
 Entwicklungswerkzeuge
atom
So installieren und führen Sie Python in Atom unter einer Win10-Umgebung aus
Entwicklungswerkzeuge
atom
So installieren und führen Sie Python in Atom unter einer Win10-Umgebung aus
So installieren und führen Sie Python in Atom unter einer Win10-Umgebung aus

In diesem Artikel erfahren Sie, wie Sie Python auf Atom unter Windows 10 installieren und ausführen. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.

Verwandte Empfehlungen: „Atom-Tutorial“ 1. Laden Sie Atom herunter
1. Offizielle Website: Offizielle Atom-Website
2. Öffnen Sie diese Webseite, Sie können die Funktionsweise sehen von Atom System
3. Der Download ist abgeschlossen. Doppelklicken Sie auf die exe-Datei.
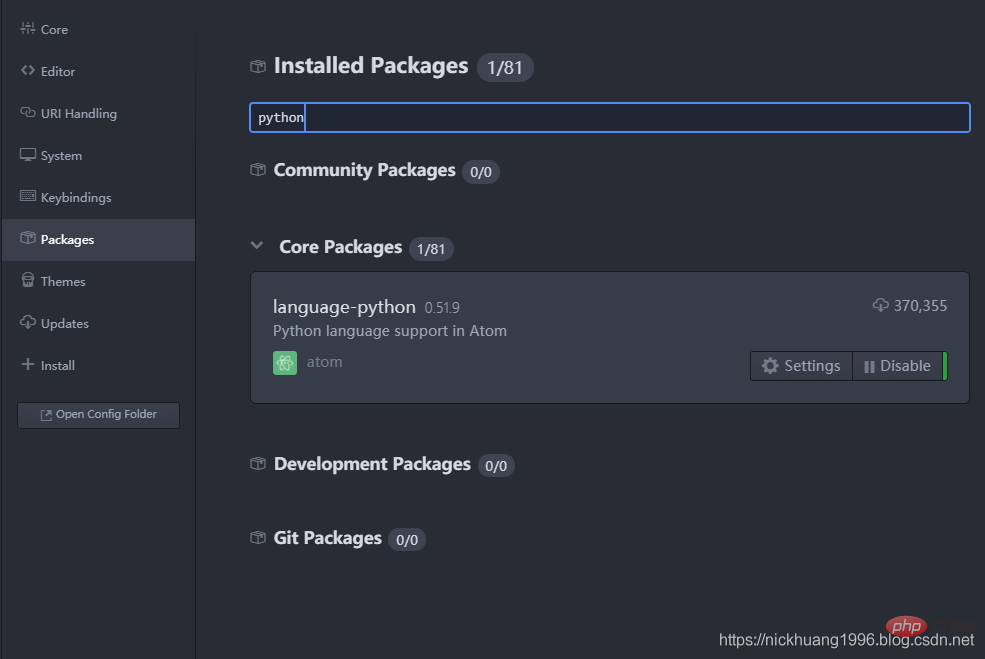
1. Überprüfen Sie die Unterstützung der Python-Bibliothek

python-Language-Server
pip install python-language-server[all]
 zu installieren. Die Installation ist erfolgreich und diese Schnittstelle wird angezeigt:
zu installieren. Die Installation ist erfolgreich und diese Schnittstelle wird angezeigt:
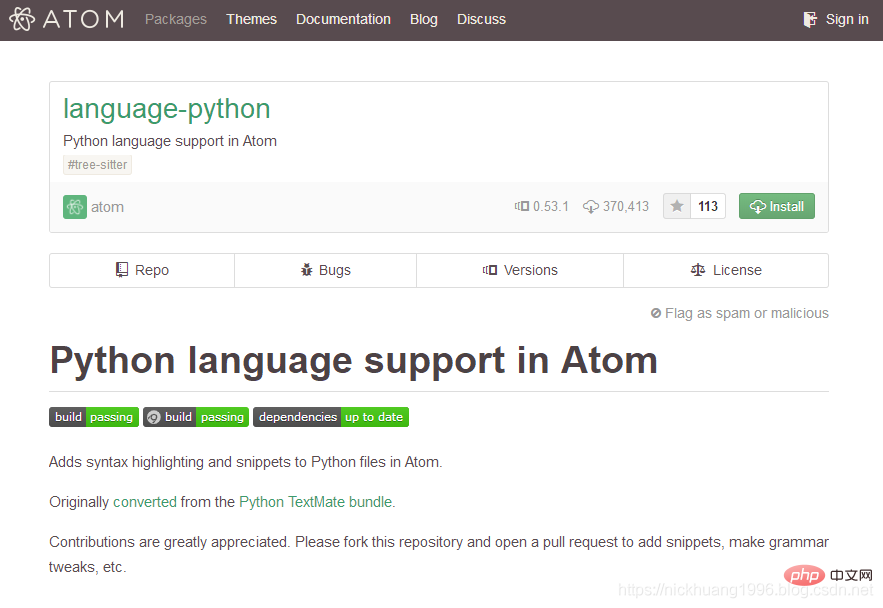
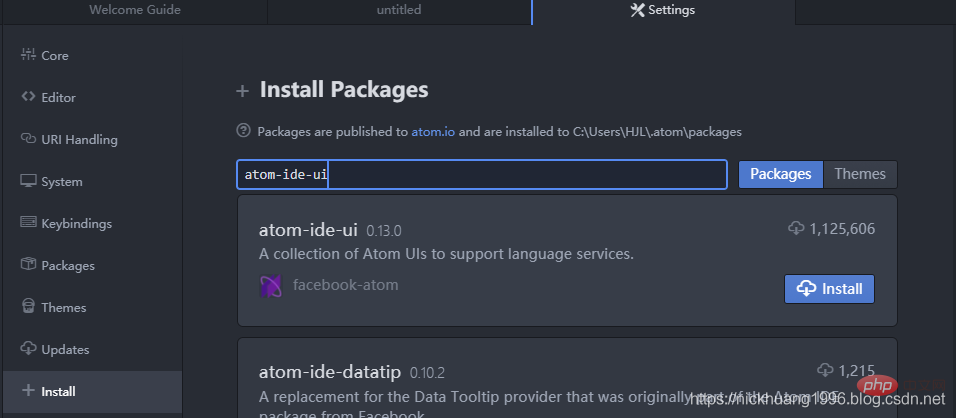
(2) Die Installation unterstützt verschiedene Sprach-IDEs. Suchen Sie nach der UI-Schnittstelle
atom-ide-uiatom-ide-ui
wie im Bild gezeigt
 (3) Installieren Sie auf die gleiche Weise
(3) Installieren Sie auf die gleiche Weise
:
ide-python
(4) Schließlich
Das wichtigste , installieren Sie das laufende Tool atom-python-run: press
f5 zum Ausführen, f6 zur Pause ~
 . 1. Hier nehme ich meine
. 1. Hier nehme ich meine
als Beispiel: Python-Implementierung zum Crawlen und Herunterladen von Baidu-Bildern 2.打开这个项目,菜单栏里点击File->Add Project Folder 3.Atom里打开这个download_picture.py(以杉原杏璃为关键字) 效果如下(可以看到很多警告,也支持ctrl+鼠标访问函数和变量): 4.我们点击F5,可以看到程序运行成功!! 是不是用这个IDE也很不错呢~ 更多编程相关知识,请访问:编程课程!! Das obige ist der detaillierte Inhalt vonSo installieren und führen Sie Python in Atom unter einer Win10-Umgebung aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
# coding=utf-8
"""
@author:nickhuang1996
"""
import re
import sys
import urllib
import requests
import os
import cv2
from glob import glob
import time
def getPage(keyword, times, page_number, pic_type):
page = times * page_number#time每一次加一
keyword = urllib.parse.quote(keyword, safe='/')#对含有特殊符号的URL进行编码,使其转换为合法的url字符串。中文则转换为数字,符号和字母的组合
#print(keyword)
url_begin = "http://image.baidu.com/search/" + pic_type + "?tn=baiduimage&ie=utf-8&word="#pic_type
url = url_begin + keyword + "&pn=" +str(page)
return url
def get_onepage_urls(onepageurl):
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
return pic_urls
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)#index是30个图片的链接,flip是60个
print("一共有{}个图片链接".format(len(pic_urls)))
return pic_urls
def download_pic(pic_urls, keyword, save_path):
#给出图片链接列表, 下载所有图片
print("去除了重复的图片下载数量为:{}".format(len(pic_urls)))
print("\n开始下载...")
start_time = time.time()
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=5)
string = save_path + '/' + str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
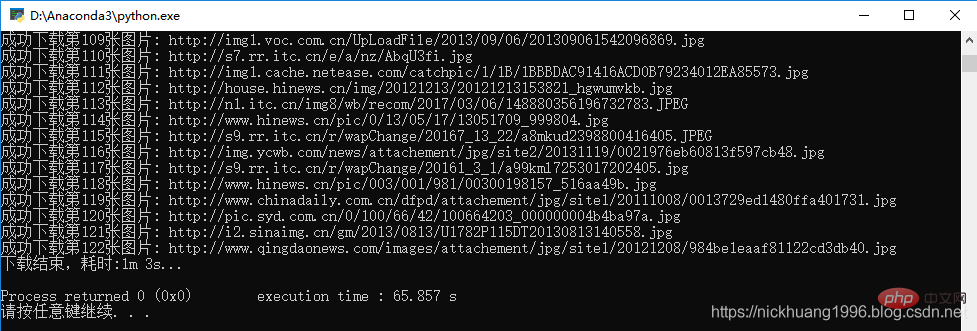
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
end_time = time.time()-start_time
print("下载结束,耗时:{:.0f}m {:.0f}s...".format(end_time // 60, end_time % 60))
if __name__ == '__main__':
keyword = '杉原杏璃' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
save_path = './baidu_download/' + keyword
if not os.path.exists(save_path):
os.mkdir(save_path)
#参数设置
times = 0
#图片参数类型
pic_type = "flip"#"flip"/"index"
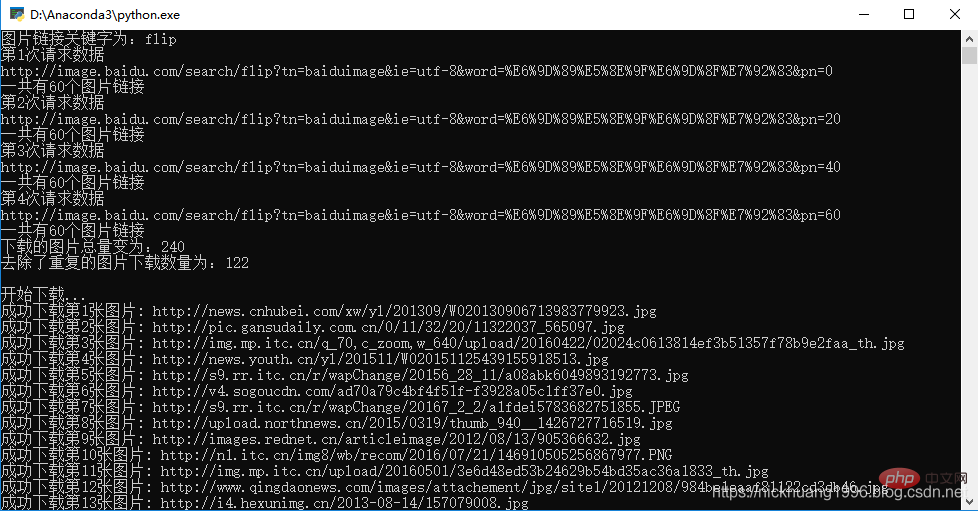
print("图片链接关键字为:{}".format(pic_type))
page_number = 20#flip时为60,index时为30则不会有缓存
total_times = 3#请求总次数
"""
如果page_number为20,则百度图片每页显示20张图片,因此对于flip形式每页会多缓存(60-20=40)张,index形式每页会多缓存(30-20=10)张,
所以,请求4次的话:
flip应该是 20 × 4 + (60 - 20) = 120张图片,而不是60×4 = 240
index应该是 20 × 4 + (30 - 20) = 90张图片,而不是30×4 = 120
示意图:
flip index
0 ________ ______ 0
| | | |
| 20 | | 20 | 10
| | | |
20 |______|______ |______|______ 20
| | | |
| 20 | _|_ 20 | 30
| | | |
40 |______|______ |______|______ 40
| | | | |
| | 20 | _|_ 20 | 50
| | | | |
60 _|_ |______|______ |______|______ 60
| | | | |
| | 20 | _|_ 20 | 70
| | | | |
80 _|_ |______| |______| 80
| | |
| | _|_ 90
| |
100 _|_ |
|
|
|
120 _|_
说白了,就是获取了重复的图片
可以通过调节page_number变量查看
"""
all_pic_urls = []
while 1:#死循环
if times > total_times:
break
print("第{}次请求数据".format(times + 1))
url=getPage(keyword, times, page_number, pic_type)#输入参数:关键词,开始的页数,总页数
print(url)#打印链接
onepage_urls= get_onepage_urls(url)#index是30个图片的链接,flip是60个
times += 1#页数加1
if onepage_urls != 0:
all_pic_urls.extend(onepage_urls)#列表末尾一次性追加另一个序列中的多个值
#print("将要下载的图片数量变为:{}".format(len(all_pic_urls)))
print("下载的图片总量变为:{}".format(len(all_pic_urls)))
download_pic(list(set(all_pic_urls)),keyword, save_path)#set去除重复的元素(链接)

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Obwohl eindeutig und unterschiedlich mit der Unterscheidung zusammenhängen, werden sie unterschiedlich verwendet: Unterschieds (Adjektiv) beschreibt die Einzigartigkeit der Dinge selbst und wird verwendet, um Unterschiede zwischen den Dingen zu betonen; Das Unterscheidungsverhalten oder die Fähigkeit des Unterschieds ist eindeutig (Verb) und wird verwendet, um den Diskriminierungsprozess zu beschreiben. In der Programmierung wird häufig unterschiedlich, um die Einzigartigkeit von Elementen in einer Sammlung darzustellen, wie z. B. Deduplizierungsoperationen; Unterscheidet spiegelt sich in der Gestaltung von Algorithmen oder Funktionen wider, wie z. B. die Unterscheidung von ungeraden und sogar Zahlen. Bei der Optimierung sollte der eindeutige Betrieb den entsprechenden Algorithmus und die Datenstruktur auswählen, während der unterschiedliche Betrieb die Unterscheidung zwischen logischer Effizienz optimieren und auf das Schreiben klarer und lesbarer Code achten sollte.
 Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Es gibt kein absolutes Gehalt für Python- und JavaScript -Entwickler, je nach Fähigkeiten und Branchenbedürfnissen. 1. Python kann mehr in Datenwissenschaft und maschinellem Lernen bezahlt werden. 2. JavaScript hat eine große Nachfrage in der Entwicklung von Front-End- und Full-Stack-Entwicklung, und sein Gehalt ist auch beträchtlich. 3. Einflussfaktoren umfassen Erfahrung, geografische Standort, Unternehmensgröße und spezifische Fähigkeiten.
 Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
! X Understanding! X ist ein logischer Nicht-Operator in der C-Sprache. Es booleschen den Wert von x, dh wahre Änderungen zu falschen, falschen Änderungen an True. Aber seien Sie sich bewusst, dass Wahrheit und Falschheit in C eher durch numerische Werte als durch Boolesche Typen dargestellt werden, ungleich Null wird als wahr angesehen und nur 0 wird als falsch angesehen. Daher handelt es sich um negative Zahlen wie positive Zahlen und gilt als wahr.
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Es gibt keine integrierte Summenfunktion in C für die Summe, kann jedoch implementiert werden durch: Verwenden einer Schleife, um Elemente nacheinander zu akkumulieren; Verwenden eines Zeigers, um auf die Elemente nacheinander zuzugreifen und zu akkumulieren; Betrachten Sie für große Datenvolumina parallele Berechnungen.
 Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Das Kopieren und Einfügen des Codes ist nicht unmöglich, sollte aber mit Vorsicht behandelt werden. Abhängigkeiten wie Umgebung, Bibliotheken, Versionen usw. im Code stimmen möglicherweise nicht mit dem aktuellen Projekt überein, was zu Fehlern oder unvorhersehbaren Ergebnissen führt. Stellen Sie sicher, dass der Kontext konsistent ist, einschließlich Dateipfade, abhängiger Bibliotheken und Python -Versionen. Wenn Sie den Code für eine bestimmte Bibliothek kopieren und einfügen, müssen Sie möglicherweise die Bibliothek und ihre Abhängigkeiten installieren. Zu den häufigen Fehlern gehören Pfadfehler, Versionskonflikte und inkonsistente Codestile. Die Leistungsoptimierung muss gemäß dem ursprünglichen Zweck und den Einschränkungen des Codes neu gestaltet oder neu gestaltet werden. Es ist entscheidend, den Code zu verstehen und den kopierten kopierten Code zu debuggen und nicht blind zu kopieren und einzufügen.
 Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalte ich dynamische Daten von 58.com Arbeitsseite beim Kriechen? Wenn Sie eine Arbeitsseite von 58.com mit Crawler -Tools kriechen, können Sie auf diese begegnen ...
