

In der Kolumne „MySQL-Tutorial“ werden heute verwandte Indexkenntnisse vorgestellt.
Der zweite Artikel der MySQL-Reihe behandelt hauptsächlich einige Probleme zu Indizes in MySQL, einschließlich Indextypen, Datenmodellen, Indexausführungsprozessen, Präfixprinzipien ganz links, Indexfehlersituationen, Index-Pushdown usw.
Das erste Mal, dass ich etwas über Indizes gelernt habe, war im Kurs „Datenbankprinzipien“ im zweiten Jahr. Wenn eine Abfrageanweisung sehr langsam ist, können Sie „die Abfrageeffizienz verbessern“, indem Sie Indizes zu bestimmten Feldern hinzufügen. 
1. Indextypen
In MySQL wird der Index basierend auf der Logik oder den Feldeigenschaften grob in die folgenden Typen unterteilt: gewöhnlicher Index, eindeutiger Index, Primärschlüsselindex, gemeinsamer Index und Präfixindex.
Normaler Index: Der einfachste Index ohne Einschränkungen. Eindeutiger Index: Der Wert der Indexspalte muss eindeutig sein. Primärschlüsselindex: ein spezieller eindeutiger Index, dessen Wert als Primärschlüssel nicht leer sein darf. Gemeinsamer Index: Ein gemeinsamer Index ist ein gewöhnlicher Index mit mehreren Feldern in der Indexspalte. Sie müssen das „Prinzip des am weitesten links stehenden Präfixes“ berücksichtigen.2. Indexdatenstruktur
Unter normalen Umständen kann die zeitliche Komplexität einer äquivalenten Abfrage in einer Hash-Tabelle O(1) erreichen, aber im Falle eines Hash-Konflikts ist es notwendig, zusätzlich alle Werte in der verknüpften Liste zu durchlaufen um die passenden bedingten Daten zu finden.
Hash-Tabellen eignen sich also nur für Gleichheitsabfragen.
Wie der Name schon sagt, ist ein geordnetes Array ein Array, das in der Reihenfolge der Schlüssel angeordnet ist. Seine Zeitkomplexität für äquivalente Abfragen kann bei binären Abfragen O(logN) erreichen, was Hash-Tabellen deutlich unterlegen ist wenige.
Aber die Bereichsabfrage über ein geordnetes Array ist effizienter: Finden Sie zuerst den Minimalwert (oder Maximalwert) über eine binäre Abfrage und durchlaufen Sie ihn dann in umgekehrter Richtung bis zu einer anderen Grenze.
Was das Sortieren angeht, sind geordnete Arrays von Natur aus geordnet und natürlich sortiert. Natürlich ist das Sortierfeld kein Indexfeld, also lassen Sie uns separat darüber sprechen.
Aber geordnete Arrays haben einen Nachteil: Wenn zu diesem Zeitpunkt eine neue Datenzeile eingefügt wird, müssen Elemente größer als der Schlüssel dieses Elements eingefügt werden, um die Ordnung des geordneten Arrays aufrechtzuerhalten verschoben werden. Bewegen Sie dann eine Einheit, um einen Platz zu schaffen, an dem sie eingefügt werden kann. Und die Kosten für diese Art der Indexpflege sind sehr hoch.
2.3 Suchbaum
Wer die Datenstruktur kennt, sollte wissen, dass der Suchbaum eine Datenstruktur mit einer Abfragezeitkomplexität von O(logN) und einer Aktualisierungszeitkomplexität von O(logN) ist. Daher berücksichtigen Suchbäume im Vergleich zu Hash-Tabellen und geordneten Arrays sowohl Abfrage- als auch Aktualisierungsaspekte. Aus diesem Grund ist der Suchbaum das am häufigsten verwendete Datenmodell in MySQL.
Angesichts der Tatsache, dass der Index auf der Festplatte gespeichert ist und der Suchbaum ein Binärbaum ist, kann er nur zwei linke und rechte untergeordnete Knoten haben. Wenn viele Daten vorhanden sind, kann die Höhe dieses Binärbaums sehr groß sein hoch. Wenn MySQL Abfragen durchführt, ist die Anzahl der Festplatten-E/A aufgrund der Höhe des Baums möglicherweise zu hoch und die Abfrageeffizienz wird geringer.
Darüber hinaus gibt es auch einen Volltextindex, der das Problem der Bestimmung, ob ein Feld enthalten ist, durch die Einrichtung eines invertierten Index löst.
Der invertierte Index wird verwendet, um die Zuordnung des Speicherorts eines Wortes in einem Dokument oder einer Gruppe von Dokumenten im Rahmen der Volltextsuche zu speichern. Über den invertierten Index können Sie schnell eine Liste von Dokumenten erhalten, die dieses Wort enthalten das Wort.
Bei der Suche nach Schlüsselwörtern ist die Volltextindizierung hilfreich.
Dies ist ein relativ einfacher B+-Baum.
... Wert der Indexspalte. 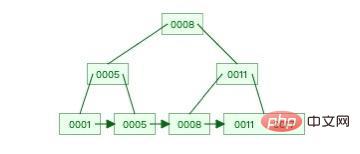
In dieser Tabelle gibt es nur zwei Felder: die Primärschlüssel-ID und das Namensfeld, und es wird ein BTree-Index mit dem Namensfeld als Indexspalte erstellt. Ein Index, der auf dem Primärschlüssel-ID-Feld basiert, wird auch als Primärschlüsselindex bezeichnet. Seine Indexbaumstruktur ist: Die Nicht-Blatt-Stufe des Indexbaums speichert den Wert der Primärschlüssel-ID und den im Blatt gespeicherten Wert Knoten istIn InnoDB wird am häufigsten das auf BTree basierende Indexmodell verwendet. Hier ist ein praktisches Beispiel zur Veranschaulichung der Struktur des BTree-Index in InnoDB.
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(36) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `nameIndex`(`name`) USING BTREE ) ENGINE = InnoDB;-- 插入数据insert into user1(id,name,age) values (1,'one',21),(2,'two',22),(3,'three',23),(4,'four',24),(5,'five',25);复制代码Nach dem Login kopieren
Auch weil die Blattknoten des Primärschlüsselindex die gesamte Datenzeile speichern, die der Primärschlüssel-ID entspricht, dem Primärschlüssel Der Schlüsselindex wird auch Clustered-Index genannt. In einem Indexbaum mit dem Namensfeld als Spalte speichern die Nicht-Blattknoten auch den Wert der Indexspalte, und der in der Blattstufe gespeicherte Wert ist der Wert der
Primärschlüssel-ID, wie in gezeigt die Abbildung unten. 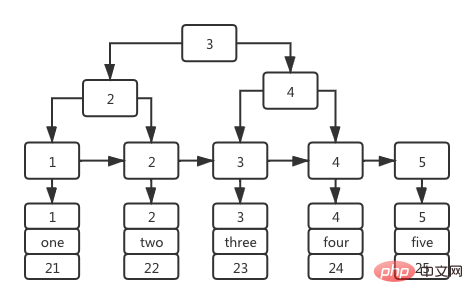
3.3 IndexausführungsprozessSehen Sie sich zunächst den folgenden SQL-Satz an, um die Datenzeile mit der ID = 1 in der Benutzertabelle abzufragen.
select * from user where id=1;复制代码
Der Ausführungsprozess dieser SQL ist sehr einfach. Wenn die Speicher-Engine die ID = 1 findet, gibt sie die Datenzeile mit der ID = 1 im Indexbaum zurück. Da der Primärschlüsselwert eindeutig ist, wird die Suche gestoppt und die Ergebnismenge direkt zurückgegeben, wenn das Trefferziel gefunden wird. 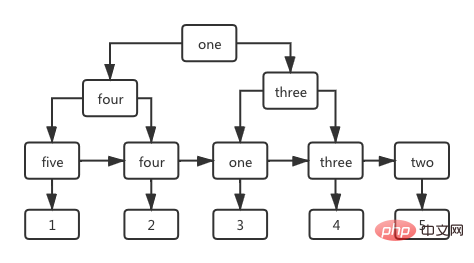
select * from user where name='one';复制代码
Zurück an den Tisch
. Da die Unterknoten des Indexbaums gewöhnlicher Indizes Primärschlüsselwerte speichern, muss die Abfrageanweisung, wenn sie andere Felder außer der Primärschlüssel-ID und der Indexspalte abfragen muss, zur Abfragebasis zum Primärschlüssel-Indexbaum zurückkehren Rufen Sie anhand des Werts der Primärschlüssel-ID die gesamte Datenzeile ab, die der Primärschlüssel-ID entspricht, und rufen Sie dann die vom Client benötigten Felder ab, bevor Sie diese Zeile zum Ergebnissatz hinzufügen. Dann durchsucht die Speicher-Engine den Indexbaum weiter, bis sie auf den ersten Datensatz stößt, dername='one' nicht erfüllt. Anschließend stoppt sie die Suche und gibt schließlich alle Trefferdatensätze an den Indexbaum zurück Kunde. Wir nennen den Prozess der Abfrage der gesamten Datenzeile im Primärschlüsselindex basierend auf dem vom gewöhnlichen Index abgefragten Primärschlüssel-ID-Wert
zurück zur Tabelle. Wenn die Datenmenge sehr groß ist, ist die Tabellenrückgabe ein sehr zeitaufwändiger Prozess. Daher sollten wir versuchen, die Tabellenrückgabe zu vermeiden, was zur nächsten Frage führt: Verwenden Sie abdeckende Indizes, um die Tabellenrückgabe zu vermeiden.name='one' 的记录才会停止搜索,最后将所有命中的记录返回客户端。我们把根据从普通索引查询到的主键 id 值,再在主键索引中查询整个数据行的过程称之为回表。
当数据量十分庞大时,回表是一个十分耗时的过程,所以我们应该尽量避免回表发生,这就引出了下一个问题:使用覆盖索引避免回表。
不知道你有没有注意到,在上一个回表的问题中有这样一句描述:“当查询语句需要查询除主键 id 及索引列之外的其他字段时...”,在这种场景下需要通过回表来获取其他的查询字段。也就是说,如果查询语句需要查询的字段仅有主键 id 和索引列的字段时,是不是就不需要回表了?
下面来分析一波这个过程,首先建立一个联合索引。
alter table user add index name_age ('name','age');复制代码那么这棵索引树的结构图应该是下面这样:

联合索引索引树的子节点顺序是按照声明索引时的字段来排序的,类似于 order by name, age
select name,age from user where name='one';复制代码
 🎜🎜Die Reihenfolge der untergeordneten Knoten des gemeinsamen Index-Indexbaums wird nach dem Feld beim Indexieren sortiert wird deklariert, ähnlich wie bei
🎜🎜Die Reihenfolge der untergeordneten Knoten des gemeinsamen Index-Indexbaums wird nach dem Feld beim Indexieren sortiert wird deklariert, ähnlich wie bei Reihenfolge nach Name, Alter. Der seinem Index entsprechende Wert ist der Primärschlüsselwert wie bei einem normalen Index. 🎜select name,age from user where name='one';复制代码
上面这条 SQL 是查询所有 name='one' 记录的 name 和 age 字段,理想的执行计划应该是搜索刚刚建立的联合索引。
与普通索引一样,存储引擎会搜索联合索引,由于联合索引的顺序是先按照 name 再按照 age 进行排序的,所以当找到第一个 name 不是 one 的索引时,才会停止搜索。
而由于 SQL 语句查询的只是 name 和 age 字段,恰好存储引擎命中查询条件时得到的数据正是 name, age 和 id 字段,已经包含了客户端需要的字段了,所以就不需要再回表了。
我们把只需要在一棵索引树上就可以得到查询语句所需要的所有字段的索引成为覆盖索引,覆盖索引无须进行回表操作,速度会更快一些,所以我们在进行 SQL 优化时可以考虑使用覆盖索引来优化。
上面所举的例子都是使用索引的情况,事实上在项目中复杂的查询语句中,也可能存在不使用索引的情况。首先我们要知道,MySQL 在执行 SQL 语句的时候一张表只会选择一棵索引树进行搜索,所以一般在建立索引时需要尽可能覆盖所有的查询条件,建立联合索引。
而对于联合索引,MySQL 会遵循最左前缀原则:查询条件与联合索引的最左列或最左连续多列一致,那么就可以使用该索引。
为了详细说明最左前缀原则,同时说明最左前缀原则的一些特殊情况。
即便我们根据最左前缀的原则创建了联合索引,还是会有一些特殊的场景会导致索引失效,下面举例说明。
假设有一张 table 表,它有一个联合索引,索引列为 a,b,c 这三个字段,这三个字段的长度均为10。
CREATE TABLE `demo` ( `a` varchar(1) DEFAULT NULL, `b` varchar(1) DEFAULT NULL, `c` varchar(1) DEFAULT NULL, INDEX `abc_index`(`a`, `b`, `c`) USING BTREE ) ENGINE = InnoDB;复制代码
第一种情况是查询条件与索引字段全部一致,并且用的是等值查询,如:
select * from demo where a='1' and b='1' and c='1';select * from demo where c='1' and a='1' and b='1';复制代码
输出上述两条 SQL 的执行计划来看它们使用索引的情况。
mysql> explain select * from demo where a='1' and b='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where c='1' and a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)复制代码
第一条 SQL 很显然能够用到联合索引。
从执行计划中可以看到,第二条 SQL 与第一条 SQL 使用的索引以及索引长度是一致的,都是使用 abc_index 索引,索引长度为 18 个字节。
按理说查询条件与索引的顺序不一致,应该不会用到索引,但是由于 MySQL 有优化器存在,它会把第二条 SQL 优化成第一条 SQL 的样子,所以第二条 SQL 也使用到了联合索引 abc_index。
综上所述,全字段匹配且为等值查询的情况下,查询条件的顺序不一致也能使用到联合索引。
第二种情况是查询条件与索引字段部分保持一致,这里就需要遵循最左前缀的原则,如:
select * from demo where a='1' and b='1';select * from demo where a='1' and c='1';复制代码
上述的两条查询语句分别对应三个索引字段只用到两个字段的情况,它们的执行计划是:
mysql> explain select * from demo where a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 12 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where a='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 6 | const | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从它们的执行计划可以看到,这两条查询语句都使用到了 abc_index 索引,不同的是,它们使用到索引的长度分别是:12、6 字节。
在这里需要额外提一下索引长度的计算方式,对于本例中声明为 varchar(1) 类型的 a 字段,它的索引长度= 1 * (3) + 1 + 2 = 6。
所以这两条查询语句使用索引的情况是:
由此可见:最左前缀原则要求,查询条件必须是从索引最左列开始的连续几列。
第三种情况是查询条件用的是范围查询(,!=,=,between,like)时,如:
select * from demo where a='1' and b!='1' and c='1';复制代码
这两条查询语句的执行计划是:
mysql> EXPLAIN select * from demo where a='1' and b!='1' and c='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 12 | NULL | 2 | 10.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从执行计划可以看到,第一条 SQL 使用了联合索引,且索引长度为 12 字节,即用到了 a,b 两个字段;第二条 SQL 也使用了联合索引,索引长度为 6 字节,仅使用了联合索引中的 a 字段。
综上所述,在全字段匹配且为范围查询的情况下,也能使用联合索引,但只能使用到联合索引中第一个出现范围查询条件的字段。
需要注意的是:
第四种情况是查询条件中带有函数或特殊表达式的,比如:
select * from demo where id + 1 = 2;select * from demo where concat(a, '1') = '11';复制代码
可能由于数据的原因(空表),我输出的执行计划是使用了联合索引的,但是事实上,在查询条件中,等式不等式左侧的字段包含表达式或函数时,该字段是不会用到索引的。
至于原因,是因为使用函数或表达式的情况下,索引字段本身的值已不具备有序性。
上文中已经罗列了联合索引的实际结构、最左前缀原则以及索引失效的场景,这里再说一下索引下推这个重要的优化规则。
select * from demo where a > '1' and b='1'; mysql> explain select * from demo where a > '1' and b='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 6 | NULL | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)复制代码
上面这条查询语句,从它的执行计划也可以看出,它使用的索引长度为 6 个字节,只用到了第一个字段。
所以 MySQL 在查询过程中,只会对第一个字段 a 进行 a > '1' 的条件判断,当满足条件后,存储引擎并不会进行 b=1 的判断, 而是通过回表拿到整个数据行之后再进行判断。
这好像很蠢,就算索引只用到了第一个字段,但明明索引树中就有 b 字段的数据,为什么不直接进行判断呢?
听上去好像是个 bug,其实在未使用索引下推之前整个查询逻辑是:由存储引擎检索索引树,就算索引树中存在 b 字段的值,但由于这条查询语句的执行计划使用了联合索引但没有用到 b 字段,所以也无法进行 b 字段的条件判断,当存储引擎拿到满足条件(a>'1')的数据后,再由 MySQL 服务器进行条件判断。
在 MySQL5.6 版本中对这样的情况进行优化,引入索引下推技术:在搜索索引树的过程中,就算没能用到联合索引的其他字段,也能优先对查询条件中包含且索引也包含的字段进行判断,减少回表次数,提高查询效率。
在使用索引下推优化之后,b 字段作为联合索引列,又存在于查询条件中,同时又没有在搜索索引树时被使用到,MySQL 服务器会把查询条件中关于 b 字段的部分也传给存储引擎,存储引擎会在搜索索引树命中数据之后再进行 b 字段查询条件的判断,满足的才会加入结果集。
Ps: 执行计划中 Extra 字段的值包含 Using index condition 就代表使用到了索引下推。
更多相关免费学习推荐:mysql教程(视频)
Das obige ist der detaillierte Inhalt vonMein Verständnis von MySQL Teil 2: Index. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 Was ist ein Index?
Was ist ein Index?
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



