

Erfahren Sie mehr über JavaScript-Caching

Da unsere Anwendungen weiter wachsen und komplexe Berechnungen durchführen, wird der Bedarf an Geschwindigkeit immer höher, sodass die Optimierung des Prozesses unerlässlich wird. Wenn wir dieses Problem ignorieren, erhalten wir am Ende ein Programm, das während der Ausführung viel Zeit in Anspruch nimmt und viele Systemressourcen verbraucht.
Empfohlenes Tutorial: „JavaScript-Video-Tutorial“
Caching ist eine Optimierungstechnik, die die Anwendung beschleunigt, indem sie die Ergebnisse teurer Funktionsausführungen speichert und die zwischengespeicherten Ergebnisse zurückgibt, wenn die gleiche Eingabegeschwindigkeit erneut auftritt.
Wenn Ihnen das nicht viel bedeutet, ist das in Ordnung. In diesem Artikel wird ausführlich erläutert, warum Caching notwendig ist, was Caching ist, wie es implementiert wird und wann Sie Caching verwenden sollten.
Was ist Caching?
Caching ist eine Optimierungstechnik, die eine Anwendung beschleunigt, indem sie die Ergebnisse teurer Funktionsausführungen speichert und die zwischengespeicherten Ergebnisse zurückgibt, wenn dieselbe Eingabe erneut erfolgt.
An diesem Punkt ist uns klar, dass der Zweck des Cachings darin besteht, den Zeit- und Ressourcenaufwand für die Durchführung „teurer Funktionsaufrufe“ zu reduzieren.
Was sind teure Funktionsaufrufe Lassen Sie sich nicht verwirren, wir geben hier kein Geld aus. Im Zusammenhang mit Computerprogrammen sind die beiden wichtigsten Ressourcen, über die wir verfügen, Zeit und Gedächtnis. Daher bezieht sich ein teurer Funktionsaufruf auf einen Funktionsaufruf, der aufgrund des großen Rechenaufwands während der Ausführung viele Computerressourcen und Zeit in Anspruch nimmt.
Aber genau wie beim Geld müssen wir sparen. Zu diesem Zweck werden Caches verwendet, um die Ergebnisse von Funktionsaufrufen zu speichern, damit sie zu einem späteren Zeitpunkt schnell und einfach darauf zugreifen können.
Ein Cache ist einfach ein temporärer Datenspeicher, der Daten speichert, damit zukünftige Anfragen nach diesen Daten schneller verarbeitet werden können.
Wenn also eine teure Funktion einmal aufgerufen wird, wird das Ergebnis im Cache gespeichert, sodass bei jedem erneuten Aufruf der Funktion in der Anwendung das Ergebnis sehr schnell aus dem Cache abgerufen wird, ohne dass Berechnungen erneut durchgeführt werden müssen.
Warum ist Caching wichtig?
Hier ist ein Beispiel, das die Bedeutung von Caching verdeutlicht:
Stellen Sie sich vor, Sie lesen im Park einen neuen Roman mit einem attraktiven Cover. Jedes Mal, wenn eine Person vorbeikommt, wird sie vom Cover angezogen und fragt nach dem Titel und dem Autor. Wenn Ihnen diese Frage zum ersten Mal gestellt wird, schlagen Sie das Buch auf und lesen den Titel und den Namen des Autors. Jetzt kommen immer mehr Leute hierher und stellen die gleiche Frage. Du bist ein sehr netter Mensch und beantwortest alle Fragen.
Würden Sie das Cover umdrehen und ihm nacheinander den Titel des Buches und den Namen des Autors nennen, oder würden Sie anfangen, aus dem Gedächtnis zu antworten?
Sind Ihnen die Ähnlichkeiten aufgefallen? Wenn einer Funktion Eingaben bereitgestellt werden, führt sie die erforderlichen Berechnungen durch und speichert die Ergebnisse im Cache, bevor sie den Wert zurückgibt. Wenn in Zukunft die gleiche Eingabe eingeht, muss sie nicht immer wieder wiederholt werden, sondern muss lediglich die Antwort aus dem Cache (Speicher) bereitstellen. So funktioniert Caching
Ein Abschluss ist eine Kombination aus einer Funktion und der lexikalischen Umgebung, in der die Funktion deklariert wird.Nicht ganz klar? Das denke ich auch. Zum besseren Verständnis wollen wir uns kurz mit dem Konzept des lexikalischen Bereichs in JavaScript befassen. Der lexikalische Bereich bezieht sich einfach auf die physische Position von Variablen und Blöcken, die vom Programmierer beim Schreiben von Code angegeben werden. Der folgende Code:
function foo(a) {
var b = a + 2;
function bar(c) {
console.log(a, b, c);
}
bar(b * 2);
}
foo(3); // 3, 5, 10- Globaler Bereich (enthält
-
fooBereich , der die Bezeichnera,bundbarhat -
barBereich, derc enthält code>-Bezeichner
foo als eindeutige Kennung) Wenn wir den obigen Code genau betrachten, stellen wir fest, dass die Funktion foo Zugriff auf die Variablen a und b hat, da sie in foo verschachtelt ist. Beachten Sie, dass wir die Funktion bar und ihre Ausführungsumgebung erfolgreich gespeichert haben. Daher sagen wir, dass bar einen Abschluss für den Gültigkeitsbereich von foo hat.
Sie können dies im Kontext der Genetik verstehen, wo Individuen die Möglichkeit haben, genetische Merkmale auch außerhalb ihrer aktuellen Umgebung zu erwerben und auszudrücken. Diese Logik hebt ein weiteres Element der Schließung hervor und führt uns zu zwei Hauptkonzepten.
Funktionen von Funktionen zurückgeben
Funktionen, die andere Funktionen als Argumente akzeptieren oder andere Funktionen zurückgeben, werden als Funktionen höherer Ordnung bezeichnet. Abschlüsse ermöglichen es uns, innere Funktionen außerhalb der einschließenden Funktion aufzurufen und gleichzeitig den Zugriff auf den lexikalischen Bereich der einschließenden Funktion aufrechtzuerhalten.- Nehmen wir einige Anpassungen am Code im vorherigen Beispiel vor, um dies zu berücksichtigen.
foo作为唯一标识符) -
foo作用域,它有标识符a、b和bar -
bar作用域,包含c标识符
仔细查看上面的代码,我们注意到函数 foo 可以访问变量 a 和 b,因为它嵌套在 foo 中。注意,我们成功地存储了函数 bar 及其运行环境。因此,我们说 bar 在 foo
function foo(){
var a = 2;
function bar() {
console.log(a);
}
return bar;
}
var baz = foo();
baz();//2注意函数 foo 如何返回另一个函数 bar。这里我们执行函数 foo 并将返回值赋给baz。但是在本例中,我们有一个返回函数,因此,baz 现在持有对 foo 中定义的bar 函数的引用。
最有趣的是,当我们在 foo 的词法作用域之外执行函数 baz 时,仍然会得到 a 的值,这怎么可能呢?
请记住,由于闭包的存在,bar 总是可以访问 foo 中的变量(继承的特性),即使它是在 foo 的作用域之外执行的。
案例研究:斐波那契数列
斐波那契数列是什么?
斐波那契数列是一组数字,以1 或 0 开头,后面跟着1,然后根据每个数字等于前两个数字之和规则进行。如
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
或者
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
挑战:编写一个函数返回斐波那契数列中的 n 元素,其中的序列是:
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …]
知道每个值都是前两个值的和,这个问题的递归解是:
function fibonacci(n) {
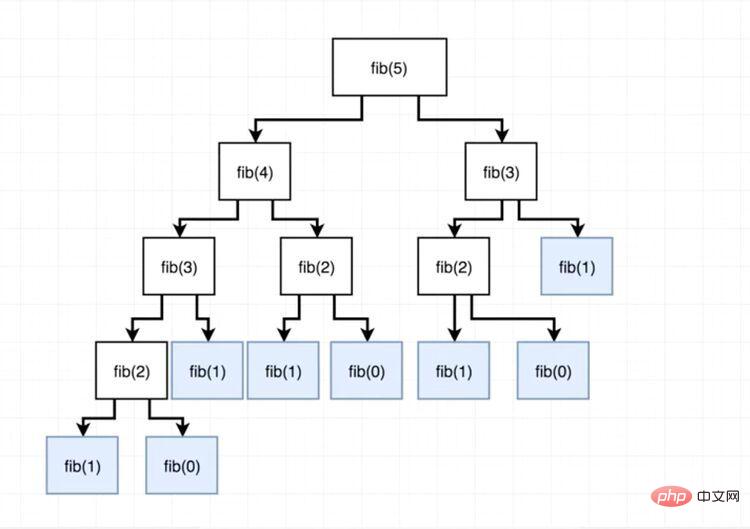
if (n <p>确实简洁准确!但是,有一个问题。请注意,当 <code>n</code> 的值到终止递归之前,需要做大量的工作和时间,因为序列中存在对某些值的重复求值。</p><p>看看下面的图表,当我们试图计算 <code>fib(5)</code>时,我们注意到我们反复地尝试在不同分支的下标 <code>0,1,2,3</code> 处找到 Fibonacci 数,这就是所谓的冗余计算,而这正是缓存所要消除的。</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/image/136/162/211/1604656285576117.jpg" class="lazy" title="1604656285576117.jpg" alt="Erfahren Sie mehr über JavaScript-Caching"></p><pre class="brush:php;toolbar:false">function fibonacci(n, memo) {
memo = memo || {}
if (memo[n]) {
return memo[n]
}
if (n <p>在上面的代码片段中,我们调整函数以接受一个可选参数 <code>memo</code>。我们使用 <code>memo</code> 对象作为缓存来存储斐波那契数列,并将其各自的索引作为键,以便在执行过程中稍后需要时检索它们。</p><pre class="brush:php;toolbar:false">memo = memo || {}在这里,检查是否在调用函数时将 memo 作为参数接收。如果有,则初始化它以供使用;如果没有,则将其设置为空对象。
if (memo[n]) {
return memo[n]
}接下来,检查当前键 n 是否有缓存值,如果有,则返回其值。
和之前的解一样,我们指定了 n 小于等于 1 时的终止递归。
最后,我们递归地调用n值较小的函数,同时将缓存值(memo)传递给每个函数,以便在计算期间使用。这确保了在以前计算并缓存值时,我们不会第二次执行如此昂贵的计算。我们只是从 memo 中取回值。
注意,我们在返回缓存之前将最终结果添加到缓存中。
使用 JSPerf 测试性能
可以使用些链接来性能测试。在那里,我们运行一个测试来评估使用这两种方法执行fibonacci(20) 所需的时间。结果如下:

哇! ! !这让人很惊讶,使用缓存的 fibonacci 函数是最快的。然而,这一数字相当惊人。它执行 126,762 ops/sec,这远远大于执行 1,751 ops/sec 的纯递归解决方案,并且比较没有缓存的递归速度大约快 99%。
注:“ops/sec”表示每秒的操作次数,就是一秒钟内预计要执行的测试次数。
现在我们已经看到了缓存在函数级别上对应用程序的性能有多大的影响。这是否意味着对于应用程序中的每个昂贵函数,我们都必须创建一个修改后的变量来维护内部缓存?
不,回想一下,我们通过从函数返回函数来了解到,即使在外部执行它们,它们也会导致它们继承父函数的范围,这使得可以将某些特征和属性从封闭函数传递到返回的函数。
使用函数的方式
在下面的代码片段中,我们创建了一个高阶的函数 memoizer。有了这个函数,将能够轻松地将缓存应用到任何函数。
function memoizer(fun) {
let cache = {}
return function (n) {
if (cache[n] != undefined) {
return cache[n]
} else {
let result = fun(n)
cache[n] = result
return result
}
}
}上面,我们简单地创建一个名为 memoizer 的新函数,它接受将函数 fun 作为参数进行缓存。在函数中,我们创建一个缓存对象来存储函数执行的结果,以便将来使用。
从 memoizer 函数中,我们返回一个新函数,根据上面讨论的闭包原则,这个函数无论在哪里执行都可以访问 cache。
在返回的函数中,我们使用 if..else 语句检查是否已经有指定键(参数) n 的缓存值。如果有,则取出并返回它。如果没有,我们使用函数来计算结果,以便缓存。然后,我们使用适当的键 n 将结果添加到缓存中,以便以后可以从那里访问它。最后,我们返回了计算结果。
很顺利!
要将 memoizer 函数应用于最初递归的 fibonacci 函数,我们调用 memoizer 函数,将 fibonacci 函数作为参数传递进去。
const fibonacciMemoFunction = memoizer(fibonacciRecursive)
测试 memoizer 函数
当我们将 memoizer 函数与上面的例子进行比较时,结果如下:
memoizer 函数以 42,982,762 ops/sec 的速度提供了最快的解决方案,比之前考虑的解决方案速度要快 100%。
关于缓存,我们已经说明什么是缓存 、为什么要有缓存和如何实现缓存。现在我们来看看什么时候使用缓存。
何时使用缓存
当然,使用缓存效率是级高的,你现在可能想要缓存所有的函数,这可能会变得非常无益。以下几种情况下,适合使用缓存:
- 对于昂贵的函数调用,执行复杂计算的函数。
- 对于具有有限且高度重复输入范围的函数。
- 用于具有重复输入值的递归函数。
- 对于纯函数,即每次使用特定输入调用时返回相同输出的函数。
缓存库
总结
使用缓存方法 ,我们可以防止函数调用函数来反复计算相同的结果,现在是你把这些知识付诸实践的时候了。
更多编程相关知识,请访问:编程入门!!
Das obige ist der detaillierte Inhalt vonErfahren Sie mehr über JavaScript-Caching. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Wo werden Videodateien im Browser-Cache gespeichert?
Feb 19, 2024 pm 05:09 PM
Wo werden Videodateien im Browser-Cache gespeichert?
Feb 19, 2024 pm 05:09 PM
In welchem Ordner speichert der Browser das Video? Wenn wir den Internetbrowser täglich nutzen, schauen wir uns häufig verschiedene Online-Videos an, z. B. Musikvideos auf YouTube oder Filme auf Netflix. Diese Videos werden während des Ladevorgangs vom Browser zwischengespeichert, sodass sie bei späterer erneuter Wiedergabe schnell geladen werden können. Die Frage ist also: In welchem Ordner werden diese zwischengespeicherten Videos tatsächlich gespeichert? Verschiedene Browser speichern zwischengespeicherte Videoordner an unterschiedlichen Orten. Im Folgenden stellen wir einige gängige Browser und deren Funktionen vor
 So zeigen Sie den DNS-Cache unter Linux an und aktualisieren ihn
Mar 07, 2024 am 08:43 AM
So zeigen Sie den DNS-Cache unter Linux an und aktualisieren ihn
Mar 07, 2024 am 08:43 AM
DNS (DomainNameSystem) ist ein System, das im Internet verwendet wird, um Domänennamen in entsprechende IP-Adressen umzuwandeln. In Linux-Systemen ist DNS-Caching ein Mechanismus, der die Zuordnungsbeziehung zwischen Domänennamen und IP-Adressen lokal speichert, was die Geschwindigkeit der Domänennamenauflösung erhöhen und die Belastung des DNS-Servers verringern kann. DNS-Caching ermöglicht es dem System, die IP-Adresse schnell abzurufen, wenn es anschließend auf denselben Domänennamen zugreift, ohne jedes Mal eine Abfrageanforderung an den DNS-Server senden zu müssen, wodurch die Netzwerkleistung und -effizienz verbessert wird. In diesem Artikel erfahren Sie, wie Sie den DNS-Cache unter Linux anzeigen und aktualisieren, sowie zugehörige Details und Beispielcode. Bedeutung des DNS-Cachings In Linux-Systemen spielt das DNS-Caching eine Schlüsselrolle. seine Existenz
 Beschleunigen Sie Ihre Anwendungen: Eine einfache Anleitung zum Guava-Caching
Jan 31, 2024 pm 09:11 PM
Beschleunigen Sie Ihre Anwendungen: Eine einfache Anleitung zum Guava-Caching
Jan 31, 2024 pm 09:11 PM
Erste Schritte mit Guava Cache: Beschleunigen Sie Ihre Anwendungen. Guava Cache ist eine leistungsstarke In-Memory-Caching-Bibliothek, die die Anwendungsleistung erheblich verbessern kann. Es bietet eine Vielzahl von Caching-Strategien, darunter LRU (zuletzt verwendet), LFU (zuletzt verwendet) und TTL (Lebensdauer). 1. Installieren Sie den Guava-Cache und fügen Sie Ihrem Projekt die Abhängigkeit der Guava-Cache-Bibliothek hinzu. com.goog
 Werden HTML-Dateien zwischengespeichert?
Feb 19, 2024 pm 01:51 PM
Werden HTML-Dateien zwischengespeichert?
Feb 19, 2024 pm 01:51 PM
Titel: Caching-Mechanismus und Codebeispiele für HTML-Dateien. Einführung: Beim Schreiben von Webseiten stoßen wir häufig auf Probleme mit dem Browser-Cache. In diesem Artikel wird der Caching-Mechanismus von HTML-Dateien ausführlich vorgestellt und einige spezifische Codebeispiele bereitgestellt, um den Lesern zu helfen, diesen Mechanismus besser zu verstehen und anzuwenden. 1. Browser-Caching-Prinzip Im Browser prüft der Browser bei jedem Zugriff auf eine Webseite zunächst, ob sich eine Kopie der Webseite im Cache befindet. Wenn dies der Fall ist, wird der Inhalt der Webseite direkt aus dem Cache abgerufen. Dies ist das Grundprinzip des Browser-Caching. Vorteile des Browser-Caching-Mechanismus
 Erweiterte Verwendung von PHP APCu: Die verborgene Kraft freisetzen
Mar 01, 2024 pm 09:10 PM
Erweiterte Verwendung von PHP APCu: Die verborgene Kraft freisetzen
Mar 01, 2024 pm 09:10 PM
PHPAPCu (Ersatz für PHP-Cache) ist ein Opcode-Cache- und Daten-Cache-Modul, das PHP-Anwendungen beschleunigt. Das Verständnis seiner erweiterten Funktionen ist entscheidend, um sein volles Potenzial auszuschöpfen. 1. Batch-Betrieb: APCu bietet eine Batch-Betriebsmethode, mit der eine große Anzahl von Schlüssel-Wert-Paaren gleichzeitig verarbeitet werden kann. Dies ist nützlich für umfangreiche Cache-Löschvorgänge oder Aktualisierungen. //Cache-Schlüssel stapelweise abrufen $values=apcu_fetch(["key1","key2","key3"]); //Cache-Schlüssel stapelweise löschen apcu_delete(["key1","key2","key3"]) ;2 .Cache-Ablaufzeit festlegen: Mit APCu können Sie eine Ablaufzeit für Cache-Elemente festlegen, sodass diese nach einer bestimmten Zeit automatisch ablaufen.
 So speichern Sie Videodateien aus dem Browser-Cache lokal
Feb 23, 2024 pm 06:45 PM
So speichern Sie Videodateien aus dem Browser-Cache lokal
Feb 23, 2024 pm 06:45 PM
So exportieren Sie Browser-Cache-Videos Mit der rasanten Entwicklung des Internets sind Videos zu einem unverzichtbaren Bestandteil des täglichen Lebens der Menschen geworden. Beim Surfen im Internet stoßen wir oft auf Videoinhalte, die wir speichern oder teilen möchten, aber manchmal können wir die Quelle der Videodateien nicht finden, weil sie möglicherweise nur im Cache des Browsers vorhanden sind. Wie exportieren Sie also Videos aus Ihrem Browser-Cache? In diesem Artikel werden Ihnen mehrere gängige Methoden vorgestellt. Zunächst müssen wir ein Konzept klären, nämlich den Browser-Cache. Der Browser-Cache wird vom Browser verwendet, um die Benutzererfahrung zu verbessern.
 Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
In der PHP-Entwicklung verbessert der Caching-Mechanismus die Leistung, indem er häufig aufgerufene Daten vorübergehend im Speicher oder auf der Festplatte speichert und so die Anzahl der Datenbankzugriffe reduziert. Zu den Cache-Typen gehören hauptsächlich Speicher-, Datei- und Datenbank-Cache. In PHP können Sie integrierte Funktionen oder Bibliotheken von Drittanbietern verwenden, um Caching zu implementieren, wie zum Beispiel Cache_get() und Memcache. Zu den gängigen praktischen Anwendungen gehören das Zwischenspeichern von Datenbankabfrageergebnissen zur Optimierung der Abfrageleistung und das Zwischenspeichern von Seitenausgaben zur Beschleunigung des Renderings. Der Caching-Mechanismus verbessert effektiv die Reaktionsgeschwindigkeit der Website, verbessert das Benutzererlebnis und reduziert die Serverlast.
 Ein tiefer Einblick in die PHP-Caching-Technologie: Der Schlüssel zur Beschleunigung der Website-Leistung
Jan 23, 2024 am 08:37 AM
Ein tiefer Einblick in die PHP-Caching-Technologie: Der Schlüssel zur Beschleunigung der Website-Leistung
Jan 23, 2024 am 08:37 AM
Erkundung der PHP-Caching-Technologie: ein leistungsstarkes Tool zur Verbesserung der Website-Leistung, spezifische Codebeispiele sind erforderlich. Einführung: Angesichts der rasanten Entwicklung des heutigen Internets ist die Website-Leistung von entscheidender Bedeutung für das Benutzererlebnis und das Suchmaschinen-Ranking. Als häufig verwendete Programmiersprache wird PHP häufig in der Website-Entwicklung eingesetzt. Wie die Leistung von PHP-Websites verbessert werden kann, ist für Entwickler zu einem dringenden Problem geworden. Eine der sehr wichtigen Lösungen ist die Verwendung der PHP-Caching-Technologie. In diesem Artikel werden das Konzept und die spezifische Technologie des PHP-Caching untersucht und Codebeispiele bereitgestellt, um den Lesern das Verständnis zu erleichtern
