


Empfohlenes kostenloses Lernen: Python-Video-Tutorial
1. Vorwort
2. Erforderliche Bibliotheken2. Bibliotheken, die verwendet werden müssen
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
Freunde, die keine Bibliotheken installieren müssen, können sich diesen Artikel ansehen, den ich zuvor geschrieben habe. Er enthält viele Links zu inländischen Quellen, um Ihnen das Herunterladen zu erleichtern.
Portal: 3. Implementierungsprozess Rufen Sie die Seite „Originalgemälde“ auf. Nachdem Sie die Seite „Hintergründe“ aufgerufen haben, wählen Sie ein Hintergrundbild aus und schauen Sie es sich an.
Ich habe festgestellt, dass es verschiedene Links gibt, die unterschiedlichen Auflösungen entsprechen, und das von mir überprüfte Bild hat sechs Auflösungen. Sind alle Bilder so?
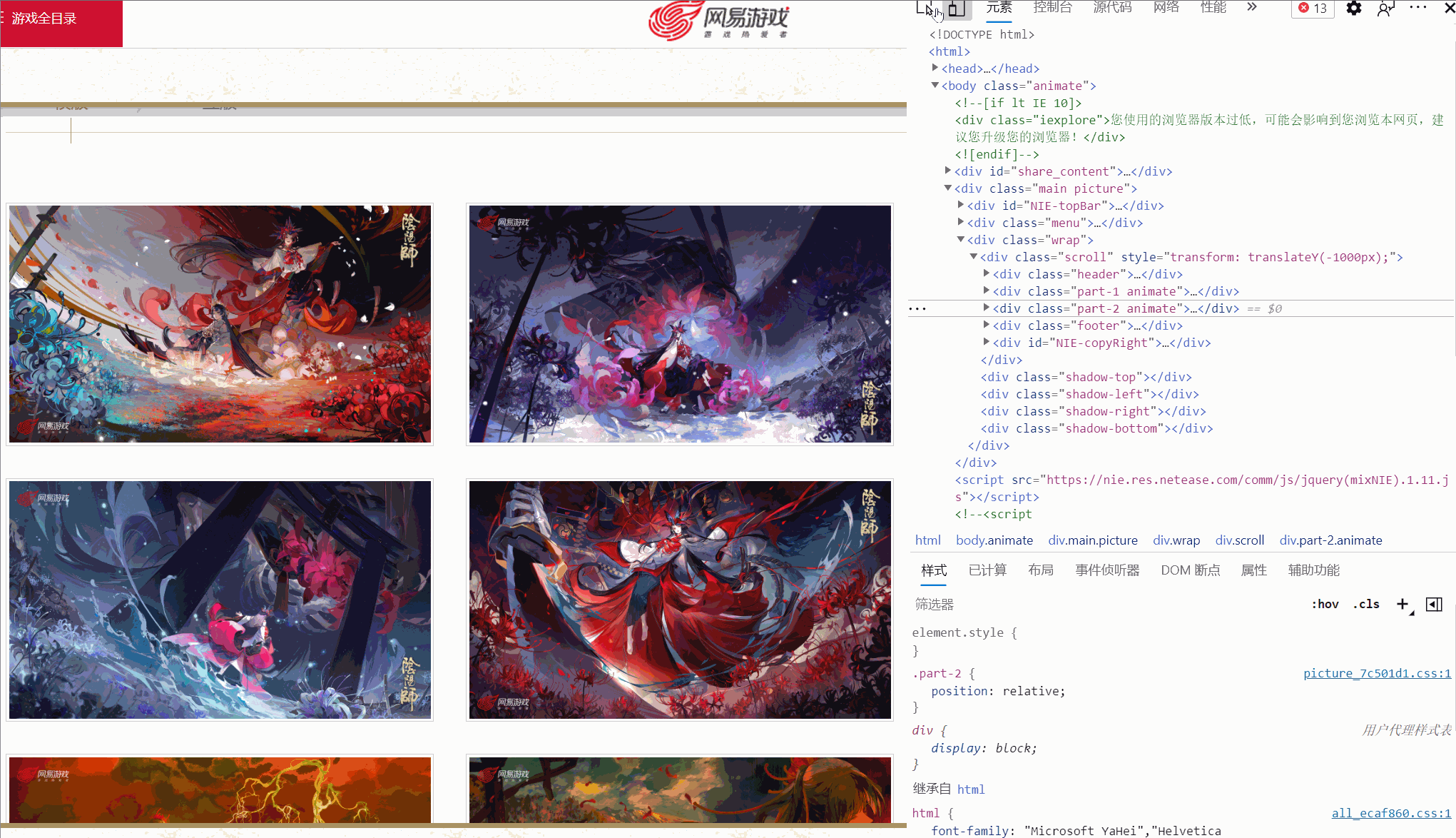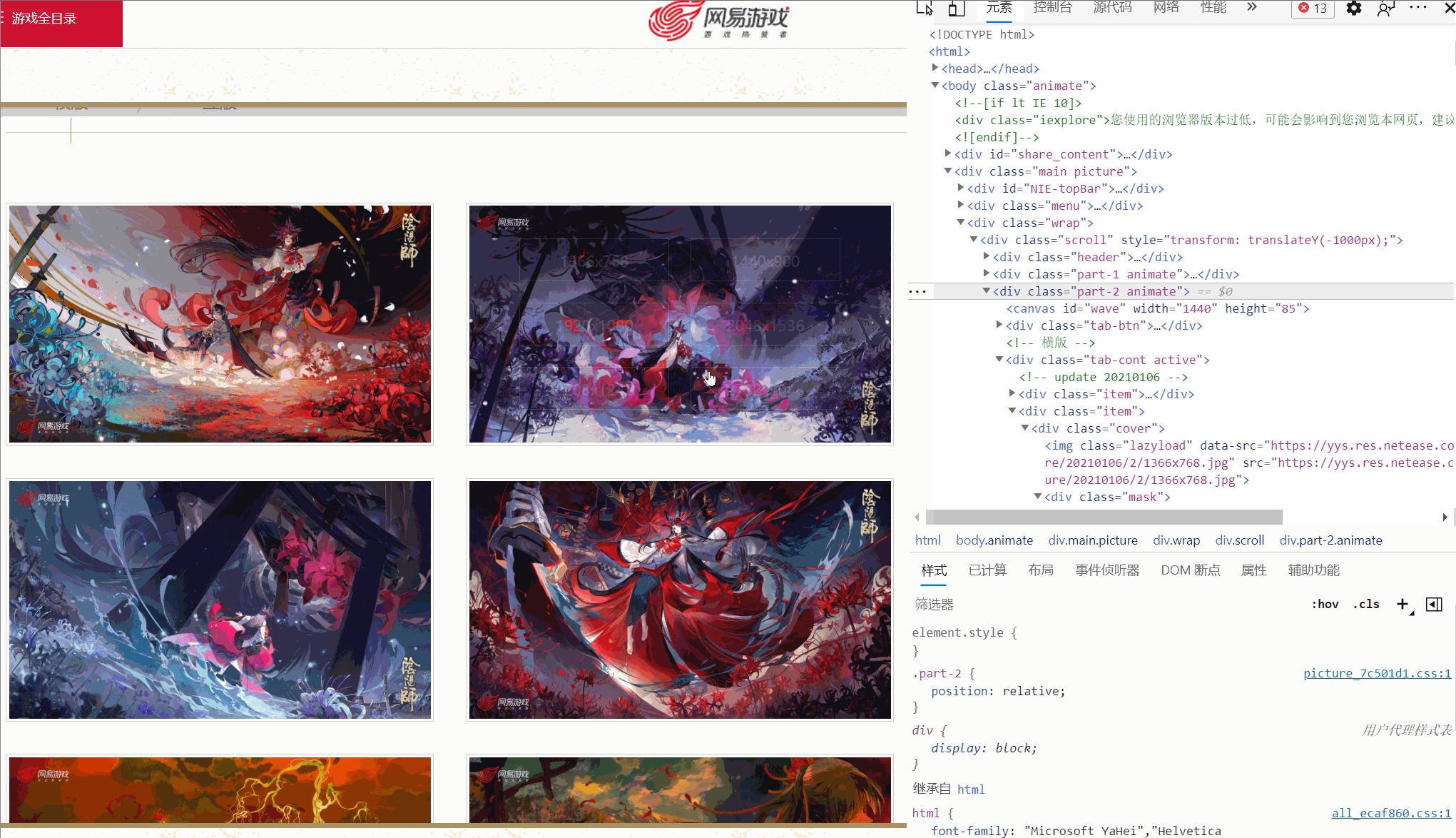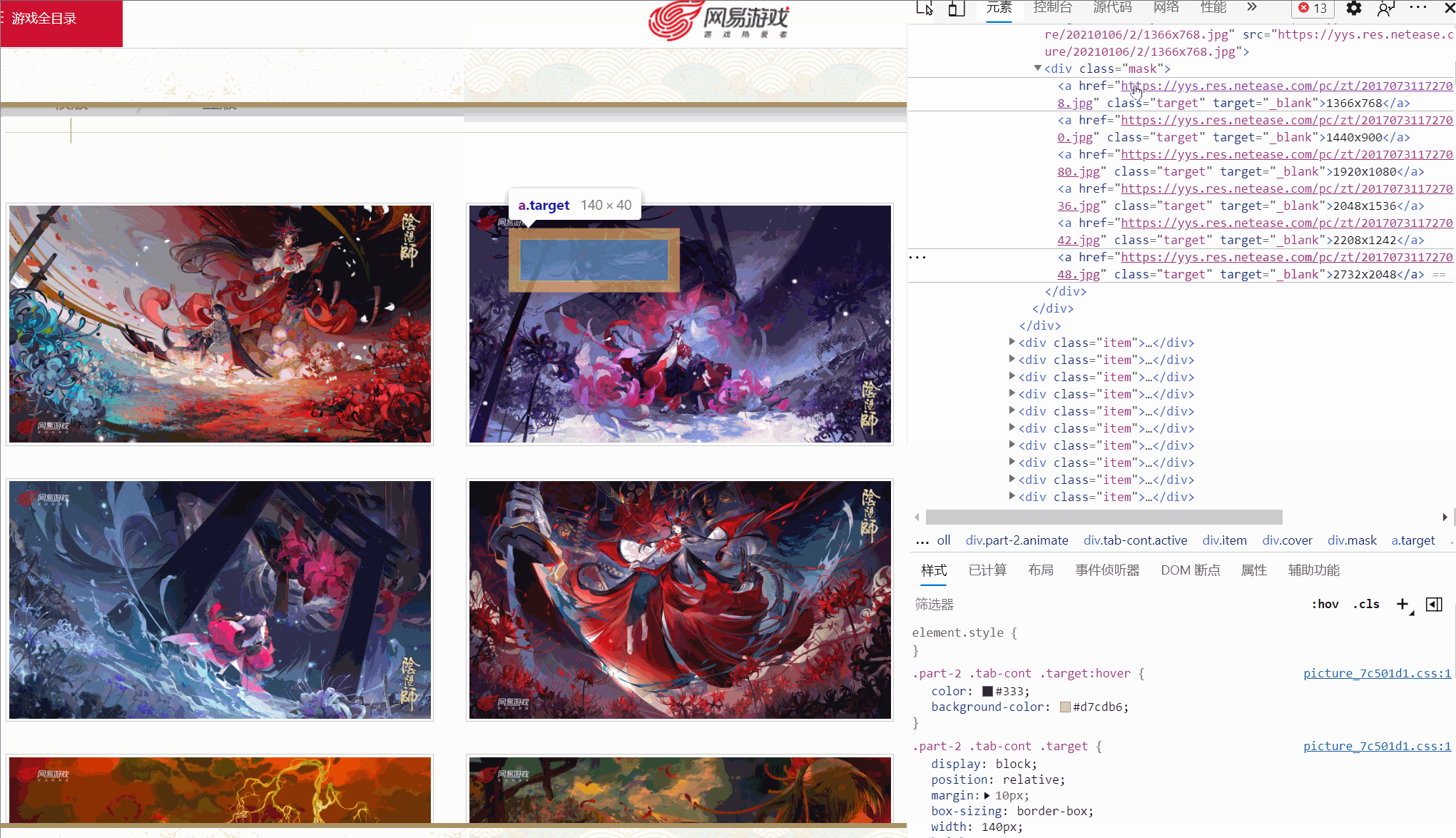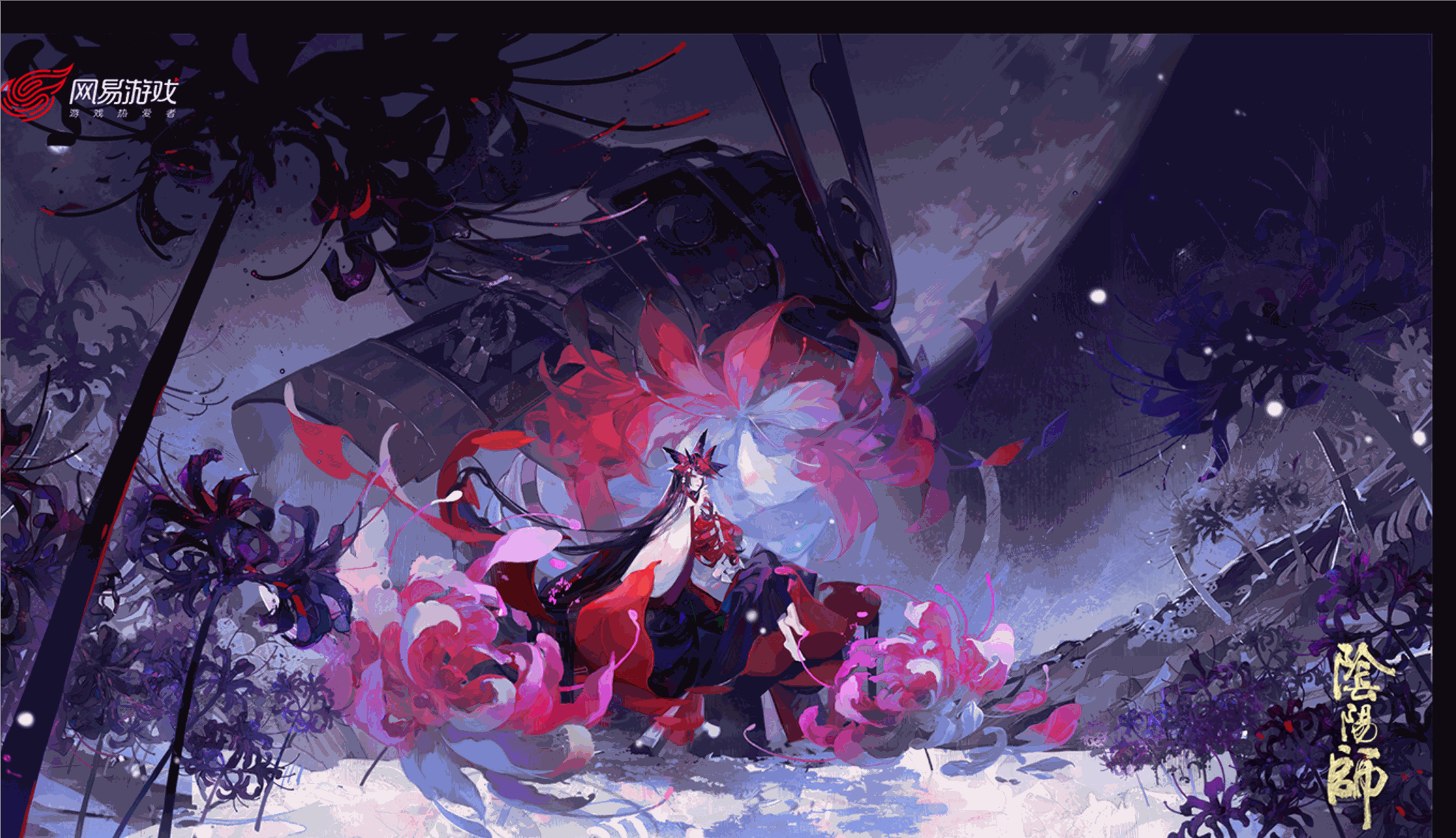
Später fand ich heraus, dass dem nicht so war!Wie oben gezeigt, hat ein Bild sogar nur vier Auflösungen und die Auflösung und Position jedes Bildes sind nicht konsistent. Wie kann man also den Original-Gemälde-Link extrahieren? A: Verwenden Sie xpath, um Knoten basierend auf Textinhalten zu extrahieren
a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0]F:Was ist das? A: Sie werden es wissen, nachdem Sie den vollständigen Code gelesen haben. 2. Vollständige Code-Implementierung Der Code lautet wie folgt:
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
path = 'D:/阴阳师'if not os.path.exists(path):
os.mkdir(path)# 随机产生请求头ua = UserAgent(verify_ssl=False, path='fake_useragent.json')url = 'https://yys.163.com/media/picture.html' # 原画壁纸的页面链接response = requests.get(url=url).text
html = etree.HTML(response)lists = html.xpath('/html/body/p[2]/p[3]/p[1]/p[3]/p[2]/p')num = 1for i in range(len(lists)):
a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0] # 根据文本内容锁定节点a
image_url = a.xpath('./@href')[0] # 获取原画壁纸链接
image_data = requests.get(url=image_url).content
image_name = '{}.jpg'.format(num) # 给每张图片命名
save_path = path + '/' + image_name # 图片的保存地址
with open(save_path, 'wb') as f:
f.write(image_data)
print(image_name, '=======================>下载成功!!!')
f.close()
num += 1Hinweis: Beim Zusammenstellen eines Videos dürfen der Bildspeicherpfad und der Videogenerierungspfad kein Chinesisch enthalten! ! !
Eine Sammlung von Onmyoji-Originalgemälden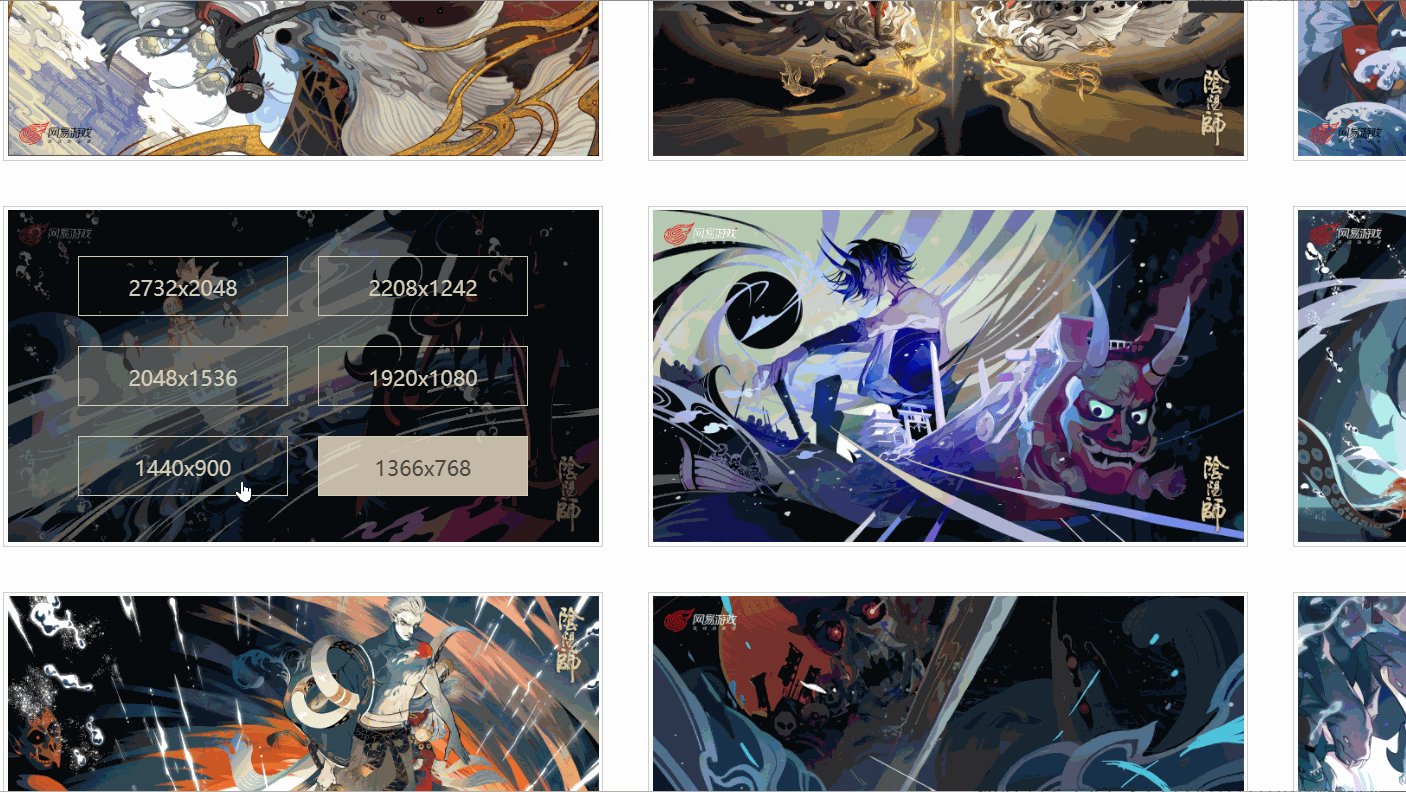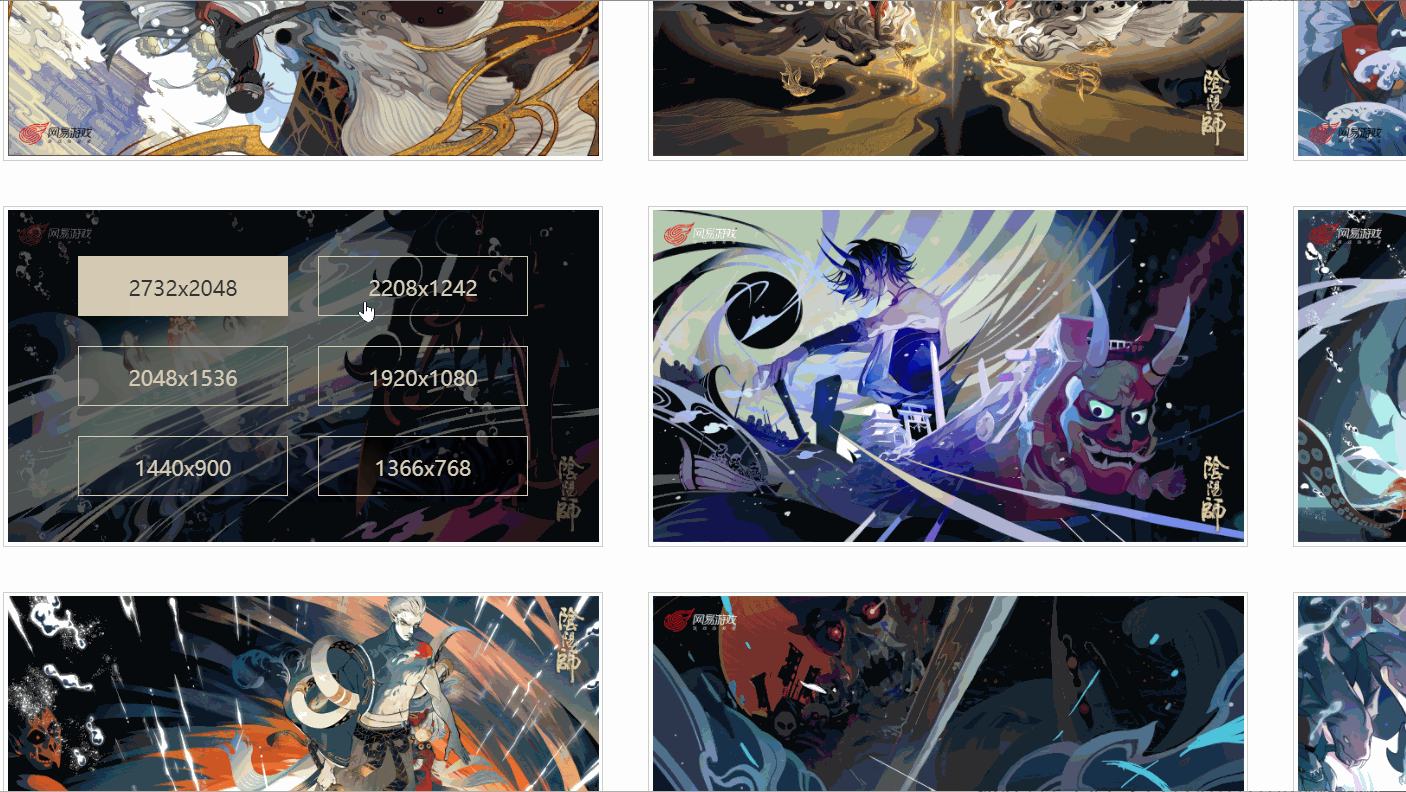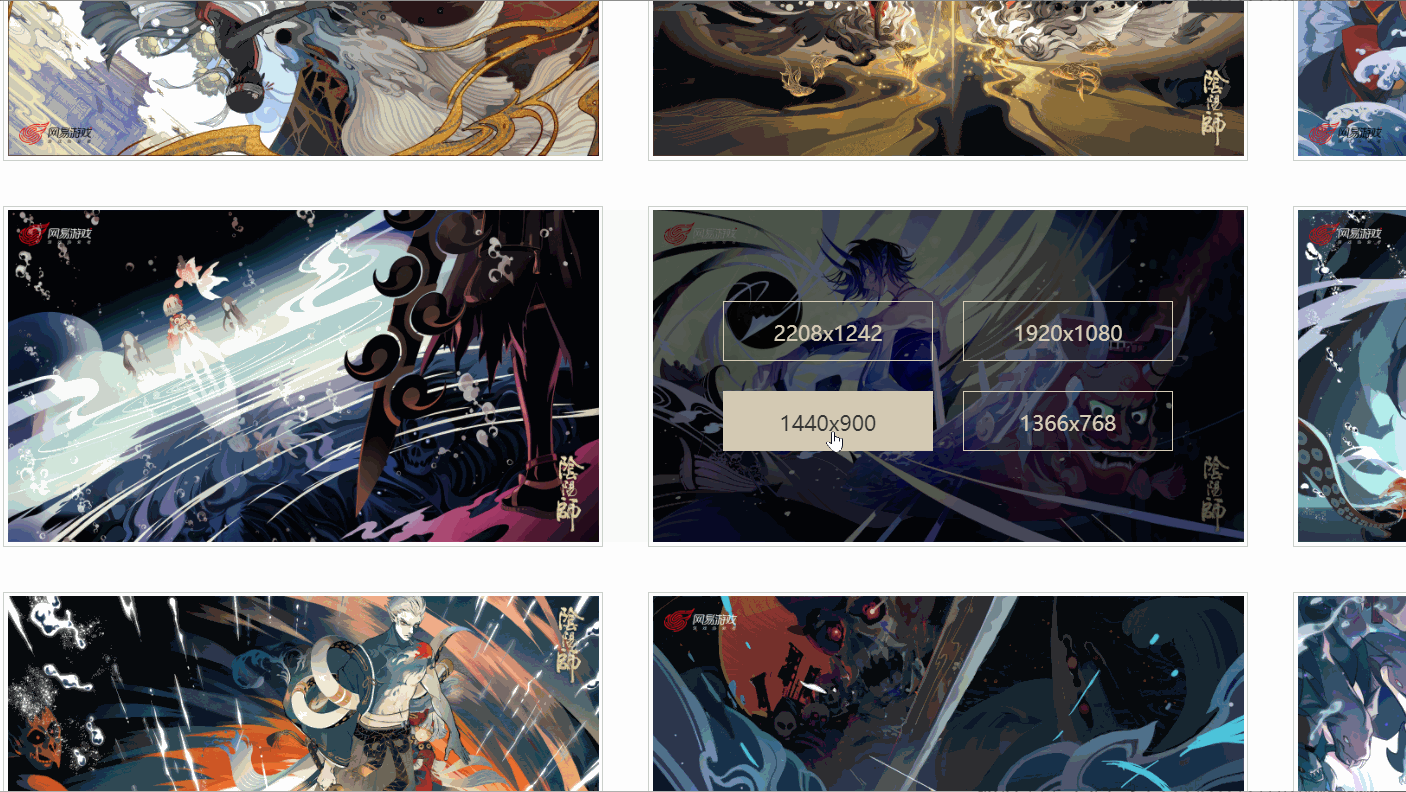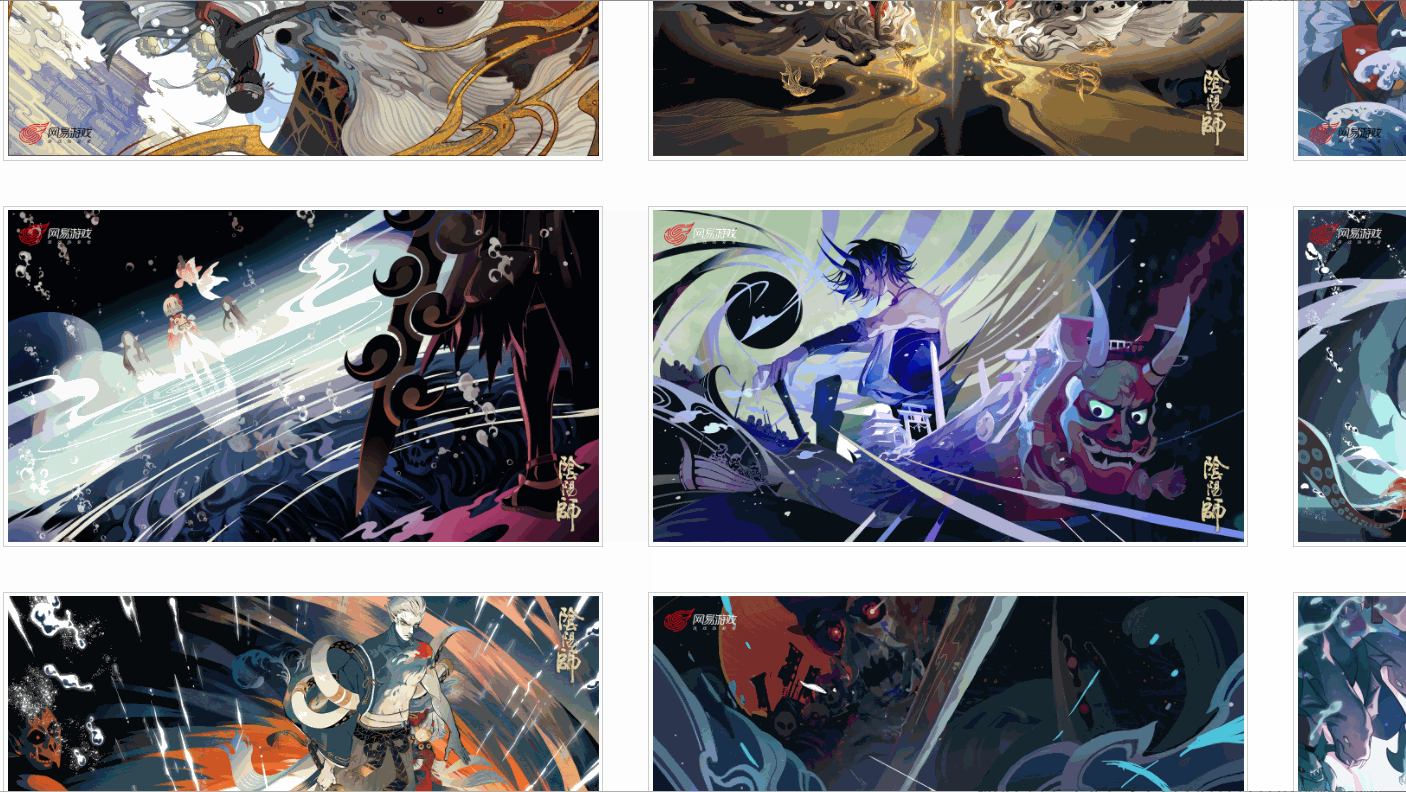
Python-Tutorial
lists[i](Video)
Das obige ist der detaillierte Inhalt vonPython implementiert einfach eine Ein-Klick-Methode, um die Originalgemälde von Onmyoji zu extrahieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



