

In der Kolumne

Ich habe schon lange keinen Artikel mehr geschrieben, ich habe mehr als ein halbes Jahr geschwiegen
Anhaltendes Unwohlsein, intermittierende epileptische Anfälle
Ich besuche meinen Onkel jeden Tag und verbringe jeden Tag in Verwirrung und Angst
Ich muss es zugeben, tatsächlich bin ich eine Verschwendung
Als Front-End-Ingenieur auf niedrigem Niveau
Ich habe mich kürzlich mit einer alten Schnittstelle meiner Vorfahren befasst, die seit mehr als zehn Jahren weitergegeben wird Jahre
Es hat die gesamte höchste Komplexitätslogik geerbt
Man sagt, dass ein Aufruf dazu führen kann, dass die CPU-Auslastung um 90 % pro Tag steigt.
Spezialisiert auf die Behandlung verschiedener Unzufriedenheiten und der Alzheimer-Krankheit
Lassen Sie uns schätzen, wie zeitaufwändig diese Schnittstelle ist ist
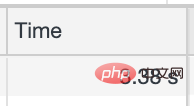
Die durchschnittliche Anrufzeit beträgt mehr als 3 Sekunden
Dies führt zu einer ernsthaften Seitenumleitung
Nach verschiedenen eingehenden Analysen dieser Art und Fragen und Antworten mit Fachleuten
Die endgültige Schlussfolgerung lautet: Geben Sie die medizinische Behandlung auf
Lu Xun sagte einmal in „Tagebuch eines Verrückten“: „Die einzigen Dinge, die mich besiegen können, sind Frauen und Alkohol, nicht Insekten“ Sehen Sie das Licht能打败我的,只有女人和酒精,而不是bug”
每当身处黑暗之时
这句话总能让我看到光
所以这次要硬起来
我决定做一个node代理层
用下面三个方法进行优化:
按需加载 -> graphQL
数据缓存 -> redis
轮询更新 -> schedule
代码地址:github
天秀老接口存在一个问题,我们每次请求1000条数据,返回的数组中,每一条数据都有上百个字段,其实我们前端只用到其中的10个字段而已。
如何从一百多个字段中,抽取任意n个字段,这就用到graphQL。
graphQL按需加载数据只需要三步:
我们针对屌丝追求女神的场景,定义一个数据池,如下:
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }]
},
{ id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }]
}]
}复制代码里面有两个女神的所有信息,包括女神的名字、手机、微信、身高、学校、备胎集合等信息。
接下来我们就要对这些数据结构进行描述。
const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(`
type Wheel {
name: String,
money: String
}
type Info {
id: Int
name: String
iphone: Int
weixin: String
height: Int
school: String
wheel: [Wheel]
}
type Query {
girls: [Info]
}
`);复制代码上面这段代码就是女神信息的schema。
首先我们用type Query定义了一个对女神信息的查询,里面包含了很多女孩girls的信息Info,这些信息是一堆数组,所以是[Info]
我们在type Info
Laden bei Bedarf -> graphQL
Daten-Caching->Polling-Update-> code><img class="lazyload lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/f39da530744af5475a629c8f3c5aa0ae-2.png" alt="" data- style="max-width:90%" data- style="max-width:90%">
Tianxiu Every Wenn wir 1000 Datenelemente anfordern, enthält jedes Datenelement im zurückgegebenen Array Hunderte von Feldern. Tatsächlich verwendet unser Frontend nur 10 davon.
So extrahieren Sie beliebige n Felder aus mehr als hundert Feldern mithilfe von graphQL. 
Wir definieren einen Datenpool für die Szene, in der die Diaosi die Göttin verfolgen, wie folgt:
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
weixin
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码It enthält alle Informationen der beiden Göttinnen, einschließlich des Namens der Göttin, Mobiltelefon, WeChat, Größe, Schule, Ersatzreifensammlung und andere Informationen.
Als nächstes beschreiben wir diese Datenstrukturen.
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
wheel {
money
}
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码type Query, um eine Abfrage nach Göttinneninformationen zu definieren, die viele Informationen über Mädchen Info enthält. Diese Informationen sind also eine Reihe von Arrays [Info]Wir beschreiben die Dimensionen aller Informationen über ein Mädchen im Typ Info, einschließlich Name, Mobiltelefon (iPhone), WeChat (weixin), Größe, Schule , Ersatzreifensatz (Rad)Abfrageregeln definierenNachdem Sie die Informationsbeschreibung (Schema) der Göttin erhalten haben, können Sie die Kombination verschiedener von der Göttin erhaltener Informationen anpassen. Wenn ich zum Beispiel eine Göttin kennenlernen möchte, brauche ich nur ihren Namen und Weixin. Der Abfrageregelcode lautet wie folgt:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码Die Filterergebnisse lauten wie folgt:
🎜🎜🎜🎜Wir verwenden das Beispiel der Göttin, um zu zeigen, wie Daten bei Bedarf über graphQL geladen werden. 🎜🎜Abgebildet auf das spezifische Szenario unseres Unternehmens enthält jedes von der Tianxiu-Schnittstelle zurückgegebene Datenelement 100 Felder. Wir konfigurieren das Schema so, dass 10 der Felder abgerufen werden, wodurch die Übertragung der verbleibenden 90 unnötigen Felder vermieden wird. 🎜🎜Ein weiterer Vorteil von graphQL besteht darin, dass es flexibel konfiguriert werden kann. Diese Schnittstelle erfordert 10 Felder, eine andere Schnittstelle erfordert 5 Felder und die n-te Schnittstelle erfordert weitere x Felder. 🎜🎜Nach dem traditionellen Ansatz müssen wir nur n Schnittstellen erstellen Die Schnittstelle muss mit unterschiedlichen Schemata konfiguriert werden, um allen Situationen gerecht zu werden. 🎜🎜Inspiration🎜🎜Im Leben fehlt uns Leckerbissen wirklich die Idee, graphQL auf Abruf zu laden🎜🎜Dreckskerle und Dreckskerle, jeder bekommt, was er braucht🎜🎜Deine wahren Gefühle sind vor Prominenten nicht der Rede wert🎜🎜 Wir müssen lernen, ob es Ihnen gefällt🎜🎜zeigen Sie Ihre Autoschlüssel, wenn Sie herkommen, und zeigen Sie Ihre Talente, wenn Sie kein Auto haben🎜🎜Heute Abend habe ich ein Ahnenchromosom, das ich mit Ihnen teilen möchte🎜🎜Wenn ja Funktioniert, ändern Sie es einfach. Wenn nicht, ändern Sie es einfach in das nächste. 🎜🎜Gehen Sie direkt zum Thema, einfach und grob: 🎜🎜Cache->天秀老接口内部调用了另外三个老接口,而且是串行调用,极其耗时耗资源,秀到你头皮发麻
我们用redis来缓存天秀接口的聚合数据,下次再调用天秀接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码先通过getAsync来读取redis缓存中的数据,如果有数据,直接返回,绕过接口调用,如果没有数据,就会调用天秀接口,然后setAsync更新到缓存中,以便下次调用。因为redis存储的是字符串,所以在设置缓存的时候,需要加上JSON.stringify(data),为了便于大家理解,我就不加了,会把具体细节代码放在github中。
将数据放在redis缓存里有几个好处
可以实现多接口复用、多机共享缓存
这就是传说中的云备胎
追求一个女神的成功率是1%
同时追求100个女神,那你获取到一个女神的概率就是100%
鲁迅《狂人日记》里曾说过:“舔一个是舔狗,舔一百个你就是战狼”
你是想当舔狗还是当战狼?
来吧,缓存用起来,redis用起来
最后一个优化手段:轮询更新 -> schedule
女神的备胎用久了,会定时换一批备胎,让新鲜血液进来,发现新的快乐
缓存也一样,需要定时更新,保持与数据源的一致性,代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码天秀接口不是一个强实时性接口,数据源一周可能才会变一次
所以我们根据实际情况用轮询来设置更新缓存频率
我们用node-schedule这个库来轮询更新缓存,* * 0 * * *这个的意思就是设置每个小时的第0分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中,这样其他接口和机器在调用缓存的时候,就能获取到最新数据,这就是共享缓存和轮询更新的好处。
早年我在当舔狗的时候,就将轮询机制发挥到淋漓尽致
每天向白名单里的女神,定时轮询发消息
无限循环云跪舔三件套:
虽然女神依然看不上我
但仍然时刻准备着为女神服务
经过以上三个方法优化后
接口请求耗时从3s降到了860ms
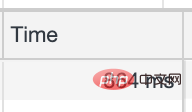
这些代码都是从业务中简化后的逻辑
真实的业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等
每一个模块都晦涩难懂
就好像每一个女神都高不可攀
屌丝战胜了所有bug,唯独战胜不了她的心
受伤了只能在深夜里独自买醉
但每当梦到女神打开我做的页面
被极致流畅的体验惊艳到
在精神高潮中享受灵魂升华
那一刻
我觉得我又行了
(完)
相关免费学习推荐:JavaScript(视频)
Das obige ist der detaillierte Inhalt vonOptimierungstipps! ! Front-End-Rookie beschleunigt Schnittstelle um 60 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



