

Empfohlen (kostenlos): Redis-Einführungs-Tutorial
1. Große Chancen im Internetzeitalter, warum NoSQL verwenden? 1.1 Die gute Ära des eigenständigen MySQL In den 1990er Jahren ist die Anzahl der Besuche auf einer Website im Allgemeinen nicht groß und kann problemlos von einer einzigen Datenbank verarbeitet werden. Zu dieser Zeit waren die meisten davon statische Webseiten und es gab nicht viele dynamische interaktive Websites.
DAL dal ist die englische Abkürzung für Data Access Layer, also Data Access Layer
Werfen wir unter der oben genannten Architektur einen Blick auf die Engpässe bei der Datenspeicherung? 1. Die Gesamtgröße des Datenvolumens pro Maschine Wenn es nicht passt
2. Wenn der Datenindex (B+ Baum) nicht im Speicher einer Maschine gespeichert werden kann
3. Die Zugriffsmenge (gemischtes Lesen und Schreiben) kann von einer Instanz nicht toleriert werden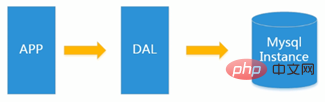 Wenn 1 oder 3 von Die oben genannten Punkte sind erfüllt, entwickeln sich weiter ...
Wenn 1 oder 3 von Die oben genannten Punkte sind erfüllt, entwickeln sich weiter ...
1.2.Memcached (Cache) + MySQL + vertikale Aufteilung
Später, mit der Zunahme der Besuche, traten bei fast den meisten Websites, die die MySQL-Architektur verwendeten, Leistungsprobleme in der Datenbank auf Programme konzentrieren sich nicht mehr nur auf Funktionen, sondern auch auf das Streben nach Leistung.
Programmierer begannen, Caching-Technologie in großem Umfang einzusetzen, um den Druck auf die Datenbank zu verringern und die Struktur und den Index der Datenbank zu optimieren
Memcached natürlich zu einem sehr modischen Technologieprodukt geworden.
Dies entspricht dem direkten Zugriff der vorherigen Dao-Schicht auf die Datenbank, und jetzt wird in der Mitte eine Cache-Schicht eingefügt. Häufige Datenbankzugriffe führen zu Leistungseinbußen. Daher legen wir einen Teil des Inhalts im Cache ab, um den Druck zu verringern. 1.3. MySQL-Master-Slave-Lese- und SchreibtrennungAufgrund des erhöhten Schreibdrucks auf die Datenbank kann
Memcached nur den Lesedruck auf die Datenbank verringern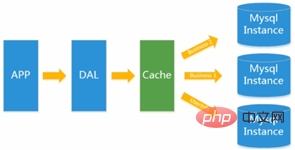 . Die Konzentration des Lesens und Schreibens auf eine Datenbank führt dazu, dass die Datenbank überlastet wird.
. Die Konzentration des Lesens und Schreibens auf eine Datenbank führt dazu, dass die Datenbank überlastet wird.
Die meisten Websites haben begonnen, Master-Slave-Replikationstechnologie zu verwenden, um Lesen und Schreiben zu trennen, um die Lese- und Schreibleistung und die Skalierbarkeit von Lesedatenbanken zu verbessern. „Der Master-Slave-Modus von MySQL“ ist derzeit zum Standard für Websites geworden.
Erläuterung: In der Hauptbibliothek findet eine Datensatzaktualisierung statt. Um die Integrität der Daten sicherzustellen, müssen diese in die Slave-Bibliothek kopiert werden. Lese- und Schreibtrennung: Master/Slave. Wir können Schreiboperationen in der Master-Bibliothek und Leseoperationen in der Slave-Bibliothek platzieren.
1.4. Geteilte Tabellen und Datenbanken + horizontale Aufteilung + MySQL-Cluster Basierend auf dem Cache von Memcached, der Master-Slave-Replikation und der Lese-Schreib-Trennung Zu diesem Zeitpunkt beginnt der Schreibdruck der MySQL-Hauptdatenbank Es gibt einen Engpass und die Datenmenge steigt weiter an. Da MyISAM Tabellensperren verwendet, treten bei hoher Parallelität schwerwiegende Sperrprobleme auf
und eine große Anzahl von MySQL-Anwendungen mit hoher Parallelität haben begonnen, die InnoDB-Engine anstelle von MyISAM zu verwenden . 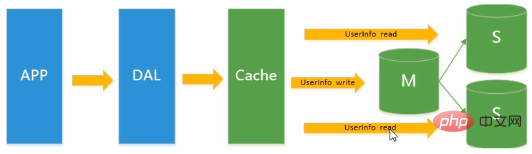 Gleichzeitig
Gleichzeitig
ist es populär geworden, Untertabellen und Unterdatenbanken zu verwenden, um Schreibdruck und Erweiterungsprobleme des Datenwachstums zu lindern
Tabellensperren und Zeilensperren?
Unterbibliothek und Untertabelle 1-3000 betreten die Bibliothek Nr. 1. 3001-6000 gehen in Lager 2. Warten Sie1.5. MySQL-Skalierbarkeitsengpass
MySQL-Datenbank speichert auch oft einige große Textfelder, was zu sehr großen Datenbanktabellen führt, was die Datenbankwiederherstellung sehr langsam macht und es schwierig macht, die Datenbank schnell wiederherzustellen. Beispielsweise sind 10 Millionen 4-KB-Texte fast 40 GB groß. Wenn diese Daten in MySQL weggelassen werden können, wird MySQL sehr klein. Relationale Datenbanken sind leistungsstark, können jedoch nicht alle Anwendungsszenarien bewältigen. MySQL weist eine schlechte Skalierbarkeit auf (erfordert komplexe Technologie zur Implementierung), einen hohen E/A-Druck bei großen Datenmengen und Schwierigkeiten beim Ändern der Tabellenstruktur. Dies sind die Probleme, mit denen Entwickler derzeit konfrontiert sind, wenn sie MySOL verwenden.
1.6. Wie sieht es heute aus?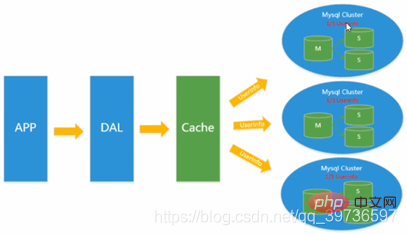
Firewall-Nginx-Tomcat-Cluster
1.7. Warum NoSQL verwenden?Heute können wir über Drittplattformen (wie Google, Facebook usw.) problemlos auf Daten zugreifen und diese erfassen. Persönliche Informationen der Benutzer, soziale Netzwerke, geografische Standorte, benutzergenerierte Daten und Benutzerbetriebsprotokolle haben exponentiell zugenommen. Wenn wir diese Benutzerdaten schürfen möchten, sind SQL-Datenbanken für diese Anwendungen nicht mehr geeignet. Die Entwicklung von NoSQL-Datenbanken kann diese großen Datenmengen jedoch sehr gut verarbeiten. 
2. Was ist
NoSQL (NoSQL = Not Only SQL), was „nicht nur SQL“ bedeutet, bezieht sich im Allgemeinen auf nicht-relationale Datenbanken . Mit dem Aufkommen von Web2.0-Websites im Internet sind herkömmliche relationale Datenbanken nicht mehr in der Lage, mit Web2.0-Websites zurechtzukommen, insbesondere mit sehr großen und hochgradig gleichzeitigen, rein dynamischen Web2.0-Websites vom Typ SNS, was viele unüberwindbare Probleme aufdeckt Datenbanken haben sich aufgrund ihrer Eigenheiten sehr schnell entwickelt. NoSQL-Datenbanken wurden erstellt, um die Herausforderungen zu lösen, die große Datensammlungen und mehrere Datentypen mit sich bringen, insbesondere Big-Data-Anwendungsprobleme, einschließlich der Speicherung extrem großer Datenmengen.
(z. B. sammeln Google oder Facebook täglich Billionen von Daten für ihre Nutzer). Diese Arten von Datenspeichern erfordern kein festes Schema und können ohne redundante Vorgänge skaliert werden.
3. Was es kann
Einfach zu erweitern
Es gibt viele Arten von NoSQL-Datenbanken, aber ein gemeinsames Merkmal besteht darin, die relationalen Eigenschaften relationaler Datenbanken zu entfernen. Es besteht keine Beziehung zwischen den Daten und ist daher sehr einfach zu erweitern. Es bietet auch unsichtbar Skalierbarkeitsmöglichkeiten auf Architekturebene.
Hohe Leistung bei großen Datenmengen
NoSQL-Datenbanken haben eine sehr hohe Lese- und Schreibleistung, insbesondere bei großen Datenmengen sind sie auch performant.
Dies liegt an der nicht relationalen Natur und der einfachen Datenbankstruktur.
Im Allgemeinen verwendet MySQL den Abfrage-Cache, wenn die Tabelle aktualisiert wird. Bei Anwendungen mit häufigen Interaktionen ist die Cache-Leistung nicht hoch.
Der Cache von NoSQL ist auf Datensatzebene und ein feinkörniger Cache, sodass NoSQL auf dieser Ebene eine viel höhere Leistung aufweist.
Vielfältige und flexible Datenmodelle
NoSQL muss keine Felder für die zu speichernden Daten im Voraus erstellen und kann jederzeit benutzerdefinierte Datenformate speichern.
In einer relationalen Datenbank ist das Hinzufügen und Löschen von Feldern eine sehr mühsame Sache. Wenn es sich um eine Tabelle mit einer sehr großen Datenmenge handelt, ist das Hinzufügen von Feldern einfach ein Albtraum.
Traditionelles RDBMS VS NOSQL
RDBMS
Hochorganisierte strukturierte Daten
Strukturierte Abfragesprache (SQL)
Daten und Beziehungen werden in separaten Tabellen gespeichert
Datenmanipulationssprache, Datendefinitionssprache
Strikte Konsistenz
Grundlegende Transaktionen
NoSQL
bedeutet mehr als nur SQL
Keine deklarative Abfragesprache
Keine vordefinierten Schemata
Schlüsselwertspeicher, Spaltenspeicher, Dokumentspeicher, Diagrammdatenbanken
Eventuelle Konsistenz, keine ACID-Eigenschaften
Unstrukturierte und unvorhersehbare Daten:
CAP-Theorem
Hohe Leistung, hohe Verfügbarkeit und Skalierbarkeit
4. Was sind die NoSQL?
KV Cache
Persistenz
3V + 3 Hoch
3V im Big-Data-Zeitalter:
Riesiges Volumen
Echtzeitgeschwindigkeit
Beschreibung einiger Probleme im System, Taobao Double Eleven massive Daten. Ein Weibo, Textfeld, Videofeld, Hintergrundfeld usw. Diversifizierung. 12306 stellt hohe Echtzeitanforderungen. Absolute Echtzeit ist unmöglichDrei hohe Anforderungen an das Internet: Hohe Parallelität
Hohe Skalierbarkeit Hohe Leistung
Das System muss hohe Parallelität unterstützen, z. B. 12306. Vier Möglichkeiten, Threads zu erhalten.
Skalierbarkeit, horizontal und vertikal. Wenn eine Maschine horizontal nicht ausreicht, fügen Sie weitere Maschinen hinzu.
Hohe Leistungsanforderungen
Weitere verwandte Informationen finden Sie in der Spalte
redis
. .
Das obige ist der detaillierte Inhalt vonEinführung in das Redis-Lernen von NoSQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Spleißverwendung
Spleißverwendung
 So löschen Sie Daten in MongoDB
So löschen Sie Daten in MongoDB
 Wie wäre es mit der MEX-Börse?
Wie wäre es mit der MEX-Börse?
 Webserver
Webserver
 Der Unterschied zwischen vscode und vs
Der Unterschied zwischen vscode und vs
 Welche Versionen des Linux-Systems gibt es?
Welche Versionen des Linux-Systems gibt es?
 Was sind die Haupttechnologien von Firewalls?
Was sind die Haupttechnologien von Firewalls?
 Was bedeuten Zeichen in voller Breite?
Was bedeuten Zeichen in voller Breite?
 Der Unterschied zwischen MySQL und SQL_Server
Der Unterschied zwischen MySQL und SQL_Server











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



