

Detaillierte Erläuterung der Python-Listen


Empfohlenes kostenloses Lernen: Python-Video-Tutorial
Python: Liste
- 1. Sequenz
- 1.1. Grundkonzepte
- 1.2. Index
- 1.3、 Praktische Anwendung
- 2. Liste (Liste)
-
- 2.1. Das Konzept der Liste
- 3. Das Konzept des Schneidens
- 3.2. Grammatik
3.3. Praktische Anwendung - 4.1 Bedienung und Anweisungen
- 4.2 Praktische Anwendung
- 5. Änderungsliste
5.2 , Slice-Modifikation- 5.3. die Liste
- 6.2.1, Sortieren
7, Ergänzung zur bedingten Anweisung (for-Schleife)-
- 7.1, Grundkonzepte
- 7.2, for-Schleifensyntax
- 7.2 Verwendung des Bereichs
8. Hausaufgaben nach der Schule -
- 8.1. Jetzt gibt es a = [1,2,3,4,5,6]. ,1]) und notieren Sie den Ableitungsprozess
- 8.2 Geben Sie dem Benutzer 9 Chancen, 1 - 10 Zahlen zufällig zu erraten, um die Zahl zu erraten.
- 8.3. Es gibt zwei Listen lst1 = [11, 22, 33] lst2 = [22, 33, 44], um Elemente mit dem gleichen Inhalt zu erhalten
- 8.4 Es sind jetzt 8 Lehrer und 3 Büros erforderlich Kombinieren Sie 8 Lehrer, die zufällig drei Büros zugewiesen werden 1/99 – Der Wert von 1/100
- 9,2. Berechnen Sie die Summe der folgenden Sequenz. 1/3+3/5+5/7+....+97/99
- 9,3. Geben Sie 2 Werte ein, bestimmen Sie, wie viele Primzahlen dazwischen liegen, und geben Sie alle Primzahlen aus
- Der Index der Sequenz wurde bereits im
String Slicingdes vierten Blogs erwähnt, da er sehr wichtig ist ., wichtig, wichtig, sehr wichtige Dinge sollten dreimal gesagt werden. Interessierte Freunde können auf den Blog-Link klicken, um einen Blick darauf zu werfen. Natürlich geht es in diesem Artikel auch um Slicing-Listen - Sequenz ist die grundlegendste Datenstruktur in Python.
- Der Index der Sequenz wurde bereits im
- Sequenz wird verwendet, um
einen Satz geordneter Datenzu speichern. Alle Daten haben eine eindeutige Position (Index) in der Sequenz und den Daten in der Sequenz wird in der Reihenfolge der Addition ein Index zugewiesen Eine Sequenz ist eine
Datenstruktur, die als Container bezeichnet wird. Sequenzen (zum Beispiel: Listen, Tupel) und Karten (zum Beispiel: Wörterbücher) Jedes Element in einer Sequenz hat eine Nummer, während jedes Element in einer Karte einen Namen (Schlüssel) hat und eine Sammlung ist weder ein Container vom Sequenztyp noch ein zugeordneter Typ. <li> Sequenzen können einige spezielle Operationen ausführen: Indizierung, Slicing, Addition, Multiplikation und Prüfung, ob ein Element zur Sequenz gehört. Darüber hinaus kann Python auch die Länge einer Sequenz berechnen und die integrierten Funktionen der Maximalfunktion und der Minimalfunktion finden. <ul>
<li>
<li>Datenstruktur bezieht sich auf die Art und Weise, wie Daten in einem Computer gespeichert werden <li>
<li>Klassifizierung von Sequenzen: </ul>
</li>
<li>Variable Sequenz (Elemente in der Sequenz können sich ändern): wie Liste (Liste) </li>
<li>Unveränderliche Sequenz ( in der Reihenfolge Die Elemente können nicht geändert werden): Zum Beispiel String (str) Tupel (Tupel) <ul>
<li>
<li>
<li>1.2, Index </li>
</ul>
</li>
Hier zeigen wir den Index einer Liste, zum Beispiel Array a=['a','b','c','d','e','f','g','h ', 'i']
'a'
字符串切片中有说到过,这里再次提一下,因为它很重要,重要,重要,很重要的事情要说3遍嘛。博客链接,感兴趣的朋友可以点过去看看,当然,本篇中也讲述了列表的切片哦
1.1、基本概念
- 序列是Python中最基本的一种数据结构。
序列用于保存
一组有序的数据,所有的数据在序列当中都有一个唯一的位置(索引)并且序列中的数据会按照添加的顺序来分配索引
序列就是名为容器的数据结构。序列(例如:列表,元组)和映射(例如:字典),序列中的每个元素都有一个编号,而映射中的每个元素都有一个名字(键),而集合既不是序列类型的容器也不是映射的类型。
序列可以一些特殊的操作:索引,分片,加,乘,检查某个元素是否属于序列。除此之外python还可以计算序列的长度,找出最大函数和最小函数的内建函数。
数据结构指计算机中数据存储的方式
-
序列的分类:
- 可变序列(序列中的元素可以改变):例如 列表(list)
- 不可变序列(序列中的元素不能改变):例如 字符串(str)元组(tuple)
1.2、索引
数组索引,数组索引机制指的是用方括号([])加序号的形式引用单个数组元素,它的用处很多,比如抽取元素,选取数组的几个元素,甚至为其赋一个新值。
'b'
这里拿一个列表的索引展示一下,例如数组a=['a','b','c','d','e','f','g','h','i']
| 'e' | 'f | 'g ' | 'h' | 'i' | Zahl (positive Sequenz) | 0 | 1 | |||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 5 | 6 | 7 | 8 | Nummer (umgekehrte Reihenfolge) | -9 | -8 | -7 | ||||||||||||||||||||||||||||||||||
| -5 | -4 | -3 | -2 | -1 |
| * | |
|
in |
|
| nicht in | |
| len() | |
| max() | |
| min() | |
| list.index(x[, start[, end]]) | |
| Liste flacher Kopien |
| cmp( list1, list2)
| vergleicht die Elemente zweier Listen |
| 方法 | 说明 |
|---|---|
| append() | 像列表的最后添加一个元素 |
| insert(arg1,arg2) | 像列表指定位置插入一个元素 参数1:要插入的位置 参数2:要插入的元素 |
| extend(iterable) | 使用一个新的序列来扩展当前序列 (它会将该序列的中元素添加到列表中) 参数需要传递 |
| pop() | 根据索引删除并返回指定元素 |
| remove() | 删除指定元素 (如果相同值的元素有多个,只会删除第一个) |
| reverse() | 翻转列表 |
| sort(key=None,reverse=False) | 用来对列表中的元素进行排序 reverse:True反序;False 正序 |
6.2 实际运用
6.2.1、添加方法
- append()
# list.append() 向类表中最后的位置插入一个元素
a = ['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬']
a.append('凯')
print(a)
# 运行结果 》》》['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬', '凯']- insert(arg1,arg2)
# list.insert() 向列表中的指定位置插入一个元素,第一个参数是要插入的位置,第二个参数是要插入的内容 a = ['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬'] a.insert(4, '亚瑟') print(a) # 运行结果 》》》['孙悟空', '猪八戒', '鲁班', '露娜', '亚瑟', '安琪拉', '虞姬']
- extend(iterable)
# list.extend() 使用新的序列来扩展当前序列,就是添加多个元素 a = ['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬'] a.extend(['亚瑟', '凯']) print(a) # 运行结果 》》》['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬', '亚瑟', '凯']
6.2.2、删除方法
- pop()
# list.pop() 根据索引删除并返回元素, 如果不传递索引,默认删除最后一个 a = ['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬'] a = a.pop() print(a) 运行结果 》》》虞姬
- remove()
# list.remove() 删除指定的元素
a = ['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬']
a.remove('鲁班')
print(a)
运行结果 》》》['孙悟空', '猪八戒', '露娜', '安琪拉', '虞姬']6.2.4、反转列表
- reverse()
a = ['孙悟空', '猪八戒', '鲁班', '露娜', '安琪拉', '虞姬'] a.reverse() print(a) 运行结果 》》》['虞姬', '安琪拉', '露娜', '鲁班', '猪八戒', '孙悟空']
6.2.1、排序
- sort(key=None,reverse=False)
# list.sort() 默认是正序排序 他有一个参数reverse a = [4,5,2,7,1,0,5,8] a.sort(reverse=True) print(a) 运行结果 》》》[8, 7, 5, 5, 4, 2, 1, 0]
7、对条件语句的补充(for循环)
7.1、基本概念
for 语句是 Python 中执行迭代的两个语句之一,另一个语句是 while。while在之前的博客里有讲过,这里我们补充介绍一下for循环的用法。
Python 中,for 循环用于遍历一个迭代对象的所有元素。循环内的语句段会针对迭代对象的每一个元素项目都执行一次。这里我们用的迭代对象就是列表和range。
7.2、for 循环语法
- 字符串
for i(迭代变量) in 'Python': 循环体
- range
for i(迭代变量) in range(1,9): 循环体
- 序列
for i(迭代变量) in 序列(遍历的规则): 循环体
7.2 range的用法
- for 迭代变量 in range ( i, j [,k ]):
参数说明:
这个也是左闭右开区间,所以终止值不可取
i: 初始值(默认为‘0’)
j: 终止值(默认为‘1’)
k: 步长值,即每次重复操作时比上一次操作所增长的数值。(默认为‘1’)
执行过程:
第一步:将 i 值传递给 ‘迭代变量’,然后执行一次内部语句;
第二步:在 i 的基础上 + k 再次传递给 ‘迭代变量’,如果 ‘迭代变量’ 的值小于 ‘j’ 的值,则再次执行内部语句,否则退出for循环。
详情如下:
for i in range(9): print(i)
运行结果如图;
8、课后作业

8.1、 现在有 a = [1,2,3,4,5,6] 用多种方式实现列表的反转([6,5,4,3,2,1]) 并写出推导过程
# 第一种方法,使用append a = [1,2,3,4,5,6] b = [] for i in a: b.append(a[6-i]) print(b) # 第二种方法,切片的运用 a = [1,2,3,4,5,6] print(a[::-1]) # 第三种方法,反转列表 a = [1,2,3,4,5,6] a.reverse() print(a) # 第四种方法,排序 a = [1,2,3,4,5,6] a.sort(reverse=True) print(a)
运行结果如下:

知识点运用及编写思路:
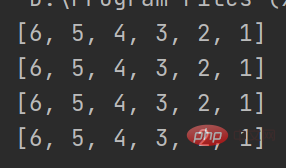
第一种方法用到了列表方法append和for循环的配合,每一次运行都将列表a中的值添加给b,达到逆序的效果。
第二种方法是切片的逆序打印,详情可以看上面切片的介绍及运用。
第三种和第四张方法都是列表方法的运用,不过第三种不管里面的元素是什么类型的都可以逆序打印,但第四张只能针对像这种原本就是元素从小到大的列表,其他的就达不到逆序的效果。
8.2、给用户9次机会 猜1 - 10 个数字随机来猜数字。
# 第一种
list1 = [1,2,3,4,5,6,7,8,9,10]
list2=[]
print('现在我们来猜数字,给你9次机会哦')
for i in range(1,10):
a = int(input('请输入1 - 10中的数字:'))
if a in list1:
print(f'你猜错啦,不是{a}')
list2.append(a)
else:
print('哎呀,要猜1到10内的数字哦!!!')
continue
else:
for a in list1:
if a not in list2:
d = a
print(f'哈哈哈,你9次都没猜对哦!!!应该是{d}才对哦!')
# 第二种
list1 = [1,2,3,4,5,6,7,8,9,10]
list2=[]
print('现在我们来猜数字,给你9次机会哦')
i=1
while i- 运行结果如下(最终方法的运行)
- 知识点运用及编写思路:
这3种方法也是循序渐进的,由
Cheney老师以及群里的各位大佬指点改进的
第一种方法中规中矩,就是利用for循环,循环9次,让用户每次都猜一次,我们就将用户猜的值添加给列表list2,最后9次循环之后将list1与list2的值进行判断,最后输出用户没有猜到的值。
第二种方法就是再第一题的基础上加上了判断,限定用户必须猜1~10之间的数字。
上述的2种方法也能达到效果,但是还是不够简便,所以在听取了群里的大佬西安聂泽雨的意见后改的,使用remove方法将用户猜的数字都从列表中删除,这样就能达到与上面2种方法相同的效果,也简化了代码。
在此,还要非常感谢一下Cheney老师以及群里的大佬的指点与帮助,让我学习到了更多的代码知识以及思路。学无止境,希望各位再观看完我的博客后,能给我的不足地方指出,谢谢。
- 下面是我原本写的,解题思路稍微有点偏差,也可以借鉴一下的
- 让用户9次都猜不对,前2种方法都有一点点问题,可以结合第三种一起理解一下
# 让用户9次都猜不对,然后每一次都输出一个值
# 第一种方法
list1 = [1,2,3,4,5,6,7,8,9,10]
for i in range(1,10):
a = int(input('请输入1 - 10中的数字:'))
b = list1[a+1]
print(f'你猜错啦,应该是{b}才对哦!')
else:
print('哈哈哈,你9次都没猜对哦!!!')
# 第二种方法
list1 = [1,2,3,4,5,6,7,8,9,10]
i=1
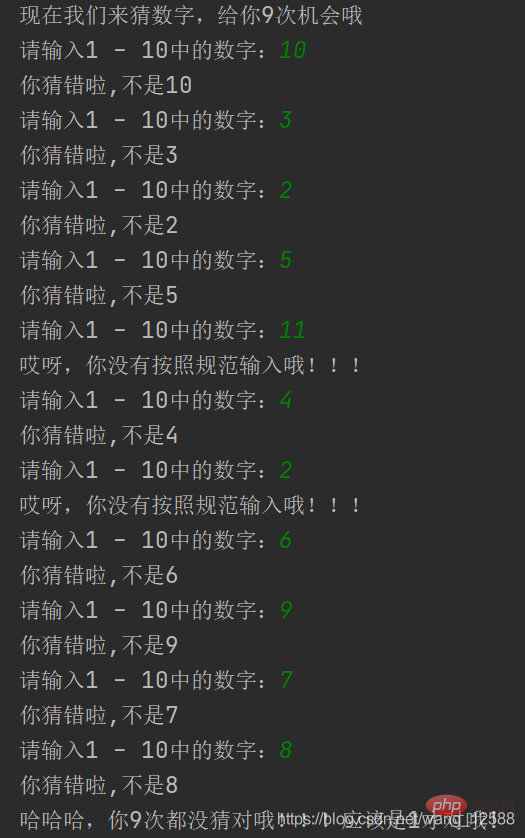
while i=1 and a运行结果如下(这里只展示第3种方法的效果,还有2种也差不多):
知识点运用及编写思路:

此代码是我在理解错题目意思后写的,让用户9次都猜不对,每一次都输出一个数字。
这里我写了3种方法,思路是循序渐进的,应该更好理解。
首先我们第一种方法用到的就是for循环和列表的运用,先创建一个列表,里面的元素就是1~10的数字,然后不管用户输入什么数字,我这边都加上2输出,这里因为索引是从0开始,所以list1[a+1]就能达到这种效果,但是我发现这个方法又不足,先不说,我们输出的数字不随机,再有就是我不管输入什么数字都行,缺少了一个判断,所以我又进行了更改
第二种方法我就在第一种方法加上了if判断,但是我这个时候又遇到一个问题,如果接着用for循环,就算我输不是1 ~ 10 内的数字,然后他总的循环只能有9次,所以不符合我的预期效果,这个时候我想到了while循环,并将其添加进去,这时我就限定了用户只能输入1 ~ 10内的数字。
第三种方法,是我想让我们输出的数字也随机,这是我想到了random模块,使用这个模块不就能随机了能生成随机数了嘛,但是我又想到这个还有一个问题,就是他有很大概率让用户懵中,所以我这又给他加了个循环,使其就算猜中了也没用,猜中我就换一个随机数就好了。最后的效果就如上图了。
8.3、有两个列表 lst1 = [11, 22, 33] lst2 = [22, 33, 44]获取内容相同的元素
# 第一种方法 while循环 lst1 = [11, 22, 33] lst2 = [22, 33, 44] a = 0 c = '相同的元素为:' while a
- 运行结果如下:
- 知识点运用及编写思路:
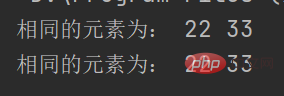
这题比较容易,获取2个列表相同的元素,我们只要用一下循环嵌套就好了,外循环和内循环都是循环3次,外循环就是lst1的元素数量,内循环是lst2的元素数量,之后那list1的每一个元素都与list2的元素一一对比判断就行了,相同的复制给c,最后直接输出c即可。
8.4、现在有8位老师,3个办公室,要求将8位老师随机的分配到三个办公室中
# 第一种方法 while循环 import random a = 1 while a
运行结果如下:
知识点运用及编写思路:

这题说白了就是random模块与循环之间的使用,将老师的数量作为迭代变量,也就是循环的次数,然后使用random模块生产随机的1~3之间的数字,然后就是输出啦。

9、附加(个人代码练习)
9.1、求1/1-1/2+1/3-1/4+1/5 …… + 1/99 - 1/100的值
# 求1/1-1/2+1/3-1/4+1/5 …… + 1/99 - 1/100的值
# while循环
i=1
sum=0
while i<blockquote><p>运行结果:<br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/035db9fe0baa39f789db2df222f2d9f8-10.png" class="lazy" alt="Detaillierte Erläuterung der Python-Listen"></p></blockquote><p><strong>9.2、计算下面数列的和值。 1/3+3/5+5/7+…+97/99</strong></p><pre class="brush:php;toolbar:false"># 计算下面数列的和值。 1/3+3/5+5/7+....+97/99
# while循环
i,j,sum = 1,3,0
while i<blockquote><p>运行结果:<br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/035db9fe0baa39f789db2df222f2d9f8-11.png" class="lazy" alt="Detaillierte Erläuterung der Python-Listen"></p></blockquote><p><strong>9.3、 输入2个数值,判断之间有多少个素数,并输出所有素数</strong></p><pre class="brush:php;toolbar:false"># 输入2个数值,判断之间有多少个素数,并输出所有素数
c=[int(input('输入第一个数:')),int(input('输入第二个数:'))]
c.sort(reverse=False) #保证2个数以升序方式排列
a,b=c[0],c[1]
while a <blockquote><p>运行结果:<br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/035db9fe0baa39f789db2df222f2d9f8-12.png" class="lazy" alt="Detaillierte Erläuterung der Python-Listen"></p></blockquote><blockquote><p><strong>相关免费学习推荐:</strong><a href="https://www.php.cn/course/list/30.html" target="_blank"><strong>python教程</strong></a><strong>(视频)</strong></p></blockquote>Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Python-Listen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Bei der Verwendung von Pythons Pandas -Bibliothek ist das Kopieren von ganzen Spalten zwischen zwei Datenrahmen mit unterschiedlichen Strukturen ein häufiges Problem. Angenommen, wir haben zwei Daten ...
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?
Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?
Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?
Apr 02, 2025 am 07:15 AM
Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?
Apr 02, 2025 am 07:15 AM
Wie kann man nicht erkannt werden, wenn Sie Fiddlereverywhere für Man-in-the-Middle-Lesungen verwenden, wenn Sie FiddLereverywhere verwenden ...
 Was sind reguläre Ausdrücke?
Mar 20, 2025 pm 06:25 PM
Was sind reguläre Ausdrücke?
Mar 20, 2025 pm 06:25 PM
Regelmäßige Ausdrücke sind leistungsstarke Tools für Musteranpassung und Textmanipulation in der Programmierung, wodurch die Effizienz bei der Textverarbeitung in verschiedenen Anwendungen verbessert wird.
 Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen an? Uvicorn ist ein leichter Webserver, der auf ASGI basiert. Eine seiner Kernfunktionen ist es, auf HTTP -Anfragen zu hören und weiterzumachen ...
 Was sind einige beliebte Python -Bibliotheken und ihre Verwendung?
Mar 21, 2025 pm 06:46 PM
Was sind einige beliebte Python -Bibliotheken und ihre Verwendung?
Mar 21, 2025 pm 06:46 PM
In dem Artikel werden beliebte Python-Bibliotheken wie Numpy, Pandas, Matplotlib, Scikit-Learn, TensorFlow, Django, Flask und Anfragen erörtert, die ihre Verwendung in wissenschaftlichen Computing, Datenanalyse, Visualisierung, maschinellem Lernen, Webentwicklung und h beschreiben
 Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstellt in Python ein Objekt dynamisch über eine Zeichenfolge und ruft seine Methoden auf? Dies ist eine häufige Programmieranforderung, insbesondere wenn sie konfiguriert oder ausgeführt werden muss ...
