
 Java
JavaBase
Verstehen Sie Java-Protokollebenen, doppelte Aufzeichnungen und Probleme mit Protokollverlusten
Java
JavaBase
Verstehen Sie Java-Protokollebenen, doppelte Aufzeichnungen und Probleme mit Protokollverlusten
Verstehen Sie Java-Protokollebenen, doppelte Aufzeichnungen und Probleme mit Protokollverlusten

Java Basic TutorialDie Kolumne stellt vor, wie man die Java-Protokollebene und andere Probleme löst

Verwandte kostenlose Lernempfehlungen: Java Basic Tutorial
1 Häufige Ursachen für Protokollfehler
1.1 Es gibt viele Protokollierungsfehler Frameworks
Verschiedene Klassenbibliotheken können verwendet werden, und die Kompatibilität ist ein Problem
1.2 Die Konfiguration ist komplex und fehleranfällig
Protokollkonfigurationsdateien sind normalerweise sehr kompliziert, Konfigurationsdateien direkt von anderen zu kopieren Projekte oder Online-Blogs, studieren Sie jedoch nicht sorgfältig, wie Sie diese ändern können. Häufige Fehler treten bei der doppelten Protokollierung, der Leistung der synchronen Protokollierung und einer Fehlkonfiguration der asynchronen Protokollierung auf.
1.3 Es gibt einige Missverständnisse bei der Protokollierung selbst
Zum Beispiel die Nichtberücksichtigung der Kosten für den Erhalt des Protokollinhalts, die zufällige Verwendung von Protokollebenen usw.
2 SLF4J
Logback, Log4j, Log4j2, Commons-Logging, java.util.logging, das mit JDK geliefert wird usw. sind alles Protokoll-Frameworks des Java-Systems, und es gibt tatsächlich viele davon. Verschiedene Klassenbibliotheken können sich auch für die Verwendung unterschiedlicher Protokollierungsframeworks entscheiden. Dadurch wird eine einheitliche Verwaltung der Protokolle sehr schwierig.
- SLF4J (Simple Logging Facade For Java) bietet eine einheitliche Protokollierungsfassaden-API, um dieses Problem zu lösen. Dies ist der violette Teil im Bild. Außerdem wird eine neutrale Protokollierungs-API implementiert Blauer Teil, Brücke verschiedener Log-Framework-APIs (grüner Teil) zur SLF4J-API. Selbst wenn Sie verschiedene Protokollierungs-APIs zum Aufzeichnen von Protokollen in Ihrem Programm verwenden, können Sie auf diese Weise letztendlich eine Brücke zur SLF4J-Fassaden-API schlagen.
Handelt es sich bei SLF4J nur um einen Protokollierungsstandard, ist dafür noch ein tatsächliches Protokollierungs-Framework erforderlich? Das Protokollierungsframework selbst implementiert die SLF4J-API nicht, daher ist eine Vorkonvertierung erforderlich. Logback wird gemäß dem SLF4J-API-Standard implementiert, sodass keine Module für die Konvertierung gebunden werden müssen. 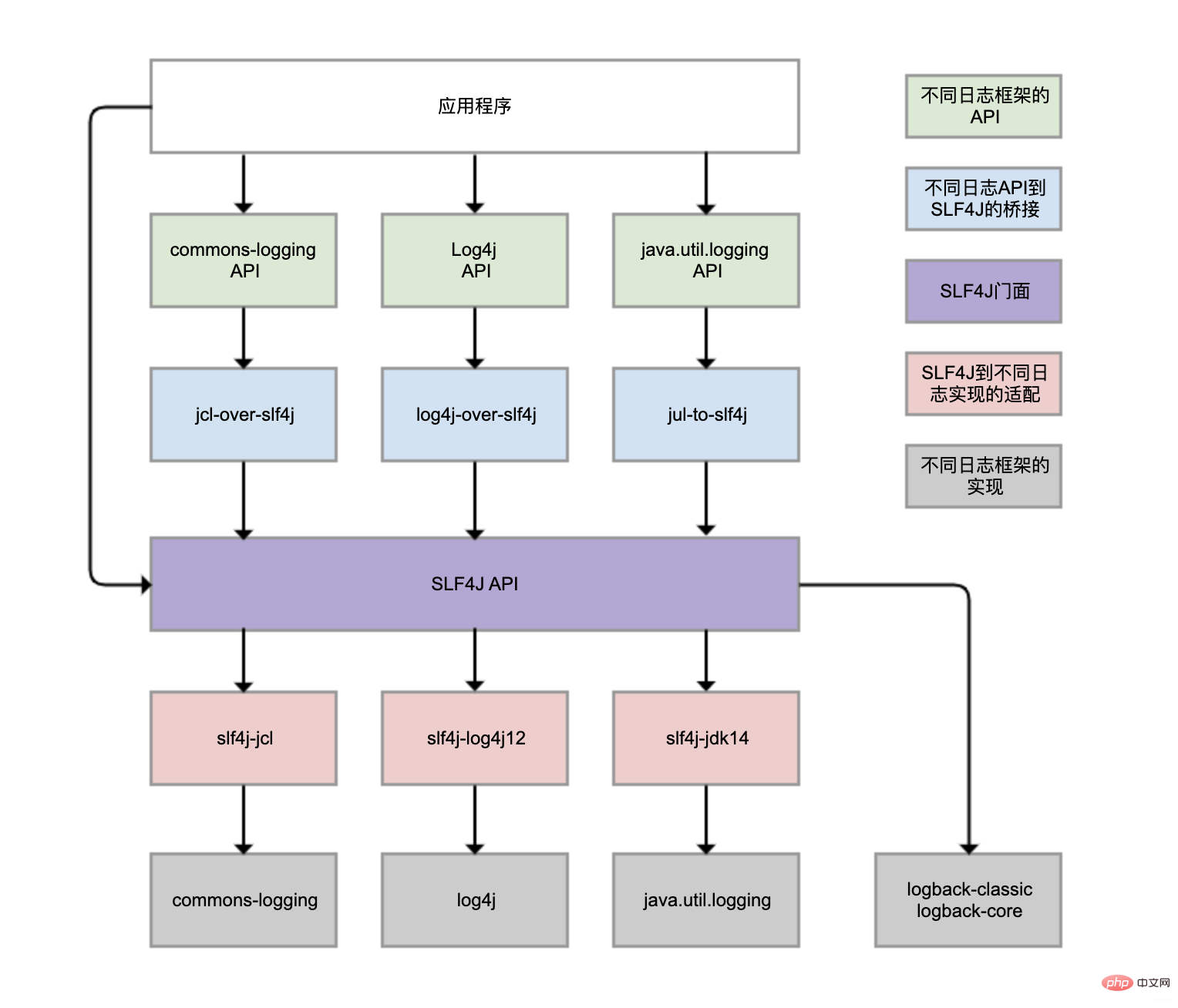
- Obwohl Sie
- Obwohl es im Bild vier graue Log-Implementierungs-Frameworks gibt, werden im täglichen Geschäft am häufigsten Logback und Log4j verwendet, die beide von derselben Person entwickelt wurden. Logback kann als verbesserte Version von Log4j betrachtet werden, die eher empfohlen wird und grundsätzlich zum Mainstream gehört.
- Das Protokollierungsframework von Spring Boot ist auch Logback. Warum können wir Logback also direkt verwenden, ohne das Logback-Paket manuell einzuführen?
-
spring-boot-starter-Modul hängt vom spring-boot-starter-logging-Modul ab.
spring-boot-starter-logging-Modul führt automatisch logback-classic ein strong> (einschließlich SLF4J und Logback-Protokollierungsframework) und einige Adapter für SLF4J. Unter anderem wird log4j-to-slf4j verwendet, um die Log4j2-API mit SLF4J zu überbrücken, und jul-to-slf4j wird verwendet, um die java.util.logging-API mit SLF4J zu überbrücken.
log4j-over-slf4j verwenden können, um Log4j mit SLF4J zu überbrücken, können Sie auch slf4j-log4j12 verwenden, um SLF4J an Log4j anzupassen und sie in einer Spalte zu zeichnen Es ist jedoch nicht möglich, sie gleichzeitig zu verwenden, da es sonst zu einer Endlosschleife kommt. Das Gleiche gilt für jcl und jul. 3 Doppelte Protokollaufzeichnunglog4j-over-slf4j实现Log4j桥接到SLF4J,也可使用slf4j-log4j12实现SLF4J适配到Log4j,也把它们画到了一列,但是它不能同时使用它们,否则就会产生死循环。jcl和jul同理。
虽然图中有4个灰色的日志实现框架,但日常业务使用最多的还是Logback和Log4j,都是同一人开发的。Logback可认为是Log4j改进版,更推荐使用,基本已是主流。
Spring Boot的日志框架也是Logback。那为什么我们没有手动引入Logback包,就可直接使用Logback?
spring-boot-starter模块依赖spring-boot-starter-logging模块
spring-boot-starter-logging模块自动引入logback-classic(包含SLF4J和Logback日志框架)和SLF4J的一些适配器。其中,log4j-to-slf4j用于实现Log4j2 API到SLF4J的桥接,jul-to-slf4j则是实现java.util.logging API到SLF4J的桥接。
3 日志重复记录
日志重复记录不但给查看日志和统计工作带来不必要的麻烦,还会增加磁盘和日志收集系统的负担。
logger配置继承关系导致日志重复记录
定义一个方法实现debug、info、warn和error四种日志的记录

Logback配置
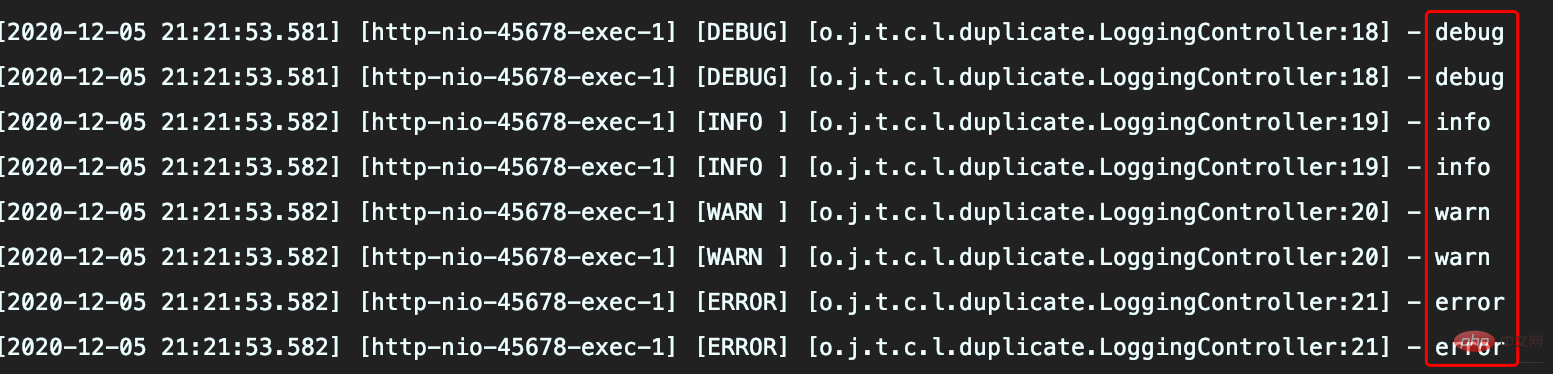
配置看没啥问题,执行方法后出现日志重复记录
分析
CONSOLE这个Appender同时挂载到了俩Logger,定义的<logger>和<root>,由于定义的<logger>继承自<root>,所以同一条日志既会通过logger记录,也会发送到root记录,因此应用package下日志出现重复记录。

如此配置的初衷是啥呢?
内心是想实现自定义logger配置,让应用内的日志暂时开启DEBUG级别日志记录。其实,这无需重复挂载Appender,去掉<logger>下挂载的Appender即可:
<logger name="org.javaedge.time.commonmistakes.logging" level="DEBUG"/>
若自定义<logger>需把日志输出到不同Appender:
比如
- 应用日志输出到文件app.log
- 其他框架日志输出到控制台
可设置<logger>的additivity属性为false,这就不会继承<root>
Die doppelte Protokollaufzeichnung führt nicht nur zu unnötigen Problemen bei der Protokollanzeige und statistischen Arbeit, sondern erhöht auch die Belastung der Festplatte und des Protokollerfassungssystems. 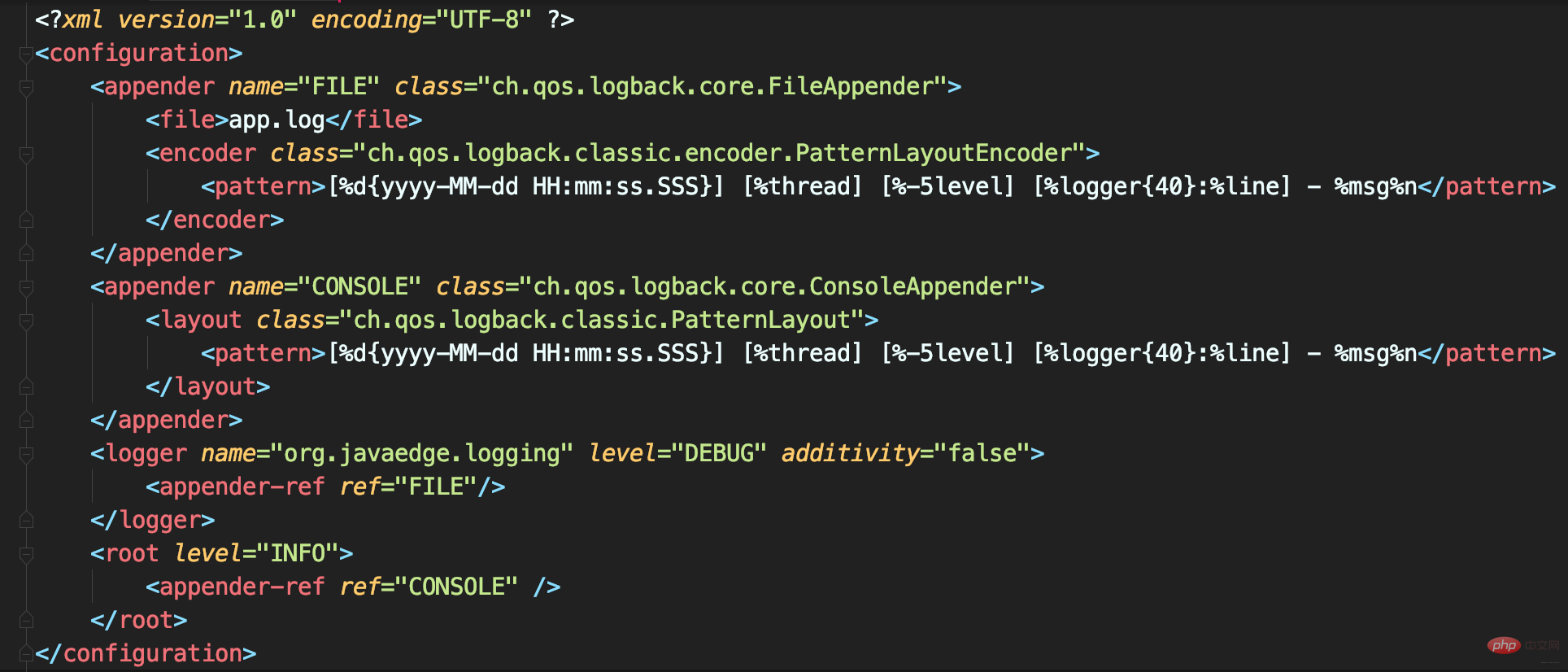
 🎜🎜🎜🎜Logback-Konfiguration🎜🎜🎜🎜🎜An der Konfiguration ist nichts auszusetzen, aber nach der Ausführung der Methode erscheinen doppelte Protokolleinträge🎜🎜🎜🎜🎜Analysis🎜 CONSOLE Dieser Appender wird gleichzeitig an zwei Logger gemountet, der definierte
🎜🎜🎜🎜Logback-Konfiguration🎜🎜🎜🎜🎜An der Konfiguration ist nichts auszusetzen, aber nach der Ausführung der Methode erscheinen doppelte Protokolleinträge🎜🎜🎜🎜🎜Analysis🎜 CONSOLE Dieser Appender wird gleichzeitig an zwei Logger gemountet, der definierte <logger> und <root>, da der definierte <logger> von <root> erbt, wird dasselbe Protokoll erstellt Vom Logger aufgezeichnet und an Root gesendet, sodass im Protokoll unter dem Anwendungspaket doppelte Datensätze vorhanden sind. 🎜🎜🎜🎜Was ist die ursprüngliche Absicht dieser Konfiguration? 🎜 In meinem Herzen möchte ich eine benutzerdefinierte Logger-Konfiguration implementieren, damit die Protokolle in der Anwendung vorübergehend die Protokollierung auf DEBUG-Ebene aktivieren können. Tatsächlich besteht keine Notwendigkeit, den Appender wiederholt zu mounten. Entfernen Sie einfach den Appender, der unter <logger> gemountet ist: 🎜public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> {
// 是否收集调用方数据
boolean includeCallerData = false;
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
// 丢弃 ≤ INFO级日志
return level.toInt() <= Level.INFO_INT;
}
protected void preprocess(ILoggingEvent eventObject) {
eventObject.prepareForDeferredProcessing();
if (includeCallerData)
eventObject.getCallerData();
}}public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
// 阻塞队列:实现异步日志的核心
BlockingQueue<E> blockingQueue;
// 默认队列大小
public static final int DEFAULT_QUEUE_SIZE = 256;
int queueSize = DEFAULT_QUEUE_SIZE;
static final int UNDEFINED = -1;
int discardingThreshold = UNDEFINED;
// 当队列满时:加入数据时是否直接丢弃,不会阻塞等待
boolean neverBlock = false;
@Override
public void start() {
...
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
if (discardingThreshold == UNDEFINED)
//默认丢弃阈值是队列剩余量低于队列长度的20%,参见isQueueBelowDiscardingThreshold方法
discardingThreshold = queueSize / 5;
...
}
@Override
protected void append(E eventObject) {
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { //判断是否可以丢数据
return;
}
preprocess(eventObject);
put(eventObject);
}
private boolean isQueueBelowDiscardingThreshold() {
return (blockingQueue.remainingCapacity() < discardingThreshold);
}
private void put(E eventObject) {
if (neverBlock) { //根据neverBlock决定使用不阻塞的offer还是阻塞的put方法
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
//以阻塞方式添加数据到队列
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}}<logger> anpassen und benötigen um das Protokoll an verschiedene Appender auszugeben: 🎜 Zum Beispiel 🎜🎜🎜 Anwendungsprotokolle werden in die Datei app.log ausgegeben🎜🎜Andere Framework-Protokolle werden an die Konsole ausgegeben🎜🎜🎜Sie können die Additivitätvon festlegen <logger> >Attribut ist false, wodurch der Appender von <root>🎜🎜🎜 nicht geerbt wirdEine falsche Konfiguration von LevelFilter führt zu doppelten Protokollen
Während der Aufzeichnung von Protokollen in der Konsole werden Protokolldatensätze je nach Ebene in zwei Dateien aufgezeichnet
Ausführungsergebnisse
Die Datei info.log enthält INFO, WARNUNG und ERROR dreistufige Protokolle, nicht wie erwartet
error.log enthält WARN- und ERROR-Protokolle, was zu einer wiederholten Erfassung von Protokollen führt
Unfallverantwortung
Einige Unternehmen verwenden automatisierte ELK-Lösungen zum Sammeln von Protokollen. und die Protokolle werden gleichzeitig gesammelt. Ausgabe an die Konsole und Dateien. Beim lokalen Testen sind die in den Dateien aufgezeichneten Protokolle egal, da Entwickler keine Serverzugriffsrechte haben in den ursprünglichen Protokolldateien sind schwer zu finden.


Warum werden die Protokolle wiederholt?
ThresholdFilter-Quellcode-Analyse
- Wenn
Protokollebene ≥ Konfigurationsebene日志级别 ≥ 配置级别返回NEUTRAL,继续调用过滤器链上的下个过滤器 - 否则返回DENY,直接拒绝记录日志
该案例我们将 ThresholdFilter 置 WARN,因此可记录WARN和ERROR级日志。
LevelFilter
用于比较日志级别,然后进行相应处理。
- 若匹配就调用onMatch定义的处理方式:默认交给下一个过滤器处理(AbstractMatcherFilter基类中定义的默认值)
- 否则调用onMismatch定义的处理方式:默认也是交给下一个过滤器
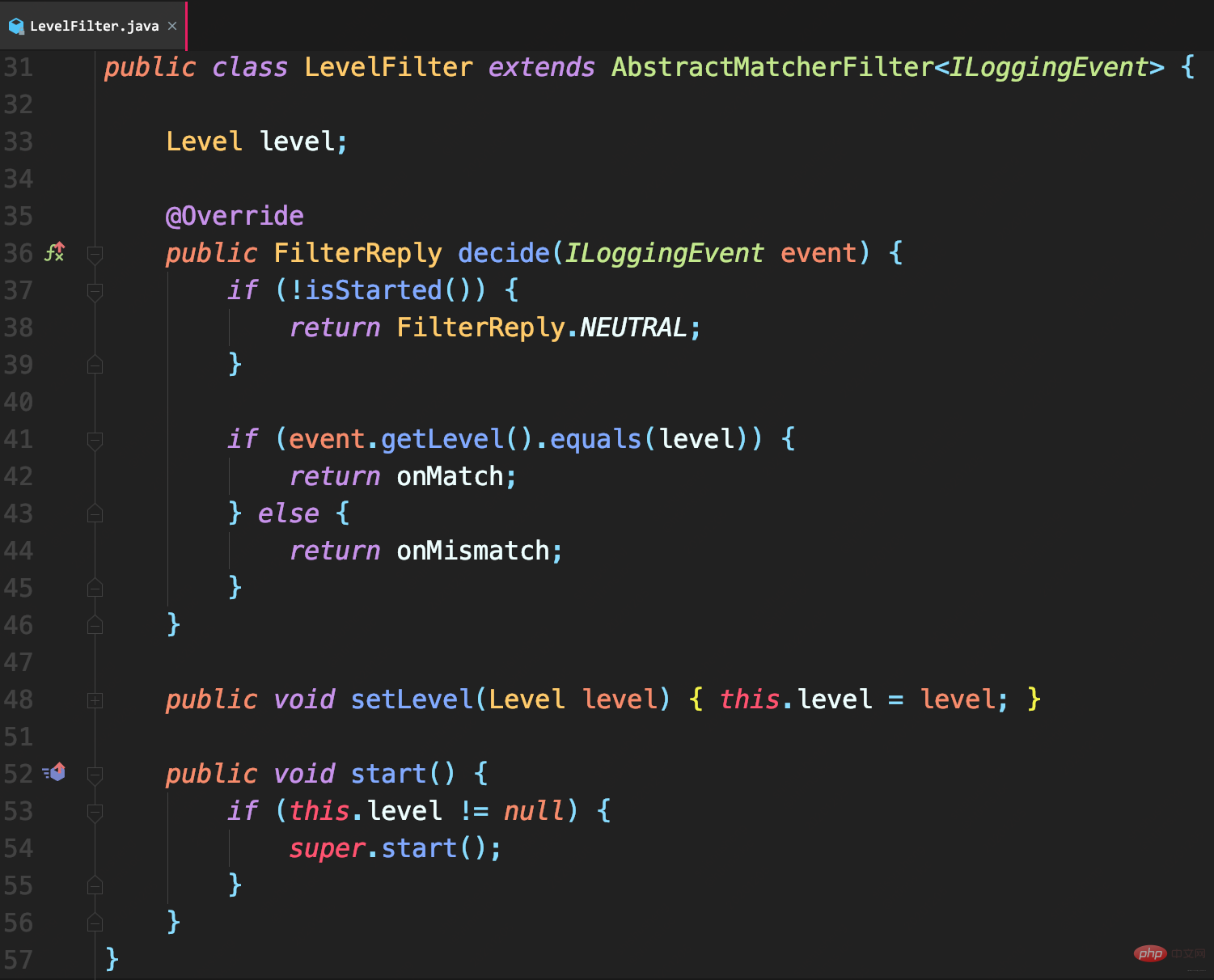

和ThresholdFilter不同,LevelFilter仅配置level无法真正起作用。
由于未配置onMatch和onMismatch属性,所以该过滤器失效,导致INFO以上级别日志都记录了。
修正
配置LevelFilter的onMatch属性为ACCEPT,表示接收INFO级别的日志;配置onMismatch属性为DENY,表示除了INFO级别都不记录: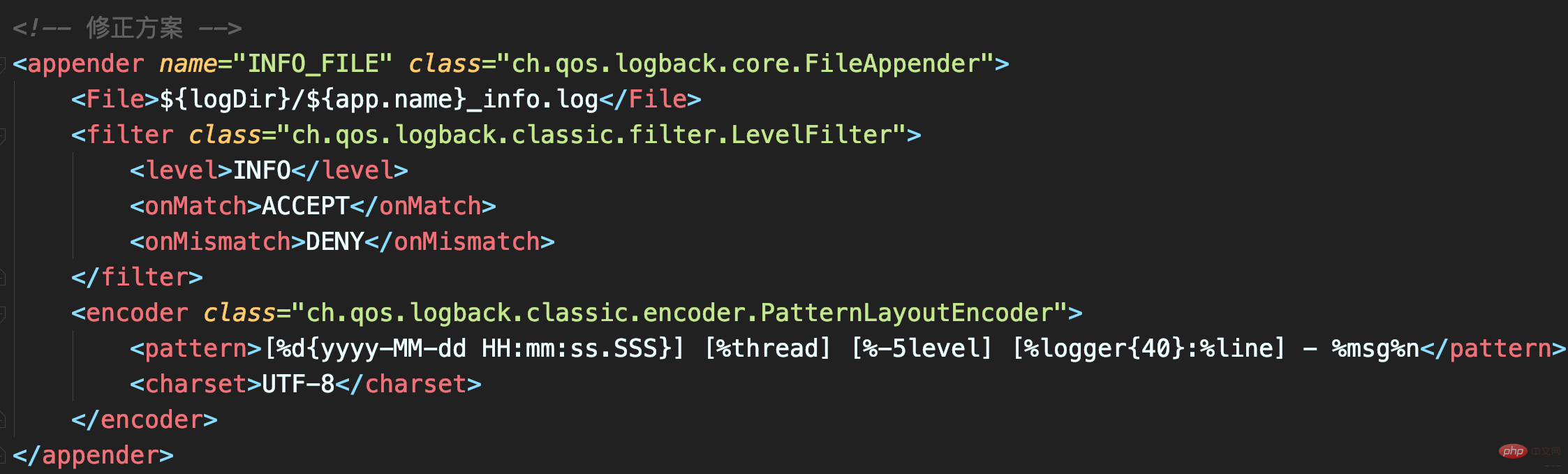
如此,_info.logNEUTRAL
DENY
zurückgegeben und die Aufzeichnung direkt verweigert Protokolle 
In diesem Fall werden wir
ThresholdFilter festlegen 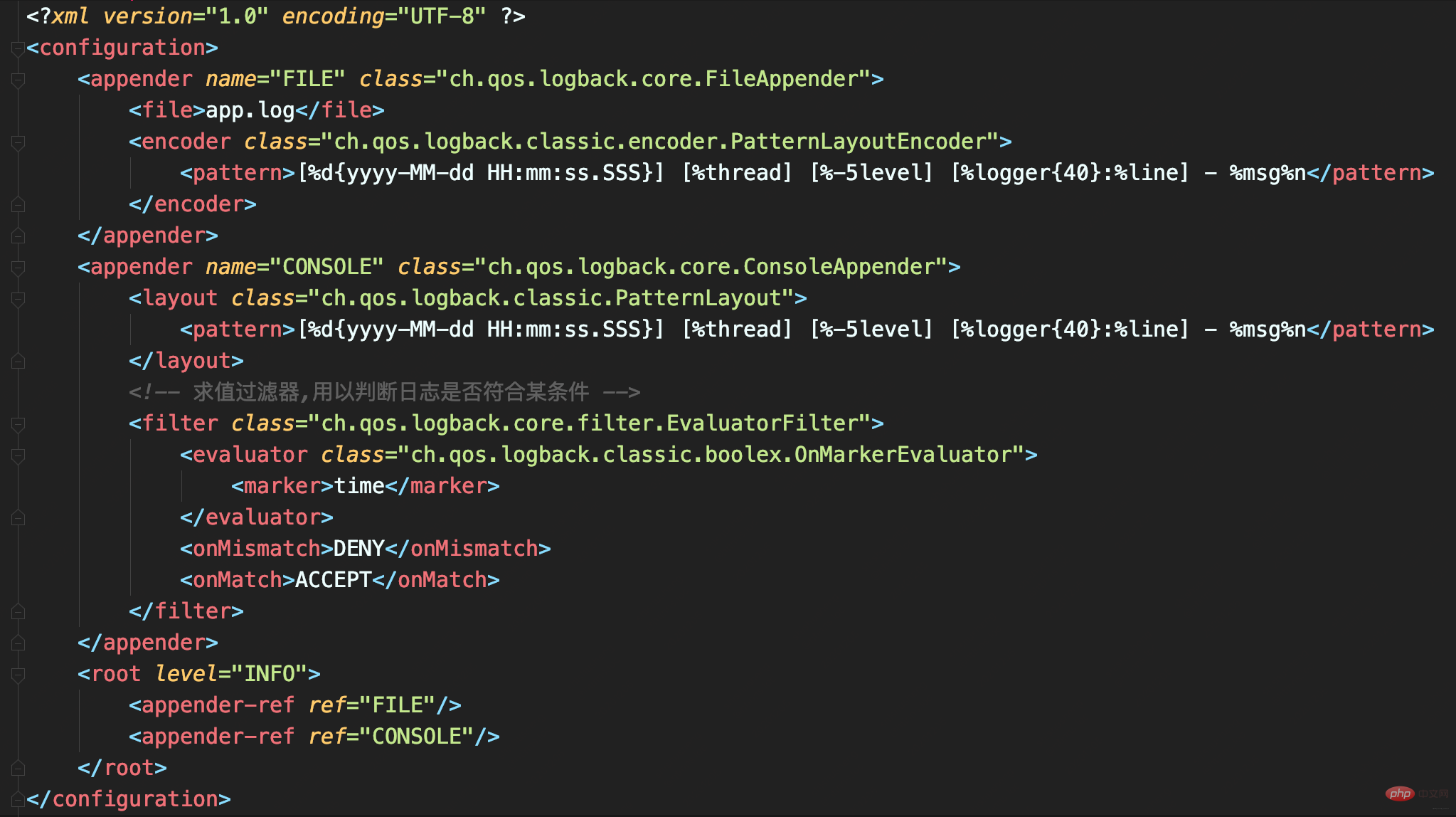 bis
bis
WARN
WARNLevelFilterund ERROR aufgezeichnet werden können.
- wird verwendet, um Protokollebenen zu vergleichen und sie dann entsprechend zu behandeln.
onMatch
Die definierte Verarbeitungsmethode auf: Der Standardwert wird an den nächsten Filter übergeben (der in der AbstractMatcherFilter-Basisklasse definierte Standardwert). 
 Andernfalls rufen Sie
Andernfalls rufen Sie
Die definierte Verarbeitungsmethode auf : Der Standardwert wird auch an den nächsten Filter übergeben. "/>
 unterscheidet sich von
unterscheidet sich von ThresholdFilter
, LevelFilterNur das Konfigurieren der Ebene funktioniert nicht wirklich. 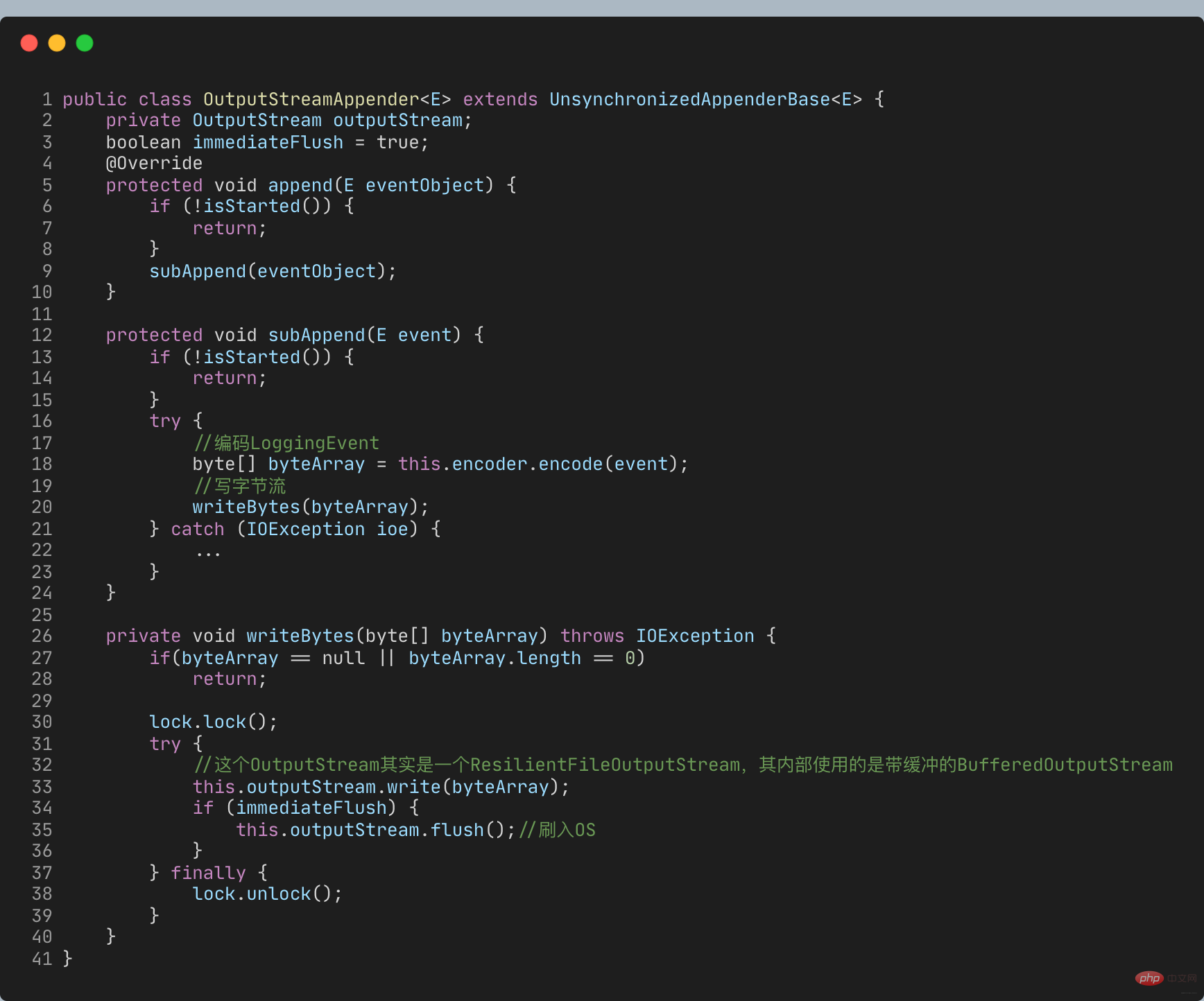 Da die Attribute onMatch und onMismatch nicht konfiguriert sind, schlägt der Filter fehl, was dazu führt, dass Protokolle auf Ebenen über INFO aufgezeichnet werden.
Da die Attribute onMatch und onMismatch nicht konfiguriert sind, schlägt der Filter fehl, was dazu führt, dass Protokolle auf Ebenen über INFO aufgezeichnet werden.
 🎜🎜Auf diese Weise enthält die Datei
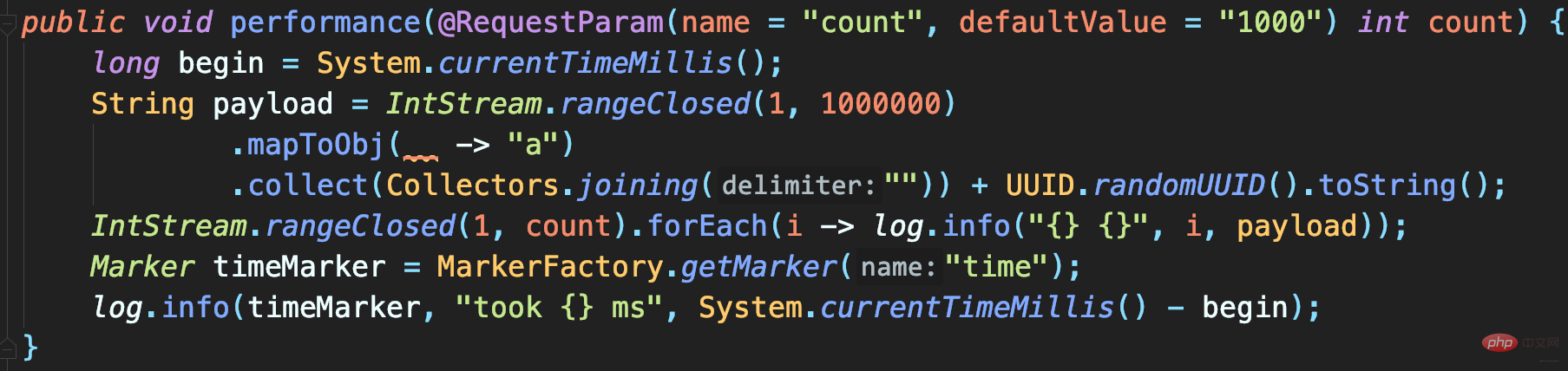
🎜🎜Auf diese Weise enthält die Datei _info.log nur INFO Protokolle auf Ebene, und es werden keine doppelten Protokolle vorhanden sein. 🎜🎜4 Verbessert die asynchrone Protokollierung die Leistung?🎜🎜Nachdem Sie wissen, wie Sie Protokolle korrekt in Dateien ausgeben, sollten Sie darüber nachdenken, wie Sie verhindern können, dass die Protokollierung zu einem Engpass bei der Systemleistung wird. Dies kann das Problem der Protokollaufzeichnung lösen, wenn die E/A-Leistung von Festplatten (z. B. mechanischen Festplatten) schlecht und das Protokollvolumen groß ist. 🎜🎜Definieren Sie die folgende Protokollkonfiguration. Es gibt insgesamt zwei Appender: 🎜🎜FILE ist ein FileAppender, der zum Aufzeichnen aller Protokolle verwendet wird; 🎜 CONSOLE ist ein ConsoleAppender, der zum Aufzeichnen von Protokollen mit Zeitmarkierungen verwendet wird. 🎜🎜🎜 Geben Sie eine große Anzahl von Protokollen in eine Datei aus. Wenn auch die Ergebnisse des Leistungstests gemischt sind, ist es schwierig, das Protokoll zu finden. Daher wird EvaluatorFilter hier verwendet, um Protokolle nach Tags zu filtern, und die gefilterten Protokolle werden separat an die Konsole ausgegeben. In diesem Fall wird dem Protokoll, das die Testergebnisse ausgibt, eine Zeitmarke hinzugefügt. 🎜🎜🎜🎜Verwenden Sie Tags und EvaluatorFilter zusammen, um Protokolle nach Tags zu filtern🎜. 🎜🎜🎜🎜Testcode: Realisieren Sie die Aufzeichnung großer Protokolle für eine bestimmte Anzahl von Malen. Jedes Protokoll enthält 1 MB simulierter Daten. Schließlich wird ein zeitaufwendiges Protokoll zur Methodenausführung aufgezeichnet: 🎜🎜🎜🎜Sie können sehen Nach der Ausführung des Programms beträgt die Aufrufzeit zum Aufzeichnen von 1000 Protokollen bzw. 10000 Protokollen 5,1 Sekunden bzw. 39 Sekunden🎜🎜🎜🎜🎜Für den Code, der nur Dateiprotokolle aufzeichnet, dauert dies zu lange. 🎜🎜Quellcode-Analyse🎜🎜FileAppender erbt von OutputStreamAppender🎜🎜🎜 Beim Anhängen von Protokollen werden die Protokolle direkt in den OutputStream geschrieben, der ein synchroner Protokolldatensatz ist🎜🎜🎜所以日志大量写入才会旷日持久。如何才能实现大量日志写入时,不会过多影响业务逻辑执行耗时而影响吞吐量呢?
AsyncAppender
使用Logback的AsyncAppender
即可实现异步日志记录。AsyncAppender类似装饰模式,在不改变类原有基本功能情况下为其增添新功能。这便可把AsyncAppender附加在其他Appender,将其变为异步。
定义一个异步Appender ASYNCFILE,包装之前的同步文件日志记录的FileAppender, 即可实现异步记录日志到文件
- 记录1000次日志和10000次日志的调用耗时,分别是537毫秒和1019毫秒


异步日志真的如此高性能?并不,因为这并没有记录下所有日志。
AsyncAppender异步日志坑
- 记录异步日志撑爆内存
- 记录异步日志出现日志丢失
- 记录异步日志出现阻塞。
案例
模拟慢日志记录场景:
首先,自定义一个继承自ConsoleAppender的MySlowAppender,作为记录到控制台的输出器,写入日志时休眠1秒。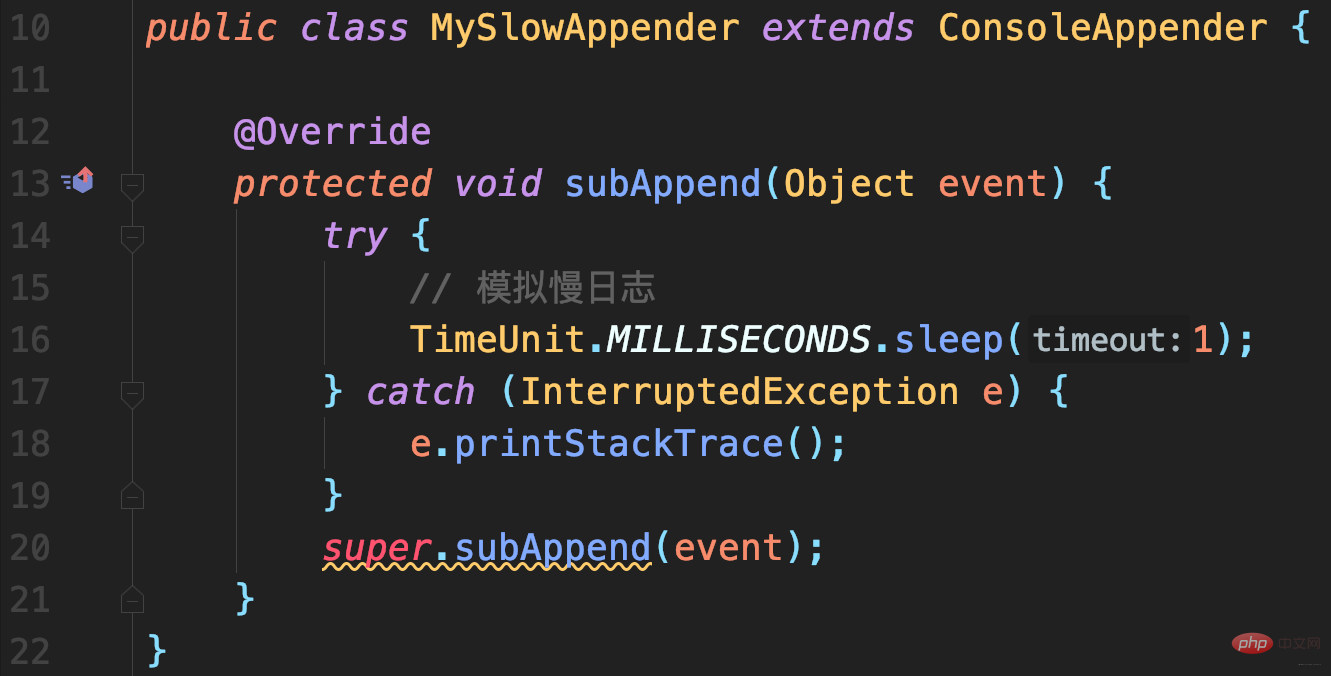
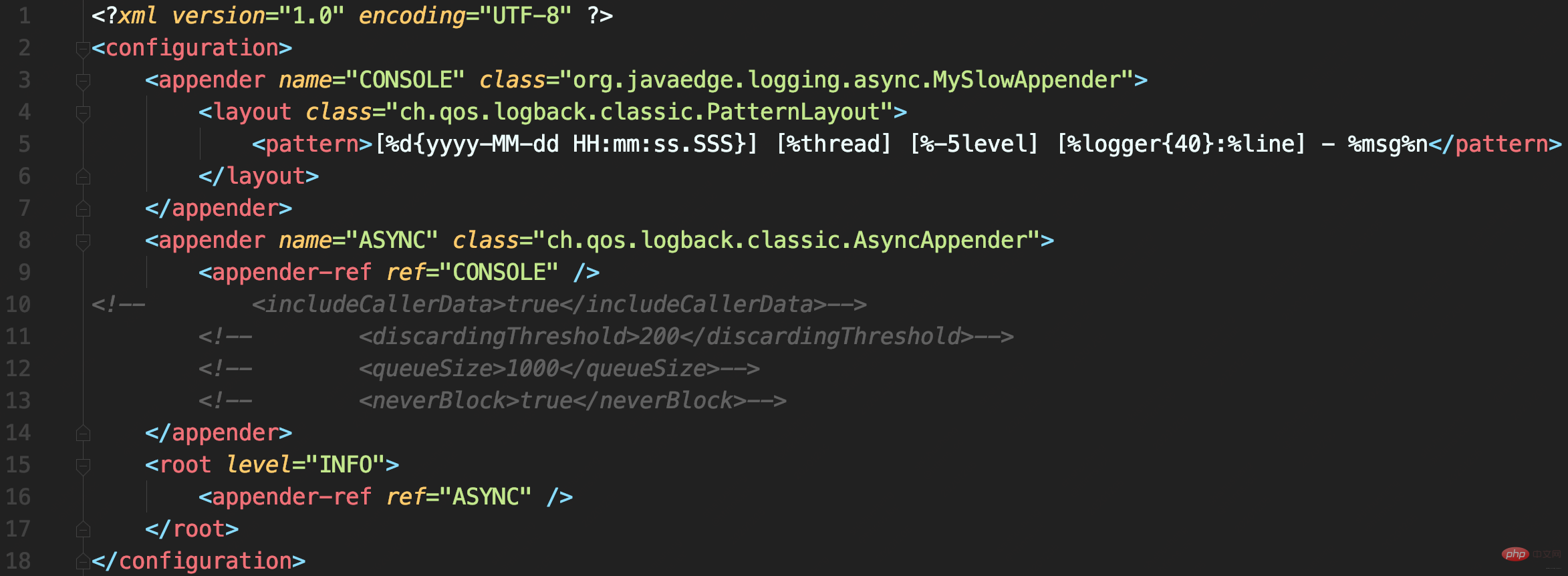
配置文件中使用AsyncAppender,将MySlowAppender包装为异步日志记录
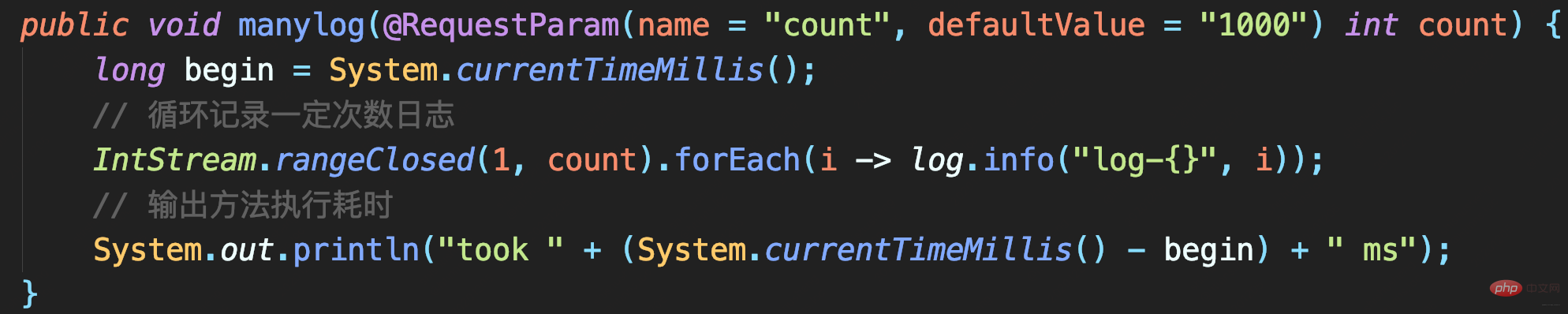
测试代码
耗时很短但出现日志丢失:要记录1000条日志,最终控制台只能搜索到215条日志,而且日志行号变问号。
原因分析
AsyncAppender提供了一些配置参数,而当前没用对。
源码解析
- includeCallerData
默认false:方法行号、方法名等信息不显示 - queueSize
控制阻塞队列大小,使用的ArrayBlockingQueue阻塞队列,默认容量256:内存中最多保存256条日志 - discardingThreshold
丢弃日志的阈值,为防止队列满后发生阻塞。默认队列剩余容量 < 队列长度的20%,就会丢弃TRACE、DEBUG和INFO级日志 - neverBlock
控制队列满时,加入的数据是否直接丢弃,不会阻塞等待,默认是false- 队列满时:offer不阻塞,而put会阻塞
- neverBlock为true时,使用offer
public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> {
// 是否收集调用方数据
boolean includeCallerData = false;
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
// 丢弃 ≤ INFO级日志
return level.toInt() <= Level.INFO_INT;
}
protected void preprocess(ILoggingEvent eventObject) {
eventObject.prepareForDeferredProcessing();
if (includeCallerData)
eventObject.getCallerData();
}}public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
// 阻塞队列:实现异步日志的核心
BlockingQueue<E> blockingQueue;
// 默认队列大小
public static final int DEFAULT_QUEUE_SIZE = 256;
int queueSize = DEFAULT_QUEUE_SIZE;
static final int UNDEFINED = -1;
int discardingThreshold = UNDEFINED;
// 当队列满时:加入数据时是否直接丢弃,不会阻塞等待
boolean neverBlock = false;
@Override
public void start() {
...
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
if (discardingThreshold == UNDEFINED)
//默认丢弃阈值是队列剩余量低于队列长度的20%,参见isQueueBelowDiscardingThreshold方法
discardingThreshold = queueSize / 5;
...
}
@Override
protected void append(E eventObject) {
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { //判断是否可以丢数据
return;
}
preprocess(eventObject);
put(eventObject);
}
private boolean isQueueBelowDiscardingThreshold() {
return (blockingQueue.remainingCapacity() < discardingThreshold);
}
private void put(E eventObject) {
if (neverBlock) { //根据neverBlock决定使用不阻塞的offer还是阻塞的put方法
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
//以阻塞方式添加数据到队列
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}}默认队列大小256,达到80%后开始丢弃<=INFO级日志后,即可理解日志中为什么只有两百多条INFO日志了。
queueSize 过大
可能导致OOM
queueSize 较小
默认值256就已经算很小了,且discardingThreshold设置为大于0(或为默认值),队列剩余容量少于discardingThreshold的配置就会丢弃<=INFO日志。这里的坑点有两个:
- 因为discardingThreshold,所以设置queueSize时容易踩坑。
比如本案例最大日志并发1000,即便置queueSize为1000,同样会导致日志丢失 - discardingThreshold参数容易有歧义,它
不是百分比,而是日志条数。对于总容量10000队列,若希望队列剩余容量少于1000时丢弃,需配置为1000
neverBlock 默认false
意味总可能会出现阻塞。
- 若discardingThreshold = 0,那么队列满时再有日志写入就会阻塞
- 若discardingThreshold != 0,也只丢弃≤INFO级日志,出现大量错误日志时,还是会阻塞
queueSize、discardingThreshold和neverBlock三参密不可分,务必按业务需求设置:
- 若优先绝对性能,设置
neverBlock = true,永不阻塞 - 若优先绝不丢数据,设置
discardingThreshold = 0,即使≤INFO级日志也不会丢。但最好把queueSize设置大一点,毕竟默认的queueSize显然太小,太容易阻塞。 - 若兼顾,可丢弃不重要日志,把queueSize设置大点,再设置合理的discardingThreshold
以上日志配置最常见两个误区
Schauen wir uns die Missverständnisse bei der Protokollierung selbst an.
Durch die Verwendung von Protokollplatzhaltern entfällt die Notwendigkeit, die Protokollebene zu beurteilen?
Die {}-Platzhaltersyntax von SLF4J ruft die tatsächlichen Parameter nur dann ab, wenn das Protokoll tatsächlich aufgezeichnet wird, wodurch das Leistungsproblem der Protokolldatenerfassung gelöst wird.
Ist das richtig?
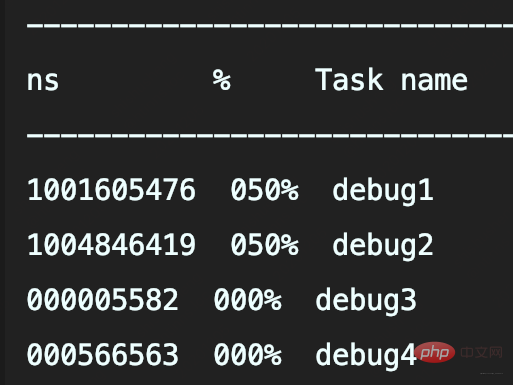
- Bestätigungscode: Es dauert 1 Sekunde, bis das Ergebnis zurückgegeben wird
Wenn Sie DEBUG-Protokolle aufzeichnen und nur Protokolle der Ebene >=INFO aufzeichnen, dauert das Programm dann auch 1 Sekunde?
Drei Methoden zum Testen:
- SlowString durch Verketten von Zeichenfolgen aufzeichnen
- Platzhaltermethode zum Aufzeichnen von slowString verwenden
- Bestimmen Sie zunächst, ob die Protokollebene DEBUG aktiviert ist.
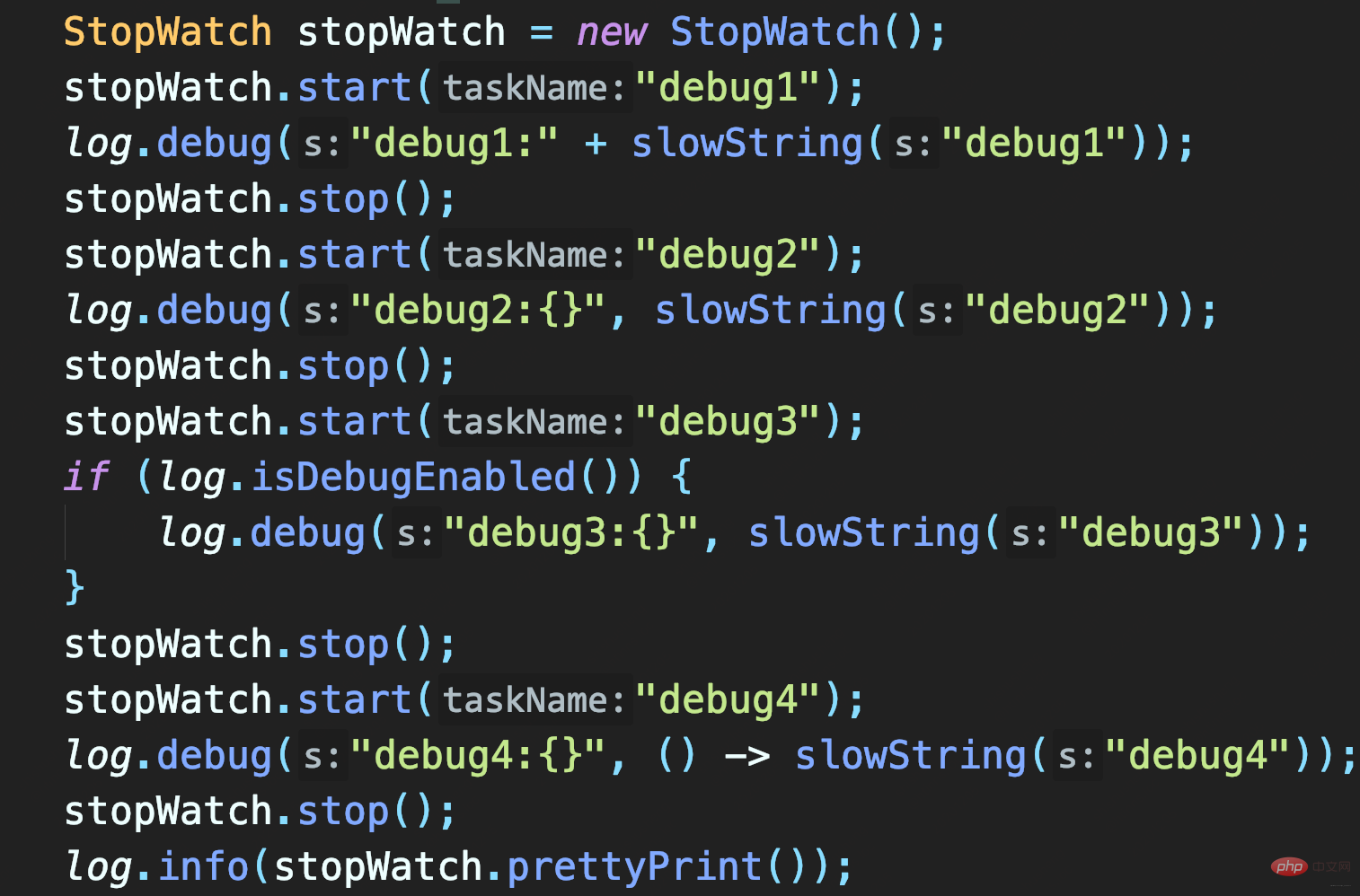
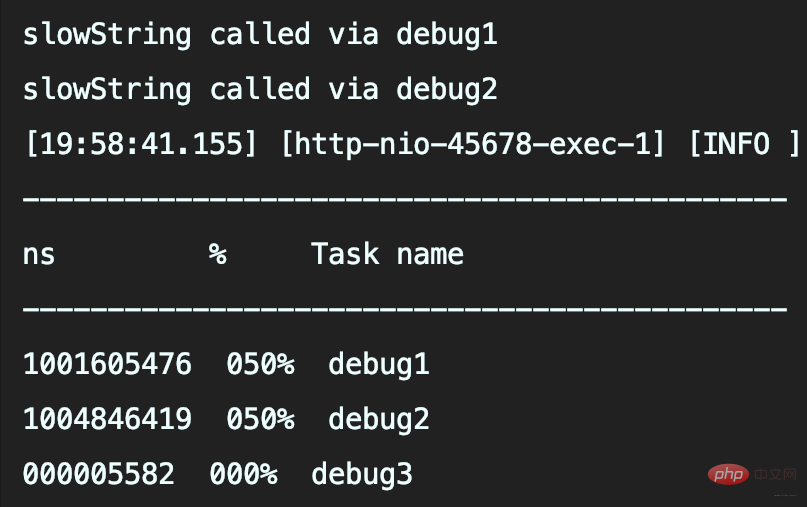
Die ersten beiden Methoden rufen beide slowString auf, sodass beide 1s benötigen. Und die zweite Methode besteht darin, Platzhalter zum Aufzeichnen von slowString zu verwenden. Obwohl diese Methode die Übergabe von Objekten ohne explizites Spleißen von Strings ermöglicht, handelt es sich nur um eine Verzögerung (wenn das Protokoll nicht aufgezeichnet wird, wird es weggelassen) Protokollparameter object.toString() und Zeitaufwendig für die String-Verkettung.
In diesem Fall muss slowString aufgerufen werden, sofern die Protokollebene nicht im Voraus festgelegt wird.
Daher kann die Verwendung von {}占位符 das Leistungsproblem der Protokolldatenerfassung nicht lösen, indem die Parameterwerterfassung verzögert wird.
Neben der vorherigen Beurteilung der Protokollebene können Sie auch verzögerte Parameterinhalte über Lambda-Ausdrücke erhalten. Allerdings unterstützt die API von SLF4J Lambda noch nicht, daher müssen Sie die Log4j2-Log-API verwenden und Lomboks @Slf4j-Annotation durch die **@Log4j2**-Annotation ersetzen, um eine Methode für Lambda-Ausdrucksparameter bereitzustellen: 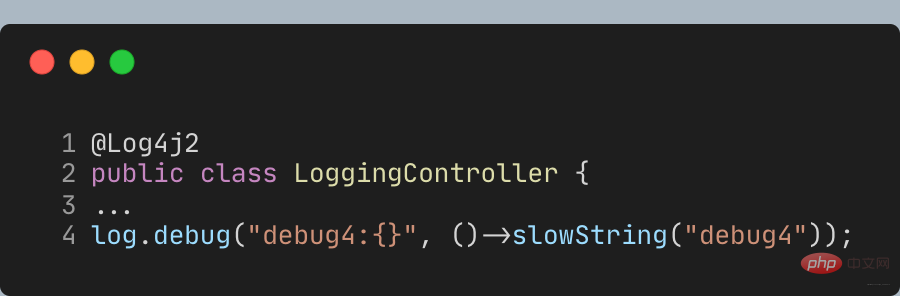
Call Wie bei diesem Debug, der Signatur Supplier werden die Parameter verzögert, bis das Protokoll tatsächlich benötigt wird: Debug4 ruft also nicht die slowString-Methode auf ersetzt sie einfach Mit der Log4j2-API erfolgt die eigentliche Protokollierung immer noch über Logback. Dies ist der Vorteil der SLF4J-Anpassung. Das obige ist der detaillierte Inhalt vonVerstehen Sie Java-Protokollebenen, doppelte Aufzeichnungen und Probleme mit Protokollverlusten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



Zusammenfassung

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Leitfaden zur Quadratwurzel in Java. Hier diskutieren wir anhand eines Beispiels und seiner Code-Implementierung, wie Quadratwurzel in Java funktioniert.
 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Armstrong-Zahl in Java
Aug 30, 2024 pm 04:26 PM
Armstrong-Zahl in Java
Aug 30, 2024 pm 04:26 PM
Leitfaden zur Armstrong-Zahl in Java. Hier besprechen wir eine Einführung in die Armstrong-Zahl in Java zusammen mit einem Teil des Codes.
 Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Leitfaden zum Zufallszahlengenerator in Java. Hier besprechen wir Funktionen in Java anhand von Beispielen und zwei verschiedene Generatoren anhand ihrer Beispiele.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
