revue passieren zu lassen und Neues zu lernen, kann zum Lehrer werden.“
Was ist der Unterschied zwischen Redo-Log und Bin-Log?
Weitere verwandte kostenlose Lernempfehlungen: MySQL-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonEines meiner Verständnisse von MySQL: Infrastruktur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



