


Kostenlose Lernempfehlung: MySQL-Datenbank (Video)
Hintergrund
Alibaba Cloud RDS FÜR MySQL (MySQL Version 5. 7) Datenbank-Geschäftstabellen werden jeden Monat hinzugefügt Da die Datenmenge weiterhin zunimmt, kommt es in unserem Unternehmen zu langsamen Abfragen in großen Tabellen. In Spitzenzeiten dauern langsame Abfragen in der Hauptgeschäftstabelle Dutzende von Sekunden, was erhebliche Auswirkungen auf das Geschäft hat Überblick über die Lösung
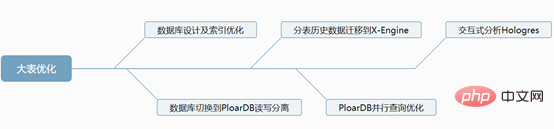 1. Datenbankdesign und Indexoptimierung
1. Datenbankdesign und Indexoptimierung
Die MySQL-Datenbank selbst ist sehr flexibel, was zu einer unzureichenden Leistung führt und stark von den Tabellendesignfunktionen und Indexoptimierungsfunktionen des Entwicklers abhängig ist. Hier sind einige Optimierungsvorschläge
Konvertieren Sie den Zeittyp in das Zeitstempelformat, verwenden Sie den Typ int zum Speichern und Erstellen des Index, um die Abfrageeffizienz zu erhöhen
In gemischten Offline-Szenarien: Verschiedene Dienste verwenden unterschiedliche Verbindungsadressen und verwenden unterschiedliche Datenknoten, um gegenseitige Beeinflussung zu vermeiden
PloarDB 8-Core 32G 2 EinheitenDie geteilte Geschäftstabelle speichert 3 Monate an Daten (dies basiert auf den Unternehmensanforderungen) und historische Daten werden monatlich in historische Datenbank-X-Engine-Speicher-Engine-Tabellen aufgeteilt. Warum sollten wir uns für X-Engine-Speicher-Engine-Tabellen entscheiden? sind seine Vorteile?
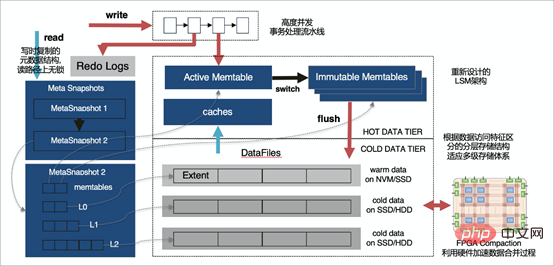
Die X-Engine-Speicher-Engine ist nicht nur nahtlos mit MySQL kompatibel (dank der MySQL Pluginable Storage Engine-Funktion), sondern X-Engine verwendet auch eine mehrschichtige Speicherarchitektur. Da das Ziel darin besteht, umfangreiche Datenmengen zu speichern, eine hohe Fähigkeit zur gleichzeitigen Transaktionsverarbeitung bereitzustellen und die Speicherkosten zu senken, sind in den meisten Szenarien mit großem Datenvolumen die Möglichkeiten für den Datenzugriff ungleichmäßig, und häufig abgerufene Hot-Daten sind tatsächlich dafür verantwortlich Sehr selten unterteilt X-Engine die Daten entsprechend der Häufigkeit des Datenzugriffs in mehrere Ebenen, entwirft die entsprechende Speicherstruktur und schreibt sie auf das entsprechende Speichergerät
4. Parallele Abfrage der Alibaba Cloud PloarDB MySQL8.0-Version
Nach der Aufteilung der Tabellen ist unser Datenvolumen immer noch sehr groß, was unser langsames Abfrageproblem nicht vollständig löst, sondern nur die Größe verringert unserer Geschäftstabellen Für diesen Teil der langsamen Abfrage müssen wir die parallele Abfrageoptimierung von PolarDB verwenden.
PolarDB MySQL 8.0 startet das parallele Abfrage-Framework automatisch gestartet, wodurch die Abfrage zeitaufwändig wird.
In der Speicherschicht werden die Daten in mehrere Threads fragmentiert und die Ergebnispipeline wird im Hauptthread zusammengefasst Einfache Zusammenführung und Rückgabe an den Benutzer, um die Abfrageeffizienz zu verbessern.
Parallel Query nutzt die Parallelverarbeitungsfähigkeiten von Multi-Core-CPUs. Am Beispiel der 8-Core-32-GB-Konfiguration sieht das schematische Diagramm wie folgt aus.
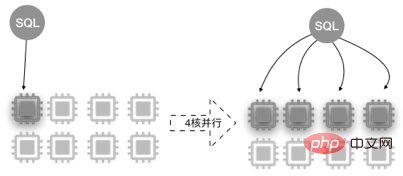
Parallele Abfragen eignen sich für die meisten SELECT-Anweisungen, z. B. große Tabellenabfragen, Verknüpfungsabfragen mit mehreren Tabellen und Abfragen mit großer Berechnungslast. Bei sehr kurzen Abfragen ist der Effekt weniger spürbar.
Parallele Abfragenutzung: Sie können die Hint-Syntax verwenden, um eine einzelne Anweisung zu steuern. Wenn das System beispielsweise parallele Abfragen standardmäßig deaktiviert, Sie aber eine hochfrequente langsame SQL-Abfrage beschleunigen müssen, können Sie Hint zur Beschleunigung verwenden spezifisches SQL erstellen.
SELECT /+PARALLEL(x)/ … FROM …; – x >0
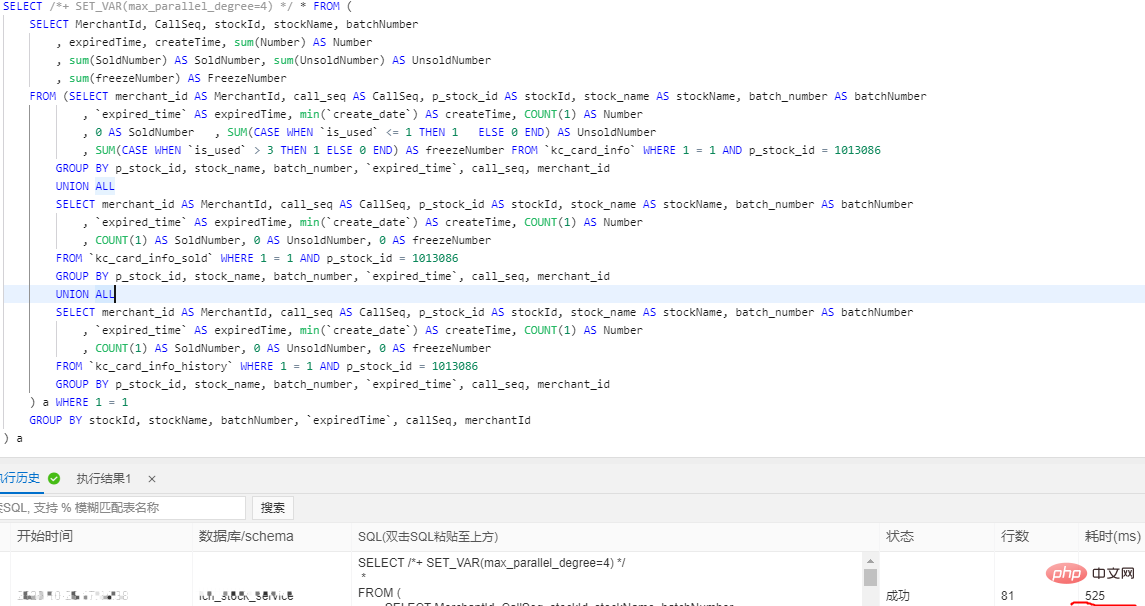
SELECT /*+ SET_VAR(max_parallel_degree=n) */ * FROM … // n > Bei der Konfiguration von 16 Kernen und 32G übersteigt das Datenvolumen einer einzelnen Tabelle 30 Millionen.
Vor dem Hinzufügen der parallelen Abfrage waren es 4326 ms und nach dem Hinzufügen waren es 525 ms. Die Leistung stieg um das 8,24-fache. 5 .Interaktive Analyse Hologre
Obwohl wir die Effizienz langsamer Abfragen in großen Tabellen mithilfe der parallelen Abfrageoptimierung verbessern, können wir einige spezifische Anforderungen für Echtzeitberichte und Echtzeit-Großbildschirme immer noch nicht erfüllen und können uns nur darauf verlassen Big Data, um sie zu verarbeiten. Hier empfehlen wir die interaktive Analyse Hologre von Alibaba Cloud ( https://help.aliyun.com/product/113622.html)
https://help.aliyun.com/product/113622.html)
6. Postscript
Die Optimierung von zig Millionen großen Tabellen basiert auf Geschäftsszenarien werden auf Kosten der Kosten optimiert. Eine horizontale Aufteilung und Erweiterung der Datenbank ist in vielen Fällen möglicherweise nicht gut Datenbankdesign, Indexoptimierung und Tabellenpartitionierungsstrategien sind Sobald dies erledigt ist, sollten Sie die geeignete Technologie auswählen, um es basierend auf den Geschäftsanforderungen zu implementieren.
Weitere verwandte kostenlose Lernempfehlungen: MySQL-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonVorstellung der MySQL-Lösung zur Optimierung großer Tabellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



