

In der Spalte „MySQL-Video-Tutorial“ werden echte Indizes vorgestellt.
Die von der InnoDB-Speicher-Engine nach MySQL5.5 verwendete Indexdatenstruktur verwendet hauptsächlich: B+Tree; in diesem Artikel werden Sie über die Vergangenheit und Gegenwart von B+Tree sprechen 
**Mark**B+Tree kann Indizes für , >=, BETWEEN, IN und LIKE verwenden, die nicht mit einem Platzhalter beginnen. (Nach MySQL 5.5) Diese Fakten können einige Ihrer Wahrnehmungen untergraben, beispielsweise in anderen Artikeln oder Büchern, die Sie gelesen haben. Alle oben genannten sind „Bereichsabfragen“ und werden nicht indiziert! Das stimmt, vor 5.5 hat sich der Optimierer nicht dafür entschieden, den Index zu durchsuchen. Der Optimierer ging davon aus, dass die auf diese Weise abgerufenen Zeilen größer waren als die des vollständigen Tabellenscans, da er zur Tabelle zurückkehren musste Nachschlagen, was E/A erfordern kann. Die Anzahl der Zeilen ist höher und wird vom Optimierer aufgegeben.
Wenn eine Datenspalte viele wiederholte Inhalte enthält, hat die Indizierung keine großen praktischen Auswirkungen. Bei sehr kleinen Tabellen ist in den meisten Fällen ein einfacher vollständiger Tabellenscan effizienterNach der Optimierung des Algorithmus (B+Tree) unterstützt er das Scannen einiger Bereichstypen (unter Ausnutzung der Ordnungsmäßigkeit der B+Tree-Datenstruktur). Dieser Ansatz verstößt auch gegen das Präfixprinzip ganz links, was dazu führt, dass die Bedingung nach der Bereichsabfrage den gemeinsamen Index nicht verwenden kann, was wir später ausführlich erläutern werden. 2. Vor- und Nachteile des Index O in Sequenz-E/A
2. Nachteile
Obwohl der Index die Abfragegeschwindigkeit erheblich verbessert, verringert er auch die Geschwindigkeit der Aktualisierung der Tabelle, z. B. INSERT, UPDATE und DELETE in der Tabelle. Denn beim Aktualisieren der Tabelle muss MySQL nicht nur die Daten, sondern auch die Indexdatei speichern. Das Erstellen von Indexdateien belegt Speicherplatz. Im Allgemeinen ist dieses Problem nicht schwerwiegend. Wenn Sie jedoch mehrere Kombinationsindizes für eine große Tabelle erstellen und eine große Datenmenge einfügen, nimmt die Größe der Indexdatei schnell zu.
Daher sollten nur die am häufigsten abgefragten und am häufigsten sortierten Datenspalten indiziert werden. (Die Gesamtzahl der Indizes in derselben Datentabelle in MySQL ist auf 16 begrenzt)
Und der von Freunden erwähnte Rot-Schwarz-Baum ist eine Speicherstruktur in Programmiersprachen, nicht MySQL. Javas HashMap verwendet beispielsweise eine verknüpfte Liste plus einen Rot-Schwarz-Baum.
Okay, heute werde ich Sie durch den Prozess der Entwicklung zu einem B+-Baum führen.
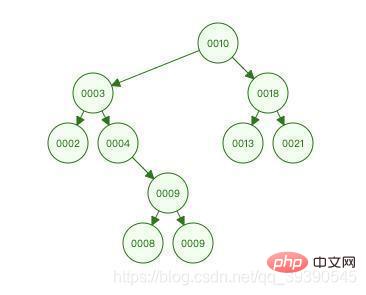 Das Bild oben ist ein binärer Sortierbaum. Sie können versuchen, seine Eigenschaften zu nutzen, um den Prozess des Findens von 9 zu erleben:
Das Bild oben ist ein binärer Sortierbaum. Sie können versuchen, seine Eigenschaften zu nutzen, um den Prozess des Findens von 9 zu erleben:
2. AVL-Baum (selbstausgleichender binärer Suchbaum)
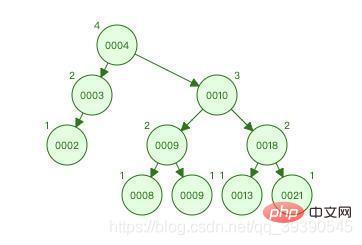 Das Bild oben ist ein AVL-Baum. Die Anzahl und der Wert der Knoten sind genau die gleichen wie beim binären Sortierbaum. Schauen wir uns den Prozess an Finden Sie 9:
Das Bild oben ist ein AVL-Baum. Die Anzahl und der Wert der Knoten sind genau die gleichen wie beim binären Sortierbaum. Schauen wir uns den Prozess an Finden Sie 9:
3. B-Tree (Balanced Tree) Mehrweg-Balanced-Suchbaum
B-Tree ist ein mehrwegiger, selbstausgleichender Suchbaum. Er ähnelt einem gewöhnlichen Binärbaum, jedoch dem B-Baum Ermöglicht jedem Knoten, mehr untergeordnete Knoten zu haben. Das schematische Diagramm des B-Baums sieht wie folgt aus:
Merkmale des B-Baums: 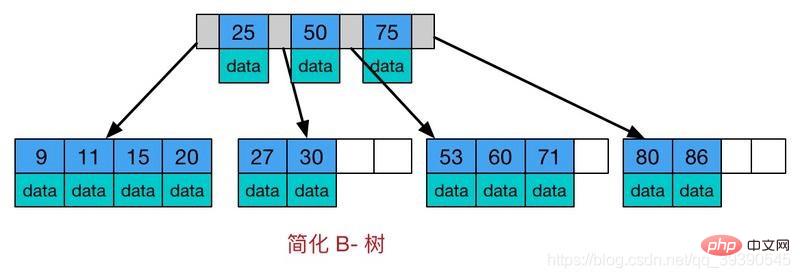
Alle Schlüsselwerte sind im gesamten Baum verteilt.
Jedes Schlüsselwort erscheint und erscheint nur in einem Knoten4. B+-Baum (B+-Baum ist eine Variante des B-Baums und auch ein Mehrweg-Suchbaum)
Sie können auch auf dem Bild sehen, dass der Unterschied zwischen B+-Baum und B-Baum ist: 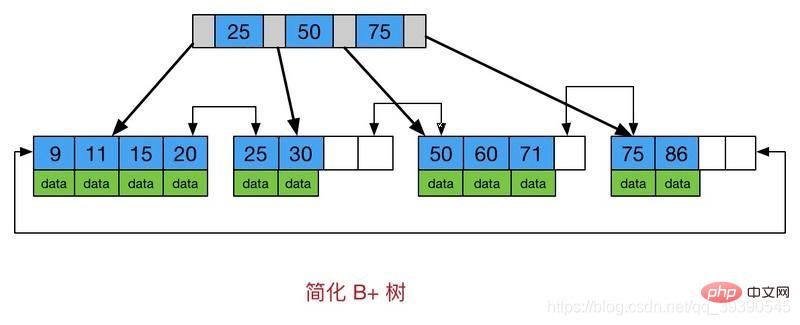 Alle Schlüsselwörter werden in Blattknoten gespeichert. Nicht-Blattknoten speichern keine echten Daten, sodass Blattknoten schnell gefunden werden können.
Alle Schlüsselwörter werden in Blattknoten gespeichert. Nicht-Blattknoten speichern keine echten Daten, sodass Blattknoten schnell gefunden werden können.
Was Sie wissen müssen, ist, dass das System jedes Mal, wenn Sie eine Tabelle erstellen, automatisch eine ID-basierte Tabelle erstellt Clustered-Index für Sie (der oben genannte B+-Baum), speichert alle Daten, jedes Mal, wenn Sie einen Index hinzufügen, erstellt die Datenbank einen zusätzlichen Index (den oben genannten B+-Baum) für Sie Anzahl der in jedem Knoten gespeicherten Datenindizes. Beachten Sie, dass dieser Index nicht alle Daten speichert.
select * from table where name ='陈哈哈' and age = 26; 1复制代码
, da es nur Namen gibt und Alter im zusätzlichen Index, daher muss die Datenbank nach dem Aufrufen des Index zum Clustered-Index zurückkehren, um andere Daten zu finden. Dies ist auch der Grund, warum Sie sich Folgendes gemerkt haben: Verwenden Sie select * less.
2. Indexabdeckung
select name, age from table where name ='陈哈哈' and age = 26; 1复制代码
Zu diesem Zeitpunkt können die ausgewählten Felder name_age_index abgerufen werden. Es besteht also keine Notwendigkeit, zur Tabelle zurückzukehren, was die Indexabdeckung erfüllt und die Daten direkt im Index zurückgibt, was sehr effizient ist. Es ist die bevorzugte Optimierungsmethode für DBA-Studenten bei der Optimierung.
3. Das Präfixprinzip ganz links
Warum lässt uns die Datenbank die Reihenfolge der Felder auswählen? Sind das nicht alle gemeinsame Indizes von drei Feldern? Dies führt zum Prinzip des ganz linken Präfixes von Datenbankindizes. In unserer Entwicklung stoßen wir häufig auf das Problem, dass für dieses Feld ein gemeinsamer Index erstellt wird, der Index jedoch nicht verwendet wird, wenn SQL dieses Feld abfragt. Beispielsweise ist der Index abc_index: (a, b, c) ein gemeinsamer Index der drei Felder a, b, c. Wenn die folgende SQL ausgeführt wird, kann der Index abc_index nicht erreicht werden Lassen Sie den Index verwenden:
select * from table where c = '1'; select * from table where b ='1' and c ='2'; 123复制代码
Haben Sie irgendwelche Hinweise aus den beiden oben genannten Beispielen?
Ja, der Index abc_index: (a,b,c) wird nur in drei Arten von Abfragen verwendet: (a), (a,b) und (a,b,c). Tatsächlich gibt es hier eine gewisse Unklarheit. Tatsächlich wird auch (a,c) verwendet, aber nur der Feldindex a wird verwendet, und das Feld c wird nicht verwendet.
Darüber hinaus gibt es einen Sonderfall: Im folgenden Typ werden nur a und b indiziert, c wird nicht indiziert.
select * from table where a = '1'; select * from table where a = '1' and b = '2'; select * from table where a = '1' and b = '2' and c='3'; 12345复制代码
Bei SQL-Anweisungen des oben genannten Typs ist c nach der Indizierung von a und b bereits außer Betrieb, sodass c nicht indiziert werden kann. Der Optimierer denkt, dass es besser ist, das c-Feld in der gesamten Tabelle zu scannen. schnell.
**Präfix ganz links: Wie der Name schon sagt, bedeutet es Priorität ganz links. Im obigen Beispiel haben wir einen mehrspaltigen Index a_b_c erstellt, was der Erstellung eines einspaltigen Index (a, b) entspricht Index und (a,b, c) Kombinierter Index. ** Daher wird beim Erstellen eines mehrspaltigen Index entsprechend den Geschäftsanforderungen die am häufigsten verwendete Spalte in der where-Klausel ganz links platziert.
4. Index-Pushdown-Optimierung
oder der Index name_age_index, es gibt die folgende SQL
select * from table where a = '1' and b > '2' and c='3'; 1复制代码
Solange die Spalten Nullwerte enthalten, werden sie nicht in den Index aufgenommen Wenn der zusammengesetzte Index einen Nullwert enthält, ist diese Spalte für diesen zusammengesetzten Index ungültig. Daher empfehlen wir, beim Entwurf der Datenbank den Standardwert eines Felds nicht auf Null zu setzen.
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like “%陈%” 不会使用索引而like “陈%”可以使用索引。
这将导致索引失效而进行全表扫描,例如
SELECT * FROM table_name WHERE YEAR(column_name)<h2 data-id="heading-21">6、不使用not in和操作</h2><p>这不属于支持的范围查询条件,不会使用索引。</p><h1 data-id="heading-22">我的体会</h1><p> 曾经,我一度以为我很懂MySQL。</p><p> 刚入职那年,我还是个孩子,记得第一个需求是做个统计接口,查询近两小时每隔5分钟为一时间段的网站访问量,JSONArray中一共返回24个值,当时菜啊,写了个接口循环二十四遍,发送24条SQL去查(捂脸),由于那个接口,被技术经理嘲讽~~表示他写的SQL比我吃的米都多。虽然我们山东人基本不吃米饭,但我还是羞愧不已。。<br>然后经理通过调用一个dateTime函数分组查询处理一下,就ok了,效率是我的几十倍吧。从那时起,我就定下目标,深入MySQL学习,万一日后有机会嘲讽回去?</p><p> 筒子们,MySQL路漫漫,其修远兮。永远不要眼高手低,一起加油,希望本文能对你有所帮助。</p>
Das obige ist der detaillierte Inhalt vonWeinen ... ich dachte, ich kenne MySQL-Indizes gut. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL-Index
MySQL-Index
 Vier Hauptmerkmale der Blockchain
Vier Hauptmerkmale der Blockchain
 So legen Sie Startelemente beim Start fest
So legen Sie Startelemente beim Start fest
 Lösung für Java-Erfolg und Javac-Fehler
Lösung für Java-Erfolg und Javac-Fehler
 Wo ist der Prtscrn-Button?
Wo ist der Prtscrn-Button?
 Einführung in die Repeater-Verschachtelungsmethode
Einführung in die Repeater-Verschachtelungsmethode
 So lösen Sie „Keine Route zum Host'.
So lösen Sie „Keine Route zum Host'.
 Verwendung von indexof in Java
Verwendung von indexof in Java
 So konfigurieren Sie die Pycharm-Umgebung
So konfigurieren Sie die Pycharm-Umgebung










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



