

Schock! Es gibt so viele Sperren in einer SQL-Anweisung ...


Empfohlen (kostenlos): SQL-Tutorial
Lückensperre plus Zeilensperre, es ist leicht, Fehler bei der Beurteilung zu machen, ob eine Sperre wartet.
Da die Lückensperre nur unter der Isolationsstufe „Wiederholbares Lesen“ wirksam ist, wird in diesem Artikel standardmäßig das wiederholbare Lesen verwendet.
Sperrregeln
- Prinzip 1
Die Grundeinheit des Sperrens ist das Next-Key-Schloss, bei dem es sich um ein offenes und geschlossenes Intervall handelt. - Prinzip 2
Nur Objekte, auf die während des Suchvorgangs zugegriffen wird, werden gesperrt. - Optimierung 1
Bei äquivalenten Abfragen für den Index degeneriert die Next-Key-Sperre beim Sperren des eindeutigen Index in eine Zeilensperre. - Optimierung 2
Bei Gleichheitsabfragen im Index degeneriert die Next-Key-Sperre zu einer Lückensperre, wenn nach rechts gelaufen wird und der letzte Wert die Gleichheitsbedingung nicht erfüllt. - Ein Fehler
Eine Bereichsabfrage für einen eindeutigen Index greift auf den ersten Wert zu, der die Bedingung nicht erfüllt.
Datenvorbereitung
Tabellenname: t
Neue Daten: (0,0,0),(5,5,5),(10,10,10),(15,15,15), ( 20,20,20),(25,25,25)
Die folgenden Beispiele werden grundsätzlich von Bildbeschreibungen begleitet, daher empfehle ich Ihnen, sie anhand des Manuskripts zu lesen. Einige Beispiele können „die drei Ansichten ruinieren“, und das wird empfohlen Sie üben es selbst, nachdem Sie den Artikel gelesen haben.
Fall: Gleichwertige Abfragelückensperre TastensperreDaher ist der Sperrbereich von Sitzung A (5,10)
Gleichzeitig entspricht gemäß Optimierung 2 die Abfrage (id=7), aber id=10 ist nicht erfüllt, der nächste Schlüssel Die Sperre degeneriert in eine Lückensperre, daher ist der endgültige Sperrbereich (5,10)
- Wenn also Sitzung B den Datensatz mit der ID = 8 in diese Lücke einfügt, wird er gesperrt, aber Sitzung C kann die Zeile mit ändern id=10.
Nicht-eindeutiges Indexäquivalent
- Eine Sperre, die nur einem nicht-eindeutigen Index hinzugefügt wird

Sitzung A muss eine Lesesperre zu c=5 hinzufügen Zeile des Index c
Nach Prinzip 1 ist die Sperreinheit eine Next-Key-Sperre, also füge die Next-Key-Sperre zu (0,5] hinzuc ist ein gewöhnlicher Index , sodass nur auf den Datensatz c=5
zugegriffen werden kann Stoppen Sie sofort- , Sie müssen
- nach rechts queren
und erst aufgeben, wenn c=10 gefunden wird. Gemäß Prinzip 2 muss alles, auf das zugegriffen wird, gesperrt sein, also fügen Sie die Sperre für die nächste Taste zu (5,10) hinzu Gleichzeitig erfüllt es Optimierung 2: Äquivalenzbeurteilung, Querung nach rechts, und der letzte Wert erfüllt nicht die Äquivalenzbedingung von c = 5, sodass er nur nach Prinzip 2 zur Lückensperre (5,10) degeneriert Das Objekt, auf das zugegriffen wird, wird gesperrt. Diese Abfrage verwendet einen abdeckenden Index und muss nicht auf den Primärschlüsselindex zugreifen. Daher kann die Aktualisierungsanweisung von Sitzung B ausgeführt werden Wenn C (7,7,7) einfügen möchte, wird es durch die Lückensperre (5,10) von Sitzung A gesperrt Anders verhält es sich, wenn es sich um eine Aktualisierung handelt. Bei der Ausführung geht das System davon aus, dass Sie die Daten als Nächstes aktualisieren möchten, und fügt daher Zeilensperren zu den Zeilen hinzu, die die Bedingungen für den Primärschlüsselindex erfüllen. Es zeigt, dass die Sperre zum Index hinzugefügt wird. Gleichzeitig gibt es den Hinweis, dass Sie dies tun müssen, wenn Sie die Sperre im Freigabemodus verwenden möchten, um der Zeile eine Lesesperre hinzuzufügen, um zu verhindern, dass die Daten aktualisiert werden Umgehen Sie die Optimierung des Abdeckindex. Ändern Sie beispielsweise die Abfrageanweisung von Sitzung A, um d aus t auszuwählen, wobei c=5 im Freigabemodus gesperrt ist
Bereichsabfrage
3 Primärschlüssel-Indexbereichssperre - Haben die folgenden beiden Abfrageanweisungen den gleichen Sperrbereich?
mysql> select * from t where id=10 for update; select * from t where id> ;=10 and id<11 for update;
Sie denken vielleicht, dass diese beiden Anweisungen gleichwertig sind, da id als int-Typ definiert ist, oder? Tatsächlich sind sie nicht völlig gleichwertig. Logisch gesehen sind diese beiden Abfrageanweisungen definitiv gleichwertig, aber ihre Sperrregeln sind unterschiedlich. Lassen wir nun Sitzung A die zweite Abfrageanweisung ausführen, um den Sperreffekt zu sehen. Abbildung 3 Sperren für Bereichsabfragen im Primärschlüsselindex Lassen Sie uns nun die zuvor erwähnten Sperrregeln verwenden, um zu analysieren, welche Sperren zu Sitzung A hinzugefügt werden.
Wenn wir die Ausführung starten, müssen wir die erste Zeile mit der ID=10 finden, daher sollte es sich um next-key lock(5,10) handeln. Gemäß Optimierung 1 degeneriert die Äquivalenzbedingung für die Primärschlüssel-ID zu einer Zeilensperre und fügt nur die Zeilensperre für die Zeile mit der ID=10 hinzu.
Die Bereichssuche wird fortgesetzt, bis die Zeile mit der ID=15 gefunden wird. Daher muss die nächste Schlüsselsperre (10,15) hinzugefügt werden. Also, Sitzung A zu diesem Zeitpunkt Der Umfang der Sperre ist der Primärschlüsselindex, die Zeilensperre-ID = 10 und die Sperre für den nächsten Schlüssel (10,15). Auf diese Weise können Sie die Ergebnisse von Sitzung B und Sitzung C verstehen.
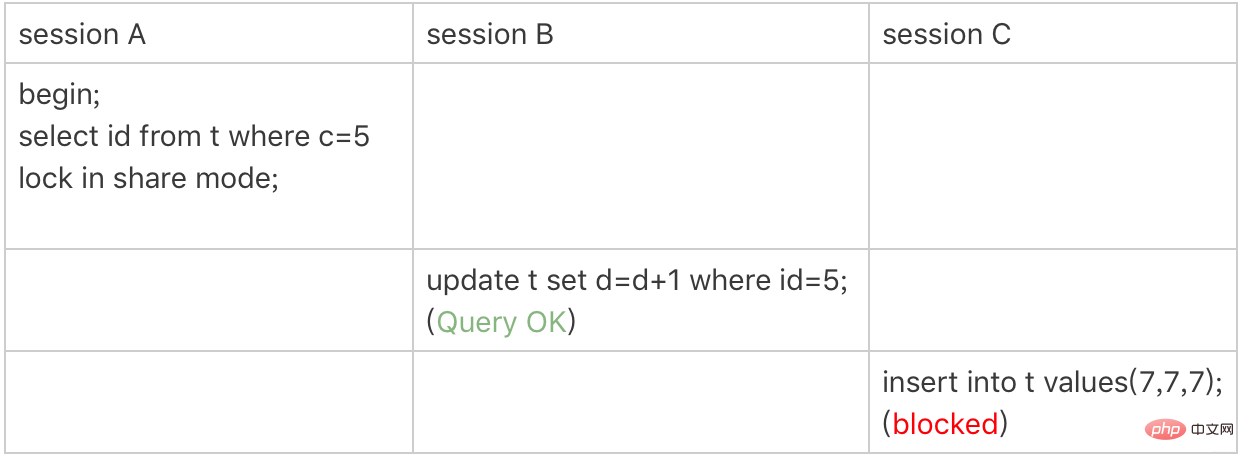
Hier müssen Sie auf eines achten: Die erste Sitzung A. Wenn Sie die Zeile mit der ID = 10 finden, wird sie als äquivalente Abfrage beurteilt, und beim Scannen nach rechts bis zur ID = 15 wird sie anhand eines Bereichs beurteilt Abfrage
.Schauen Sie sich die Bereichsabfragesperre noch einmal an. Sie können sie mit Fall drei vergleichen t wobei c>=10 und c<11 für Update; code> Um den Datensatz zum ersten Mal zu finden, wird Index c mit (5,10] next-key lock hinzugefügt.
c ist ein nicht eindeutiger Index. Es gibt keine Optimierungsregeln. das heißt, es wird nicht zu einer Zeilensperre ausarten
| Also aus dem Ergebnis, wenn session2 die Einfügeanweisung von (8,8,8) einfügen möchte, muss der nicht eindeutige Index auf c=15 gescannt werden, bevor Sie das wissen Es besteht keine Notwendigkeit, den Fehler bei der Sperrung des Indexbereichs fortzusetzen. Die ersten vier Fälle verwenden zwei Prinzipien und zwei Optimierungen session_3 | ||
|---|---|---|
update t | setze d=d+1 wobei id=20;(blockierend) | |
| session1 ist eine Bereichsabfrage | A Aufzeichnung Fügen Sie gemäß Prinzip 1 nur (10,15] next-key lock zur Index-ID hinzu. Da id der einzige Schlüssel ist, bestimmt die Schleife id=15 Diese Zeile sollte Stoppen Sie das Durchlaufen |
- Wenn also Sitzung2 die Zeile id=20 aktualisieren möchte, wird sie blockiert.
- Sitzung3 muss auch id=16 einfügen blockiert werden.
c=10定位记录时,索引c加了(5,10] next-key lock - c是非唯一索引,无优化规则,即不会退变为行锁
- 因此最终sesion1加锁为c的
(5,10]和(10,15]next-key lock。
所以从结果上来看,sesson2要插入(8,8,8)的这个insert语句时就被阻塞。
非唯一索引要扫到c=15,才知道无需继续往后遍历。
唯一索引范围锁bug
前四案例用到两个原则和两个优化,再看加锁规则bug案例。
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; select * from t where id>10 and id<=15 for update; | ||
| update t set d=d+1 where id=20;(阻塞) |
||
| insert into t values(16,16,16);(阻塞) |
| Zur besseren Veranschaulichung des „Lücken“-Konzepts. | Datensatz 7 einfügen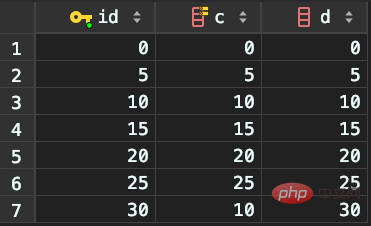 |
|
|---|---|---|
|
Schauen Sie sich die folgenden Fälle an. 6 | Die Sperrlogik von delete ähnelt
session_1 |
|
| session_3 |
begin; delete * from t | wobei c=10|
| |
values(13 ,13,13);(Blockieren)
| session1 greift beim Durchlaufen von 10 zuerst auf das erste c= zu : | |
|---|---|
| Dann sucht Sitzung1 nach rechts, bis sie auf (c=15, id=15) An dieser Zeile endet die Schleife. Gemäß Optimierung 2, äquivalenter Abfrage, werden rechts Zeilen gefunden, die die Bedingungen nicht erfüllen, sodass sie zu einer Lückensperre degenerieren (offenes Intervall, (c= Die beiden Zeilen 5, id=5) und (c=15, id=15) sind sperrenfrei). 7 Limit-Anweisungssperre |
|
|
Die Löschanweisung von Sitzung1 wird mit Limit 2 hinzugefügt. Sie wissen, dass es in Tabelle t tatsächlich nur zwei Datensätze mit c = 10 gibt. Unabhängig davon, ob Limit 2 hinzugefügt wird oder nicht, ist der Effekt des Löschens derselbe, der Effekt des Sperrens jedoch unterschiedlich. Es ist ersichtlich, dass die Einfügeanweisung von Sitzung B erfolgreich ausgeführt wurde, was sich vom Ergebnis von Fall 6 unterscheidet. Das liegt daran, dass die Löschanweisung in Fall 7 eindeutig eine Grenze von Grenze 2 hinzufügt, sodass nach dem Durchlaufen der Zeile (c=10, id=30) bereits zwei Anweisungen vorhanden sind, die die Bedingung erfüllen, und die Schleife endet. Daher wird der Sperrbereich auf Index c zum Intervall von vorne offen und hinten geschlossen von (c=5, id=5) bis (c=10, id=30), wie in der folgenden Abbildung dargestellt: Der Sperreffekt mit Limit 2 Man erkennt, dass die Lücke nach (c=10, id=30) nicht im Sperrbereich liegt, sodass die Einfügeanweisung zum Einfügen von c=12 erfolgreich ausgeführt werden kann. Die zentrale Bedeutung dieses Beispiels für unsere Praxis besteht darin, zu versuchen, beim Löschen von Daten ein Limit hinzuzufügen. Dadurch wird nicht nur die Anzahl der gelöschten Daten kontrolliert, was den Vorgang sicherer macht, sondern auch der Umfang der Sperrung verringert. Ein Deadlock-Beispiel Im vorherigen Beispiel haben wir es bei der Analyse nach der Logik der Next-Key-Sperre analysiert, da es auf diese Weise bequemer zu analysieren ist. Schauen wir uns zum Schluss noch einen anderen Fall zur Veranschaulichung an: Die Next-Key-Sperre ist eigentlich das Ergebnis der Summe aus Lückensperre und Zeilensperre. Sie fragen sich bestimmt, wurde dieses Konzept nicht gleich zu Beginn erwähnt? Keine Sorge, schauen wir uns zunächst das folgende Beispiel an: Operationssequenz von Fall 8 Sitzung A. Führen Sie nach dem Starten der Transaktion die Abfrageanweisung aus, fügen Sie eine Sperre im Freigabemodus hinzu und fügen Sie den nächsten Schlüssel hinzu lock(5,10 auf Index c ] und Gap Lock (10,15); Die Update-Anweisung von Sitzung B muss auch Next-Key Lock (5,10] zu Index c hinzufügen und die Sperre eingeben; Dann Sitzung A muss (8,8,8) einfügen. Diese Zeile ist durch die Gap-Sperre von Sitzung B gesperrt. Aufgrund eines Deadlocks setzt InnoDB Sitzung B zurück. Sie fragen sich vielleicht, ob die Next-Key-Sperre der Sitzung nicht vorhanden ist B erfolgreich angewendet? Tatsächlich ist die Operation „Nächste Tastensperre hinzufügen (5,10)“ in zwei Schritte unterteilt. Fügen Sie zunächst die Lückensperre von (5,10) hinzu. und die Sperre ist erfolgreich. Fügen Sie dann c = 10 hinzu müssen in Lückensperren unterteilt werden und die Zeilensperre wird in zwei Stufen ausgeführt. Alle Fälle werden unter wiederholbarem Lesen überprüft. Alle gesperrten Ressourcen werden festgeschrieben oder zurückgesetzt Transaktion. Im letzten Fall können Sie deutlich erkennen, dass die Next-Key-Sperre tatsächlich durch Lückensperre und Zeilensperre implementiert wird. Wenn Sie zur Lese-Committed-Isolationsstufe wechseln, wird der Lückensperrenteil entfernt Dabei bleibt nur der Zeilensperrteil übrig Unter der Lese-Commit-Isolationsstufe gibt es eine weitere Optimierung, nämlich die Zeilensperre, die während der Anweisungsausführung hinzugefügt wird Die „Zeile, die die Bedingungen nicht erfüllt“ muss direkt freigegeben werden, ohne auf die Festschreibung der Transaktion zu warten.Unter der Lese-Festschreibungs-Isolationsstufe ist der Sperrbereich kleiner und die Sperrzeit kürzer, was auch von vielen Unternehmen verwendet wird Standardmäßig lesen. Wenn das Unternehmen wiederholbare Lesevorgänge verwenden muss, kann es das Problem des Phantomlesens lösen und die Fähigkeit des Systems maximieren, Transaktionen parallel zu verarbeiten. Lückensperren und Zeilensperren erleichtern die Feststellung, ob eine Sperre wartet Es werden Probleme auftreten. Da die Lückensperre nur unter der wiederholbaren Leseisolationsstufe wirksam ist, besuchen Sie bitte die Spalte „SQL-freies Lesen“. |
Das obige ist der detaillierte Inhalt vonSchock! Es gibt so viele Sperren in einer SQL-Anweisung .... Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Was ist der Unterschied zwischen HQL und SQL im Hibernate-Framework?
Apr 17, 2024 pm 02:57 PM
Was ist der Unterschied zwischen HQL und SQL im Hibernate-Framework?
Apr 17, 2024 pm 02:57 PM
HQL und SQL werden im Hibernate-Framework verglichen: HQL (1. Objektorientierte Syntax, 2. Datenbankunabhängige Abfragen, 3. Typsicherheit), während SQL die Datenbank direkt betreibt (1. Datenbankunabhängige Standards, 2. Komplexe ausführbare Datei). Abfragen und Datenmanipulation).
 Verwendung der Divisionsoperation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
Verwendung der Divisionsoperation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
„Verwendung der Divisionsoperation in OracleSQL“ In OracleSQL ist die Divisionsoperation eine der häufigsten mathematischen Operationen. Während der Datenabfrage und -verarbeitung können uns Divisionsoperationen dabei helfen, das Verhältnis zwischen Feldern zu berechnen oder die logische Beziehung zwischen bestimmten Werten abzuleiten. In diesem Artikel wird die Verwendung der Divisionsoperation in OracleSQL vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Zwei Arten von Divisionsoperationen in OracleSQL In OracleSQL können Divisionsoperationen auf zwei verschiedene Arten durchgeführt werden.
 Vergleich und Unterschiede der SQL-Syntax zwischen Oracle und DB2
Mar 11, 2024 pm 12:09 PM
Vergleich und Unterschiede der SQL-Syntax zwischen Oracle und DB2
Mar 11, 2024 pm 12:09 PM
Oracle und DB2 sind zwei häufig verwendete relationale Datenbankverwaltungssysteme, die jeweils über ihre eigene, einzigartige SQL-Syntax und -Eigenschaften verfügen. In diesem Artikel werden die SQL-Syntax von Oracle und DB2 verglichen und unterschieden und spezifische Codebeispiele bereitgestellt. Datenbankverbindung Verwenden Sie in Oracle die folgende Anweisung, um eine Verbindung zur Datenbank herzustellen: CONNECTusername/password@database. In DB2 lautet die Anweisung zum Herstellen einer Verbindung zur Datenbank wie folgt: CONNECTTOdataba
 Ausführliche Erläuterung der Funktion „Tag festlegen' in den dynamischen SQL-Tags von MyBatis
Feb 26, 2024 pm 07:48 PM
Ausführliche Erläuterung der Funktion „Tag festlegen' in den dynamischen SQL-Tags von MyBatis
Feb 26, 2024 pm 07:48 PM
Interpretation der dynamischen SQL-Tags von MyBatis: Detaillierte Erläuterung der Verwendung von Set-Tags. MyBatis ist ein hervorragendes Persistenzschicht-Framework. Es bietet eine Fülle dynamischer SQL-Tags und kann Datenbankoperationsanweisungen flexibel erstellen. Unter anderem wird das Set-Tag zum Generieren der SET-Klausel in der UPDATE-Anweisung verwendet, die sehr häufig bei Aktualisierungsvorgängen verwendet wird. In diesem Artikel wird die Verwendung des Set-Tags in MyBatis ausführlich erläutert und seine Funktionalität anhand spezifischer Codebeispiele demonstriert. Was ist Set-Tag? Set-Tag wird in MyBati verwendet
 Was bedeutet das Identitätsattribut in SQL?
Feb 19, 2024 am 11:24 AM
Was bedeutet das Identitätsattribut in SQL?
Feb 19, 2024 am 11:24 AM
Was ist Identität in SQL? In SQL ist Identität ein spezieller Datentyp, der zum Generieren automatisch inkrementierender Zahlen verwendet wird. Er wird häufig verwendet, um jede Datenzeile in einer Tabelle eindeutig zu identifizieren. Die Spalte „Identität“ wird oft in Verbindung mit der Primärschlüsselspalte verwendet, um sicherzustellen, dass jeder Datensatz eine eindeutige Kennung hat. In diesem Artikel wird die Verwendung von Identity detailliert beschrieben und es werden einige praktische Codebeispiele aufgeführt. Die grundlegende Möglichkeit, Identity zu verwenden, besteht darin, Identit beim Erstellen einer Tabelle zu verwenden.
 So beheben Sie den 5120-Fehler in SQL
Mar 06, 2024 pm 04:33 PM
So beheben Sie den 5120-Fehler in SQL
Mar 06, 2024 pm 04:33 PM
Lösung: 1. Überprüfen Sie, ob der angemeldete Benutzer über ausreichende Berechtigungen zum Zugriff auf oder zum Betrieb der Datenbank verfügt, und stellen Sie sicher, dass der Benutzer über die richtigen Berechtigungen verfügt. 2. Überprüfen Sie, ob das Konto des SQL Server-Dienstes über die Berechtigung zum Zugriff auf die angegebene Datei verfügt Ordner und stellen Sie sicher, dass das Konto über ausreichende Berechtigungen zum Lesen und Schreiben der Datei oder des Ordners verfügt. 3. Überprüfen Sie, ob die angegebene Datenbankdatei von anderen Prozessen geöffnet oder gesperrt wurde. Versuchen Sie, die Datei zu schließen oder freizugeben, und führen Sie die Abfrage erneut aus . Versuchen Sie es als Administrator. Führen Sie Management Studio aus als usw.
 Datenbanktechnologie-Wettbewerb: Was sind die Unterschiede zwischen Oracle und SQL?
Mar 09, 2024 am 08:30 AM
Datenbanktechnologie-Wettbewerb: Was sind die Unterschiede zwischen Oracle und SQL?
Mar 09, 2024 am 08:30 AM
Datenbanktechnologie-Wettbewerb: Was sind die Unterschiede zwischen Oracle und SQL? Im Datenbankbereich sind Oracle und SQL Server zwei hoch angesehene relationale Datenbankverwaltungssysteme. Obwohl beide zur Kategorie der relationalen Datenbanken gehören, gibt es viele Unterschiede zwischen ihnen. In diesem Artikel befassen wir uns mit den Unterschieden zwischen Oracle und SQL Server sowie deren Funktionen und Vorteilen in praktischen Anwendungen. Zunächst einmal gibt es Unterschiede in der Syntax zwischen Oracle und SQL Server.
 So verwenden Sie „months_between' in SQL
Jan 25, 2024 pm 03:23 PM
So verwenden Sie „months_between' in SQL
Jan 25, 2024 pm 03:23 PM
MONTHS_BETWEEN ist in SQL eine häufig verwendete Funktion zur Berechnung der Monatsdifferenz zwischen zwei Daten. Wie es verwendet wird, hängt vom jeweiligen Datenbankverwaltungssystem ab.
