
In der Spalte
Basic Java Tutorial wird vorgestellt, wie Billionen von Daten migriert werden sollten.

In Xingyes „Westward Journey“ gibt es eine sehr berühmte Zeile: „Es gab einmal eine aufrichtige Beziehung vor mir, die ich nicht schätzte. Ich habe es erst bereut, als ich sie verloren habe.“ „Und das Schmerzlichste auf der Welt ist das. Wenn Gott mir noch eine Chance geben kann, werde ich jedem Mädchen drei Worte sagen: Ich liebe dich. Wenn ich dieser Liebe eine zeitliche Grenze hinzufügen muss, hoffe ich, Zehntausend Jahre!“ In den Augen unserer Entwickler ist diese Emotion die gleiche wie die Daten in unserer Datenbank. Wir hoffen, dass sich die Dinge zehntausend Jahre lang nicht ändern . Auch unsere Anforderungen an Daten ändern sich ständig und es gibt wahrscheinlich folgende Situationen:
In der tatsächlichen Geschäftsentwicklung werden wir je nach Situation unterschiedliche Migrationspläne erstellen. Als nächstes besprechen wir, wie Daten migriert werden.
Tatsächlich erfolgt die Datenmigration nicht über Nacht, es kann eine Woche oder mehrere Monate dauern. Im Allgemeinen ähnelt unser Datenmigrationsprozess im Wesentlichen dem Bild unten . :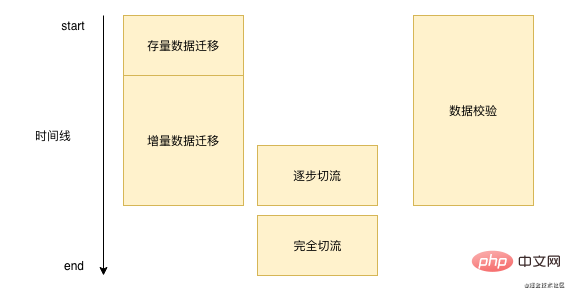 '
Zuerst müssen wir die vorhandenen Daten in unserer Datenbank stapelweise migrieren und dann die neuen Daten verarbeiten. Wir müssen diese Daten in Echtzeit in unseren neuen Speicher schreiben. Hier müssen wir die Daten kontinuierlich überprüfen während des Prozesses. Wenn wir sicherstellen, dass die grundlegenden Probleme nicht schwerwiegend sind, führen wir den Flow-Cut-Vorgang durch. Nach Abschluss des Flow-Cut-Vorgangs müssen wir keine Datenüberprüfung und inkrementelle Datenmigration mehr durchführen.
'
Zuerst müssen wir die vorhandenen Daten in unserer Datenbank stapelweise migrieren und dann die neuen Daten verarbeiten. Wir müssen diese Daten in Echtzeit in unseren neuen Speicher schreiben. Hier müssen wir die Daten kontinuierlich überprüfen während des Prozesses. Wenn wir sicherstellen, dass die grundlegenden Probleme nicht schwerwiegend sind, führen wir den Flow-Cut-Vorgang durch. Nach Abschluss des Flow-Cut-Vorgangs müssen wir keine Datenüberprüfung und inkrementelle Datenmigration mehr durchführen.
Lassen Sie uns zunächst darüber sprechen, wie Sie vorhandene Daten migrieren können. Nachdem wir in der Open-Source-Community nach vorhandenen Datenmigrationen gesucht haben, haben wir festgestellt, dass es derzeit keine einfach zu verwendenden Tools für Alibaba Cloud gibt Bietet die Migration bestehender Daten. DTS unterstützt die Migration zwischen verschiedenen homogenen und heterogenen Datenquellen und unterstützt grundsätzlich branchenübliche Datenbanken wie MySQL, Orcale, SQL Server usw. DTS eignet sich besser für die ersten beiden zuvor erwähnten Szenarien. Wenn Sie DRDS von Alibaba Cloud verwenden, können Sie die Daten direkt über DTS migrieren. Unabhängig davon, ob Redis, ES und DTS alle die direkte Migration unterstützen.
Wie migriert man also DTS-Bestände? Tatsächlich ist es relativ einfach und besteht wahrscheinlich aus den folgenden Schritten:
select * from table_name where id > curId and id < curId + 10000;复制代码
3 Wenn die ID größer oder gleich maxId ist, endet die bestehende Datenmigrationsaufgabe
Natürlich verwenden wir Alibaba Cloud möglicherweise nicht während des eigentlichen Migrationsprozesses, oder in unserem dritten Szenario müssen wir viele Konvertierungen zwischen Datenbankfeldern durchführen und DTS unterstützt dies nicht. Dann können wir DTS nachahmen Migrieren Sie Daten durch stapelweises Lesen von Daten in Segmenten. Hierbei ist zu beachten, dass wir bei der stapelweisen Migration von Daten die Größe und Häufigkeit der Segmente kontrollieren müssen, um zu verhindern, dass sie den normalen Betrieb unseres Online-Betriebs beeinträchtigen.
Die Migrationslösungen für vorhandene Daten sind relativ begrenzt, aber inkrementelle Datenmigrationsmethoden sind in voller Blüte:
Welche sollten wir bei so vielen Methoden verwenden? Persönlich empfehle ich die Überwachung des Binlogs, um die Entwicklungskosten zu senken. Da es sich um ein überwachtes Binlog handelt, besteht kein Grund zur Sorge verschiedene geschäftliche Probleme.
Obwohl es sich bei allen oben genannten Lösungen um ausgereifte Cloud-Dienste (DTS) oder Middleware (Kanal) handelt, ist es wahrscheinlich, dass sie einen gewissen Datenverlust erleiden, und es kommt immer noch zu Datenverlusten relativ selten, aber es ist sehr schwierig, Fehler zu beheben. Es kann sein, dass das DTS oder der Kanal versehentlich wackelt oder beim Empfangen von Daten versehentlich verloren geht. Da wir nicht verhindern können, dass unsere Daten während des Migrationsprozesses verloren gehen, sollten wir sie auf andere Weise korrigieren.
Normalerweise gibt es bei der Datenmigration einen Schritt der Datenüberprüfung, aber verschiedene Teams wählen möglicherweise unterschiedliche Datenüberprüfungsschemata:
Natürlich müssen wir im eigentlichen Entwicklungsprozess auch auf folgende Punkte achten:
Nachdem unsere Datenüberprüfung grundsätzlich keine Fehler aufweist, bedeutet dies, dass unser Migrationsprogramm relativ stabil ist. Können wir dann unsere neuen Daten direkt verwenden? Natürlich ist es nicht möglich, alles auf einmal umzustellen, aber wenn etwas schief geht, wird es alle Benutzer betreffen.
Als nächstes müssen wir Graustufen durchführen, also Stream-Cutting. Die Dimensionen verschiedener Geschäftsflusskürzungen sind unterschiedlich. Für die Kürzung von Datenflüssen in der Mandanten- oder Händlerdimension verwenden wir normalerweise die Modulo-Methode der Mandanten-ID der Fluss. Für diese Verkehrsreduzierung müssen Sie einen Plan zur Verkehrsreduzierung erstellen, in welchem Zeitraum und wie viel Verkehr freigegeben werden soll, und wenn Sie den Verkehr reduzieren, müssen Sie einen Zeitpunkt wählen, zu dem der Verkehr relativ gering ist Um detaillierte Beobachtungen der Protokolle durchzuführen, wird der Prozess der Freigabe des Datenverkehrs zu Beginn mit 1 % kontinuierlich überlagert Verwenden Sie direkt 10 % oder 20 % der Lautstärke, um die Lautstärke schnell zu erhöhen. Denn wenn es ein Problem gibt, wird es oft entdeckt, wenn der Verkehr gering ist. Wenn es bei geringem Verkehr kein Problem gibt, kann das Volumen schnell erhöht werden.
Bei der Datenmigration sollte besonders auf die Primärschlüssel-ID geachtet werden. In der oben genannten Lösung mit doppeltem Schreiben wird auch erwähnt, dass die Primärschlüssel-ID doppelt sein muss - manuell geschrieben und angegeben, um zu verhindern, dass die ID-Generierungsreihenfolge falsch ist.
Wenn wir aufgrund von Sharding-Datenbanken und -Tabellen migrieren, müssen wir berücksichtigen, dass unsere zukünftige Primärschlüssel-ID keine automatisch inkrementierte ID sein kann und wir verteilte IDs verwenden müssen. Die empfohlenere hier ist Meituans Open-Source-Blatt. Der erste Modus ist der Snowflake-Algorithmus mit steigendem Trend, aber alle IDs sind vom Typ Long, was für einige Anwendungen geeignet ist, die Long als ID unterstützen. Es gibt auch einen Nummernsegmentmodus, der basierend auf einer von Ihnen festgelegten Basis-ID von oben weiter ansteigt. Und grundsätzlich nutzen alle die Speichergenerierung, und die Leistung ist auch sehr schnell.
Natürlich gibt es immer noch Situationen, in denen wir das System migrieren müssen. Die Primärschlüssel-ID des vorherigen Systems ist bereits im neuen System vorhanden, sodass unsere ID einige Zuordnungen vornehmen muss. Wenn wir bei der Migration des Systems bereits wissen, welche Systeme in Zukunft migriert werden, können wir die Reservierungsmethode verwenden. Beispielsweise betragen die aktuellen Daten von System A 100 Millionen bis 100 Millionen und die Daten von System B ebenfalls 100 Millionen Wir müssen nun die beiden Systeme A und B zu einem neuen System zusammenführen. Dann können wir den Puffer leicht schätzen, indem wir beispielsweise 100 bis 150 Millionen für System A belassen, sodass A nicht zugeordnet werden muss. und System B beträgt 150 Millionen bis 300 Millionen. Wenn wir dann auf die alte System-ID umstellen, müssen wir 150 Millionen abziehen. Schließlich wird die neue ID unseres neuen Systems von 300 Millionen erhöht. Was aber, wenn im System kein geplantes reserviertes Segment vorhanden ist? Sie können dies auf zwei Arten tun:
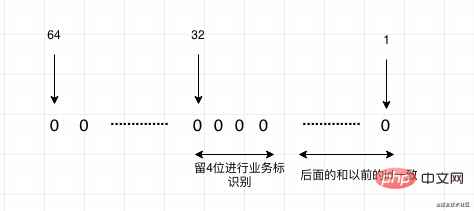
Lassen Sie uns diese Routine abschließend kurz zusammenfassen. Es handelt sich tatsächlich um vier Schritte: Lager, Inkrement, Überprüfung, Flussschnitt und schließlich auf die ID achten. Unabhängig davon, wie groß die Datenmenge ist, wird es bei der Migration nach dieser Routine im Grunde keine großen Probleme geben. Ich hoffe, dieser Artikel kann Ihnen bei Ihrer späteren Datenmigrationsarbeit helfen.
Wenn Sie der Meinung sind, dass dieser Artikel für Sie hilfreich ist, sind Ihre Aufmerksamkeit und Weiterleitung die größte Unterstützung für mich, O(∩_∩)O:
Verwandte kostenlose Lernempfehlungen: Grundlegendes Java-Tutorial
Das obige ist der detaillierte Inhalt vonWie Billionen Daten migriert werden sollen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
 Was bedeutet WLAN deaktiviert?
Was bedeutet WLAN deaktiviert?
 Was ist der Befehl zum Löschen einer Spalte in SQL?
Was ist der Befehl zum Löschen einer Spalte in SQL?
 Was bedeutet Handy-HD?
Was bedeutet Handy-HD?
 Was bedeutet es, einen Drucker offline zu verwenden?
Was bedeutet es, einen Drucker offline zu verwenden?
 Ripple-Kaufprozess
Ripple-Kaufprozess
 So öffnen Sie das TIF-Format in Windows
So öffnen Sie das TIF-Format in Windows
 Was sind die Java-Workflow-Engines?
Was sind die Java-Workflow-Engines?











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



