

Verstehen Sie die Checkpoint-Technologie von InnoDB

In der Spalte „MySQL-Tutorial“ lernen Sie die Checkpoint-Technologie von InnoDB kennen.
In einem Satz: Checkpoint-Technologie ist der Vorgang, bei dem schmutzige Seiten im Cache-Pool zu einem bestimmten Zeitpunkt zurück auf die Festplatte geleert werden. Sind Probleme aufgetreten?

Wir alle wissen, dass die Entstehung des Pufferpools dazu dient, die Lücke zwischen CPU- und Festplattengeschwindigkeit zu schließen, sodass wir beim Lesen und Schreiben der Datenbank keine Festplatten-E/A-Vorgänge ausführen müssen. Beim Pufferpool werden alle Seitenvorgänge zunächst im Pufferpool abgeschlossen. Wenn beispielsweise in einer DML-Anweisung ein Datenaktualisierungs- oder Löschvorgang durchgeführt wird, wird der Datensatz auf der Pufferpoolseite geändert. Da die Daten auf der Pufferpoolseite zu diesem Zeitpunkt neuer sind als die Daten auf der Festplatte wird als Dirty Page bezeichnet.
Egal was passiert, die Speicherseitendaten müssen nach der Hauptversammlung wieder auf die Festplatte geleert werden. Hierbei gibt es mehrere Probleme:
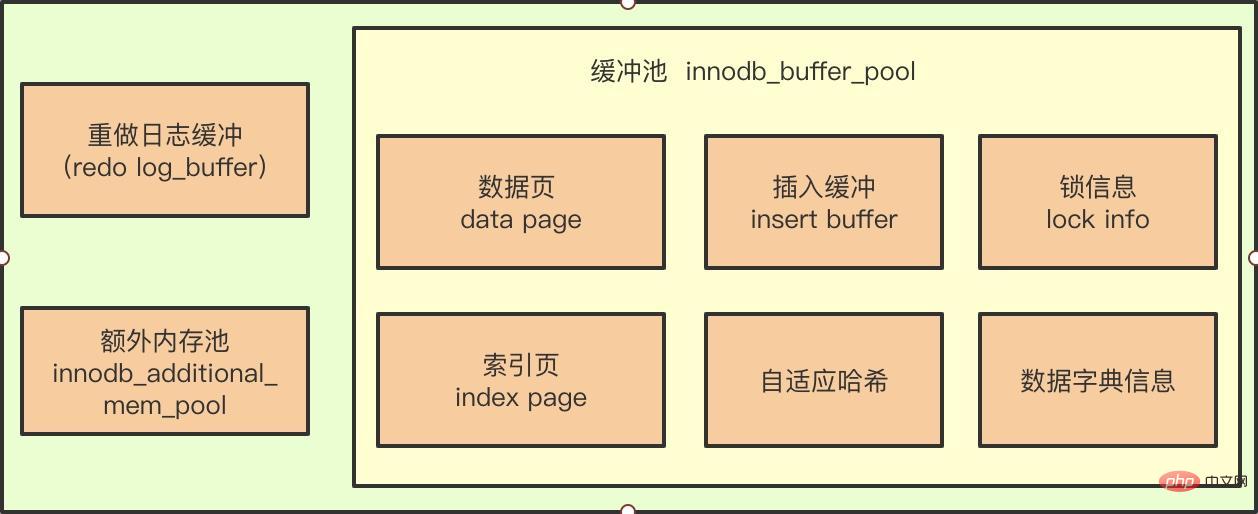 Wenn sich eine Seite ändert, wird die neue Seitenversion auf die Festplatte geleert , dann ist dieser Overhead sehr groß Die Daten können nicht wiederhergestellt werden
Wenn sich eine Seite ändert, wird die neue Seitenversion auf die Festplatte geleert , dann ist dieser Overhead sehr groß Die Daten können nicht wiederhergestellt werden
- (Redo-Log), das Ändern der Pufferpool-Datenseite, sodass das System nach einem Neustart bei einem Stromausfall weiterarbeiten kann.
- Prinzip des WAL-Richtlinienmechanismus
- InnoDB für Stellen Sie sicher, dass keine Daten verloren gehen und das Redo-Protokoll gepflegt wird. Bevor die Datenseite im Pufferpool geändert wird, muss der geänderte Inhalt im Redo-Protokoll aufgezeichnet werden und das Redo-Protokoll muss früher als die entsprechende Datenseite auf die Festplatte geleert werden.
Wenn ein Fehler auftritt und Speicherdaten verloren gehen, stellt InnoDB die Datenseiten des Pufferpools in den Zustand vor dem Absturz zurück, indem das Redo-Protokoll beim Neustart erneut abgespielt wird.
Checkpoint
Es liegt auf der Hand, dass wir uns mit der WAL-Strategie zurücklehnen und entspannen können. Das Problem tritt jedoch erneut im Redo-Log auf:
- Das Redo-Log kann nicht unendlich sein, und wir können unsere Daten nicht endlos speichern und darauf warten, gemeinsam auf der Festplatte aktualisiert zu werden.
- Wenn die Datenbank im Leerlauf ist und wiederhergestellt wird, wenn das Redo-Log vorhanden ist zu groß Wenn es groß ist, sind auch die Wiederherstellungskosten sehr hoch
Um die Aktualisierungsleistung verschmutzter Seiten zu lösen, wann und unter welchen Umständen verschmutzte Seiten aktualisiert werden sollten, wird die Checkpoint-Technologie verwendet.
Der Zweck von Checkpoint
1. Verkürzen Sie die Wiederherstellungszeit der Datenbank
Wenn die Datenbank inaktiv ist und wiederhergestellt wird, müssen nicht alle Protokollinformationen wiederholt werden. Weil die Datenseite vor Checkpoint zurück auf die Festplatte geleert wurde. Stellen Sie einfach das Redo-Log nach dem Checkpoint wieder her.
2. Wenn der Pufferpool nicht ausreicht, leeren Sie die verschmutzten Seiten auf die Festplatte.
Wenn der Pufferpoolspeicher nicht ausreicht, läuft die zuletzt verwendete Seite gemäß dem LRU-Algorithmus über Seite, dann muss ein Prüfpunkt erzwungen werden. Die fehlerhaften Seiten, bei denen es sich um neue Versionen der Seiten handelt, werden zurück auf die Festplatte geleert.
3. Wenn das Redo-Log nicht verfügbar ist, aktualisieren Sie die schmutzigen Seiten
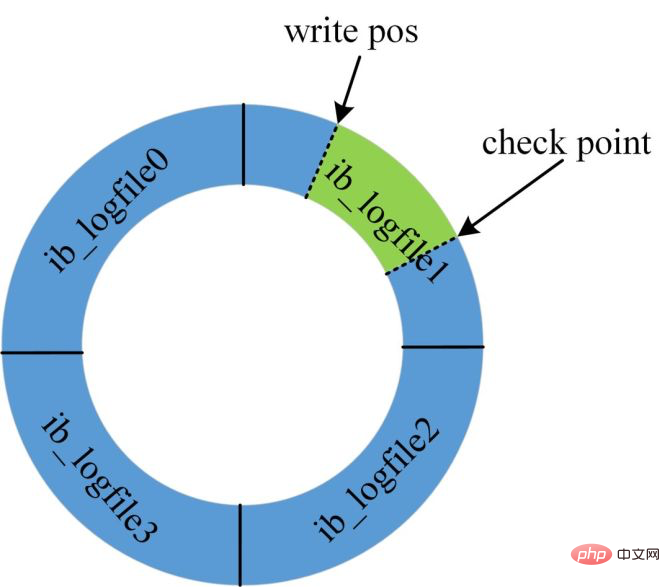
Wie in der Abbildung gezeigt, ist das Redo-Log nicht verfügbar, da die aktuelle Datenbank für die zyklische Verwendung ausgelegt ist und daher nicht unendlich viel Speicherplatz bietet .
Wenn das Redo-Protokoll voll ist, werden alle Aktualisierungsanweisungen blockiert, da das System zu diesem Zeitpunkt keine Aktualisierungen akzeptieren kann.
Zu diesem Zeitpunkt muss die Generierung eines Checkpoints erzwungen werden und die Schreibposition muss nach vorne verschoben werden. Die schmutzigen Seiten innerhalb des Fortschrittsbereichs müssen auf die Festplatte geleert werden.
Arten von Checkpoints. Die Zeit und Bedingungen dafür Das Auftreten von Checkpoints und die Auswahl schmutziger Seiten sind sehr komplex.
Checkpoint Wie viele verschmutzte Seiten werden jedes Mal auf die Festplatte geleert?
Woher bekommt Checkpoint jedes Mal schmutzige Seiten?
Wann wird Checkpoint ausgelöst?
Angesichts der oben genannten Probleme stellt uns die InnoDB-Speicher-Engine intern zwei Arten von Checkpoints zur Verfügung:
- Sharp Checkpoint
-
tritt auf, wenn die Datenbank heruntergefahren wird und alle fehlerhaften Seiten zurück auf die Festplatte geleert werden ist der Standardjob. Methode, Parameter innodb_fast_shutdown=1
Fuzzy Checkpoint -
InnoDB-Speicher-Engine verwendet diesen Modus intern und löscht nur einen Teil der schmutzigen Seiten, anstatt alle schmutzigen Seiten zurück auf die Festplatte zu leeren. Was passiert? an FuzzyCheckpoint
schreibt fast jede Sekunde oder alle zehn Sekunden einen bestimmten Anteil der Seiten aus der Liste der schmutzigen Seiten im Pufferpool zurück auf die Festplatte.
Dieser Prozess ist asynchron, das heißt, die InnoDB-Speicher-Engine kann zu diesem Zeitpunkt andere Vorgänge ausführen und der Benutzerabfrage-Thread wird nicht blockiert- FLUSH_LRU_LIST PrüfpunktDa die LRU-Liste sicherstellen muss, dass eine bestimmte Anzahl von Es können freie Seiten verwendet werden. Wenn die Seite nicht ausreicht, wird die Seite aus dem Ende entfernt. Wenn die entfernte Seite fehlerhafte Seiten enthält, wird dieser Prüfpunkt durchgeführt. Nach Version 5.6 wird dieser Checkpoint in einem separaten Page Cleaner-Thread platziert und Benutzer können die Anzahl der verfügbaren Seiten in der LRU-Liste über den Parameter innodb_lru_scan_ Depth steuern. Der Standardwert ist 1024
-
Async/Sync Flush Checkpoint
Bezieht sich auf die Situation, in der die Redo-Log-Datei nicht verfügbar ist. Zu diesem Zeitpunkt müssen die fehlerhaften Seiten aus der Liste der fehlerhaften Seiten ausgewählt werden 5.6, Benutzeranfragen werden nicht blockiert - Dirty Page too much Checkpoint Das heißt, die Anzahl der fehlerhaften Seiten ist zu groß, was dazu führt, dass die InnoDB-Speicher-Engine einen Prüfpunkt erzwingt. Der übergeordnete Zweck besteht darin, sicherzustellen, dass im Pufferpool genügend Seiten verfügbar sind. Es kann durch den Parameter innodb_max_dirty_pages_pct gesteuert werden. Der Wert beträgt beispielsweise 75, was bedeutet, dass CheckPoint gezwungen wird, Pufferpool-Datenseiten auszuführen, um die Datenbank-DML zu beschleunigen Operationen
- Aufgrund des Konsistenzproblems zwischen Pufferpool-Datenseiten und Festplattendaten erscheint die WAL-Strategie (der Kern ist das Redo-Log). Technologie InnoDB Um die Ausführungseffizienz zu verbessern, interagiert nicht jeder DML-Vorgang mit der Festplatte. Schreiben Sie stattdessen zuerst das Redo-Protokoll über Write Ahead Log, um die Persistenz der Dinge sicherzustellen. Für in Transaktionen geänderte Dirty-Puffer-Pool-Seiten wird die Festplatte asynchron geleert und die Verfügbarkeit freier Speicherseiten und Redo-Logs wird durch die Checkpoint-Technologie garantiert.
MySQL-Tutorial
- (Video)
Das obige ist der detaillierte Inhalt vonVerstehen Sie die Checkpoint-Technologie von InnoDB. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Was ist MySQL Innodb?
Apr 14, 2023 am 10:19 AM
Was ist MySQL Innodb?
Apr 14, 2023 am 10:19 AM
InnoDB ist eine der Datenbank-Engines von MySQL und einer der Standards für Binärversionen von MySQL AB. Ein zweigleisiges Autorisierungssystem ist die GPL-Autorisierung, das andere ist proprietäre Software Genehmigung. InnoDB ist die bevorzugte Engine für Transaktionsdatenbanken und unterstützt Transaktionssicherheitstabellen (ACID). InnoDB unterstützt Sperren auf Zeilenebene, die die Parallelität weitgehend unterstützen können. Sperren auf Zeilenebene werden von der Speicher-Engine-Ebene implementiert.
 Wie MySQL das InnoDB-Zeilenformat anhand von Binärinhalten erkennt
Jun 03, 2023 am 09:55 AM
Wie MySQL das InnoDB-Zeilenformat anhand von Binärinhalten erkennt
Jun 03, 2023 am 09:55 AM
InnoDB ist eine Speicher-Engine, die Daten in Tabellen auf der Festplatte speichert, sodass unsere Daten auch nach dem Herunterfahren und Neustarten noch vorhanden sind. Der eigentliche Prozess der Datenverarbeitung findet im Speicher statt, daher müssen die Daten auf der Festplatte in den Speicher geladen werden. Wenn eine Schreib- oder Änderungsanforderung verarbeitet wird, muss auch der Inhalt im Speicher auf der Festplatte aktualisiert werden. Und wir wissen, dass die Geschwindigkeit beim Lesen und Schreiben auf die Festplatte sehr langsam ist, was sich um mehrere Größenordnungen vom Lesen und Schreiben im Speicher unterscheidet. Wenn wir also bestimmte Datensätze aus der Tabelle abrufen möchten, muss die InnoDB-Speicher-Engine lesen die Datensätze einzeln von der Festplatte löschen? Die von InnoDB verwendete Methode besteht darin, die Daten in mehrere Seiten aufzuteilen und Seiten als grundlegende Interaktionseinheit zwischen Festplatte und Speicher zu verwenden. Die Größe einer Seite in InnoDB beträgt im Allgemeinen 16
 Wie man mit einer MySQL-Innodb-Ausnahme umgeht
Apr 17, 2023 pm 09:01 PM
Wie man mit einer MySQL-Innodb-Ausnahme umgeht
Apr 17, 2023 pm 09:01 PM
1. Führen Sie einen Rollback durch und installieren Sie MySQL neu. Um die Probleme beim Importieren dieser Daten von anderen Orten zu vermeiden, erstellen Sie zunächst eine Sicherungskopie der Datenbankdatei der aktuellen Bibliothek (/var/lib/mysql/location). Als nächstes deinstallierte ich das Perconaserver5.7-Paket, installierte das ursprüngliche alte 5.1.71-Paket neu, startete den MySQL-Dienst und er meldete Unknown/unsupportedtabletype:innodb und konnte nicht normal gestartet werden. 11050912:04:27InnoDB:Initializingbufferpool,size=384.0M11050912:04:27InnoDB:Complete
 Vergleich der Auswahl der MySQL-Speicher-Engine: Bewertung des InnoDB-, MyISAM- und Speicherleistungsindex
Jul 26, 2023 am 11:25 AM
Vergleich der Auswahl der MySQL-Speicher-Engine: Bewertung des InnoDB-, MyISAM- und Speicherleistungsindex
Jul 26, 2023 am 11:25 AM
Vergleich der Auswahl der MySQL-Speicher-Engine: Bewertung des InnoDB-, MyISAM- und Speicherleistungsindex Einführung: In der MySQL-Datenbank spielt die Wahl der Speicher-Engine eine entscheidende Rolle für die Systemleistung und Datenintegrität. MySQL bietet eine Vielzahl von Speicher-Engines. Zu den am häufigsten verwendeten Engines gehören InnoDB, MyISAM und Memory. In diesem Artikel werden die Leistungsindikatoren dieser drei Speicher-Engines bewertet und anhand von Codebeispielen verglichen. 1. InnoDB-Engine InnoDB ist mein
 So lösen Sie Phantomlesungen in innoDB in MySQL
May 27, 2023 pm 03:34 PM
So lösen Sie Phantomlesungen in innoDB in MySQL
May 27, 2023 pm 03:34 PM
1. MySQL-Transaktionsisolationsstufe: Bei mehreren Transaktions-Parallelitätskonflikten können einige Probleme wie schmutziges Lesen, nicht wiederholbares Lesen und Phantomlesen auftreten, und innoDB löst sie im wiederholbaren Leseisolationsstufenmodus des Phantom-Lesens, 2. Was ist Phantom-Lesen? Das bedeutet, dass in derselben Transaktion die Ergebnisse, die wir erhalten, wenn wir denselben Bereich vorher und nachher zweimal abfragen, inkonsistent sind, wie in der ersten Transaktion gezeigt Zu diesem Zeitpunkt gibt es nur ein Datenelement, das die Bedingungen erfüllt. In der zweiten Transaktion wird eine Datenzeile eingefügt und bei der ersten Transaktion erneut abgefragt Beachten Sie, dass die ersten und zweiten Abfragen der ersten Transaktion identisch sind
 Erläutern Sie InnoDB Volltext-Suchfunktionen.
Apr 02, 2025 pm 06:09 PM
Erläutern Sie InnoDB Volltext-Suchfunktionen.
Apr 02, 2025 pm 06:09 PM
Die Volltext-Suchfunktionen von InnoDB sind sehr leistungsfähig, was die Effizienz der Datenbankabfrage und die Fähigkeit, große Mengen von Textdaten zu verarbeiten, erheblich verbessern kann. 1) InnoDB implementiert die Volltext-Suche durch invertierte Indexierung und unterstützt grundlegende und erweiterte Suchabfragen. 2) Verwenden Sie die Übereinstimmung und gegen Schlüsselwörter, um den Booleschen Modus und die Phrasesuche zu unterstützen. 3) Die Optimierungsmethoden umfassen die Verwendung der Word -Segmentierungstechnologie, die regelmäßige Wiederaufbauung von Indizes und die Anpassung der Cache -Größe, um die Leistung und Genauigkeit zu verbessern.
 So verwenden Sie MyISAM- und InnoDB-Speicher-Engines, um die MySQL-Leistung zu optimieren
May 11, 2023 pm 06:51 PM
So verwenden Sie MyISAM- und InnoDB-Speicher-Engines, um die MySQL-Leistung zu optimieren
May 11, 2023 pm 06:51 PM
MySQL ist ein weit verbreitetes Datenbankverwaltungssystem und verschiedene Speicher-Engines haben unterschiedliche Auswirkungen auf die Datenbankleistung. MyISAM und InnoDB sind die beiden am häufigsten verwendeten Speicher-Engines in MySQL. Sie haben unterschiedliche Eigenschaften und eine unsachgemäße Verwendung kann die Leistung der Datenbank beeinträchtigen. In diesem Artikel wird erläutert, wie Sie diese beiden Speicher-Engines verwenden, um die MySQL-Leistung zu optimieren. 1. MyISAM-Speicher-Engine MyISAM ist die am häufigsten verwendete Speicher-Engine für MySQL. Ihre Vorteile sind hohe Geschwindigkeit und geringer Speicherplatz. MyISA
 Tipps und Strategien zur Verbesserung der Leseleistung der MySQL-Speicher-Engine: Vergleichende Analyse von MyISAM und InnoDB
Jul 26, 2023 am 10:01 AM
Tipps und Strategien zur Verbesserung der Leseleistung der MySQL-Speicher-Engine: Vergleichende Analyse von MyISAM und InnoDB
Jul 26, 2023 am 10:01 AM
Tipps und Strategien zur Verbesserung der Leseleistung der MySQL-Speicher-Engine: Vergleichende Analyse von MyISAM und InnoDB Einführung: MySQL ist eines der am häufigsten verwendeten relationalen Open-Source-Datenbankverwaltungssysteme, das hauptsächlich zum Speichern und Verwalten großer Mengen strukturierter Daten verwendet wird. In Anwendungen ist die Leseleistung der Datenbank oft sehr wichtig, da Lesevorgänge in den meisten Anwendungen die Hauptoperationsart darstellen. Dieser Artikel konzentriert sich auf die Verbesserung der Leseleistung der MySQL-Speicher-Engine und konzentriert sich auf eine vergleichende Analyse von MyISAM und InnoDB, zwei häufig verwendeten Speicher-Engines.
