

Erfahren Sie mehr über den Ereignisschleifenmechanismus in Nodejs

Dieser Artikel führt Sie durch den nodejsEvent-Loop-Mechanismus. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.

Verwandte Empfehlungen: „nodejs Tutorial“
Node.js verwendet ereignisgesteuerte und asynchrone E/A, um eine Single-Threaded-JavaScript-Laufzeitumgebung mit hoher Parallelität zu implementieren, und Single-Threading bedeutet nur eines kann gleichzeitig durchgeführt werden. Wie erreicht Node.js also eine hohe Parallelität und asynchrone E/A über einen einzelnen Thread? Dieser Artikel konzentriert sich auf dieses Problem, um das Single-Threaded-Modell von Node.js zu diskutieren.
Strategie für hohe Parallelität
Im Allgemeinen besteht die Lösung für hohe Parallelität darin, ein Multithreading-Modell bereitzustellen. Der Server weist für jede Clientanforderung einen Thread zu und verwendet synchrone E/A. Das System gleicht die synchrone E/A aus. O durch Thread-Wechsel. O Der Zeitaufwand für den Aufruf. Beispielsweise verfügt Apache über diese Strategie. Da E/A im Allgemeinen ein zeitaufwändiger Vorgang ist, ist es schwierig, mit dieser Strategie eine hohe Leistung zu erzielen, sie ist jedoch sehr einfach und kann eine komplexe Interaktionslogik implementieren.
Tatsächlich führt die Serverseite der meisten Websites nicht allzu viele Berechnungen durch. Nachdem sie die Anfrage erhalten haben, übergeben sie sie zur Verarbeitung (z. B. zum Lesen der Datenbank) und warten dann auf die Rückgabe des Ergebnisses Senden Sie abschließend die Ergebnisse an den Kunden. Daher verwendet Node.js ein Single-Thread-Modell, um dieser Tatsache gerecht zu werden. Es weist nicht jeder Zugriffsanforderung einen Thread zu, sondern verwendet einen Hauptthread, um alle Anforderungen zu verarbeiten, und verarbeitet die E/A-Vorgänge dann asynchron. , wodurch der Aufwand und die Komplexität vermieden werden, die zum Erstellen, Zerstören und Wechseln zwischen Threads erforderlich sind.
Ereignisschleife
Node.js verwaltet eine Ereigniswarteschlange im Hauptthread Wenn eine Anfrage eingeht, wird die Anfrage als Ereignis in diese Warteschlange gestellt und empfängt dann weiterhin andere Anfragen. Wenn der Hauptthread inaktiv ist (wenn keine Zugriffsanforderung vorliegt), beginnt er, die Ereigniswarteschlange zu zirkulieren und zu prüfen, ob sich in der Warteschlange Ereignisse befinden, die verarbeitet werden müssen. Es gibt zwei Situationen: Wenn es sich um einen Nicht-E/A-Thread handelt Behandeln Sie die Aufgabe persönlich und rufen Sie sie zurück. Wenn es sich um eine E/A-Aufgabe handelt, nehmen Sie einen Thread aus dem Thread-Pool, um das Ereignis zu verarbeiten, und geben Sie dann die Rückruffunktion an Durchlaufen Sie weiterhin andere Ereignisse in der Warteschlange.
Wenn die E/A-Aufgabe im Thread abgeschlossen ist, wird die angegebene Rückruffunktion ausgeführt und das abgeschlossene Ereignis wird am Ende der Ereigniswarteschlange platziert und wartet auf die Ereignisschleife, wenn der Hauptthread erneut eine Schleife zum Ereignis durchführt , wird es direkt verarbeitet und zum Aufruf der oberen Ebene zurückgekehrt. Dieser Prozess wird als Event Loop (Ereignisschleife) bezeichnet und sein Funktionsprinzip ist in der folgenden Abbildung dargestellt:
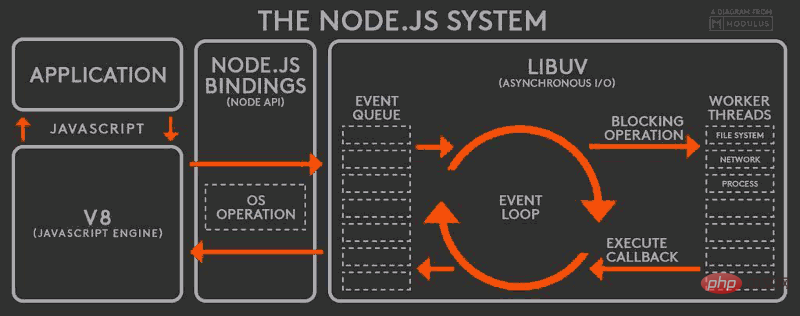
Diese Abbildung ist das Funktionsprinzip des gesamten Node.js, von links nach rechts, von oben nach unten, Node.js Es ist in vier Schichten unterteilt, nämlich Anwendungsschicht, V8-Engine-Schicht, Node-API-Schicht und LIBUV-Schicht.
Anwendungsschicht: Dies ist die JavaScript-Interaktionsschicht. Die häufigsten sind Node.js-Module wie http, fs
V8-Engine-Schicht: Sie verwendet die V8-Engine, um die JavaScript-Syntax zu analysieren, und interagiert dann mit der untere API
NodeAPI-Schicht: Bietet Systemaufrufe für Module der oberen Schicht, die normalerweise in der C-Sprache implementiert sind, um mit dem Betriebssystem zu interagieren.
LIBUV-Schicht: Es handelt sich um eine plattformübergreifende Kapselung auf unterster Ebene, die Ereignisschleifen, Dateioperationen usw. implementiert und den Kern der asynchronen Implementierung von Node.js bildet.
Ob es sich um eine Linux-Plattform oder eine Windows-Plattform handelt, Node.js führt intern asynchrone E/A-Vorgänge über den Thread-Pool aus und LIBUV implementiert einheitliche Aufrufe für die Unterschiede verschiedener Plattformen. Daher bedeutet Der einzelne Thread von Node.js nur, dass JavaScript in einem einzelnen Thread ausgeführt wird, nicht, dass Node.js ein einzelner Thread ist.
Arbeitsprinzip
Der Kern der asynchronen Implementierung von Node.js sind Ereignisse, das heißt, jede Aufgabe wird als „Ereignis“ behandelt und dann der asynchrone Effekt durch die Ereignisschleife simuliert, um genauer zu sein und klar Um diese Tatsache zu verstehen und zu akzeptieren, verwenden wir Pseudocode, um sein Funktionsprinzip zu beschreiben.
【1】Ereigniswarteschlange definierenDa es sich um eine Warteschlange handelt, handelt es sich um eine First-In-First-Out-Datenstruktur (FIFO). Wir verwenden ein JS-Array, um sie wie folgt zu beschreiben:
/** * 定义事件队列 * 入队:push() * 出队:shift() * 空队列:length == 0 */ globalEventQueue: []
Wir Verwenden Sie Arrays, um die Warteschlangenstruktur zu simulieren: Array Das erste Element des Arrays ist der Kopf der Warteschlange, das letzte Element des Arrays ist das Ende der Warteschlange, push() dient zum Einfügen eines Elements am Ende der Warteschlange. und Shift() soll ein Element aus dem Kopf der Warteschlange entfernen. Dies implementiert eine einfache Ereigniswarteschlange.
【2】Definition Anfrageeingang empfangenJede Anfrage wird abgefangen und in die Verarbeitungsfunktion eingegeben, wie unten gezeigt:
/**
* 接收用户请求
* 每一个请求都会进入到该函数
* 传递参数request和response
*/
processHttpRequest:function(request,response){
// 定义一个事件对象
var event = createEvent({
params:request.params, // 传递请求参数
result:null, // 存放请求结果
callback:function(){} // 指定回调函数
});
// 在队列的尾部添加该事件
globalEventQueue.push(event);
}这个函数很简单,就是把用户的请求包装成事件,放到队列里,然后继续接收其他请求。
【3】定义 Event Loop
当主线程处于空闲时就开始循环事件队列,所以我们还要定义一个函数来循环事件队列:
/**
* 事件循环主体,主线程择机执行
* 循环遍历事件队列
* 处理非IO任务
* 处理IO任务
* 执行回调,返回给上层
*/
eventLoop:function(){
// 如果队列不为空,就继续循环
while(this.globalEventQueue.length > 0){
// 从队列的头部拿出一个事件
var event = this.globalEventQueue.shift();
// 如果是耗时任务
if(isIOTask(event)){
// 从线程池里拿出一个线程
var thread = getThreadFromThreadPool();
// 交给线程处理
thread.handleIOTask(event)
}else {
// 非耗时任务处理后,直接返回结果
var result = handleEvent(event);
// 最终通过回调函数返回给V8,再由V8返回给应用程序
event.callback.call(null,result);
}
}
}主线程不停的检测事件队列,对于 I/O 任务,就交给线程池来处理,非 I/O 任务就自己处理并返回。
【4】处理 I/O 任务
线程池接到任务以后,直接处理IO操作,比如读取数据库:
/**
* 处理IO任务
* 完成后将事件添加到队列尾部
* 释放线程
*/
handleIOTask:function(event){
//当前线程
var curThread = this;
// 操作数据库
var optDatabase = function(params,callback){
var result = readDataFromDb(params);
callback.call(null,result)
};
// 执行IO任务
optDatabase(event.params,function(result){
// 返回结果存入事件对象中
event.result = result;
// IO完成后,将不再是耗时任务
event.isIOTask = false;
// 将该事件重新添加到队列的尾部
this.globalEventQueue.push(event);
// 释放当前线程
releaseThread(curThread)
})
}当 I/O 任务完成以后就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放当前线程,当主线程再次循环到该事件时,就直接处理了。
总结以上过程我们发现,Node.js 只用了一个主线程来接收请求,但它接收请求以后并没有直接做处理,而是放到了事件队列中,然后又去接收其他请求了,空闲的时候,再通过 Event Loop 来处理这些事件,从而实现了异步效果,当然对于IO类任务还需要依赖于系统层面的线程池来处理。
因此,我们可以简单的理解为:Node.js 本身是一个多线程平台,而它对 JavaScript 层面的任务处理是单线程的。
CPU密集型是短板
至此,对于 Node.js 的单线程模型,我们应该有了一个简单而又清晰的认识,它通过事件驱动模型实现了高并发和异步 I/O,然而也有 Node.js 不擅长做的事情:
上面提到,如果是 I/O 任务,Node.js 就把任务交给线程池来异步处理,高效简单,因此 Node.js 适合处理I/O密集型任务。但不是所有的任务都是 I/O 密集型任务,当碰到CPU密集型任务时,即只用CPU计算的操作,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),这时 Node.js 就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务就只能干等着 。如下图所示:
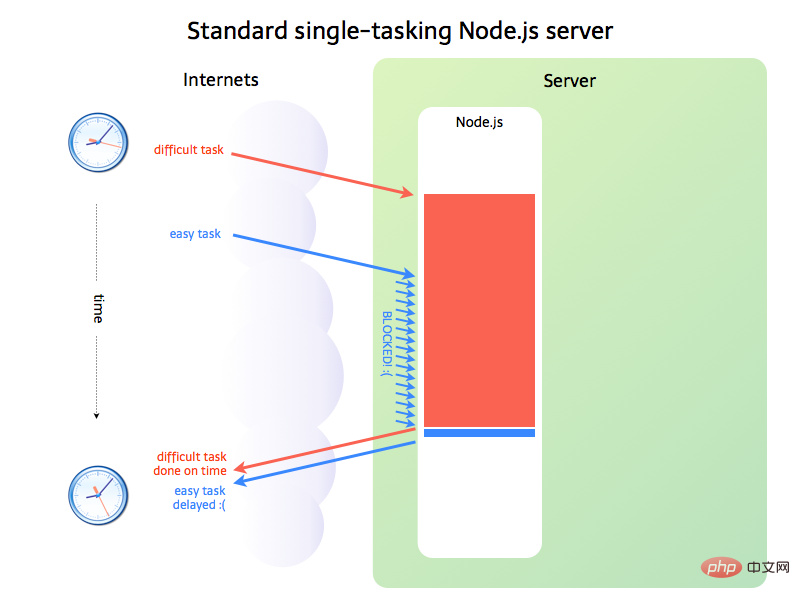
在事件队列中,如果前面的 CPU 计算任务没有完成,后面的任务就会被阻塞,出现响应缓慢的情况,如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多 CPU 或多核的,而 Node.js 只有一个 EventLoop,也就是只占用一个 CPU 内核,当 Node.js 被CPU 密集型任务占用,导致其他任务被阻塞时,却还有 CPU 内核处于闲置状态,造成资源浪费。
因此,Node.js 并不适合 CPU 密集型任务。
适用场景
RESTful API - 请求和响应只需少量文本,并且不需要大量逻辑处理, 因此可以并发处理数万条连接。
聊天服务 - 轻量级、高流量,没有复杂的计算逻辑。
更多编程相关知识,请访问:编程教学!!
Das obige ist der detaillierte Inhalt vonErfahren Sie mehr über den Ereignisschleifenmechanismus in Nodejs. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Der Unterschied zwischen NodeJS und VueJS
Apr 21, 2024 am 04:17 AM
Der Unterschied zwischen NodeJS und VueJS
Apr 21, 2024 am 04:17 AM
Node.js ist eine serverseitige JavaScript-Laufzeitumgebung, während Vue.js ein clientseitiges JavaScript-Framework zum Erstellen interaktiver Benutzeroberflächen ist. Node.js wird für die serverseitige Entwicklung verwendet, beispielsweise für die Entwicklung von Back-End-Service-APIs und die Datenverarbeitung, während Vue.js für die clientseitige Entwicklung verwendet wird, beispielsweise für Single-Page-Anwendungen und reaktionsfähige Benutzeroberflächen.
 Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Node.js kann als Backend-Framework verwendet werden, da es Funktionen wie hohe Leistung, Skalierbarkeit, plattformübergreifende Unterstützung, ein umfangreiches Ökosystem und einfache Entwicklung bietet.
 So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
Um eine Verbindung zu einer MySQL-Datenbank herzustellen, müssen Sie die folgenden Schritte ausführen: Installieren Sie den MySQL2-Treiber. Verwenden Sie mysql2.createConnection(), um ein Verbindungsobjekt zu erstellen, das die Hostadresse, den Port, den Benutzernamen, das Passwort und den Datenbanknamen enthält. Verwenden Sie „connection.query()“, um Abfragen durchzuführen. Verwenden Sie abschließend Connection.end(), um die Verbindung zu beenden.
 Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Die folgenden globalen Variablen sind in Node.js vorhanden: Globales Objekt: global Kernmodul: Prozess, Konsole, erforderlich Laufzeitumgebungsvariablen: __dirname, __filename, __line, __column Konstanten: undefiniert, null, NaN, Infinity, -Infinity
 Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Es gibt zwei npm-bezogene Dateien im Node.js-Installationsverzeichnis: npm und npm.cmd. Die Unterschiede sind wie folgt: unterschiedliche Erweiterungen: npm ist eine ausführbare Datei und npm.cmd ist eine Befehlsfensterverknüpfung. Windows-Benutzer: npm.cmd kann über die Eingabeaufforderung verwendet werden, npm kann nur über die Befehlszeile ausgeführt werden. Kompatibilität: npm.cmd ist spezifisch für Windows-Systeme, npm ist plattformübergreifend verfügbar. Nutzungsempfehlungen: Windows-Benutzer verwenden npm.cmd, andere Betriebssysteme verwenden npm.
 Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Die Hauptunterschiede zwischen Node.js und Java sind Design und Funktionen: Ereignisgesteuert vs. Thread-gesteuert: Node.js ist ereignisgesteuert und Java ist Thread-gesteuert. Single-Threaded vs. Multi-Threaded: Node.js verwendet eine Single-Threaded-Ereignisschleife und Java verwendet eine Multithread-Architektur. Laufzeitumgebung: Node.js läuft auf der V8-JavaScript-Engine, während Java auf der JVM läuft. Syntax: Node.js verwendet JavaScript-Syntax, während Java Java-Syntax verwendet. Zweck: Node.js eignet sich für I/O-intensive Aufgaben, während Java für große Unternehmensanwendungen geeignet ist.
 Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ja, Node.js ist eine Backend-Entwicklungssprache. Es wird für die Back-End-Entwicklung verwendet, einschließlich der Handhabung serverseitiger Geschäftslogik, der Verwaltung von Datenbankverbindungen und der Bereitstellung von APIs.
 So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
Serverbereitstellungsschritte für ein Node.js-Projekt: Bereiten Sie die Bereitstellungsumgebung vor: Erhalten Sie Serverzugriff, installieren Sie Node.js, richten Sie ein Git-Repository ein. Erstellen Sie die Anwendung: Verwenden Sie npm run build, um bereitstellbaren Code und Abhängigkeiten zu generieren. Code auf den Server hochladen: über Git oder File Transfer Protocol. Abhängigkeiten installieren: Stellen Sie eine SSH-Verbindung zum Server her und installieren Sie Anwendungsabhängigkeiten mit npm install. Starten Sie die Anwendung: Verwenden Sie einen Befehl wie node index.js, um die Anwendung zu starten, oder verwenden Sie einen Prozessmanager wie pm2. Konfigurieren Sie einen Reverse-Proxy (optional): Verwenden Sie einen Reverse-Proxy wie Nginx oder Apache, um den Datenverkehr an Ihre Anwendung weiterzuleiten
